归并排序和快速排序
Posted 周小末天天开心
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了归并排序和快速排序相关的知识,希望对你有一定的参考价值。

目录
归并排序
定义:归并排序是建立在归并操作上的一种有效,稳定的排序算法,该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。

思路:
1)首先将给定的数组51, 46, 20, 18, 95, 67, 82, 30一分为二,直到每个数组的长度等于1
51, 46, 20, 18 95, 67, 82, 30
51, 46 20, 18 95, 67 82, 30
51 46 20 18 95 67 82 30
2)两两比较进行交换46, 51 18, 20 67, 95 30, 82
3)最后进行合并得到排序后的数组18, 20, 30, 46, 51, 67, 82, 95
整体的递归思路就是:

代码执行:
import java.util.Arrays;
public class MergeSort
public static int sum = 0;
public static void main(String[] args)
int[] a = 51, 46, 20, 18, 95, 67, 82, 30;
mergeSort(a, 0, a.length - 1);
System.out.println(Arrays.toString(a));
public static void mergeSort(int[] a, int left, int right)
//二分
int mid = (left + right) / 2;
//拆分过程就是递归,需要不断进行递归,减小子数组的规模,最终减小到每个数组的规模为1或者为0
if (left < right)
mergeSort(a, left, mid);
mergeSort(a, mid + 1, right);
merge(a, left, mid, right);
public static void merge(int[] a, int left, int mid, int right)
int[] temp = new int[right - left + 1];//临时数组,用来进行归并
int i = left, j = mid + 1, k = 0;//左半段用i指向,右半段用j指向,temp中用k指向
while (i <= mid && j <= right)
if (a[i] < a[j])
//如果左边的a[i]小于右边的a[j],就放到数组的第k个,k和i自增
temp[k++] = a[i++];
else
//否则,就把右边的第j个放到数组的第k个,k和j自增
temp[k++] = a[j++];
while (i <= mid) temp[k++] = a[i++];//如果左边在循环比较后还有剩余,就放到k中、
while (j <= right) temp[k++] = a[j++];//如果剩余直接放到k中
for (int l = 0; l < temp.length; l++)
//让temp数组放到左半段和右半段有序的数据
a[left + l] = temp[l];
快速排序
运行流程:
1)首先设定一个分界值,通过该分界值将数组分成左右两部分。
2)将大于或等于分界值的数据集中到数组右边,小于分界值的数据集中到数组的左边。此时,左边部分中各元素都小于分界值,而右边部分中各元素都大于或等于分界值。
3)左边和右边的数据可以独立排序。对于左侧的数组数据,又可以取一个分界值,将该部分数据分成左右两部分,同样在左边放置较小值,右边放置较大值。右侧的数组数据也可以做类似处理。
4)重复上述过程,可以看出,这是一个递归定义。通过递归将左侧部分排好序后,再递归排好右侧部分的顺序。当左、右两个部分各数据排序完成后,整个数组的排序也就完成了。
运行流程图:

代码思路:
1)首先确定left、rigeht和基准点temp
2)当i(left) 和 j(right)相等的时候就结束循环
3)在循环中再次循环找出a[j]小于temp的时候把a[j]赋给a[i++],以及找出a[i]大于temp的时候把a[i]赋给a[j--]
4)不断递归进行排序
代码执行:
import java.util.Arrays;
public class quickSortDemo
public static void main(String[] args)
int[] a = 49, 38, 65, 97, 76, 13, 27, 49;
quickSort(a, 0, a.length - 1);
System.out.println(Arrays.toString(a));
public static void quickSort(int[] a, int left, int right)
if (left > right) return;//区间无效不需要递归
int i = left, j = right, temp = a[left];//temp为基准点
while (i != j)
while (a[j] >= temp && j > i) j--;//一直循环找a[j]小于temp的时候
if (j > i) a[i++] = a[j];//将a[j]赋给a[i++]
while (a[i] <= temp && i < j) i++;//循环找a[i]大于temp的时候
if (i < j) a[j--] = a[i];//将a[i]赋给a[j--]
a[i] = temp;//将基准点的元素放到a[i]处
quickSort(a, left, i - 1);//已经确定i为基准点所以right就位i - 1
quickSort(a, i + 1, right);//已经确定i为基准点所以left就位i + 1

经典排序算法和python详解:归并排序快速排序堆排序计数排序桶排序和基数排序
经典排序算法和python详解(三):归并排序、快速排序、堆排序、计数排序、桶排序和基数排序
内容目录
一、归并排序二、快速排序三、堆排序四、计数排序五、桶排序六、基数排序
一、归并排序
归并排序就是利用归并的思想进行排序,也就是分而治之的策略,将问题分成一些小问题,然后递归求解,再将解决好的小问题合并在一起。和选择排序一样,归并排序的性能不受输入数据的影响,但表现比选择排序好的多,因为始终都是 O(nlogn) 的时间复杂度。代价是需要额外的内存空间。
归并排序的流程
其中合并两个有序子问题的流程
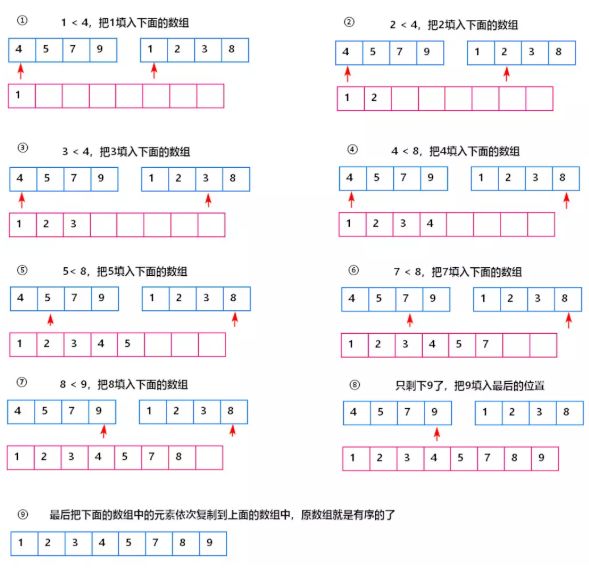
归并排序是稳定排序,它也是一种十分高效的排序,能利用完全二叉树特性的排序一般性能都不会太差。从上文的图中可看出,每次合并操作的平均时间复杂度为O(n),而完全二叉树的深度为|log2n|。总的平均时间复杂度为O(nlogn)。而且,归并排序的最好,最坏,平均时间复杂度均为O(nlogn)
Python代码:
def mergeSort(arr):
import math
if(len(arr)<2):
return arr
middle = math.floor(len(arr)/2)
left, right = arr[0:middle], arr[middle:]
return merge(mergeSort(left), mergeSort(right))
def merge(left,right):
result = []
while left and right:
if left[0] <= right[0]:
result.append(left.pop(0));
else:
result.append(right.pop(0));
while left:
result.append(left.pop(0));
while right:
result.append(right.pop(0));
return result
我们以列表[5,4,7,9,3,8,2,1]为例,
首先middle = len(list) / 2 = 8 / 2 = 4,将列表递归分为两部分Left = [0: middle] = [5,4,7,9], Right = [3,8,2,1],继续将Left和Right细分下去,Left递归得到L1 = [5,4], L2 = [7,9],Right递归得到R1 = [3,8],R2 = [2,1],
此时L1,L2,R1,R2长度仍大于1,继续细分,L1递归得到L11 = [5],L12 = [4],L2递归得到L21 = [7],L22 = [9],R1递归得到R11 = [3],R12 = [8],R2递归得到R21 = [2],R22 = [1],
此时L11,L12,L21,L22,R11,R12,R21,R22长度不再大于2,直接返回原列表,
分别成对将【L11, L12】送入merge函数,此时L11和L12都不为空,判断L11[0] 大于L12[0],result 增加L12[0] = [4],L12为空,result 增加L11[0],=[4, 5], L11为空。
同理将【L21,L22】、【R11,R12】、【R21,R22】送入merge函数,分别得到排好序的result为[7, 9]、[3, 8]、[1, 2]。
将【4,5】和【7,9】送入merge函数,得到排好序的result为[4, 5, 7, 9],
将【3,8】和【1,2】送入merge函数,得到排好序的result为[1, 2, 3, 8],
将【4,5,7,9】和【1,2,3,8】送入merge函数,得到排好序的result为[1,2,3,4,5,6,8,9]。
最终排序完的结果为[1,2,3,4,5,6,8,9]。
二、快速排序
快速排序的方法是,首先挑出一个元素作为基准,通常采用第一个元素作为基准,重新排序,使得比基准小的值都在基准左边,比基准大的值都在基准右边,这样基准的位置就确定了,进而递归的把左右两边的子序列进行排序,得到最后的排序结果。
快速排序同样是采用分而治之的策略,将一个列表细分成2个列表,本质上是在冒泡排序基础上的递归应用,和冒泡排序相比其每次交换是跳跃式的,而冒泡排序只是交换相邻数,总的比较和交换次数减少,速度提高。在最坏的情况下,仍然需要交换相邻的数,此时最差时间复杂度和冒泡排序是一样的O(n^2),平均时间复杂度为O(nlog2n)。
Python代码:
def quickSort(arr, left=None, right=None):
left = 0 if not isinstance(left,(int, float)) else left
right = len(arr)-1 if not isinstance(right,(int, float)) else right
if left < right:
partitionIndex = partition(arr, left, right)
quickSort(arr, left, partitionIndex-1)
quickSort(arr, partitionIndex+1, right)
return arr
def partition(arr, left, right):
pivot = left
index = pivot+1
i = index
while i <= right:
if arr[i] < arr[pivot]:
swap(arr, i, index)
index+=1
i+=1
swap(arr,pivot,index-1)
return index-1
def swap(arr, i, j):
arr[i], arr[j] = arr[j], arr[i]
我们用列表[6,1,2,7,9,3,4,5,10,8]为例进行快速排序,
基准为6,left为0,right为9,进入partition函数,
Index = left+1 = 1,i = index = 1,判断i=1 小于right=9,判断arr[i] = 1小于arr[0] = 6,交换arr[i] 和arr[index],列表不变,
Index = index + 1 = 2,i = i + 1 = 2,判断i=2小于right=9,判断arr[i] = 2小于arr[0] = 6, 交换arr[i]和arr[index],列表不变
Index = index + 1 = 3,i = i + 1 = 3,判断i=3小于right=9,判断arr[i] = 7不小于arr[0] = 6,列表不变,
Index = index = 3,i = i + 1 = 4,判断i=4小于right=9,判断arr[i] = 9不小于arr[0] = 6,列表不变,
Index = index = 3,i = i + 1 = 5,判断i=5小于right=9,判断arr[i] = 3小于arr[0] = 6, 交换arr[i=5]和arr[index=3],列表变为[6,1,2,3,9,7,4,5,10,8],
Index = index + 1 = 4,i = i + 1 = 6,判断i=6小于right=9,判断arr[i] = 4小于arr[0] = 6, 交换arr[i=6]和arr[index=4],列表变为[6,1,2,3,4,7,9,5,10,8],
Index = index + 1 = 5,i = i + 1 = 7,判断i=7小于right=9,判断arr[i] = 5小于arr[0] = 6, 交换arr[i=7]和arr[index=5],列表变为[6,1,2,3,4,5,9,7,10,8],
Index = index + 1 = 6,i = i + 1 = 8,判断i=8小于right=9,判断arr[i] = 10不小于arr[0] = 6,列表不变,
Index = index = 6,i = i + 1 = 9,判断i=9等于right=9,判断arr[i] = 8不小于arr[0] = 6,列表不变,
交换arr[0]和arr[5],列表变为[5,1,2,3,4,6,9,7,10,8],返回index-1=5此时,第一个基准6已经在准确的位置了,其左边的数都比自身小,右边的数都比自身大。
再将新的列表的左侧进行排序,列表为[5,1,2,3,4,6,9,7,10,8],基准为5,left为0,right 为partitionIndex-1=4,进入partition函数,
Index = left+1 = 1,i = index = 1,判断i=1 小于right=4,判断arr[i] = 1小于arr[0] = 5,交换arr[i] 和arr[index],列表不变,
Index = index+1 = 2,i = index = 2,判断i=2 小于right=4,判断arr[i] = 2小于arr[0] = 5,交换arr[i] 和arr[index],列表不变,
Index = index+1 = 3,i = index = 3,判断i=3 小于right=4,判断arr[i] = 3小于arr[0] = 5,交换arr[i] 和arr[index],列表不变,
Index = index+1 = 4,i = index = 4,判断i=4 等于right=4,判断arr[i] = 4小于arr[0] = 5,交换arr[i] 和arr[index],列表不变,
Index = index+1 = 5,i = index = 5,判断i=5 不小于right=4,交换arr[0] 和arr[index-1=4],列表变为[4,1,2,3,5,6,9,7,10,8],返回partitionIndex = index – 1 = 4,基准5已经在合适的位置了,其左边的数都比自身小,右边的数都比自身大。
再将新的列表的左侧进行排序,列表为[4,1,2,3,5,6,9,7,10,8],基准为4,left为0,right 为partitionIndex-1=3,进入partition函数,就这样一直递归下去直到6左侧的数据都排序后,再对6右边的数进行排序,最终得到排序后的列表为[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]。
三、堆排序
堆排序(Heapsort)是指利用堆这种数据结构所设计的一种排序算法。堆积是一个近似完全二叉树的结构,并同时满足堆积的性质:即子结点的键值或索引总是小于(或者大于)它的父节点。堆排序可以说是一种利用堆的概念来排序的选择排序。分为两种方法:
首先介绍堆概念:
1.大顶堆:每个节点的值都大于或等于其子节点的值,在堆排序算法中用于升序排列;
2.小顶堆:每个节点的值都小于或等于其子节点的值,在堆排序算法中用于降序排列;
如下图
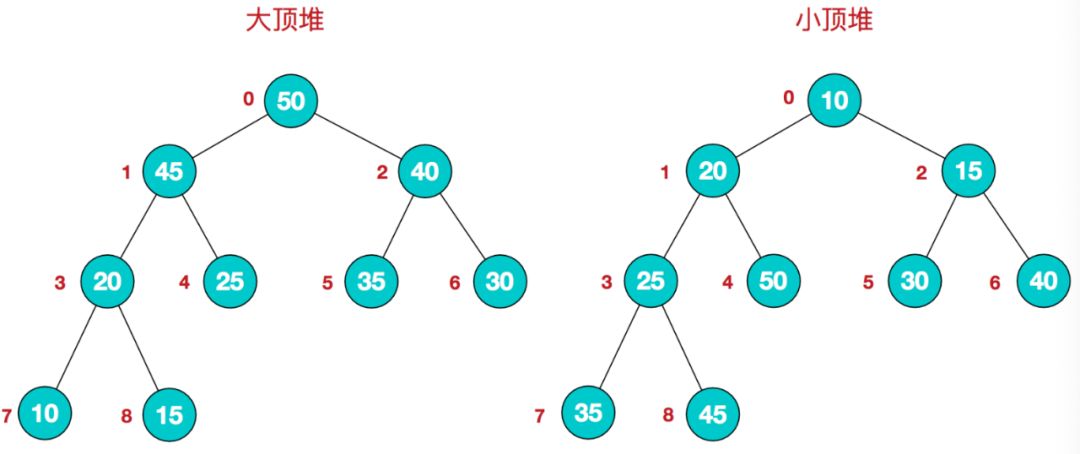
升序堆排序的思想是:将待排序序列构造成一个大顶堆,此时,整个序列的最大值就是堆顶的根节点。将其与末尾元素进行交换,此时末尾就为最大值。然后将剩余n-1个元素重新构造成一个堆,这样会得到n个元素的次小值。如此反复执行,便能得到一个有序序列了。
堆排序是一种选择排序,整体主要由构建初始堆+交换堆顶元素和末尾元素并重建堆两部分组成。其中构建初始堆经推导复杂度为O(n),在交换并重建堆的过程中,需交换n-1次,而重建堆的过程中,根据完全二叉树的性质,[log2(n-1),log2(n-2)…1]逐步递减,近似为nlogn。所以堆排序时间复杂度一般认为就是O(nlogn)级。
Python代码:
def buildMaxHeap(arr):
import math
for i in range(math.floor(len(arr)/2),-1,-1):
heapify(arr,i)
def heapify(arr, i):
left = 2*i+1
right = 2*i+2
largest = i
if left < arrLen and arr[left] > arr[largest]:
largest = left
if right < arrLen and arr[right] > arr[largest]:
largest = right
if largest != i:
swap(arr, i, largest)
heapify(arr, largest)
def swap(arr, i, j):
arr[i], arr[j] = arr[j], arr[i]
def heapSort(arr):
global arrLen
arrLen = len(arr)
buildMaxHeap(arr)
for i in range(len(arr)-1,0,-1):
swap(arr,0,i)
arrLen -=1
heapify(arr, 0)
return arr
我们用列表[4,6,8,5,9]为例,步骤一 构造初始堆。将给定无序序列构造成一个大顶堆(一般升序采用大顶堆,降序采用小顶堆)。
a. 假设给定无序序列结构如下
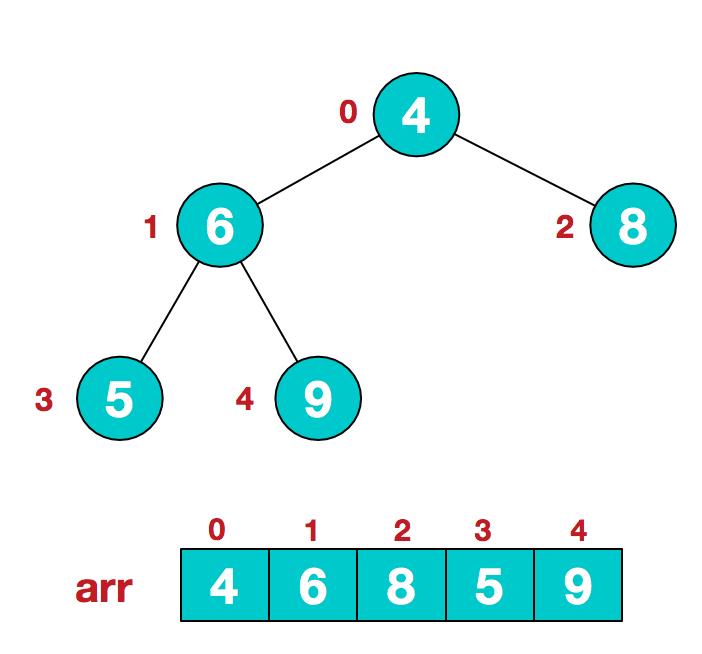
b. 此时我们从最后一个非叶子结点开始(叶结点自然不用调整,第一个非叶子结点 arr.length/2-1=5/2-1=1,也就是下面的6结点),从左至右,从下至上进行调整。
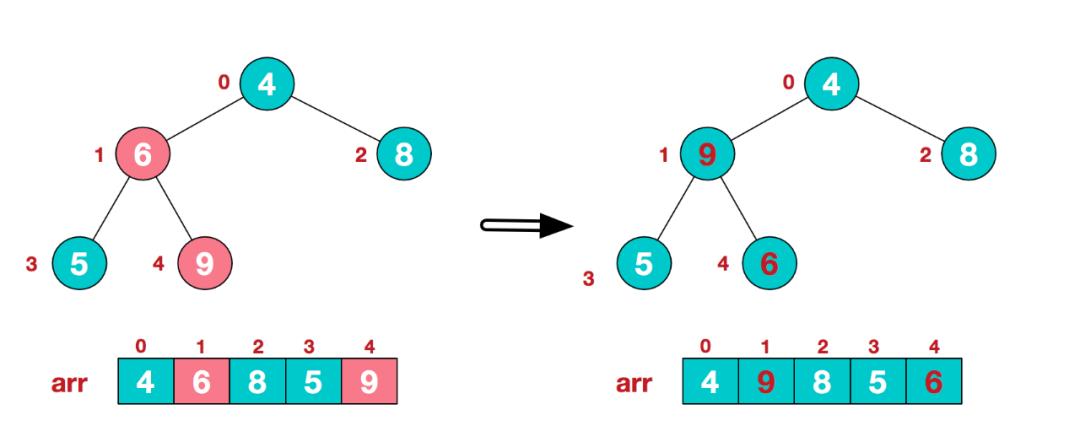
c. 找到第二个非叶节点4,由于[4,9,8]中9元素最大,4和9交换。
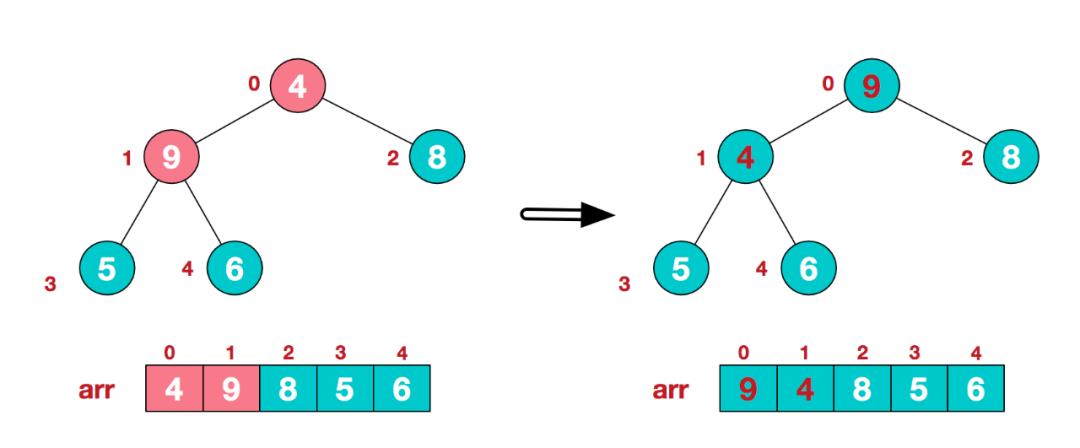
d. 这时,交换导致了子根[4,5,6]结构混乱,继续调整,[4,5,6]中6最大,交换4和6。
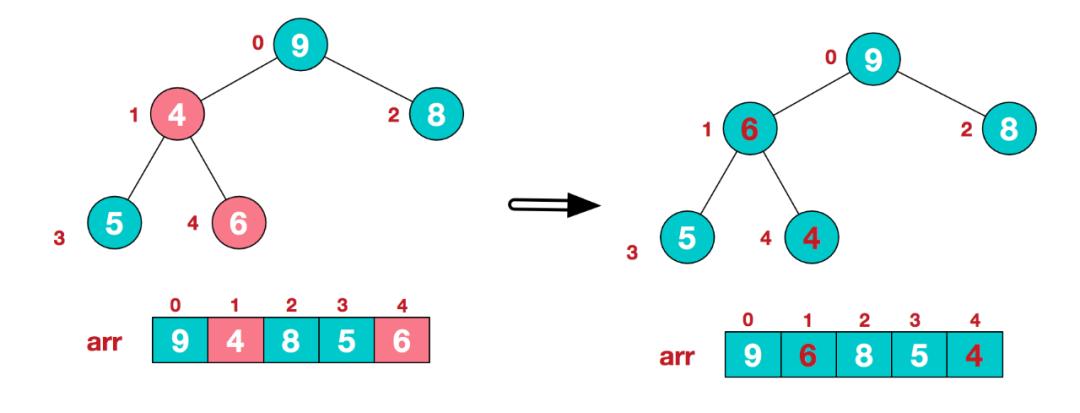
此时,我们就将一个无需序列构造成了一个大顶堆。
步骤二 将堆顶元素与末尾元素进行交换,使末尾元素最大。然后继续调整堆,再将堆顶元素与末尾元素交换,得到第二大元素。如此反复进行交换、重建、交换。
a. 将堆顶元素9和末尾元素4进行交换
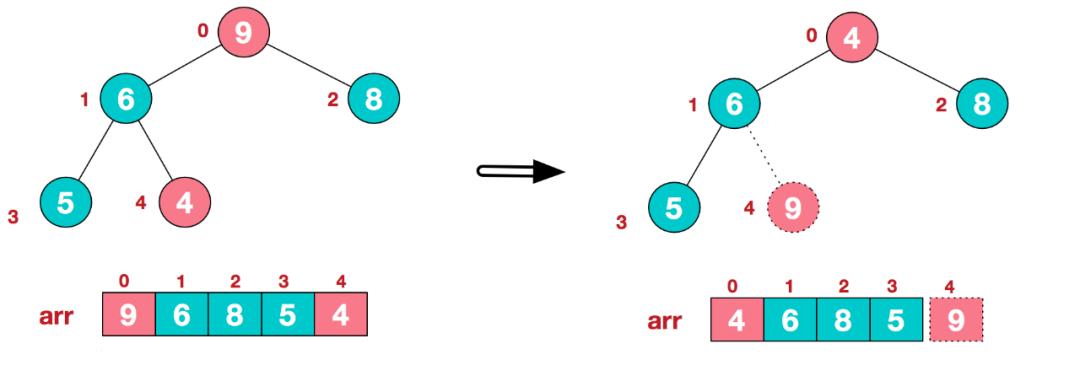
b. 重新调整结构,使其继续满足堆定义
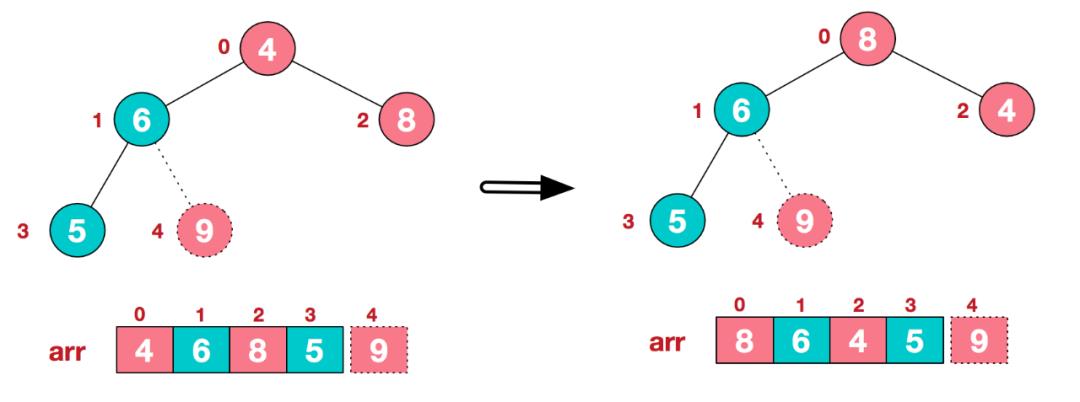
c. 再将堆顶元素8与末尾元素5进行交换,得到第二大元素8.
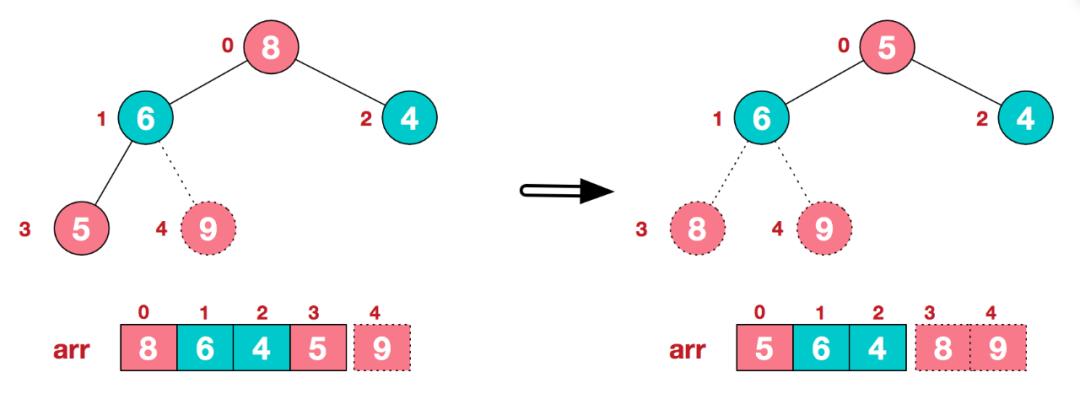
d. 后续过程,继续进行调整,交换,如此反复进行,最终使得整个序列有序
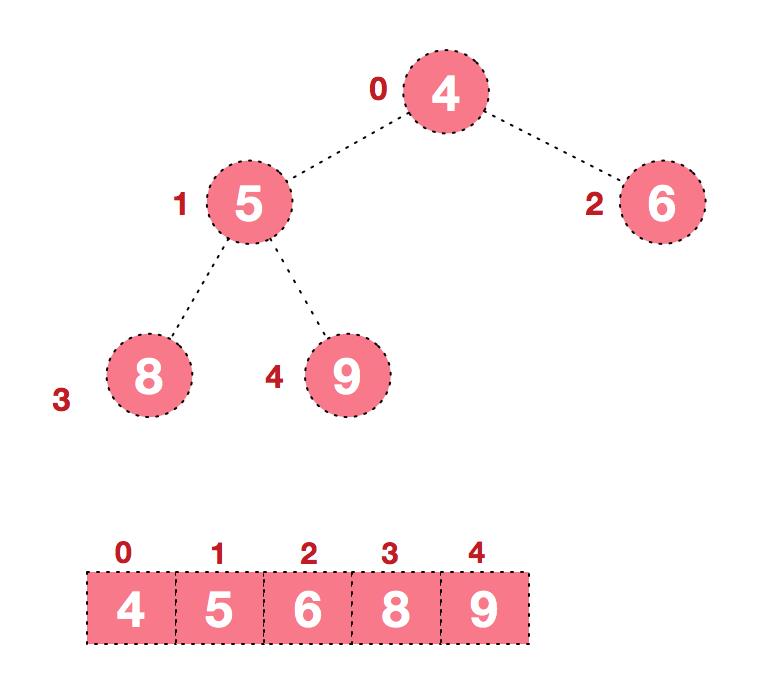
部分参考自:https://www.cnblogs.com/chengxiao/p/6129630.html
四、计数排序
计数排序过程中不存在元素之间的比较和交换操作,根据元素本身的值,将每个元素出现的次数记录到辅助空间后,通过对辅助空间内数据的计算,即可确定每一个元素最终的位置。
算法过程
1.根据待排序集合中最大元素,申请额外空间,大小为最大值 +1;
2.遍历待排序集合,将每一个元素出现的次数记录到元素值对应的额外空间内;
3.对额外空间内数据进行计算,得出每一个元素的正确位置;
4.将待排序集合每一个元素移动到计算得出的正确位置上。
Python代码:
def countingSort(arr, maxValue):
bucketLen = maxValue+1
bucket = [0]*bucketLen
sortedIndex =0
arrLen = len(arr)
for i in range(arrLen):
if not bucket[arr[i]]:
bucket[arr[i]]=0
bucket[arr[i]]+=1
for j in range(bucketLen):
while bucket[j]>0:
arr[sortedIndex] = j
sortedIndex+=1
bucket[j]-=1
return arr
假设带排序列表为[0,2,5,3,7,9,10,3,7,6],图例如下:
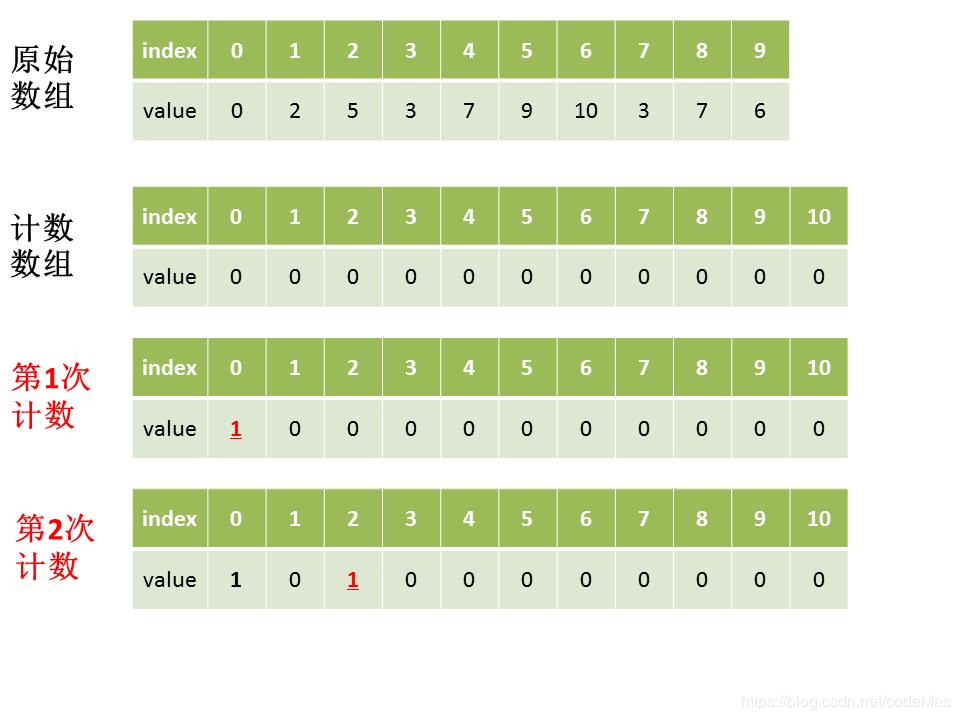
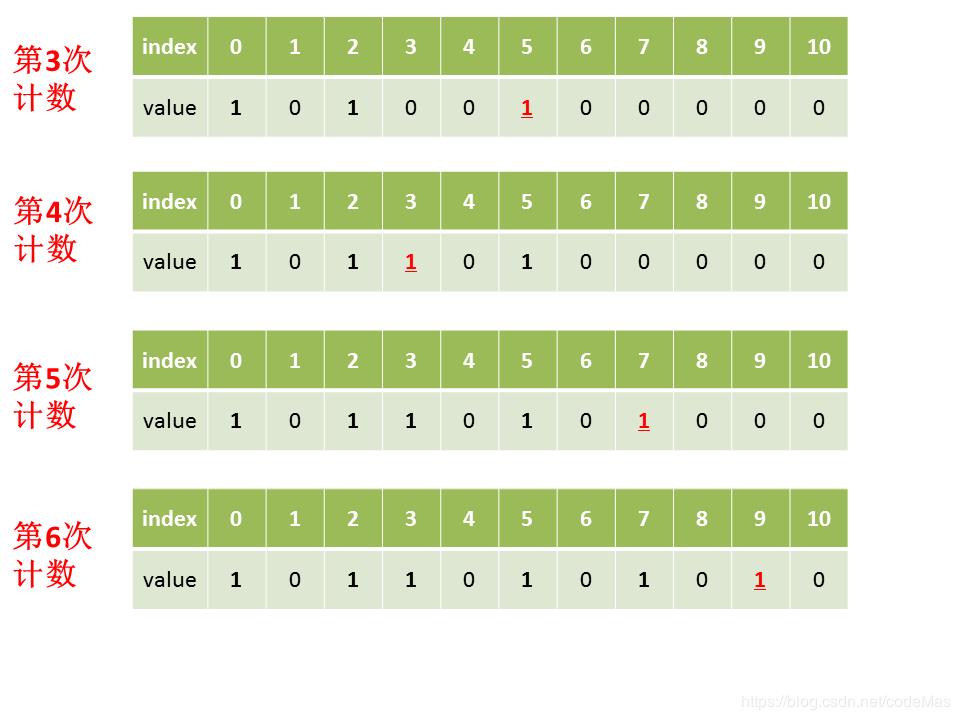
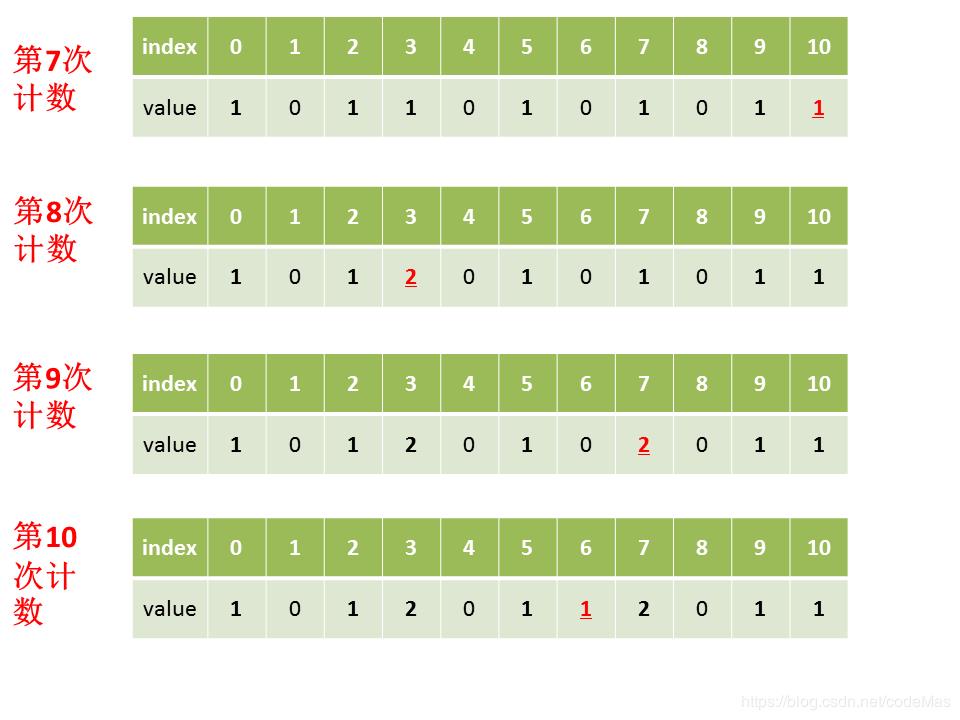
最终按顺序将value对应数量的index排列可得[0,2,3,3,5,6,7,7,9,10]
在列表取值范围不是很大的时候,其性能要比O(nlogn)更快。
但计数排序也有明显的缺点:当列表最大值和最小值差距过大时,需要创建的额外空间过大,造成时间复杂度和空间复杂度很高,不适用;当列表元素不只是整数时,无法创建对应的额外空间,也就不能用计数排序了。
五、桶排序
桶排序是计数排序的升级版,利用了函数映射关系,通过映射关系将输入的N个数据均匀的分配给K个桶里。桶排序解决了计数排序无法处理小数的问题。
为避免列表最小值很大,最大值更大的情况,如[99,100,103,105],桶排序的申请额外空间,大小为最大值-最小值 +1,向桶数组填数时不再是一个桶一个数,而是相近的几个数,之后对每个桶进行排序后得到最终排序结果。由算法过程可知,桶排序的时间复杂度为
其中M表示桶的个数。由于需要申请额外的空间来保存元素,并申请额外的数组来存储每个桶,所以空间复杂度为O(N+M)。算法的稳定性取决于对桶中元素排序时选择的排序算法。由桶排序的过程可知,当待排序集合中存在元素值相差较大时,对映射规则的选择是一个挑战,可能导致元素集中分布在某一个桶中或者绝大多数桶是空桶的现象,对算法的时间复杂度或空间复杂度有较大影响,所以同计数排序一样,桶排序适用于元素值分布较为集中的序列。
Python代码:
def bucket_sort(s):
"""桶排序"""
min_num = min(s)#2
max_num = max(s)#8
# 桶的大小
bucket_range = (max_num-min_num) / len(s)
# 桶数组6/8
count_list = [ [] for i in range(len(s) + 1)]
# 向桶数组填数
for i in s:
print(int((i-min_num)//bucket_range), i)
count_list[int((i-min_num)//bucket_range)].append(i)
print('count_list', count_list)
s.clear()
# 回填,这里桶内部排序直接调用了sorted
for i in count_list:
for j in sorted(i):
s.append(j)
六、基数排序
基数排序(Radix Sort)是桶排序的扩展,它的基本思想是:将整数按位数切割成不同的数字,然后按每个位数分别比较。
具体做法是:将所有待比较数值统一为同样的数位长度,数位较短的数前面补零。然后,从最低位开始,依次进行一次排序。这样从最低位排序一直到最高位排序完成以后, 数列就变成一个有序序列。时间复杂度:O(n*k),空间复杂度:O(n+k)。
通过基数排序对数组{53, 3, 542, 748, 14, 214, 154, 63, 616},它的示意图如下:
Python代码:
def RadixSort(list):
i = 0 #初始为个位排序
n = 1 #最小的位数置为1(包含0)
max_num = max(list) #得到排序数组中最大数
while max_num > 10**n: #得到最大数是几位数
n += 1
while i < n:
bucket = {} #用字典构建桶
for x in range(10):
bucket.setdefault(x, []) #将每个桶置空
for x in list: #对每一位进行排序
radix =int((x / (10**i)) % 10) #得到每位的基数
bucket[radix].append(x) #将对应的数组元素加入到相 #应位基数的桶中
j = 0
for k in range(10):
if len(bucket[k]) != 0: #若桶不为空
for y in bucket[k]: #将该桶中每个元素
list[j] = y #放回到数组中
j += 1
i += 1
return list以上是关于归并排序和快速排序的主要内容,如果未能解决你的问题,请参考以下文章