GoLang协程与通道---上
Posted 大忽悠爱忽悠
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了GoLang协程与通道---上相关的知识,希望对你有一定的参考价值。
GoLang协程与通道--上
协程(goroutine)与通道(channel)
作为一门 21 世纪的语言,Go 原生支持应用之间的通信(网络,客户端和服务端,分布式计算)和程序的并发。程序可以在不同的处理器和计算机上同时执行不同的代码段。Go 语言为构建并发程序的基本代码块是 协程 (goroutine) 与通道 (channel)。他们需要语言,编译器,和runtime的支持。Go 语言提供的垃圾回收器对并发编程至关重要。
不要通过共享内存来通信,而通过通信来共享内存。
通信强制协作。
并发、并行和协程
什么是协程
一个应用程序是运行在机器上的一个进程;进程是一个运行在自己内存地址空间里的独立执行体。一个进程由一个或多个操作系统线程组成,这些线程其实是共享同一个内存地址空间的一起工作的执行体。几乎所有’正式’的程序都是多线程的,以便让用户或计算机不必等待,或者能够同时服务多个请求(如 Web 服务器),或增加性能和吞吐量(例如,通过对不同的数据集并行执行代码)。一个并发程序可以在一个处理器或者内核上使用多个线程来执行任务,但是只有同一个程序在某个时间点同时运行在多核或者多处理器上才是真正的并行。
并行是一种通过使用多处理器以提高速度的能力。所以并发程序可以是并行的,也可以不是。
公认的,使用多线程的应用难以做到准确,最主要的问题是内存中的数据共享,它们会被多线程以无法预知的方式进行操作,导致一些无法重现或者随机的结果(称作 竞态)。
不要使用全局变量或者共享内存,它们会给你的代码在并发运算的时候带来危险。
解决之道在于同步不同的线程,对数据加锁,这样同时就只有一个线程可以变更数据。在 Go 的标准库 sync 中有一些工具用来在低级别的代码中实现加锁;不过过去的软件开发经验告诉我们这会带来更高的复杂度,更容易使代码出错以及更低的性能,所以这个经典的方法明显不再适合现代多核/多处理器编程:thread-per-connection 模型不够有效。
Go 更倾向于其他的方式,在诸多比较合适的范式中,有个被称作 Communicating Sequential Processes(顺序通信处理)(CSP, C. Hoare 发明的)还有一个叫做 message passing-model(消息传递)(已经运用在了其他语言中,比如 Erlang)。
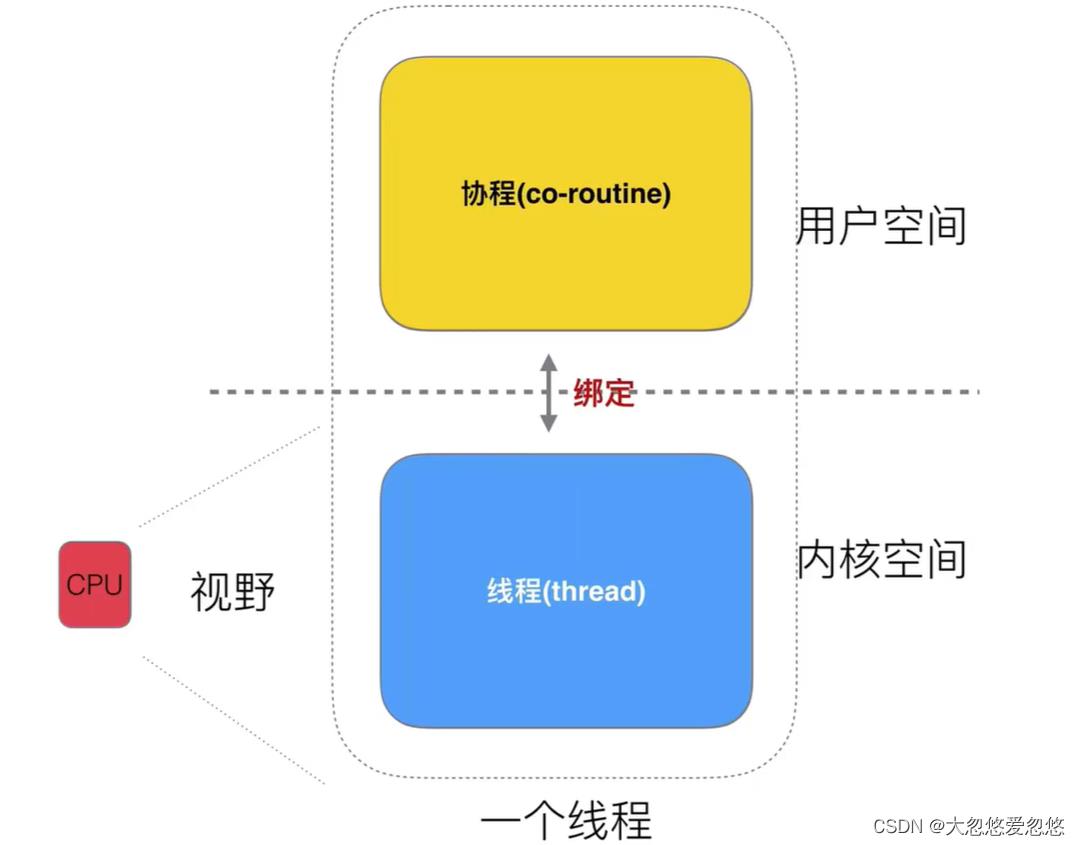
在 Go 中,应用程序并发处理的部分被称作 goroutines(协程),它可以进行更有效的并发运算。在协程和操作系统线程之间并无一对一的关系:协程是根据一个或多个线程的可用性,映射(多路复用,执行于)在他们之上的;协程调度器在 Go 运行时很好的完成了这个工作。
协程工作在相同的地址空间中,所以共享内存的方式一定是同步的;这个可以使用 sync 包来实现,不过我们很不鼓励这样做:Go 使用 channels 来同步协程
当系统调用(比如等待 I/O)阻塞协程时,其他协程会继续在其他线程上工作。协程的设计隐藏了许多线程创建和管理方面的复杂工作。
协程是轻量的,比线程更轻。它们痕迹非常不明显(使用少量的内存和资源):使用 4K 的栈内存就可以在堆中创建它们。因为创建非常廉价,必要的时候可以轻松创建并运行大量的协程(在同一个地址空间中 100,000 个连续的协程)。并且它们对栈进行了分割,从而动态的增加(或缩减)内存的使用;栈的管理是自动的,但不是由垃圾回收器管理的,而是在协程退出后自动释放。
协程可以运行在多个操作系统线程之间,也可以运行在线程之内,让你可以很小的内存占用就可以处理大量的任务。由于操作系统线程上的协程时间片,你可以使用少量的操作系统线程就能拥有任意多个提供服务的协程,而且 Go 运行时可以聪明的意识到哪些协程被阻塞了,暂时搁置它们并处理其他协程。
存在两种并发方式:确定性的(明确定义排序)和非确定性的(加锁/互斥从而未定义排序)。Go 的协程和通道理所当然的支持确定性的并发方式(例如通道具有一个 sender 和一个 receiver)。
协程是通过使用关键字 go 调用(执行)一个函数或者方法来实现的(也可以是匿名或者 lambda 函数)。这样会在当前的计算过程中开始一个同时进行的函数,在相同的地址空间中并且分配了独立的栈,比如:go sum(bigArray),在后台计算总和。
协程的栈会根据需要进行伸缩,不出现栈溢出;开发者不需要关心栈的大小。当协程结束的时候,它会静默退出:用来启动这个协程的函数不会得到任何的返回值。
任何 Go 程序都必须有的 main() 函数也可以看做是一个协程,尽管它并没有通过 go 来启动。协程可以在程序初始化的过程中运行(在 init() 函数中)。
在一个协程中,比如它需要进行非常密集的运算,你可以在运算循环中周期的使用 runtime.Gosched():这会让出处理器,允许运行其他协程;它并不会使当前协程挂起,所以它会自动恢复执行。使用 Gosched() 可以使计算均匀分布,使通信不至于迟迟得不到响应。
并发和并行的差异
Go 的并发原语提供了良好的并发设计基础:表达程序结构以便表示独立地执行的动作;所以Go的重点不在于并行的首要位置:并发程序可能是并行的,也可能不是。并行是一种通过使用多处理器以提高速度的能力。但往往是,一个设计良好的并发程序在并行方面的表现也非常出色。
在当前的运行时(2012 年一月)实现中,Go 默认没有并行指令,只有一个独立的核心或处理器被专门用于 Go 程序,不论它启动了多少个协程;所以这些协程是并发运行的,但他们不是并行运行的:同一时间只有一个协程会处在运行状态。
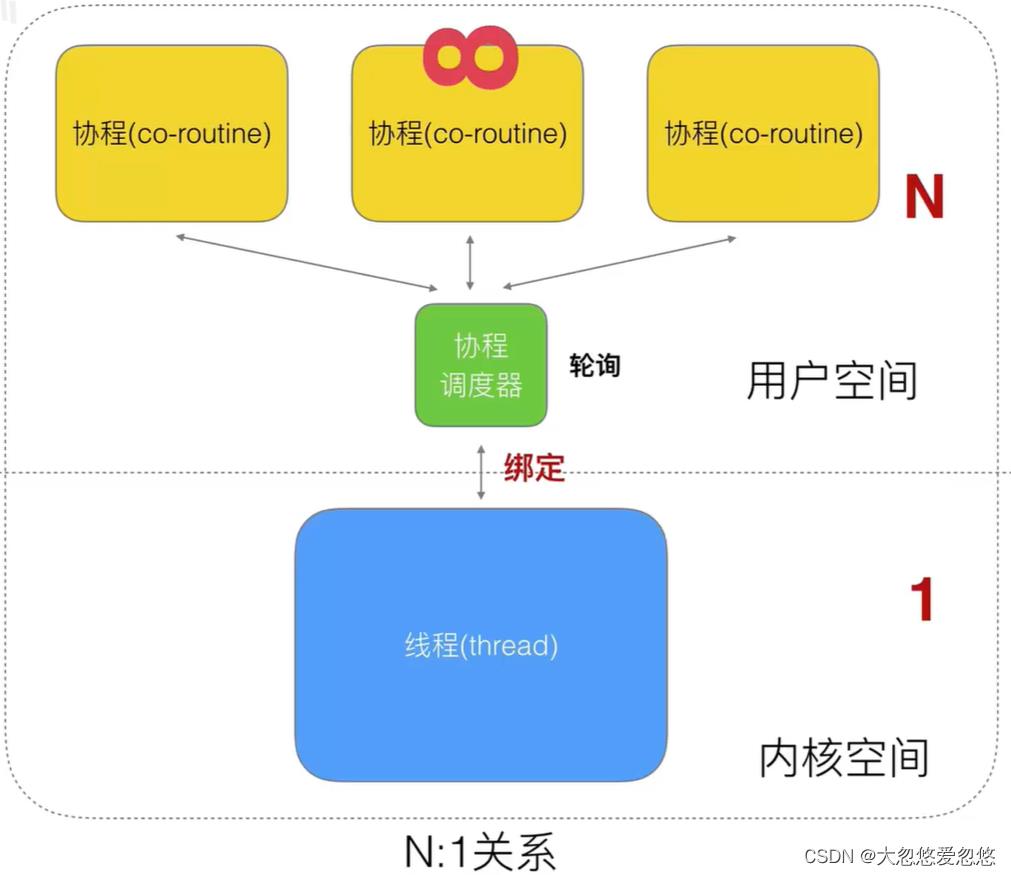
这个情况在以后可能会发生改变,不过届时,为了使你的程序可以使用多个核心运行,这时协程就真正的是并行运行了,你必须使用 GOMAXPROCS 变量。
这会告诉运行时有多少个协程同时执行。
并且只有 gc 编译器真正实现了协程,适当的把协程映射到操作系统线程。使用 gccgo 编译器,会为每一个协程创建操作系统线程。
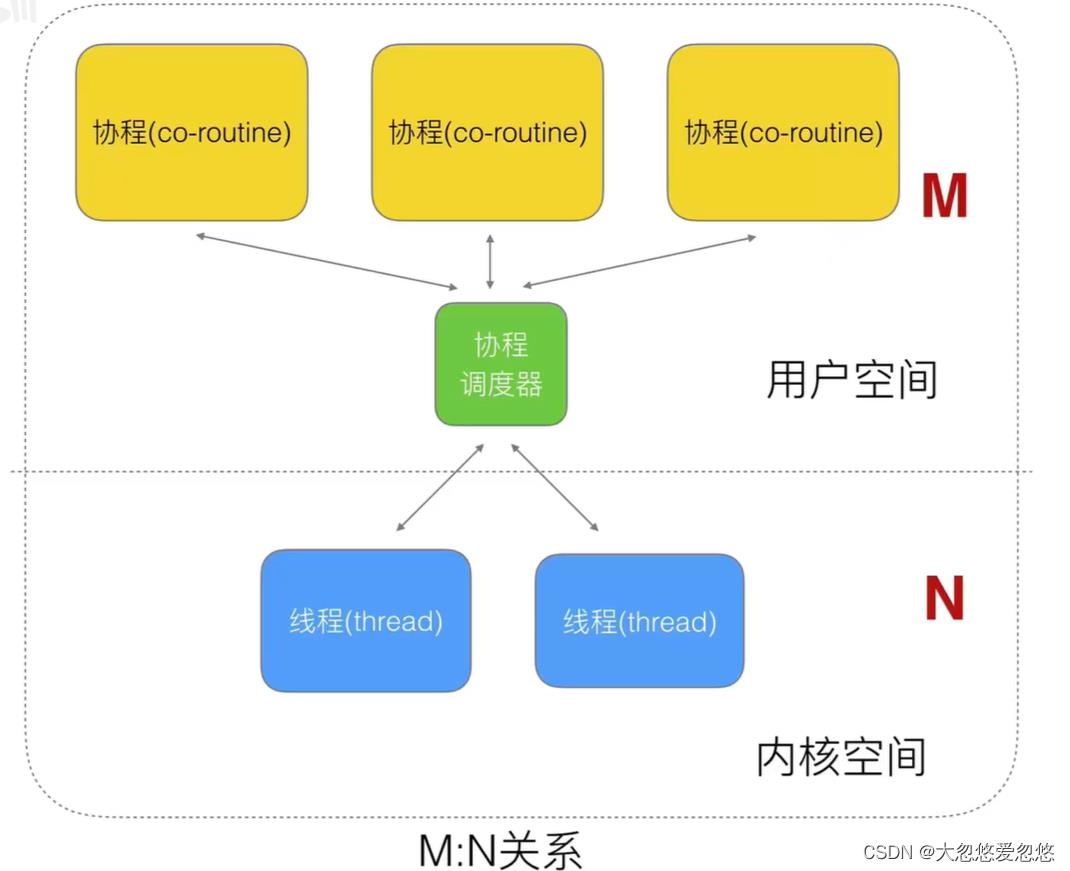
使用 GOMAXPROCS
在 gc 编译器下(6g 或者 8g)你必须设置 GOMAXPROCS 为一个大于默认值 1 的数值来允许运行时支持使用多于 1 个的操作系统线程,所有的协程都会共享同一个线程除非将 GOMAXPROCS 设置为一个大于 1 的数。
当 GOMAXPROCS 大于 1 时,会有一个线程池管理许多的线程。通过 gccgo 编译器 GOMAXPROCS 有效的与运行中的协程数量相等。
假设 n 是机器上处理器或者核心的数量。如果你设置环境变量 GOMAXPROCS>=n,或者执行 runtime.GOMAXPROCS(n),接下来协程会被分割(分散)到 n 个处理器上。更多的处理器并不意味着性能的线性提升。有这样一个经验法则,对于 n 个核心的情况设置 GOMAXPROCS 为 n-1 以获得最佳性能,也同样需要遵守这条规则:协程的数量 > 1 + GOMAXPROCS > 1。
所以如果在某一时间只有一个协程在执行,不要设置 GOMAXPROCS!
还有一些通过实验观察到的现象:在一台 1 颗 CPU 的笔记本电脑上,增加 GOMAXPROCS 到 9 会带来性能提升。在一台 32 核的机器上,设置 GOMAXPROCS=8 会达到最好的性能,在测试环境中,更高的数值无法提升性能。如果设置一个很大的 GOMAXPROCS 只会带来轻微的性能下降;设置 GOMAXPROCS=100,使用 top 命令和 H 选项查看到只有 7 个活动的线程。
增加 GOMAXPROCS 的数值对程序进行并发计算是有好处的;
总结:GOMAXPROCS 等同于(并发的)线程数量,在一台核心数多于1个的机器上,会尽可能有等同于核心数的线程在并行运行。
不理解操作系统进程和线程实现的,可以看一下下面这篇文章:
如何用命令行指定使用的核心数量
使用 flags 包,如下:
var numCores = flag.Int("n", 2, "number of CPU cores to use")
在 main() 中:
flag.Parse()
runtime.GOMAXPROCS(*numCores)
协程可以通过调用runtime.Goexit()来停止,尽管这样做几乎没有必要。
当 main() 函数返回的时候,程序退出:它不会等待任何其他非 main 协程的结束。这就是为什么在服务器程序中,每一个请求都会启动一个协程来处理,server() 函数必须保持运行状态。通常使用一个无限循环来达到这样的目的。
另外,协程是独立的处理单元,一旦陆续启动一些协程,你无法确定他们是什么时候真正开始执行的。你的代码逻辑必须独立于协程调用的顺序。
Go 协程(goroutines)和协程(coroutines)
在其他语言中,比如 C#,Lua 或者 Python 都有协程的概念。这个名字表明它和 Go协程有些相似,不过有两点不同:
- Go 协程意味着并行(或者可以以并行的方式部署),协程一般来说不是这样的
- Go 协程通过通道来通信;协程通过让出和恢复操作来通信
Go 协程比协程更强大,也很容易从协程的逻辑复用到 Go 协程。
协程间的信道
概念
协程之间必须通信才会变得更有用:彼此之间发送和接收信息并且协调/同步他们的工作。协程可以使用共享变量来通信,但是很不提倡这样做,因为这种方式给所有的共享内存的多线程都带来了困难。
而 Go 有一种特殊的类型,通道(channel),就像一个可以用于发送类型化数据的管道,由其负责协程之间的通信,从而避开所有由共享内存导致的陷阱;这种通过通道进行通信的方式保证了同步性。数据在通道中进行传递:在任何给定时间,一个数据被设计为只有一个协程可以对其访问,所以不会发生数据竞争。 数据的所有权(可以读写数据的能力)也因此被传递。
工厂的传送带是个很有用的例子。一个机器(生产者协程)在传送带上放置物品,另外一个机器(消费者协程)拿到物品并打包。
通道服务于通信的两个目的:值的交换,同步的,保证了两个计算(协程)任何时候都是可知状态。
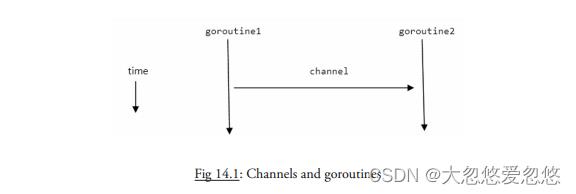
通常使用这样的格式来声明通道:var identifier chan datatype
未初始化的通道的值是nil。
所以通道只能传输一种类型的数据,比如 chan int 或者 chan string,所有的类型都可以用于通道,空接口 interface 也可以。甚至可以(有时非常有用)创建通道的通道。
通道实际上是类型化消息的队列:使数据得以传输。它是先进先出(FIFO)的结构所以可以保证发送给他们的元素的顺序(有些人知道,通道可以比作 Unix shells 中的双向管道(two-way pipe))。通道也是引用类型,所以我们使用 make() 函数来给它分配内存。这里先声明了一个字符串通道 ch1,然后创建了它(实例化):
var ch1 chan string
ch1 = make(chan string)
当然可以更短: ch1 := make(chan string)。
这里我们构建一个int通道的通道: chanOfChans := make(chan int)。
或者函数通道:funcChan := make(chan func())。
所以通道是第一类对象:可以存储在变量中,作为函数的参数传递,从函数返回以及通过通道发送它们自身。另外它们是类型化的,允许类型检查,比如尝试使用整数通道发送一个指针。
通信操作符 <-
这个操作符直观的标示了数据的传输:信息按照箭头的方向流动。
流向通道(发送)
ch <- int1 表示:用通道 ch 发送变量 int1(双目运算符,中缀 = 发送)
从通道流出(接收),三种方式:
int2 = <- ch 表示:变量 int2 从通道 ch(一元运算的前缀操作符,前缀 = 接收)接收数据(获取新值);假设 int2 已经声明过了,如果没有的话可以写成:int2 := <- ch。
<- ch 可以单独调用获取通道的(下一个)值,当前值会被丢弃,但是可以用来验证,所以以下代码是合法的:
if <- ch != 1000
...
同一个操作符 <- 既用于发送也用于接收,但Go会根据操作对象弄明白该干什么 。虽非强制要求,但为了可读性通道的命名通常以 ch 开头或者包含 chan。通道的发送和接收都是原子操作:它们总是互不干扰的完成的。下面的示例展示了通信操作符的使用。
package main
import (
"fmt"
"time"
)
func main()
ch := make(chan string)
go sendData(ch)
go getData(ch)
time.Sleep(1e9)
func sendData(ch chan string)
ch <- "Washington"
ch <- "Tripoli"
ch <- "London"
ch <- "Beijing"
ch <- "Tokyo"
func getData(ch chan string)
var input string
// time.Sleep(2e9)
for
input = <-ch
fmt.Printf("%s ", input)
输出:
Washington Tripoli London Beijing tokyo
如果 2 个协程需要通信,你必须给他们同一个通道作为参数才行。
尝试一下如果注释掉 time.Sleep(1e9) 会如何。
当 main() 函数返回的时候,程序退出:它不会等待任何其他非 main 协程的结束。这就是为什么在服务器程序中,每一个请求都会启动一个协程来处理,server() 函数必须保持运行状态。通常使用一个无限循环来达到这样的目的。
我们发现协程之间的同步非常重要:
- main() 等待了 1 秒让两个协程完成,如果不这样,sendData() 就没有机会输出。
- getData() 使用了无限循环:它随着 sendData() 的发送完成和 ch 变空也结束了。
- 如果我们移除一个或所有 go 关键字,程序无法运行,Go 运行时会抛出 panic:
---- Error run E:/Go/Goboek/code examples/chapter 14/goroutine2.exe with code Crashed ---- Program exited with code -2147483645: panic: all goroutines are asleep-deadlock!
为什么会这样?运行时(runtime)会检查所有的协程(像本例中只有一个)是否在等待着什么东西(可从某个通道读取或者写入某个通道),这意味着程序将无法继续执行。这是死锁(deadlock)的一种形式,而运行时(runtime)可以为我们检测到这种情况。
注意:不要使用打印状态来表明通道的发送和接收顺序:由于打印状态和通道实际发生读写的时间延迟会导致和真实发生的顺序不同。
channel有缓冲和无缓冲同步问题
无缓冲的channel
默认情况下,通信是同步且无缓冲的:
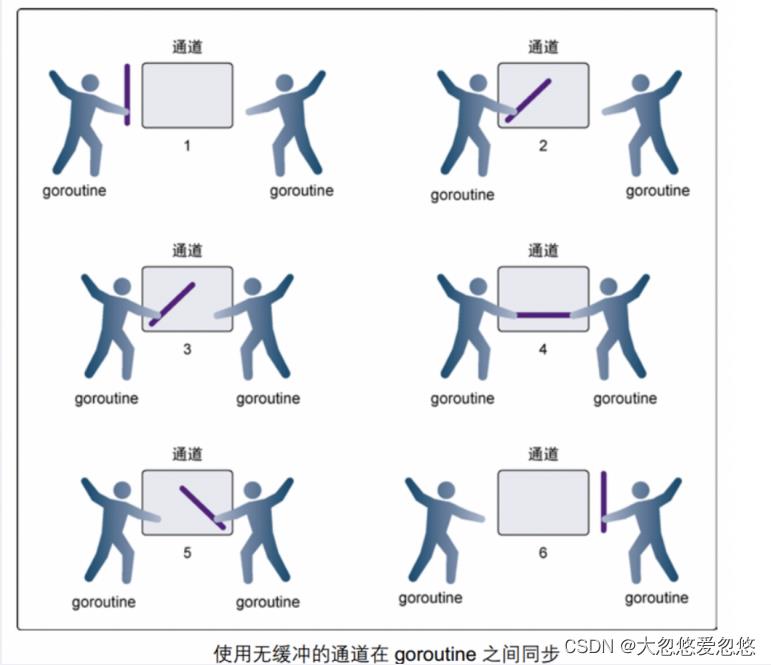
- 在第 1 步,两个 goroutine 都到达通道,但哪个都没有开始执⾏发送或者接收。
- 在第 2 步,左侧的 goroutine 将它的⼿伸进了通道,这模拟了向通道发送数据的⾏为。这时,这个 goroutine会在通道中被锁住,直到交换完成。
- 在第 3 步,右侧的 goroutine 将它的⼿放⼊通道,这模拟了从通道⾥接收数据。这个 goroutine ⼀样也会在通道中被锁住,直到交换完成.
- 在第 4 步和第 5 步,进⾏交换,并最终,在第 6 步,两个 goroutine 都将它们的⼿从通道⾥拿出来,这模拟了被锁住的
goroutine 得到释放。两个 goroutine 现在都可以去做其他事情了
有缓冲的Channel
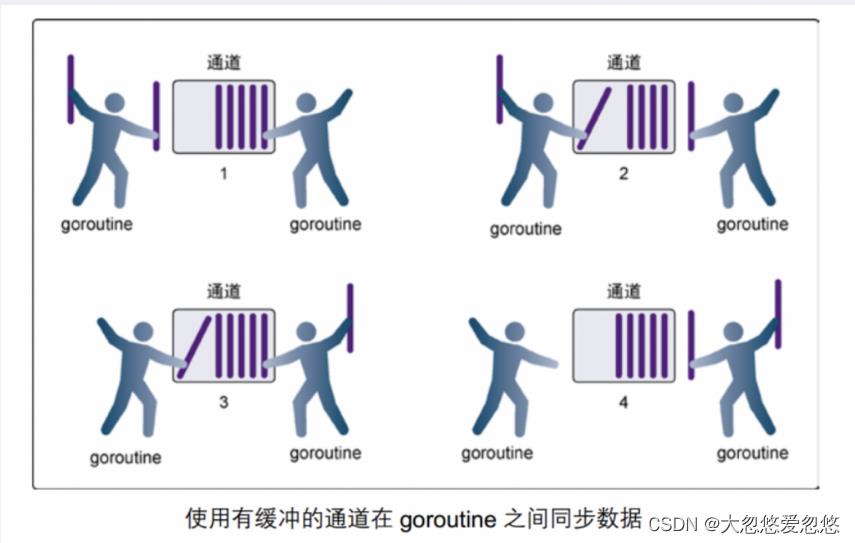
- 在第 1 步,右侧的 goroutine 正在从通道接收⼀个值
- 在第 2 步,右侧的这个 goroutine独⽴完成了接收值的动作,⽽左侧的 goroutine 正在发送⼀个新值到通道⾥
- 在第 3 步,左侧的goroutine 还在向通道发送新值,⽽右侧的 goroutine正在从通道接收另外⼀个值。这个步骤⾥的两个操作既不是同步的,也不会互相阻塞
- 最后,在第 4 步,所有的发送和接收都完成,⽽通道⾥还有⼏个值,也有⼀些空间可以存更多的值
特点
- 当channel已经满,再向⾥⾯写数据,就会阻塞
- 当channel为空,从⾥⾯取数据也会阻塞
可以将无缓冲的通道,看做是容量为0的有缓冲通道特例
了解了有缓冲和无缓冲通道的特点后,相信各位也就明白了为什么会有上面的死锁问题发生了,还不明白,可以看下面这个例子:
package main
import "fmt"
func main()
ch1 := make(chan int)
go pump(ch1)
fmt.Println(<-ch1)
fmt.Println(<-ch1)
func pump(ch chan int)
ch <- 1

当程序检测到目前存活的goroutine都处于阻塞状态时,说明出现死锁,注意: main函数被执行也是由goroutine完成的
package main
import (
"fmt"
"time"
)
func main()
ch1 := make(chan int)
go pump(ch1)
go test(ch1)
time.Sleep(3 * time.Second)
func test(ch1 chan int)
fmt.Println(<-ch1)
fmt.Println(<-ch1)
func pump(ch chan int)
ch <- 1
下面这种就不会出现死锁,因为main程序会一直存活直到睡眠结束
信号量模式
下边的片段阐明:协程通过在通道 ch 中放置一个值来处理结束的信号。main 协程等待 <-ch 直到从中获取到值。
我们期望从这个通道中获取返回的结果,像这样:
func compute(ch chan int)
ch <- someComputation() // when it completes, signal on the channel.
func main()
ch := make(chan int) // allocate a channel.
go compute(ch) // start something in a goroutines
doSomethingElseForAWhile()
result := <- ch
这个信号也可以是其他的,不返回结果,比如下面这个协程中的匿名函数(lambda)协程:
ch := make(chan int)
go func()
// doSomething
ch <- 1 // Send a signal; value does not matter
()
doSomethingElseForAWhile()
<- ch // Wait for goroutine to finish; discard sent value.
或者等待两个协程完成,每一个都会对切片s的一部分进行排序,片段如下:
done := make(chan bool)
// doSort is a lambda function, so a closure which knows the channel done:
doSort := func(s []int)
sort(s)
done <- true
i := pivot(s)
go doSort(s[:i])
go doSort(s[i:])
<-done
<-done
下边的代码,用完整的信号量模式对长度为N的 float64 切片进行了 N 个doSomething() 计算并同时完成,通道 sem 分配了相同的长度(且包含空接口类型的元素),待所有的计算都完成后,发送信号(通过放入值)。在循环中从通道 sem 不停的接收数据来等待所有的协程完成。
type Empty interface
var empty Empty
...
data := make([]float64, N)
res := make([]float64, N)
sem := make(chan Empty, N)
...
for i, xi := range data
go func (i int, xi float64)
res[i] = doSomething(i, xi)
sem <- empty
(i, xi)
// wait for goroutines to finish
for i := 0; i < N; i++ <-sem
注意上述代码中闭合函数的用法:i、xi 都是作为参数传入闭合函数的,这一做法使得每个协程在其启动时获得一份 i 和 xi 的单独拷贝,从而向闭合函数内部屏蔽了外层循环中的 i 和 xi变量;否则,for 循环的下一次迭代会更新所有协程中 i 和 xi 的值。另一方面,切片 res 没有传入闭合函数,因为协程不需要res的单独拷贝。切片 res 也在闭合函数中但并不是参数。
实现并行的 for 循环
for i, v := range data
go func (i int, v float64)
doSomething(i, v)
...
(i, v)
在 for 循环中并行计算迭代可能带来很好的性能提升。不过所有的迭代都必须是独立完成的。有些语言比如 Fortress 或者其他并行框架以不同的结构实现了这种方式,在 Go 中用协程实现起来非常容易:
用带缓冲通道实现一个信号量
信号量是实现互斥锁(排外锁)常见的同步机制,限制对资源的访问,解决读写问题,比如没有实现信号量的 sync 的 Go 包,使用带缓冲的通道可以轻松实现:
- 带缓冲通道的容量和要同步的资源容量相同
- 通道的长度(当前存放的元素个数)与当前资源被使用的数量相同
- 容量减去通道的长度就是未处理的资源个数(标准信号量的整数值)
不用管通道中存放的是什么,只关注长度;因此我们创建了一个长度可变但容量为0(字节)的通道:
type Empty interface
type semaphore chan Empty
将可用资源的数量N来初始化信号量 semaphore:sem = make(semaphore, N)
然后直接对信号量进行操作:
// acquire n resources
func (s semaphore) P(n int)
e := new(Empty)
for i := 0; i < n; i++
s <- e
// release n resources
func (s semaphore) V(n int)
for i:= 0; i < n; i++
<- s
可以用来实现一个互斥的例子:
/* mutexes */
func (s semaphore) Lock()
s.P(1)
func (s semaphore) Unlock()
s.V(1)
/* signal-wait */
func (s semaphore) Wait(n int)
s.P(n)
func (s semaphore) Signal()
s.V(1)
习惯用法:通道工厂模式
编程中常见的另外一种模式如下:不将通道作为参数传递给协程,而用函数来生成一个通道并返回(工厂角色);函数内有个匿名函数被协程调用。
package main
import (
"fmt"
"time"
)
func main()
stream := pump()
go suck(stream)
time.Sleep(1e9)
func pump() chan int
ch := make(chan int)
go func()
for i := 0; ; i++
ch <- i
()
return ch
func suck(ch chan int)
for
fmt.Println(<-ch)
给通道使用 for 循环
for 循环的 range 语句可以用在通道 ch 上,便可以从通道中获取值,像这样:
for v := range ch
fmt.Printf("The value is %v\\n", v)
它从指定通道中读取数据直到通道关闭,才继续执行下边的代码。很明显,另外一个协程必须写入 ch(不然代码就阻塞在 for 循环了),而且必须在写入完成后才关闭。suck 函数可以这样写,且在协程中调用这个动作,程序变成了这样:
package main
import (
"fmt"
"time"
)
func main()
suck(pump())
time.Sleep(1e9)
func pump() chan int
ch := make(chan int)
go func()
for i := 0; ; i++
ch <- i
()
return ch
func suck(ch chan int)
go func()
for v := range ch
fmt.Println(v)
()
习惯用法:通道迭代模式
这个模式用到了生产者-消费者模式,通常,需要从包含了地址索引字段 items 的容器给通道填入元素。为容器的类型定义一个方法 Iter(),返回一个只读的通道items,如下:
func (c *container) Iter () <- chan item
ch := make(chan item)
go func ()
for i:= 0; i < c.Len(); i++ // or use a for-range loop
ch <- c.items[i]
()
return ch
在协程里,一个 for 循环迭代容器 c 中的元素(对于树或图的算法,这种简单的 for 循环可以替换为深度优先搜索)。
调用这个方法的代码可以这样迭代容器:
for x := range container.Iter() ...
其运行在自己启动的协程中,所以上边的迭代用到了一个通道和两个协程(可能运行在不同的线程上)。 这样我们就有了一个典型的生产者-消费者模式。如果在程序结束之前,向通道写值的协程未完成工作,则这个协程不会被垃圾回收;这是设计使然。这种看起来并不符合预期的行为正是由通道这种线程安全的通信方式所导致的。如此一来,一个协程为了写入一个永远无人读取的通道而被挂起就成了一个bug,而并非你预想中的那样被悄悄回收掉(garbage-collected)了。
习惯用法:生产者消费者模式
假设你有 Produce() 函数来产生 Consume 函数需要的值。它们都可以运行在独立的协程中,生产者在通道中放入给消费者读取的值。整个处理过程可以替换为无限循环:
for
Consume(Produce())
通道的方向
通道类型可以用注解来表示它只发送或者只接收:
var send_only chan<- int // channel can only receive data
var recv_only <-chan int // channel can only send data
只接收的通道(<-chan T)无法关闭,因为关闭通道是发送者用来表示不再给通道发送值了,所以对只接收通道是没有意义的。通道创建的时候都是双向的,但也可以分配有方向的通道变量,就像以下代码:
var c = make(chan int) // bidirectional
go source(c)
go sink(c)
func source(ch chan<- int)
for ch <- 1
func sink(ch <-chan int)
for <-ch
习惯用法:管道和选择器模式
更具体的例子还有协程处理它从通道接收的数据并发送给输出通道:
sendChan := makeGoLang协程与通道---下