Python是不是被严重高估了?
Posted 我想去吃ya
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python是不是被严重高估了?相关的知识,希望对你有一定的参考价值。
Python起源一种shell的脚本语言 ,而现在已经发展成最通用的语言之一了,TIOBE指数的数据显示,Python是目前世界上最受欢迎的编程语言。
Python之所以这么受欢迎有很多原因。从Web开发到物联网编程再到AI等各个方面都能用到它。另外Python代码非常容易编写和执行,这使Python成为入门编程语言的首选。基本上每个在大学学习编码或者参加编程训练营的人都会学习Python。
然而Python的鼎盛时期会持续多久?虽然语言本身没有什么问题,但从某些方面来说,成为“万人迷”感到很惊讶。受到的欢迎程度远超出它所应得的,主要有以下四个原因:
一、Python速度不快
Python最大的缺陷就是用它编写的应用程序运行速度不快。至少,这些应用程序远不及用C或者Java等语言编码的应用程序快。代码可能易于编写和部署,但是我们却牺牲了速度、效率和性能。在这个分秒必争的世界里,Python显然不是一个很好的选择。
二、Python的语法过于僵化
对于编码小白来说,Python如此受欢迎的部分原因是它的语法非常具体,所以写出来的代码非常整洁而且可读性高。对于那些不介意花时间研究Python所有语法规则的人来说,Python很不错。但是如果你只是想快速生成代码,那Python并不是最好的选择。
因此,如果优先考虑灵活性或者动态性,而不是让代码看起来美观且一致,那么Python可能就不是未来最好的语言。
三、Python提供的编程语言有限
易于使用是Python受新手小白喜爱的另一大原因。但是实际上Python没有提供全面的开发体验。学习Python编码的人并没有了解传统软件开发系统的各个方面。
虽然这听起来可能有些苛刻,但是我认为知道如何用Python写代码只不过比知道如何在Bash shell中运行程序更高级一点,而Bash shell根本不算编码。从这个角度来说Python正在创造一代不知道“完整”编程的程序员,他们只知道如何编写解释型代码。
四、没有什么大型的产品是用Python写的
当环顾全球各种项目时,我发现没有任何真正大型、复杂且重要的应用程序或者平台是用Python写的。很多网站使用Python,主要是在后端,可能有数百万小型应用程序是用Python开发的。但是没有基于Python的类似WordPress的东西,没有非常依赖Python的办公生产力套件,当然也没有用Python编码的操作系统,甚至是操作系统的主要部分。
这并不是在谴责Python,只是在强调这样一个事实。如果说Python在未来几十年仍然保持顶级编程语言的地位,那么你会认为现在有人会用它做一些比编写脚本和简单应用程序更有趣的事。然而他们没有,可能也不会。
Python当然有很多用处,但主要用于编写相对简单的脚本和应用程序。所以它并不是编写所有内容的首选语言。
Python的普及与数据挖掘、人工智能和数值计算等领域的蓬勃发展相关,但同时也与普遍编程需求的增加有关。
Python应用领域广泛,意味着选择Python的同学在学成之后可选择的就业领域有很多,加上Python本身的优势,致使现在越来越多的新人开始学习这一编程语言。
Python优势明显
应用领域超多
如果要推荐一种人人都能掌握的编程语言,应该没有比Python更合适的了。
Python 简单易学,用途广泛,不仅可以在日常办公中提高大家的职场效率,还能被大型互联网企业应用于后端开发。随着大数据、人工智能等领域的快速发展,Python的应用领域也更加多了起来。
大数据开发做什么?
大数据开发分两类,编写Hadoop、Spark的应用程序和对大数据处理系统本身进行开发。大数据开发工程师主要负责公司大数据平台的开发和维护、相关工具平台的架构设计与产品开发、网络日志大数据分析、实时计算和流式计算以及数据可视化等技术的研发和网络安全业务主题建模等工作。
大数据开发应具备的技能:
目前从事大数据应用开发的语言包括Java、Python、Scala、R等,需要熟悉Hadoop、HBbase、hive、spark、Flink、ES、Presto、Flume、Kafka生态的原理和使用方法,掌握数据开发、数据挖掘的各项流程。
大数据学习路线以及资源:
开发入门:Linux入门 → mysql数据库
核心基础: Hadoop
数仓技术: Hive数仓项目
PB内存计算: Python入门 → Python进阶→ pyspark框架 → Hive+Spark项目
在选择培训机构之前,可以先学习一下大数据基础的教程,看看到底自己能不能掌握~
本套教程一网打尽了大数据必学的
Hadoop、Hive,云平台实战项目
让零基础同学一站式入门
直通大数据核心技术
这套大数据新教程基于Hadoop、Hive、云平台等技术带领大家由浅入深的进入大数据领域,一起体验大规模数据计算的魅力。
基于零基础学习的内容设计,提供了丰富的补充知识点供零基础学员进行前置学习。
作为2023年全新的大数据入门课程,课程内容采用全新的技术栈体系。基于Hadoop3.3.4、Hive 3.1.3、阿里云和UCloud云平台,为同学们打造一门大数据Hadoop生态体系的入门课程,但又不仅仅只是Hadoop。
2023新版大数据入门到实战教程,大数据开发必会的Hadoop、Hive,云平台实战项目全套一网打尽
课程特色
• 理论+实战完美结合:本套教程采用“理论+实战”的形式,全面介绍了大数据Hadoop、Hive离线开发的相关知识;
• 有内容也有深度:课程采用“入门+提高”的内容设计,入门知识和高阶知识相互独立,先全面入门,后全面进阶,循序渐进让大家学有所成;
• 结合当下热门的云平台(阿里云、UCloud)为大家带来《云原生大数据开发》:基于Hadoop3.3.4、Hive 3.1.3、阿里云和UCloud云平台,采用全新的技术栈体系。
适合人群
>零基础:小白入门到高阶,再到精通
>进阶者:有经验的工程师巩固拓展
>探索者:感兴趣者领略大数据魅力
第一阶段 大数据开发入门
学前导读:从传统关系型数据库入手,掌握数据迁移工具、BI数据可视化工具、SQL,对后续学习打下坚实基础。
1.大数据数据开发基础MySQL8.0从入门到精通
MySQL是整个IT基础课程,SQL贯穿整个IT人生,俗话说,SQL写的好,工作随便找。本课程从零到高阶全面讲解MySQL8.0,学习本课程之后可以具备基本开发所需的SQL水平。
2022最新MySQL知识精讲+mysql实战案例_零基础mysql数据库入门到高级全套教程
第二阶段 大数据核心基础
学前导读:学习Linux、Hadoop、Hive,掌握大数据基础技术。
2022版大数据Hadoop入门教程
Hadoop离线是大数据生态圈的核心与基石,是整个大数据开发的入门,是为后期的Spark、Flink打下坚实基础的课程。掌握课程三部分内容:Linux、Hadoop、Hive,就可以独立的基于数据仓库实现离线数据分析的可视化报表开发。
2022最新大数据Hadoop入门视频教程,最适合零基础自学的大数据Hadoop教程
第三阶段 千亿级数仓技术
学前导读:本阶段课程以真实项目为驱动,学习离线数仓技术。
数据离线数据仓库,企业级在线教育项目实战(Hive数仓项目完整流程)
本课程会、建立集团数据仓库,统一集团数据中心,把分散的业务数据集中存储和处理 ;目从需求调研、设计、版本控制、研发、测试到落地上线,涵盖了项目的完整工序 ;掘分析海量用户行为数据,定制多维数据集合,形成数据集市,供各个场景主题使用。
大数据项目实战教程_大数据企业级离线数据仓库,在线教育项目实战(Hive数仓项目完整流程)
第四阶段 PB内存计算
学前导读:Spark官方已经在自己首页中将Python作为第一语言,在3.2版本的更新中,高亮提示内置捆绑Pandas;课程完全顺应技术社区和招聘岗位需求的趋势,全网首家加入Python on Spark的内容。
1.python入门到精通(19天全)
python基础学习课程,从搭建环境。判断语句,再到基础的数据类型,之后对函数进行学习掌握,熟悉文件操作,初步构建面向对象的编程思想,最后以一个案例带领同学进入python的编程殿堂。
全套Python教程_Python基础入门视频教程,零基础小白自学Python必备教程
2.python编程进阶从零到搭建网站
学完本课程会掌握Python高级语法、多任务编程以及网络编程。
Python高级语法进阶教程_python多任务及网络编程,从零搭建网站全套教程
3.spark3.2从基础到精通
Spark是大数据体系的明星产品,是一款高性能的分布式内存迭代计算框架,可以处理海量规模的数据。本课程基于Python语言学习Spark3.2开发,课程的讲解注重理论联系实际,高效快捷,深入浅出,让初学者也能快速掌握。让有经验的工程师也能有所收获。
Spark全套视频教程,大数据spark3.2从基础到精通,全网首套基于Python语言的spark教程
4.大数据Hive+Spark离线数仓工业项目实战
通过大数据技术架构,解决工业物联网制造行业的数据存储和分析、可视化、个性化推荐问题。一站制造项目主要基于Hive数仓分层来存储各个业务指标数据,基于sparkSQL做数据分析。核心业务涉及运营商、呼叫中心、工单、油站、仓储物料。
全网首次披露大数据Spark离线数仓工业项目实战,Hive+Spark构建企业级大数据平台
自然语言推理数据集“人工痕迹”严重,模型性能被高估
编者按:自然语言推理所用的数据集再近年得到了研究和发展,但是在本文中,来自华盛顿大学、卡内基梅隆大学和纽约大学等机构的研究人员发现,这些数据集中不可避免出现了明显的“人工痕迹”,使得模型的表现被高估了,评估自然语言推理模型的问题仍然存在。以下是论智的编译。
自然语言推理是NLP领域被广泛研究的领域之一,有了这一技术,许多复杂的语义任务如问题回答和文本总结都能得到解决。而用于自然语言推理的大规模数据集是通过向众包工作者提供一个句子(前提)p,然后让他们创作出三个新的与之相关的句子(假设)h创造出来的。自然语言推理的目的就是判断是否能根据p的语义推断出h。我们证明,利用这种方法,使得数据中的很大一部分只需查看新生成的句子,无需看“前提”,就能了解到数据的标签。具体来说,一个简单的文本分类模型在SNLI数据集上对句子分类的正确率达到了67%,在MultiNLI上的正确率为53%。分析表明,特定的语言现象,比如否定和模糊与某些推理类别非常相关。所以这一研究表示,目前的自然语言推理模型的成功被高估了,这一问题仍然难以解决。
2015年,Bowman等人通过众包标记的方法创造了大规模推断数据集SNLI;2018年,Williams等人又推出了MultiNLI数据集。在这一过程中,研究人员从一些语料中抽取某个前提句子p,让众包标注者基于p创作三个新句子,创作的句子与p有三种关系标准:
包含(Entailment):h与p非常相关;
中立(Neutral):h与p可能相关;
矛盾(Contradiction):h与p绝对不相关。
下面是SNLI数据集中具体的例子:
在这篇论文中,我们发现,通过众包生成的句子人工痕迹太过明显,以至于分类器无需查看条件句子p就能将其正确分类。下面我们将详细讲解分析过程。
注释中的“人工痕迹”其实很明显
我们猜想,注释任务的框架对众包人员编写句子时会产生显著的影响,这一影响会反映在数据中,我们称之为“人工注释(annotation artifacts)”。
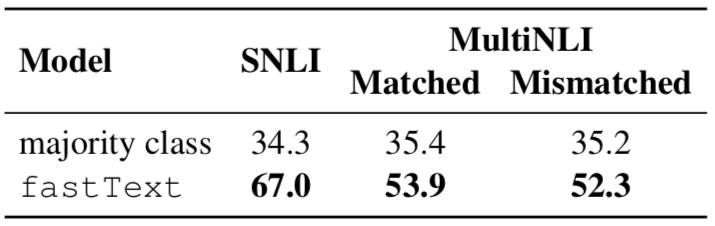
为了确定这种人为行为对数据的影响程度,我们训练一个模型来预测生成句子的标签,无需查看前提句子。具体来说,我们使用现成的文本分类器fastText,它可以将文本模型化为许多单词和二元语法(bigrams),以预测句子的标签。
下表显示,每个测试集中大部分数据都能在不看前提句子的情况下被正确分类,这也证明了即使不用对自然语言推理建模,分类器也能表现得很好。
人工注释的特点
之前我们说到,超过一半的MultiNLI数据和三分之二的SNLI数据都有明显的人工痕迹,为了从中总结出它们的特点,我们将对数据进行大致分析,重点关注词汇的选择和句子的长度。
词汇选择
为了了解特定词汇的选择是否会影响句子的分类,我们计算了训练集中每个单词和类别之间的点互信息(PMI):
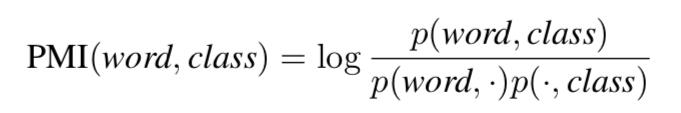
下表显示了每个分类中与类别最相关的几个单词,以及训练语句中包含这些单词的比例。
相关句子(Entailment)
与前提句子完全相关的生成句子都含有通用词汇,如动物、乐器和户外等,这些词语还有可能衍生出更具体的词语例如小狗、吉他、沙滩等等。另外,这些据此都会用确切的数字代替近似值(一些、至少、各种等等),并且会移除明确的性别。有些还会带有具体的环境,例如室内或室外,这些都是SNLI数据集中图片的个性特征。
中立句子
中立关系的句子中,最常见的就是修饰词(高、悲伤、受欢迎)和最高级词语(第一、最爱、最多)。除此之外,中立句子比较常见的是原因和目的从句,例如因为。
不相关句子
否定词例如“没有人”、“不”、“从不”、“没有”等都是不相关句子的常见词语。
句子长度
我们发现,生成句子中tokens的数量在不同的推理类别中并不是平均分配的。下图显示,中性的句子中token往往较长,而相关句子往往较短。句子长度的差异可能表明,众包工作者在生成相关句子时只是简单地从前提句子p中删除了几个单词。而事实上,当每个句子都用bag of words表示时,SNLI中有8.8%的相关生成句子完全包含在前提句子之中,而只有0.2%的中性和矛盾句子包含前提。
结论
通过观察结果,并对比其他人工注释分析,我们得到了三个主要结论。
很多数据集都包含有“人工痕迹”
监督模型需要利用人工注释。Levy等人证明了监督词汇推理模型在很大程度上以来数据集中人工生成的词汇。
人工注释会高估模型性能。大多数测试集都能单独依靠人工注释解决问题,所以我们鼓励开发额外的标准,能够给让人了解NLI模型的真实性能。
以上是关于Python是不是被严重高估了?的主要内容,如果未能解决你的问题,请参考以下文章