为什么现在的视频都会加入自动字幕功能?
Posted 杨渝
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了为什么现在的视频都会加入自动字幕功能?相关的知识,希望对你有一定的参考价值。
最近上油管和billbilli等视频网站,会发现部分视频添加了自动字幕生成甚至翻译功能(可能早就有,但是最近我才注意到)。前几天在登录T开头的微博网站,也发现有自建聊天室功能,加入一个聊天室以后又发现聊天室的发言会自动生成实时字幕。因为笔者也参与过一些NLP、语音识别、图谱、自动翻译的研究工作,发现这些功能后觉得很有意思,做过AI的同学都知道这一类语音识别和自动翻译会消耗算力,因此笔者就在思考这些互联网公司为什么会去消耗大量成本做这些功能,本文就是笔者自己对这问题的一些分析思考,未做原厂调研,不能做为严谨的科研文献参考。
1.自动字幕生成和自动翻译功能分析
我们先看看,自动字幕生成大致会用到几个工具:语音识别(负责语音转文字的识别)、自然语义处理(用于对生成的文字和词进行语义级的纠错,关键词提取)、知识图谱(其实是和自然语义处理相关联的,会根据不同schema的图谱进行更准确的纠错,并支撑自动翻译)、自然语言生成(可以算作纠错后的句子、段落生成对应的文本,当然根据地域会生成简体或者繁体中文)、自动翻译(这个没啥好说的)。
2.工程落地其他难点
2.1视频因为有分镜头和转场,所以一个完整的镜头可能是一个完整的句子或者段落,一一个完整的句子和段落可能也会对应若干个镜头。所以生成的字幕如果要和镜头相匹配,还需要对视频进行一定的图片切帧,进行图像识别或者分析,笔者猜测如果是口述可以进行一定程度的唇语分析(但是不清楚现在有没有人或者团队做过类似的训练)。但是如果是有动画、物体拍摄、逻辑递进等场景,就需要对视频主要目标,比如抖音跳舞的美女、科普演讲、手机评测等一类进行简单schema的构建,才能更好的讲生成文本和视频分镜头做更好的结合。
2.2如果是一些逻辑性不强或者没有提前构建schema的视频,比如电影介绍一类就很难去提前构建视频的图谱本体,笔者猜测这种生成的字幕可能就需要人工干预了,但是厂商如果为了控制成本,不见得会给所有的视频提供自动字幕生成或者自动翻译功能。这就是我们会看到不是所有的视频都有字幕选项。
2.3还有部分是视频制作者本身就添加了字幕,但是厂商也提供了自动字幕生成功能,这个时候从技术角度看,通过对视频自带的字幕进行OCR提取,和自动生成的字幕进行比对纠错,这算是一个很好的免费训练方式。
3.为什么要去做字幕自动生成和翻译
通过1、2的分析,其实可以知道做字幕自动生成和翻译会有两方面的成本,一方面是算力的成本,一方面是开发成本,而且预计整个开发和迭代成本并不低。如果按照预训练或者构建schema的技术逻辑,笔者认为做这个工作的投入和产出是不成正比的,本身也很难做为成熟的ToB技术创新或者技术输出变现。因为本身在算法原始创新层面没有太多创新,只是在落地工程代码层面做了些工作。
所以笔者认为互联网厂商做这些功能不能从技术创新角度去看,而应该从商业逻辑来看。做过产品经理的同学都知道,在做产品设计的时候,会将新功能分为必备、反向、无差异等属性。如果按照产品组件的角度去看,毫无疑问这两个功能大概率属于无差异功能。也许有同学会反驳翻译功能对自己还是很有用的,这个问题稍后会补充笔者的看法。但是如果把网站平台看做一个系统,这个系统对应了若干场景,每个场景是由不同组件完成(其实这里的实现已经接近于体系工程的自涌现了)。我们对场景进行研究就会发现一些有趣的事了,但是在这之前我还是想做些概念的分析和阐述。
3.1视频和微博厂商的盈利逻辑是什么?
很多同学会说互联网厂商盈利不就那几招,广告、抽成、订阅、股票等等。有经验的同学会说互联网厂商的盈利根本是用户流量。但是我们再分析下去,用户流量是什么?用户数吗,有些新型厂商为了快速融资会通过地推、促销、广告、裂变(最有名的就是PDD了)等手段快速扩大注册用户数,但是注册用户数不等于流量,因为有些用户注册了发现不感兴趣,今生今世可能都不会登录了。那是有效用户数吗?那什么是有效用户数?付了费的算有效用户吗?每天都上来看看的算有效用户吗?每天花费大量时间使用一个app的算有效用户吗?
如果是在互联网厂商待过的同学都明白,我们很难用以上的一些逻辑来真正准确定义“有效用户流量”。是在于我们的RFLP物理到抽象逻辑的建模方法,无法准确描述C端用户这种几乎是混沌的一种群体。问题出在哪儿?看过《乌合之众》的同学就知道,人这种个体的分析本来就属于人文和社会科学领域,如果强行用自然科学的思维去分析建模一开始方法就没有用对(当然当今大量技术和方法论本身就是跨学科,笔者反对的只是用单一的纯理工科的方法去分析问题,并不是反对这个过程不使用自然科学的方法论和技术)。
3.2如何按照跨学科思维去分析“有效用户流量”?
笔者这里尝试用行为心理学的“上瘾机制”来描述和定义“有效用户流量”,个人认为有效用户流量是指用户群体将注意力集中于一个事物,并且感知和认知层都专注于该事物,并投入大量成本最终形成上瘾的现象。因为行为心理学本身就是跨学科专业,除了采用了经典心理学的理论外,还参考了社会学的部分群体理论,经济学的部分原理,并衍生出了行为经济学等专业。但是笔者认为最重要的一点是,用户群体他的感知不但要集中于一个事物,认知也要集中于同一个事物,才能形成上瘾并转化为“有效流量”,系统工程和心理学里面都提到过人的短期记忆和长期记忆模型,AI的感知和认知分层也是基于该理论进行构建。其中上瘾机制就是为了获得短期快感,不断加大刺激和专注,但是对app的上瘾机制形成,绝不是和麻醉药品、光顾失足妇女一样是单纯通过感知层刺激能形成的。《认知科学导论》里面也提到对于某件事情的成瘾,比如玩手机和吸毒的原理类似,但是玩手机等事件的成瘾是需要大脑认知的参与的。(这部分阐述比较抽象,有些描述逻辑性还不够,以后有时间再去完善了)
3.3如何培养有效用户的成瘾场景?
通过前面的分析,我们梳理几个结论:对于互联网厂商的平台必须形成上瘾才能算是有效;这一类上瘾不是吸毒,不仅是感知的集中,也必须在认知上集中注意力;抛开场景谈技术无意义,群体的形成必须是有对应的场景设计和分析(比如周围的大学生都在刷抖音,你不刷就很难融入群体,本身就无法获得社会认同感。周围的单身汉都在刷soul撩妹子,你不刷就会造成对于单身的恐慌或者对约炮的向往)。
所以牛X的厂商产品经理或者总监,一定是场景设计或者预期描述的高手(但是笔者对这一点深为厌恶,从科学上看预期描述的因果关系和归因关系是两回事,从道德上看商业主义绑架了人的天性,缺乏道德的设计无论如何都应该被唾弃)。
我们回过头来看视频厂商,视频分为长视频和短视频,长视频有爱奇艺、油管、billibilli等以科普、评测、综述、影视剧为主的平台,短视频有抖音等平台(还有其他平台,但是笔者不刷短视频,也懒得去调研)。表面上看短视频刻意将时间控制在秒级为单位,但实质原因是短期感知刺激分泌的多巴胺数量和快感不是线性正比的,随着多巴胺持续分泌快感也是呈波浪形形态,所以将短期的刺激再拆分成更短的时间维度,就可以保证每个短视频的切换,都会引起快感呈一波一波的上升趋势,避免用户的快感疲劳。那为什么王者荣耀就不能以秒为单位来做一局呢,是因为对抗类游戏需要注意力不断集中,不断做出新的决策模型,多巴胺的持续分泌会消减快感疲劳,这就是为什么认知层的参与在成瘾过程中这么重要。但是如果是王者荣耀连招很熟练的高手打得太多可能就无法获得这么多快感,是因为连招的模型库已经进入短期模型库,不需要学习或者新的研判了(系统工程的一些课程里面会详细阐述人的短期记忆模型库和长期记忆模型库,这里不做过多阐述)。还有一类比如羊了个羊、植物大战僵尸玩法简单的游戏,就需要通过时间倒计时方式施加紧迫感,来加强注意力机制,避免快感疲劳。
这个时候我们再来看长视频平台,致命的场景问题出现了。我们在看长视频的时候,获得感知的方式很多,但是主要是视觉和听觉,但是因为缺乏交互,所以认知层参与的很少。这就造成用户在看一个视频的时候,很难长时间将感知和认知都集中于这个视频上,有时候可能是需要做其他事,所以打开视频也只是听声音为主(笔者不建议看学习视频的时候这样干),有时候可能是觉得视频的前叙还没有讲到让自己感兴趣的内容,也许是纯属开着听个响(奈飞、葫芦的影视剧不同,有时间我们可以单独再分析一下)。那这些场景下,客户如何成瘾并转化为有效用户呢?实际上很多长视频平台意识到了这个问题,也有意无意做了很多尝试,比如在视频中间插播广告,你真以为厂商是想赚那点广告费?在视频中加入抽奖或者其他互动环节。但是这毕竟是阶段性的,平台不能每隔30秒就来一次吧!
所以这个时候我们再来看自动字幕生成,有趣的事情发生了,图片、文字、声音、触觉采集的方式不同,在人体传输的神经链路不同,甚至在大脑的映射区都是不同的。这个不是我说的,有兴趣的可以翻看《认知科学导论》,里面有大量的医学数据和测试报告,实质上手、脚、舌头和脸触碰同一个物体表面所传递和映射的方式都是不同的(有兴趣的同学可以结合性心理学做些研究^_^,别说我猥琐哈)。因此当我们去同时看视频、文字,听声音的时候,传输到大脑的映射区和链路就有了三条不同的方式。特别是和视频、声音的短期刺激不同,文字在人的进化史中,和长期记忆模型库、认知层是高度紧密相关的。无形中就构建了感知层和认知层的同时参与,同时因为认知层的部分参与,感知层视觉和听觉的也不再分散,短期刺激的快感疲劳会通过视觉、听觉两条链路做部分抵消。
4.综上所述,因为自动字幕的生成,牵引了认知层的参与,并带动了多个感知器官的参与。用户的注意力更加集中,更容易上瘾并形成有效访问。这就是为什么聊天室如果有自动字幕生成,很多人大概率会花更多时间去看聊天室聊了什么(当然这只是相对以前而言,不代表绝对时间),至于为什么说自动翻译也是属于无感知功能呢,因为去看大段外语长视频的,大概率是为了学习了解新知识,这部分人群如果你不会外语还是去看盗版电影或者找相关翻译好的论文算了。
最后,这不是严谨的科研论文,只是笔者的个人随笔分析,仅供参考。
阿里云 Aliplayer高级功能介绍:多字幕
基本介绍
国际化场景下面,播放器支持多字幕,可以有效解决视频的传播障碍难题,该功能适用于视频内容在全球范围内推广,阿里云的媒体处理服务提供接口可以生成多字幕,现在先看一下具体的效果:
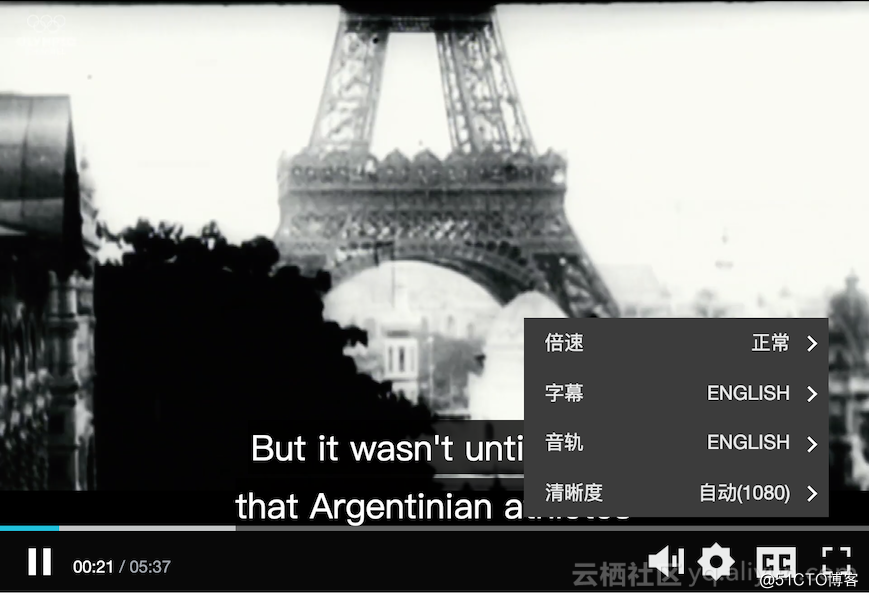
WebVTT格式介绍
多字幕现在支持HLS的格式,后期会去实现Dash格式的支持。
字幕文件
字幕的内容使用WebVTT的格式,更多的关于WebVTT可以参考WebVTT 格式如下:
WEBVTT
00:00:09.960 --> 00:00:12.600
Argentina was among the
founding members of
00:00:12.640 --> 00:00:14.440
the International Olympic
Committee,
00:00:14.480 --> 00:00:16.640
and sent a team to Paris
in 1900,
第一行必需是WEBVTT,表明这是个WebVTT文件文件。
接着是一空行,后面就是每一项的一个cue,包含时间范围和要显示的字幕,时间格式是HH:MM:SS.sss,时:分:秒.毫秒, 开始时间 --> 结束时间,-->的两边各有一个空格,这两个时间必需写在同一行,并且时间都是相对于视频开始的时间间隔。
时间之后是字幕文本,时间和字幕文本之间不能有空行,字幕文本可以是一行或多行,字幕文本中不能有空行。
字幕样式
字幕除了本身字幕里面可以定义字幕的显示样式, 如果每个字幕的样式都是一样的, 那可以通过H5 Video的CSS样式统一定义,浏览器提供了::cue伪元素, 通过匹配::cue伪元素设置字幕的样式。
video::cue {
background-image: linear-gradient(to bottom, dimgray, lightgray);
color: papayawhip;
}
video::cue(b) {
color: peachpuff;
}
更多的样式属性可以参考:: cue CSS伪元素
H5 Video如何显示字幕
H5 Video采用track组件显示字幕, 主要包含下面属性:
名称 说明
default 定义了该track应该启用
kind 定义了 text track 应该如何使用,可选值包含subtitles、captions、descriptions、chapters、metadata,默认为subtitles
label 显示标题,用户可读的
src track的地址
srclang track文本数据的语言,它必须是合法的 BCP 47 语言标签
H5 Video显示字幕的HTML代码,是很简单的:
<video controls autoplay src="video.mp4">
<track default src="track.vtt" lable="中文">
</video>
Aliplayer实现字幕
Aliplayer和阿里云视频云的点播服务或媒体处理服务结合起来更方便的实现字幕,如果用户使用了阿里云服务,那么集成播放器后不用做什么事情,只要使用VideoId的播放方式播放视频,没有额外的事情要做。
HLS字幕文件的结构
通过媒体处理服务的Open API可以打包用户的字幕文件到HLS视频里面, 具体可以参考如何进行HLS的打包 HLS打完包以后的基本结构:
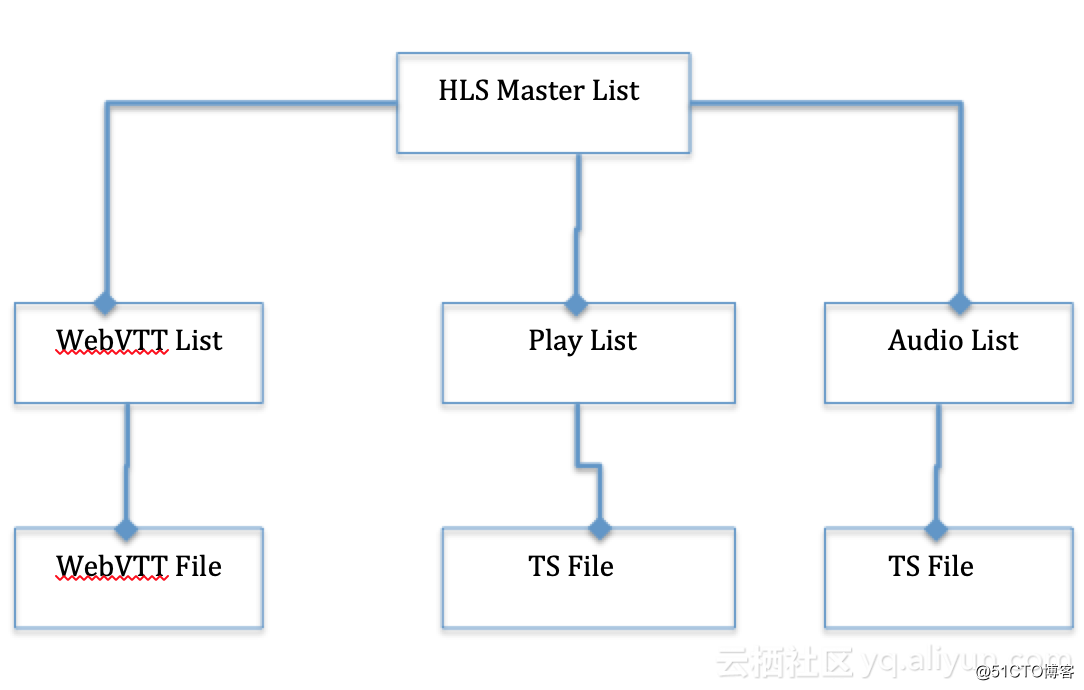
打完包以后字幕文件将做为HLS Master List里面的一部分,type的值为“SUBTITLES”, 具体看:
#EXTM3U
#EXT-X-VERSION:4
#EXT-X-MEDIA:TYPE=SUBTITLES,NAME="ENGLISH",LANGUAGE="eng",URI="english.m3u8"
#EXT-X-MEDIA:TYPE=SUBTITLES,NAME="日本語",LANGUAGE="jpn",URI="jpn.m3u8"
#EXT-X-MEDIA:TYPE=SUBTITLES,NAME="中文",LANGUAGE="zho",URI="zho.m3u8"
上面的每一种语言的字幕的URI对应的是一个m3u8文件,这个m3u8文件包含的内容是WebVTT的list,比如english.m3u8包含的内容:
#EXTM3U
#EXT-X-VERSION:4
#EXT-X-TARGETDURATION:300
#EXT-X-MEDIA-SEQUENCE:1
#EXT-X-PLAYLIST-TYPE:VOD
#EXTINF:300.000,
00001.vtt
#EXTINF:37.840,
00002.vtt
#EXT-X-ENDLIST
是不是和我们的HLS的切片列表很像的,基本一样, EXTINF下面的vtt地址对应的vtt文件里包含的是具体的字幕内容, 比如00001.vtt包含的内容:
WEBVTT
00:00:09.960 --> 00:00:12.600
Argentina was among the
founding members of
00:00:12.640 --> 00:00:14.440
the International Olympic
Committee,
00:00:14.480 --> 00:00:16.640
and sent a team to Paris
in 1900,
Aliplayer创建Track
之前说H5 Video有Track组件可以用于播放字幕, 因此在从HLS里解析出WebVTT列表以后,通过addTextTrack方法添加到音频元素的文本轨道列表中, 添加完以后,可以通过音频元素的textTracks属性,得到全部的文本轨道。
video.addTextTrack(kind,label,language);
let tracks = video.textTracks;//获取全部的轨迹
大家可能也发现了,这里添加的TextTrack并没有属性可以指定WebVTT的地址,不像HTML的Track组件,地址直接赋值给src属性就OK了, 因此我们还需要解析WebVTT的内容,然后转为cue对象,添加到当前的语言的TextTrack里面。
const textTrackCue = new TextTrackCue(cue.startTime, cue.endTime, cue.text);
textTrackCue.id = cue.id;
currentTrack.addCue(textTrackCue);
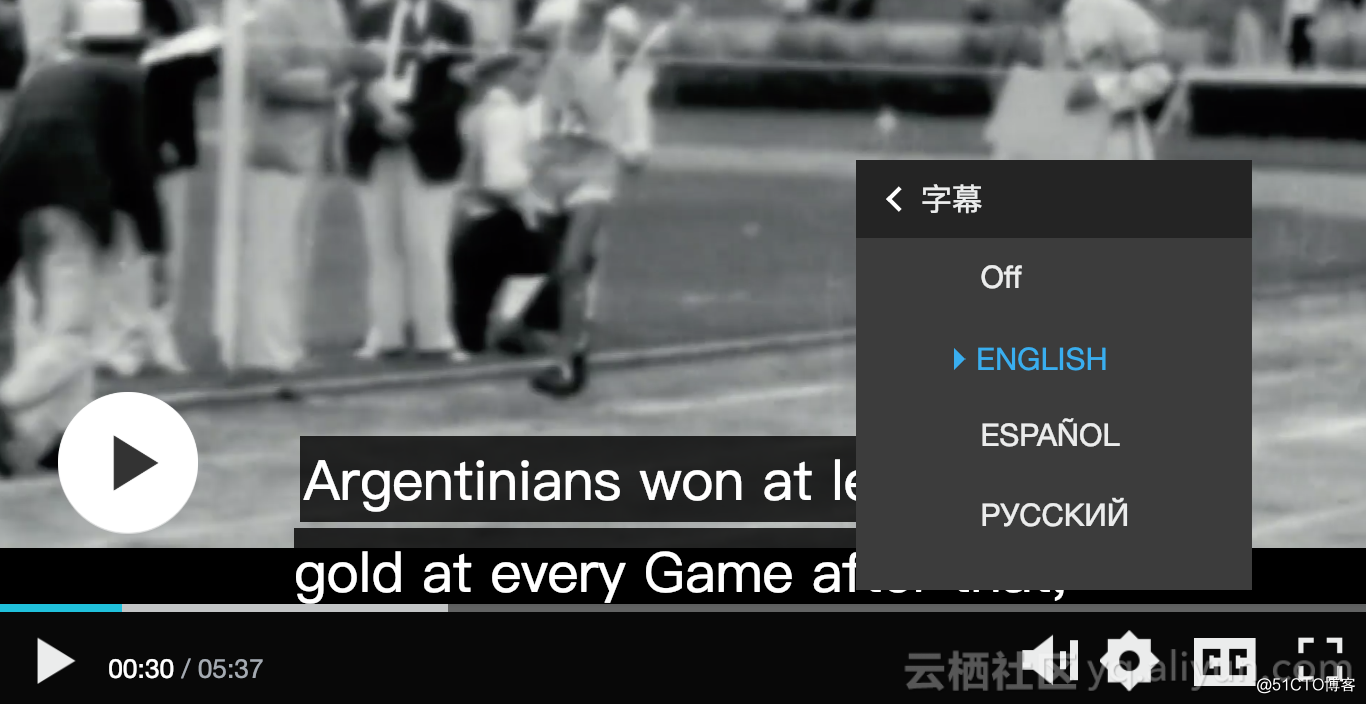
现在我们把轨道和字幕内容到添加到媒体组件了, Aliplayer在播放视频的时候会获取TextTracks里的值建立可视化的UI, 比如:
Aliplayer的字幕服务
Aliplayer除了提供默认UI操作外, 还提供了CCService满足用户的一些自定义需求,比如需要根据浏览器的语言默认播放那个语言等等,通过player._ccService属性访问字幕服务,字幕服务提供了如下的API:
名称 参数 说明
switch language 切换字幕
open 关闭字幕
close 关闭字幕
getCurrentSubtitle 获取当前字幕的language的值
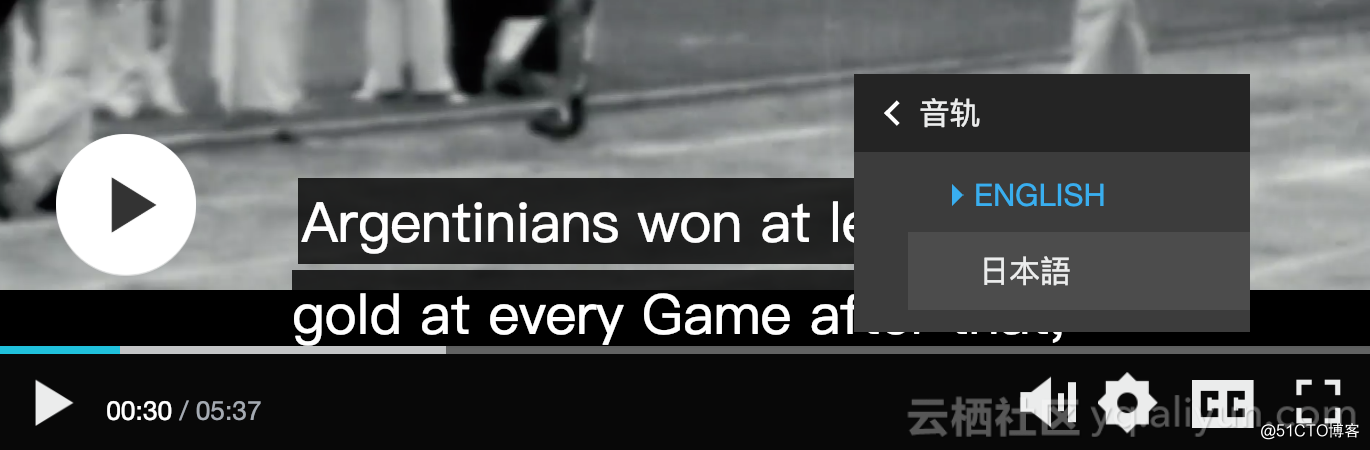
多音轨
除了支持多字幕,Aliplayer也支持多音轨,下面是效果:
使用Aliplayer
使用Aliplayer播放字幕,可以直接通过source属性指定hls文件地址播放,也可以通过vid+playauth的方式播放点播服务的视频:
var player = new Aliplayer({
id: "player-con",
source: "https://vod.olympicchannel.com/NBCR_Production_-_OCS/231/1016/GEPH-ONTHERECS02E012C-_E17101101_master.m3u8",
width: "100%",
height: "500px",
autoplay: true,
isLive: false
}, function (player) {
console.log("播放器创建成功");
});
以上是关于为什么现在的视频都会加入自动字幕功能?的主要内容,如果未能解决你的问题,请参考以下文章
Bilibili-XMLSubtitle-to-ASS可视化Bilibili本地视频XML弹幕转换ASS字幕转换器:新增自动转换Bilibili下载视频功能