提升集群吞吐量与稳定性的秘诀: Dubbo 自适应负载均衡与限流策略实现解析
Posted 阿里云云原生
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了提升集群吞吐量与稳定性的秘诀: Dubbo 自适应负载均衡与限流策略实现解析相关的知识,希望对你有一定的参考价值。
作者:刘泉禄
整体介绍
本文所说的“柔性服务”主要是指 consumer 端的负载均衡和 provider 端的限流两个功能。在之前的 Dubbo 版本中,负载均衡部分更多的考虑的是公平性原则,即 consumer 端尽可能平等的从 provider 中作出选择,在某些情况下表现并不够理想。而限流部分只提供了静态的限流方案,需要用户对 provider 端设置静态的最大并发值,然而该值的合理选取对用户来讲并不容易。我们针对这些存在的问题进行了改进。
负载均衡
在原本的 Dubbo 版本中,有五种负载均衡的方案供选择,他们分别是 “Random” , “ShortestResponse” , “RoundRobin”,“LeastActive” 和 “ConsistentHash”。
其中除 “ShortestResponse” 和 “LeastActive” 外,其他的几种方案主要是考虑选择时的公平性和稳定性。对于 “ShortestResponse” 来说,其设计目的是从所有备选的 provider 中选择 response 时间最短的以提高系统整体的吞吐量。然而存在两个问题:
-
在大多数的场景下,不同 provider 的 response 时长没有非常明显的区别,此时该算法会退化为随机选择。
-
response 的时间长短有时也并不能代表机器的吞吐能力。对于 “LeastActive” 来说,其认为应该将流量尽可能分配到当前并发处理任务较少的机器上。但是其同样存在和 “ShortestResponse” 类似的问题,即这并不能单独代表机器的吞吐能力。
基于以上分析,我们提出了两种新的负载均衡算法。一种是同样基于公平性考虑的单纯 “P2C” 算法,另一种是基于自适应的方法 “adaptive”,其试图自适应的衡量 provider 端机器的吞吐能力,然后将流量尽可能分配到吞吐能力高的机器上,以提高系统整体的性能。
效果介绍
对于负载均衡部分的有效性实验在两个不同的情况下进行的,分别是提供端机器配置比较均衡和提供端机器配置差距较大的情况。
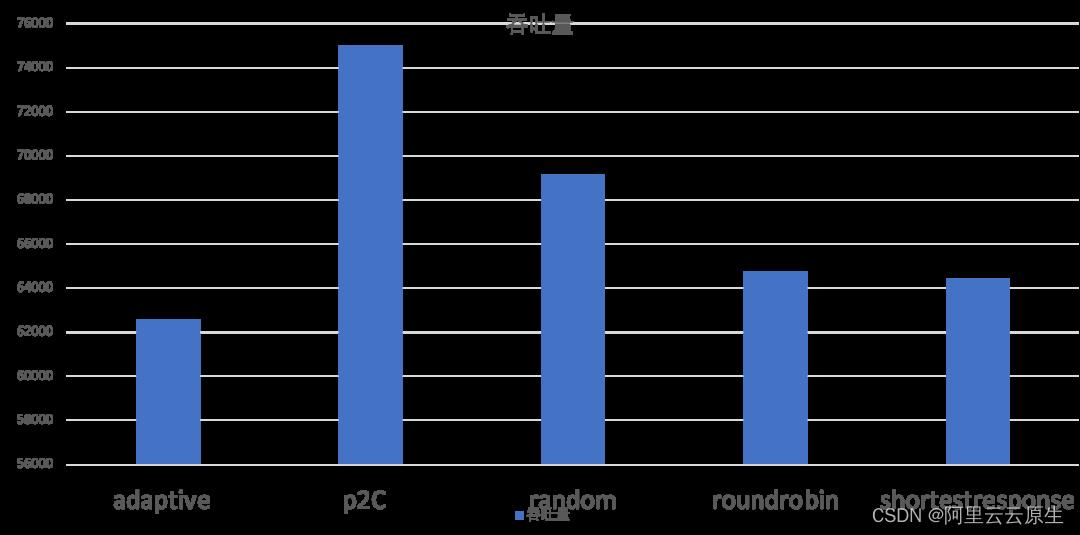
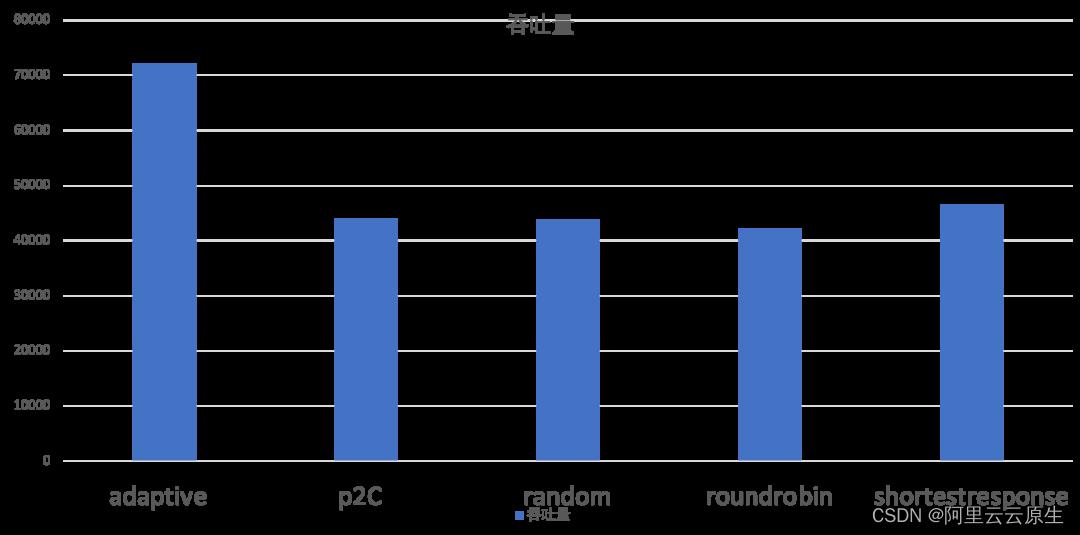
使用方法
使用方法与原本的负载均衡方法相同。只需要在 consumer 端将 “loadbalance” 设置为 “p2c” 或者 “adaptive” 即可。
代码结构
负载均衡部分的算法实现只需要在原本负载均衡框架内继承 LoadBalance 接口即可。
原理介绍
P2C 算法
Power of Two Choice 算法简单但是经典,主要思路如下:
-
对于每次调用,从可用的 provider 列表中做两次随机选择,选出两个节点 providerA 和 providerB。
-
比较 providerA 和 providerB 两个节点,选择其“当前正在处理的连接数”较小的那个节点。
adaptive 算法
代码的 github 地址 [ 1]
相关指标
- cpuLoad
cpuLoad = cpu一分钟平均负载 * 100 / 可用cpu数量。该指标在 provider 端机器获得,并通过 invocation 的 attachment 传递给 consumer 端。
- rt
rt 为一次 rpc 调用所用的时间,单位为毫秒。
- timeout
timeout 为本次 rpc 调用超时剩余的时间,单位为毫秒。
- weight
weight 是设置的服务权重。
- currentProviderTime
provider 端在计算 cpuLoad 时的时间,单位是毫秒
- currentTime
currentTime 为最后一次计算 load 时的时间,初始化为 currentProviderTime,单位是毫秒。
- multiple
multiple=(当前时间 - currentTime)/timeout + 1
- lastLatency

- beta
平滑参数,默认为0.5
- ewma
lastLatency 的平滑值
lastLatency=beta*lastLatency+(1 - beta)*lastLatency
- inflight
inflight 为 consumer 端还未返回的请求的数量。
inflight=consumerReq - consumerSuccess - errorReq
- load
对于备选后端机器x来说,若距离上次被调用的时间大于 2*timeout,则其 load 值为 0。
否则
load=CpuLoad*(sqrt(ewma) + 1)*(inflight + 1)/(((consumerSuccess / (consumerReq +1) )*weight)+1)
算法实现
依然是基于 P2C 算法。
-
从备选列表中做两次随机选择,得到 providerA 和 providerB
-
比较 providerA 和 providerB 的 load 值,选择较小的那个。
自适应限流
与负载均衡运行在 consumer 端不同的是,限流功能运行在 provider 端。其作用是限制 provider 端处理并发任务时的最大数量。从理论上讲,服务端机器的处理能力是存在上限的,对于一台服务端机器,当短时间内出现大量的请求调用时,会导致处理不及时的请求积压,使机器过载。在这种情况下可能导致两个问题:
1.由于请求积压,最终所有的请求都必须等待较长时间才能被处理,从而使整个服务瘫痪。
2.服务端机器长时间的过载可能有宕机的风险。因此,在可能存在过载风险时,拒绝掉一部分请求反而是更好的选择。在之前的 Dubbo 版本中,限流是通过在 provider 端设置静态的最大并发值实现的。但是在服务数量多,拓扑复杂且处理能力会动态变化的局面下,该值难以通过计算静态设置。
基于以上原因,我们需要一种自适应的算法,其可以动态调整服务端机器的最大并发值,使其可以在保证机器不过载的前提下,尽可能多的处理接收到的请求。
因此,我们参考部分业界方案实现基础上,在 Dubbo 的框架内实现了两种自适应限流算法,分别是基于启发式平滑的 “HeuristicSmoothingFlowControl” 和基于窗口的 “AutoConcurrencyLimier”。
代码的 github 地址 [ 2]
效果介绍
自适应限流部分的有效性实验我们在提供端机器配置尽可能大的情况下进行,并且为了凸显效果,在实验中我们将单次请求的复杂度提高,将超时时间尽可能设置的大,并且开启消费端的重试功能。
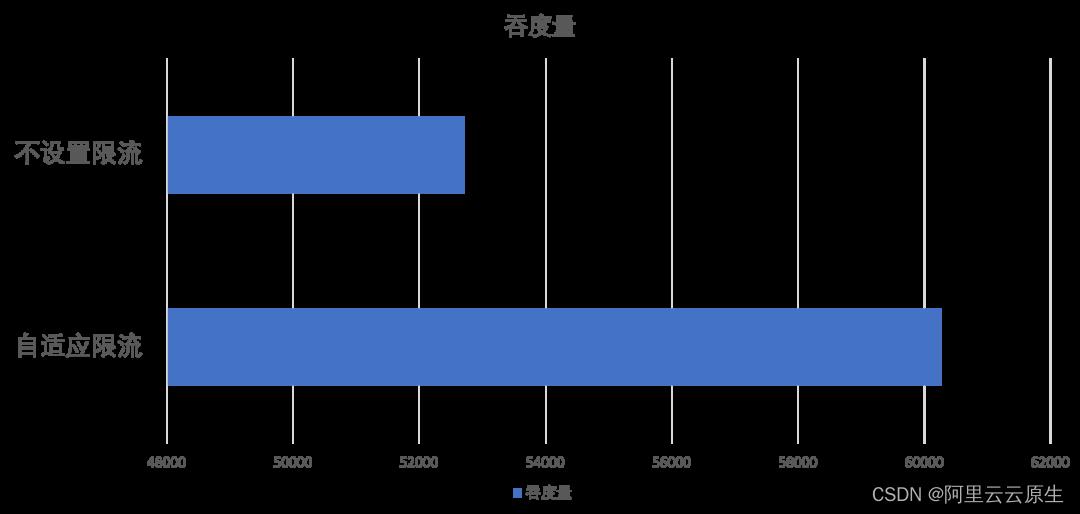
使用方法
要确保服务端存在多个节点,并且消费端开启重试策略的前提下,限流功能才能更好的发挥作用。设置方法与静态的最大并发值设置类似,只需在 provider 端将 “flowcontrol” 设置为 “autoConcurrencyLimier” 或者 “heuristicSmoothingFlowControl” 即可。
代码结构
-
FlowControlFilter:在 provider 端的 filter 负责根据限流算法的结果来对 provider 端进行限流功能。
-
FlowControl:根据 Dubbo 的 spi 实现的限流算法的接口。限流的具体实现算法需要继承自该接口并可以通过 Dubbo 的 spi 方式使用。
-
CpuUsage:周期性获取 cpu 的相关指标
-
HardwareMetricsCollector:获取硬件指标的相关方法
-
ServerMetricsCollector:基于滑动窗口的获取限流需要的指标的相关方法。比如 qps 等。
-
AutoConcurrencyLimier:自适应限流的具体实现算法。
-
HeuristicSmoothingFlowControl:自适应限流的具体实现方法。
原理介绍
HeuristicSmoothingFlowControl
相关指标
- alpha
alpha 为可接受的延时的上升幅度,默认为 0.3
- minLatency
在一个时间窗口内的最小的 Latency 值。
- noLoadLatency
noLoadLatency 是单纯处理任务的延时,不包括排队时间。这是服务端机器的固有属性,但是并不是一成不变的。在 HeuristicSmoothingFlowControl 算法中,我们根据机器CPU的使用率来确定机器当前的 noLoadLatency。当机器的 CPU 使用率较低时,我们认为 minLatency 便是 noLoadLatency。当 CPU 使用率适中时,我们平滑的用 minLatency 来更新 noLoadLatency 的值。当 CPU 使用率较高时,noLoadLatency 的值不再改变。
- maxQPS
一个时间窗口周期内的 QPS 的最大值。
- avgLatency
一个时间窗口周期内的 Latency 的平均值,单位为毫秒。
- maxConcurrency
计算得到的当前服务提供端的最大并发值。
maxConcurrency=ceil(maxQPS*((2 + alpha)*noLoadLatency - avgLatency))
算法实现
当服务端收到一个请求时,首先判断 CPU 的使用率是否超过 50%。如果没有超过 50%,则接受这个请求进行处理。如果超过 50%,说明当前的负载较高,便从 HeuristicSmoothingFlowControl 算法中获得当前的 maxConcurrency 值。如果当前正在处理的请求数量超过了 maxConcurrency,则拒绝该请求。
AutoConcurrencyLimier
相关指标
- MaxExploreRatio
默认设置为 0.3
- MinExploreRatio
默认设置为 0.06
- SampleWindowSizeMs
采样窗口的时长。默认为 1000 毫秒。
- MinSampleCount
采样窗口的最小请求数量。默认为 40。
- MaxSampleCount
采样窗口的最大请求数量。默认为 500。
- emaFactor
平滑处理参数。默认为 0.1。
- exploreRatio
探索率。初始设置为 MaxExploreRatio。若 avgLatency<=noLoadLatency*(1.0 + MinExploreRatio) 或者 qps>=maxQPS*(1.0 + MinExploreRatio)则 exploreRatio=min(MaxExploreRatio,exploreRatio+0.02)
否则
exploreRatio=max(MinExploreRatio,exploreRatio-0.02)
- maxQPS
窗口周期内 QPS 的最大值。
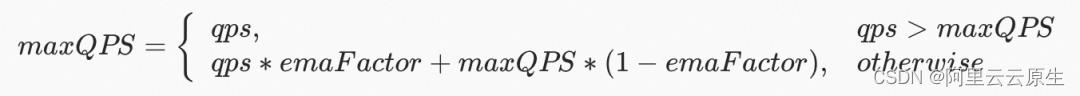
- noLoadLatency

- halfSampleIntervalMs
半采样区间。默认为 25000 毫秒。
- resetLatencyUs
下一次重置所有值的时间戳,这里的重置包括窗口内值和 noLoadLatency。单位是微秒。初始为 0.

- remeasureStartUs
下一次重置窗口的开始时间。

- startSampleTimeUs
开始采样的时间。单位为微秒。
- sampleCount
当前采样窗口内请求的数量。
- totalSampleUs
采样窗口内所有请求的 latency 的和。单位为微秒。
- totalReqCount
采样窗口时间内所有请求的数量和。注意区别 sampleCount。
- samplingTimeUs
采样当前请求的时间戳。单位为微秒。
- latency
当前请求的 latency。
- qps
在该时间窗口内的 qps 值。
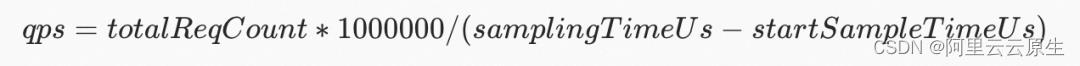
- avgLatency
窗口内的平均 latency。
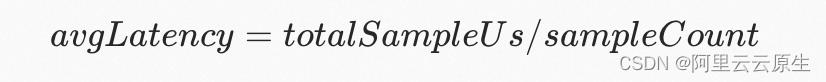
- maxConcurrency
上一个窗口计算得到当前周期的最大并发值。
- nextMaxConcurrency
当前窗口计算出的下一个周期的最大并发值。

Little’s Law
当服务处于稳定状态时:concurrency=latency*qps。这是自适应限流理论的基础。当请求没有导致机器超载时,latency 基本稳定,qps 和 concurrency 处于线性关系。当短时间内请求数量过多,导致服务超载的时候,concurrency 会和latency一起上升,qps则会趋于稳定。
算法实现
AutoConcurrencyLimier 的算法使用过程和 HeuristicSmoothingFlowControl 类似。
实现与 HeuristicSmoothingFlowControl 的最大区别是 AutoConcurrencyLimier 是基于窗口的。每当窗口内积累了一定量的采样数据时,才利用窗口内的数据来更新得到 maxConcurrency。
其次,利用 exploreRatio 来对剩余的容量进行探索。
另外,每隔一段时间都会自动缩小 max_concurrency 并持续一段时间,以处理 noLoadLatency 上涨的情况。因为估计 noLoadLatency 时必须先让服务处于低负载的状态,因此对 maxConcurrency 的缩小是难以避免的。
由于 max_concurrency
Dubbo 于上周上线了新版官网与文档,涵盖 Dubbo3 核心功能及特性,关于自适应负载均衡、自适应限流及更多方案的详细讲解,请访问:https://dubbo.apache.org
相关链接
[1] 代码的 github 地址
https://github.com/apache/dubbo/pull/10745
[2] 代码的 github 地址
https://github.com/apache/dubbo/pull/10642
OpenKruise v1.3:新增自定义 Pod Probe 探针能力与大规模集群性能显著提升
云原生应用自动化管理套件、CNCF Sandbox 项目——OpenKruise,近期发布了 v1.3 版本。
OpenKruise 是针对 Kubernetes 的增强能力套件,聚焦于云原生应用的部署、升级、运维、稳定性防护等领域。
所有的功能都通过 CRD 等标准方式扩展,可以适用于 1.16 以上版本的任意 Kubernetes 集群。单条 helm 命令即可完成 Kruise 的一键部署,无需更多配置。
版本解析
在版本 v1.3 中,OpenKruise 提供了新的 CRD 资源 PodProbeMarker,改善了大规模集群的一些性能问题,Advanced DaemonSet 支持镜像预热,以及 CloneSet、WorkloadSpread、Advanced CronJob、SidecarSet 一些新的特性。
新增 CRD 和 Controller:PodProbeMarker
Kubernetes 提供了三种默认的 Pod 生命周期管理:
- Readiness Probe:用来判断业务容器是否已经准备好响应用户请求,如果检查失败,会将该 Pod 从 Service Endpoints 中剔除。
- Liveness Probe:用来判断容器的健康状态,如果检查失败,kubelet 将会重启该容器。
- Startup Probe:用来判断容器是否启动完成,如果定义了该 Probe,那么 Readiness Probe 与 Liveness Probe 将会在它成功之后再执行。
所以 Kubernetes 中提供的 Probe 能力都已经限定了特定的语义以及相关的行为。除此之外,其实还是存在自定义 Probe 语义以及相关行为的需求,例如:
- GameServer 定义 Idle Probe 用来判断该 Pod 当前是否存在游戏对局,如果没有,从成本优化的角度,可以将该 Pod 缩容掉。
- K8s Operator 定义 main-secondary Probe 来判断当前 Pod 的角色(main or secondary),升级的时候,可以优先升级 secondary,进而达到升级过程只有一次选主的行为,降低升级过程中服务抖动时间。
OpenKruise 提供了自定义 Probe 的能力,并将结果返回到 Pod Status 中,用户可以根据该结果决定后续的行为。
PodProbeMarker 配置如下:
apiVersion: apps.kruise.io/v1alpha1
kind: PodProbeMarker
metadata:
name: game-server-probe
namespace: ns
spec:
selector:
matchLabels:
app: game-server
probes:
- name: Idle
containerName: game-server
probe:
exec: /home/game/idle.sh
initialDelaySeconds: 10
timeoutSeconds: 3
periodSeconds: 10
successThreshold: 1
failureThreshold: 3
markerPolicy:
- state: Succeeded
labels:
gameserver-idle: 'true'
annotations:
controller.kubernetes.io/pod-deletion-cost: '-10'
- state: Failed
labels:
gameserver-idle: 'false'
annotations:
controller.kubernetes.io/pod-deletion-cost: '10'
podConditionType: game.io/idlePodProbeMarker 结果可以通过 Pod 对象查看:
apiVersion: v1
kind: Pod
metadata:
labels:
app: game-server
gameserver-idle: 'true'
annotations:
controller.kubernetes.io/pod-deletion-cost: '-10'
name: game-server-58cb9f5688-7sbd8
namespace: ns
spec:
...
status:
conditions:
# podConditionType
- type: game.io/idle
# Probe State 'Succeeded' indicates 'True', and 'Failed' indicates 'False'
status: "True"
lastProbeTime: "2022-09-09T07:13:04Z"
lastTransitionTime: "2022-09-09T07:13:04Z"
# If the probe fails to execute, the message is stderr
message: ""性能优化:大规模集群性能显著提升
- #1026[1] 引入了延迟入队机制,大幅优化了在大规模应用集群下 kruise-manager 拉起时的 CloneSet 控制器工作队列堆积问题,在理想情况下初始化时间减少了 80% 以上。
- #1027[2] 优化 PodUnavailableBudget 控制器 Event Handler 逻辑,减少无关 Pod 入队数量。
- #1011[3] 通过缓存机制,优化了大规模集群下 Advanced DaemonSet 重复模拟 Pod 调度计算的 CPU、Memory 消耗。
- #1015[4] , #1068[5]大幅降低了大规模集群下的运行时内存消耗。弥补了 v1.1 版本中 Disable DeepCopy 的一些疏漏点,减少 expressions 类型 label selector 的转换消耗。
SidecarSet 支持注入特定的历史版本
SidecarSet 通过 ControllerRevision 记录了关于 containers、volumes、initContainers、imagePullSecrets 和 patchPodMetadata 等字段的历史版本,并允许用户在 Pod 创建时选择特定的历史版本进行注入。
基于这一特性,用户可以规避在 SidecarSet 灰度发布时,因 Deployment 等 Workload 扩容、升级等操作带来的 SidecarSet 发布风险。如果不选择注入版本,SidecarSet 将对重建 Pod 默认全都注入最新版本 Sidecar。
SidecarSet 相关 ControllerRevision 资源被放置在了与 Kruise-Manager 相同的命名空间中,用户可以使用以下命令来查看:
kubectl get controllerrvisions -n kruise-system -l kruise.io/sidecarset-name=your-sidecarset-name
此外,用户还可以通过 SidecarSet 的 status.latestRevision 字段看到当前版本对应的 ControllerRevision 名称,以方便自行记录。
1. 通过 ControllerRevision 名称指定注入的 Sidecar 版本
apiVersion: apps.kruise.io/v1alpha1
kind: SidecarSet
metadata:
name: sidecarset
spec:
...
injectionStrategy:
revisionName: specific-controllerRevision-nam2. 通过自定义版本标识指定注入的 Sidecar 版本
用户可以通过在发版时,同时给 SidecarSet 打上 http://apps.kruise.io/sidecarset-custom-version=your-version-id 来标记每一个历史版本,SidecarSet 会将这个 label 向下带入到对应的 ControllerRevision 对象,以便用户进行筛选,并且允许用户在选择注入历史版本时,使用改 your-version-id 来进行描述。
假设用户只想灰度 10% 的 Pods 到 version-2,并且对于新创建的 Pod 希望都注入更加稳定的 version-1 版本来控制灰度风险:
apiVersion: apps.kruise.io/v1alpha1
kind: SidecarSet
metadata:
name: sidecarset
labels:
apps.kruise.io/sidecarset-custom-version: version-2
spec:
...
updateStrategy:
partition: 90%
injectionStrategy:
customVersion: version-1SidecarSet 支持注入 Pod Annotations
SidecarSet 支持注入 Pod Annotations,配置如下:
apiVersion: apps.kruise.io/v1alpha1
kind: SidecarSet
spec:
containers:
...
patchPodMetadata:
- annotations:
oom-score: '"log-agent": 1'
custom.example.com/sidecar-configuration: '"command": "/home/admin/bin/start.sh", "log-level": "3"'
patchPolicy: MergePatchJson
- annotations:
apps.kruise.io/container-launch-priority: Ordered
patchPolicy: Overwrite | RetainpatchPolicy 为注入的策略,如下:
- Retain:默认策略,如果 Pod 中存在 annotation[key]=value ,则保留 Pod 原有的 value。只有当 Pod 中不存在 annotation[key] 时,才注入 annotations[key]=value。
- Overwrite:与 Retain 对应,当 Pod 中存在 annotation[key]=value,将被强制覆盖为 value2。
- MergePatchJson:与 Overwrite 对应,annotations value为 json 字符串。如果 Pod 不存在该 annotations[key],则直接注入。如果存在,则进行 json value 合并。例如:Pod 中存在 annotations[oom-score]='"main": 2',注入后将 value json 合并为 annotations[oom-score]='"log-agent": 1, "main": 2'。
注意:patchPolicy 为 Overwrite和MergePatchJson 时,SidecarSet 原地升级 Sidecar Container 时,能够同步更新该 annotations。但是,如果只修改 annotations 则不能生效,只能搭配 Sidecar 容器镜像一起原地升级。
patchPolicy 为 Retain 时,SidecarSet 原地升级 Sidecar Container 时,将不会同步更新该 annotations。
上述配置后,SidecarSet 在注入 Sidecar Container时,会注入 Pod annotations,如下:
apiVersion: v1
kind: Pod
metadata:
annotations:
apps.kruise.io/container-launch-priority: Ordered
oom-score: '"log-agent": 1, "main": 2'
custom.example.com/sidecar-configuration: '"command": "/home/admin/bin/start.sh", "log-level": "3"'
name: test-pod
spec:
containers:
...注意:SidecarSet 从权限、安全的考虑不应该注入或修改除 Sidecar Container 之外的 Pod 字段,所以如果想要使用该能力,首先需要配置 SidecarSet_PatchPodMetadata_WhiteList 白名单或通过如下方式关闭白名单校验:
> helm install kruise https://... --set featureGates="SidecarSetPatchPodMetadataDefaultsAllowed =true"
Advanced DaemonSet 支持镜像预热
如果你在安装或升级 Kruise 的时候启用了 PreDownloadImageForDaemonSetUpdate feature-gate,DaemonSet 控制器会自动在所有旧版本 pod 所在 node 节点上预热你正在灰度发布的新版本镜像。这对于应用发布加速很有帮助。
默认情况下 DaemonSet 每个新镜像预热时的并发度都是 1,也就是一个个节点拉镜像。
如果需要调整,你可以通过 http://apps.kruise.io/image-predownload-parallelism annotation 来设置并发度。
apiVersion: apps.kruise.io/v1alpha1
kind: DaemonSet
metadata:
annotations:
apps.kruise.io/image-predownload-parallelism: "10"CloneSet 扩缩容与 PreparingDelete
默认情况下,CloneSet 将处于 PreparingDelete 状态的 Pod 视为正常,意味着这些 Pod 仍然被计算在 replicas 数量中。
在这种情况下:
- 如果你将 replicas 从 N 改为 N-1,当一个要删除的 Pod 还在 PreparingDelete 状态中时,你重新将 replicas 改为 N,CloneSet 会将这个 Pod 重新置为 Normal 状态。
- 如果你将 replicas 从 N 改为 N-1 的同时在 podsToDelete 中设置了一个 Pod,当这个 Pod 还在 PreparingDelete 状态中时,你重新将 replicas 改为 N,CloneSet 会等到这个 Pod 真正进入 terminating 之后再扩容一个 Pod 出来。
- 如果你在不改变 replicas 的时候指定删除一个 Pod,当这个 Pod 还在 PreparingDelete 状态中时,CloneSet 会等到这个 Pod 真正进入 terminating 之后再扩容一个 Pod 出来。
从 Kruise v1.3.0 版本开始,你可以在 CloneSet 中设置一个 http://apps.kruise.io/cloneset-scaling-exclude-preparing-delete: "true" 标签,它标志着这个 CloneSet 不会将 PreparingDelete 状态的 Pod 计算在 replicas 数量中。
在这种情况下:
- 如果你将 replicas 从 N 改为 N-1,当一个要删除的 Pod 还在 PreparingDelete 状态中时,你重新将 replicas 改为 N,CloneSet 会将这个 Pod 重新置为 Normal 状态。
- 如果你将 replicas 从 N 改为 N-1 的同时在 podsToDelete 中设置了一个 Pod,当这个 Pod 还在 PreparingDelete 状态中时,你重新将 replicas 改为 N,CloneSet 会立即创建一个新 Pod。
- 如果你在不改变 replicas 的时候指定删除一个 Pod,当这个 Pod 还在 PreparingDelete 状态中时,CloneSet 会立即创建一个新 Pod。
Advanced CronJob Time zones
默认情况下,所有 AdvancedCronJob schedule 调度时,都是基于 kruise-controller-manager 容器本地的时区所计算的。
不过,在 v1.3.0 版本中我们引入了 spec.timeZone 字段,你可以将它设置为任意合法时区的名字。例如,设置 spec.timeZone: "Asia/Shanghai" 则 Kruise 会根据国内的时区计算 schedule 任务触发时间。
Go 标准库中内置了时区数据库,作为在容器的系统环境中没有外置数据库时的 fallback 选择。
其他改动
你可以通过 Github release[6] 页面,来查看更多的改动以及它们的作者与提交记录。
参考链接
[1] #1026
https://github.com/openkruise/kruise/pull/1026
[2] #1027
https://github.com/openkruise/kruise/pull/1027
[3] #1011
https://github.com/openkruise/kruise/pull/1011
[4] #1015
https://github.com/openkruise/kruise/pull/1015
[5] #1068
https://github.com/openkruise/kruise/pull/1068
[6] Github release:
https://github.com/openkruise/kruise/releases
[7] Slack channel:
https://kubernetes.slack.com/channels/openkruise
作者:赵明山(立衡)
本文为阿里云原创内容,未经允许不得转载。
以上是关于提升集群吞吐量与稳定性的秘诀: Dubbo 自适应负载均衡与限流策略实现解析的主要内容,如果未能解决你的问题,请参考以下文章