信息
Posted 二木成林
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了信息相关的知识,希望对你有一定的参考价值。
目录
概述
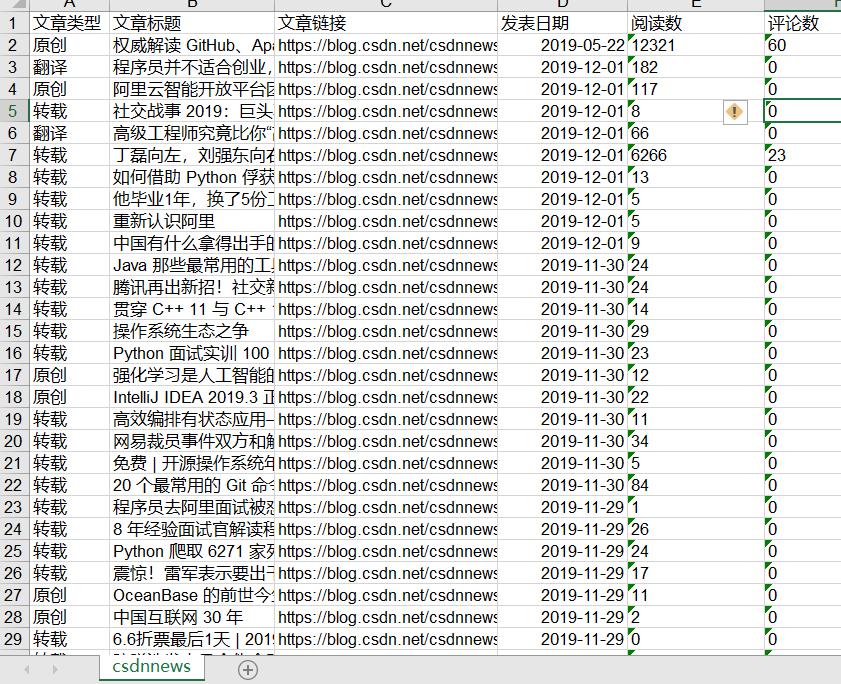
爬取CSDN博主的所有博客文章信息并保存到excel中。
准备
所需模块
- requests
- xlrd
- xlwt
- lxml
- xlutils
涉及知识点
- python基础
- requests模块基础
- xpath表达式基础
- excel文件的读取
运行效果
控制台打印:

电脑本地文件:
完成爬虫
1. 分析网页
打开博客网页:
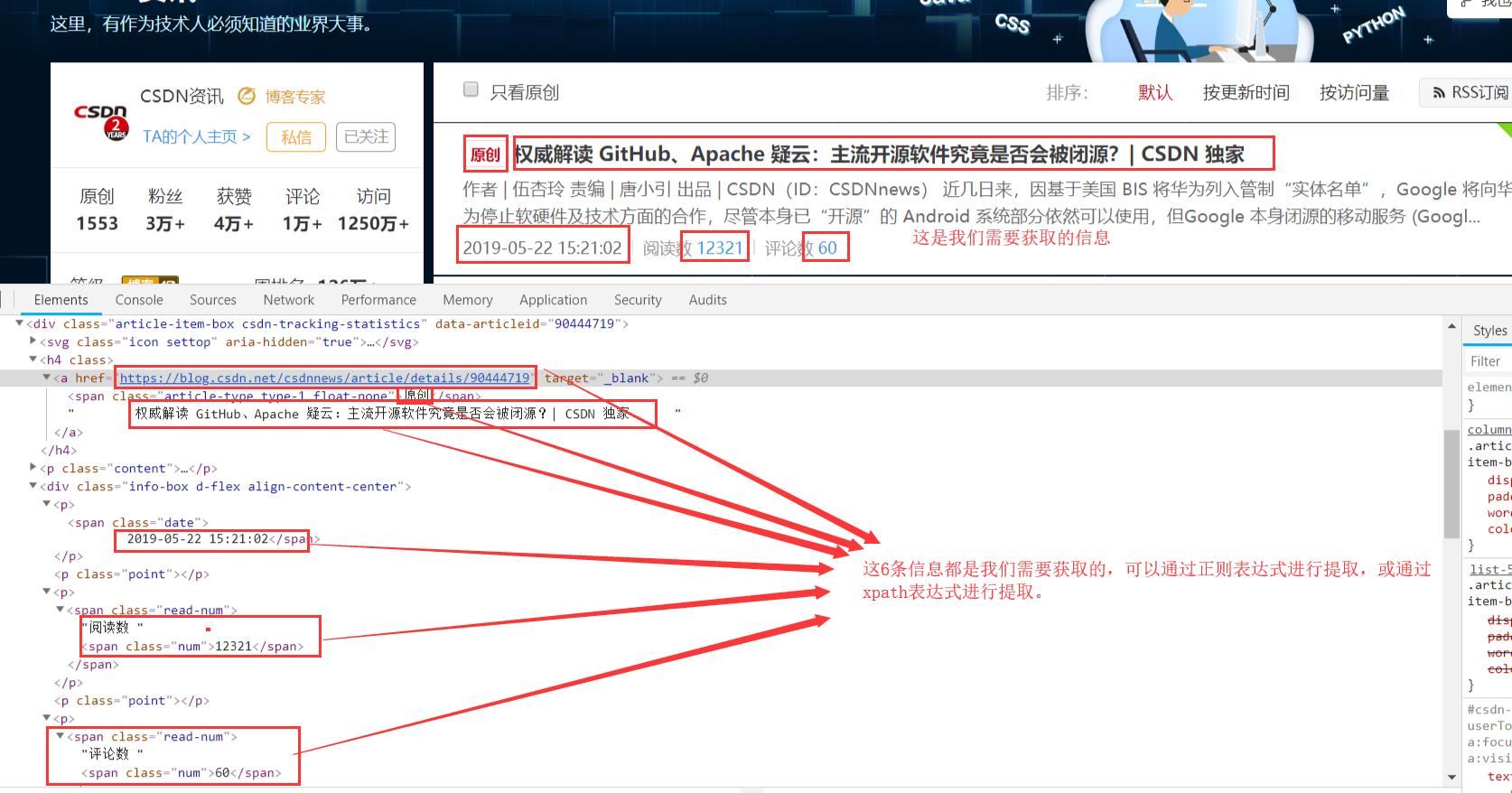
博客页面每一页的的URL联系如下:
# 第1页: https://blog.csdn.net/cnds123321/article/list/1
# 第2页: https://blog.csdn.net/cnds123321/article/list/2
# 第3页: https://blog.csdn.net/cnds123321/article/list/3
# 故可以得出公式: url="https://blog.csdn.net/"+author_name+"/article/list/"+page_index
# author_name指的是博主的名字,page_index指的是页码当前是第几页
2. 爬虫代码
import requests
import xlrd
import xlwt
from lxml import etree
from lxml import html
from xlutils.copy import copy
# 爬虫实战: 爬取CSDN博客的所有博客文章链接
# 第1页: https://blog.csdn.net/cnds123321/article/list/1
# 第2页: https://blog.csdn.net/cnds123321/article/list/2
# 第3页: https://blog.csdn.net/cnds123321/article/list/3
# 故可以得出公式: url="https://blog.csdn.net/"+author_name+"/article/list/"+page_index
# author_name指的是博主的名字,page_index指的是页码当前是第几页
# path指的是excel文件的路径;sheet_name指的是工作簿的名字;value指的是数据,是一个嵌套列表
def write_excel_xls(path, sheet_name, value):
"""创建excel文件,并初始化一定的数据"""
index = len(value) # 获取需要写入数据的行数
workbook = xlwt.Workbook() # 新建一个工作簿
sheet = workbook.add_sheet(sheet_name) # 在工作簿中新建一个表格
for i in range(0, index):
for j in range(0, len(value[i])):
sheet.write(i, j, value[i][j]) # 像表格中写入数据(对应的行和列)
workbook.save(path) # 保存工作簿
# path指的是excel文件的路径;value指的是数据,是一个嵌套列表
def write_excel_xls_append(path, value):
"""向excel表中增加数据"""
index = len(value) # 获取需要写入数据的行数
workbook = xlrd.open_workbook(path) # 打开工作簿
sheets = workbook.sheet_names() # 获取工作簿中的所有表格
worksheet = workbook.sheet_by_name(sheets[0]) # 获取工作簿中所有表格中的的第一个表格
rows_old = worksheet.nrows # 获取表格中已存在的数据的行数
new_workbook = copy(workbook) # 将xlrd对象拷贝转化为xlwt对象
new_worksheet = new_workbook.get_sheet(0) # 获取转化后工作簿中的第一个表格
for i in range(0, index):
for j in range(0, len(value[i])):
new_worksheet.write(i + rows_old, j, value[i][j]) # 追加写入数据,注意是从i+rows_old行开始写入
new_workbook.save(path) # 保存工作簿
# 请求头
header =
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.81 Safari/537.36"
# 博主名字
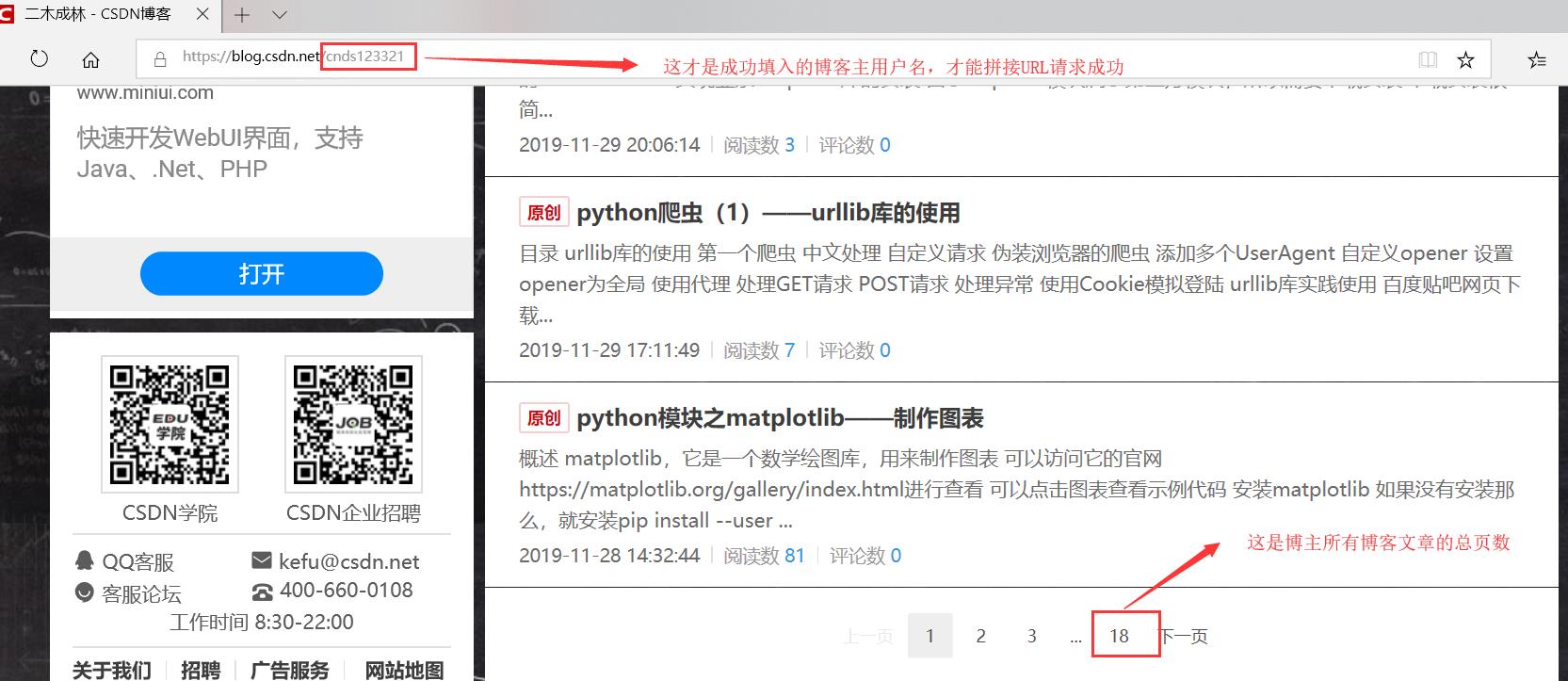
author_name = input("请输入博主的名字: ")
# 博主博文页数
page_num = int(input("请输入博客页数: "))
# 写入表头数据
write_excel_xls("CSDN-" + author_name + ".xls", author_name, [["文章类型", "文章标题", "文章链接", "发表日期", "阅读数", "评论数"], ])
# 循环每页
for index in range(1, page_num + 1):
# 拼接URL
page_url = "https://blog.csdn.net/" + author_name + "/article/list/" + str(index)
# 发送请求,获取响应
response = requests.get(page_url, headers=header).content
# 将HTML源码字符串转换尘土HTML对象
page_html = etree.HTML(response)
# 博客文章的标题
title_list = html.fromstring(response.decode()).xpath(
"//div[@class='article-item-box csdn-tracking-statistics']/h4/a/text()")
# 处理换行问题
csdn_article_title_list = []
for i in range(0, len(title_list)):
csdn_article_title_list.append(title_list[i].strip())
while "" in csdn_article_title_list:
csdn_article_title_list.remove("")
# 博客文章的类型
csdn_article_type_list = page_html.xpath("//div[@class='article-item-box csdn-tracking-statistics']/h4/a/span")
# 博客文章的链接
csdn_article_link_list = page_html.xpath("//div[@class='article-item-box csdn-tracking-statistics']//h4//a/@href")
# 博客文章的发表日期
csdn_article_publishDate_list = page_html.xpath(
"//div[@class='info-box d-flex align-content-center']/p/span[@class='date']")
# 博客文章的阅读数
csdn_article_readerCount_list = page_html.xpath(
"//div[@class='info-box d-flex align-content-center']/p[last()-2]/span/span[@class='num']")
# 博客文章的评论数
csdn_article_commentCount_list = page_html.xpath(
"//div[@class='info-box d-flex align-content-center']/p[last()]/span/span[@class='num']")
# 将数据保存到excel表格中
for i in range(0, len(csdn_article_title_list)):
data = [[csdn_article_type_list[i].text, csdn_article_title_list[i], csdn_article_link_list[i],
csdn_article_publishDate_list[i].text, csdn_article_readerCount_list[i].text,
csdn_article_commentCount_list[i].text], ]
print("正在保存: "+csdn_article_title_list[i]+"......")
write_excel_xls_append("CSDN-" + author_name + ".xls", data)
print("CSDN-" + author_name + ".xls保存成功!")注意:
以上是关于信息的主要内容,如果未能解决你的问题,请参考以下文章