机器学习强基计划1-3:图文详解Logistic回归原理(两种优化)+Python实现
Posted Mr.Winter`
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习强基计划1-3:图文详解Logistic回归原理(两种优化)+Python实现相关的知识,希望对你有一定的参考价值。
目录
0 写在前面
机器学习强基计划聚焦深度和广度,加深对机器学习模型的理解与应用。“深”在详细推导算法模型背后的数学原理;“广”在分析多个机器学习模型:决策树、支持向量机、贝叶斯与马尔科夫决策、强化学习等。
1 什么是Logistic回归?
在机器学习强基计划1-1:图文详解感知机算法原理+Python实现提到广义线性模型(generalized linear model)
f ( x ( i ) ) = g − 1 ( w T x ( i ) + b ) f\\left( \\boldsymbolx^\\left( i \\right) \\right) =g^-1\\left( \\boldsymbolw^T\\boldsymbolx^\\left( i \\right)+b \\right) f(x(i))=g−1(wTx(i)+b)
其中单调可微函数 g ( ⋅ ) g\\left( \\cdot \\right) g(⋅)称为联系函数(link function)。广义线性模型本质上仍是线性的,但通过 g ( ⋅ ) g\\left( \\cdot \\right) g(⋅)进行非线性映射,使之具有更强的拟合能力,类似神经元的激活函数。
Logistic回归是 g − 1 ( z ) = 1 1 + e − z g^-1\\left( z \\right) =\\frac11+e^-z g−1(z)=1+e−z1时的广义线性模型, g − 1 ( z ) = 1 1 + e − z g^-1\\left( z \\right) =\\frac11+e^-z g−1(z)=1+e−z1这个函数在人工智能领域非常著名,称为sigmoid函数,其值被限定在0-1区间内,因此也可认为是概率映射。
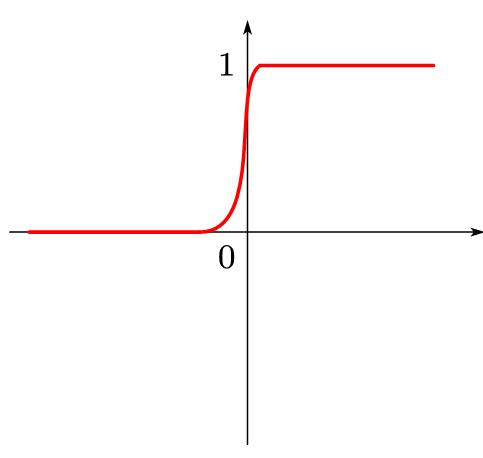
所以Logistic回归可以认为输出了预测类别的概率,因此Logistic回归本质上是在线性回归基础上,将预测值映射到概率区间内的分类学习方法。
常见的Logisitc回归类型如表所示。
| Logistic回归分析类型 | 输出标签举例 | 说明 |
|---|---|---|
| 二元Logistic回归 | 是/否 | 分类数据,且仅分为两类 |
| 多元无序Logistic回归 | 一线城市、二线城市、三线城市 | 分类数据,分类超过两类且同类别之间没有对比意义 |
| 多元有序Logistic回归 | 不同意、无所谓、同意 | 分类数据,分类超过两类且同类别之间具有对比意义 |
本节讨论最简单的二元Logistic回归。
2 手推Logistic回归原理
首先列出Logistic回归的表达式:
f ( x ^ ( i ) ) = g − 1 ( w ^ T x ^ ( i ) ) ⇔ w ^ T x ^ ( i ) = ln f ( x ^ ( i ) ) 1 − f ( x ^ ( i ) ) f\\left( \\boldsymbol\\hatx^\\left( i \\right) \\right) =g^-1\\left( \\boldsymbol\\hatw^T\\boldsymbol\\hatx^\\left( i \\right) \\right) \\Leftrightarrow \\boldsymbol\\hatw^T\\boldsymbol\\hatx^\\left( i \\right)=\\ln \\fracf\\left( \\boldsymbol\\hatx^\\left( i \\right) \\right)1-f\\left( \\boldsymbol\\hatx^\\left( i \\right) \\right) f(x^(i))=g−1(w^Tx^(i))⇔w^Tx^(i)=ln1−f(x^(i))f(x^(i))
可将输出 f ( x ^ ( i ) ) f\\left( \\boldsymbol\\hatx^\\left( i \\right) \\right) f(x^(i))视为给定一个训练样本 x ^ ( i ) \\boldsymbol\\hatx^\\left( i \\right) x^(i)输出预测类别的后验概率 p ( y i = 1 ∣ x ^ ( i ) ) p\\left( y_i=1|\\boldsymbol\\hatx^\\left( i \\right) \\right) p(yi=1∣x^(i))。
这里涉及一些概率论方面的知识,关于概率、似然等概念请参考机器学习强基计划4-1:你真的分得清频率、概率、几率和似然吗?
接下来根据极大似然法估计参数向量 w ^ \\boldsymbol\\hatw w^,即获得在给定观测样本的条件下,最接近样本真实标签的参数组合,令损失函数 E ( w ^ ) = ∑ i = 1 m ln p ( y i ∣ x ^ ( i ) ; w ^ ) E\\left( \\boldsymbol\\hatw \\right) =\\sum\\nolimits_i=1^m\\ln p\\left( y_i|\\boldsymbol\\hatx^\\left( i \\right);\\boldsymbol\\hatw \\right) E(w^)=∑i=1mlnp(yi∣x^(i);w^),考虑二分类情形:
p ( y i = 1 ∣ x ^ ( i ) ; w ^ ) = y i p ( y i = 1 ∣ x ^ ( i ) ; w ^ ) p ( y i = 0 ∣ x ^ ( i ) ; w ^ ) = ( 1 − y i ) p ( y i = 0 ∣ x ^ ( i ) ; w ^ ) ⇒ E ( w ^ ) = ∑ i = 1 m y i ln p ( y i = 1 ∣ x ^ ( i ) ; w ^ ) + ( 1 − y i ) ln ( 1 − p ( y i = 1 ∣ x ^ ( i ) ; w ^ ) ) \\begincases p\\left( y_i=1|\\boldsymbol\\hatx^\\left( i \\right);\\boldsymbol\\hatw \\right) =y_ip\\left( y_i=1|\\boldsymbol\\hatx^\\left( i \\right);\\boldsymbol\\hatw \\right)\\\\ p\\left( y_i=0|\\boldsymbol\\hatx^\\left( i \\right);\\boldsymbol\\hatw \\right) =\\left( 1-y_i \\right) p\\left( y_i=0|\\boldsymbol\\hatx^\\left( i \\right);\\boldsymbol\\hatw \\right)\\\\\\endcases\\\\\\Rightarrow E\\left( \\boldsymbol\\hatw \\right) =\\sum_i=1^my_i\\ln p\\left( y_i=1|\\boldsymbol\\hatx^\\left( i \\right);\\boldsymbol\\hatw \\right) +\\left( 1-y_i \\right) \\ln \\left( 1-p\\left( y_i=1|\\boldsymbol\\hatx^\\left( i \\right);\\boldsymbol\\hatw \\right) \\right) ⎩ ⎨ ⎧p(yi=1∣x^(i);w^)=yip(yi=1∣x^(i);w^)p(yi=0∣以上是关于机器学习强基计划1-3:图文详解Logistic回归原理(两种优化)+Python实现的主要内容,如果未能解决你的问题,请参考以下文章