es使用同义词插件注意事项
Posted 猫二哥
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了es使用同义词插件注意事项相关的知识,希望对你有一定的参考价值。
es使用同义词插件注意事项
1背景描述
就是在不修改es查语句的情况下,实现同义词搜索。比如中国和china都是中国的意思,如果一篇文章中,只有中国,没有china英文,但是需要我们搜索次是china的时候也可以搜索出这边文章
2插件安装
1docker安装es:
拉镜像 es版本:7.17.5
docker pull elasticsearch:7.17.5
找个本地磁盘配置,配置文件:
cluster.name: "docker-cluster"
network.host: 0.0.0.0
#http.port: 9200
#添加配置
http.cors.enabled: true
http.cors.allow-origin: "*"
#http.cors.allow-headers: Authorization
http.cors.allow-methods: OPTIONS, HEAD, GET, POST, PUT, DELETE
http.cors.allow-headers: "X-Requested-With,X-Auth-Token,Content-Type, Content-Length, Authorization"
discovery.zen.minimum_master_nodes: 1
#开启安全选项
xpack.security.enabled: false
#配置单节点模式
discovery.type: single-node
3 运行容器 -v挂在容器,使用自己的本地磁盘就行了。
docker network create somenetwork
docker run --restart=always -p 9200:9200 -p 9300:9300 -e ES_JAVA_OPTS="-Xms512m -Xmx512m" --net somenetwork -e "discovery.type=single-node" -v /Users/自己的用户名/work/soft/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml -v /Users/自己的用户名/work/soft/elasticsearch/data:/usr/share/elasticsearch/data -v /Users/自己的用户名/work/soft/elasticsearch/plugins:/usr/share/elasticsearch/plugins --name myes -d elasticsearch:7.17.5
验证 docker logs 容器日志
2安装插件
注意都要根据es版本来安装插件
1 中文分词插件 Ik
这里由于在网上有这个版本的ik插件,直接下载:
https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.17.5/elasticsearch-analysis-ik-7.17.5.zip
然后解压放在,磁盘 :/Users/自己的用户名/work/soft/elasticsearch/plugins中,重启容器就可以。
验证方式,调用es接口看下,是否有正确的数据:
http://localhost:9200/_analyze
"analyzer": "ik_max_word",
"text": "我的名字叫猫爷"
结果如下:

2 安装同义词插件elasticsearch-analysis-dynamic-synonym
但是由于github上,没有对应es的编译版本,所以需要下载源码本地编译。
1 下载:https://github.com/bells/elasticsearch-analysis-dynamic-synonym/releases
2 idea 打开,修改es版本
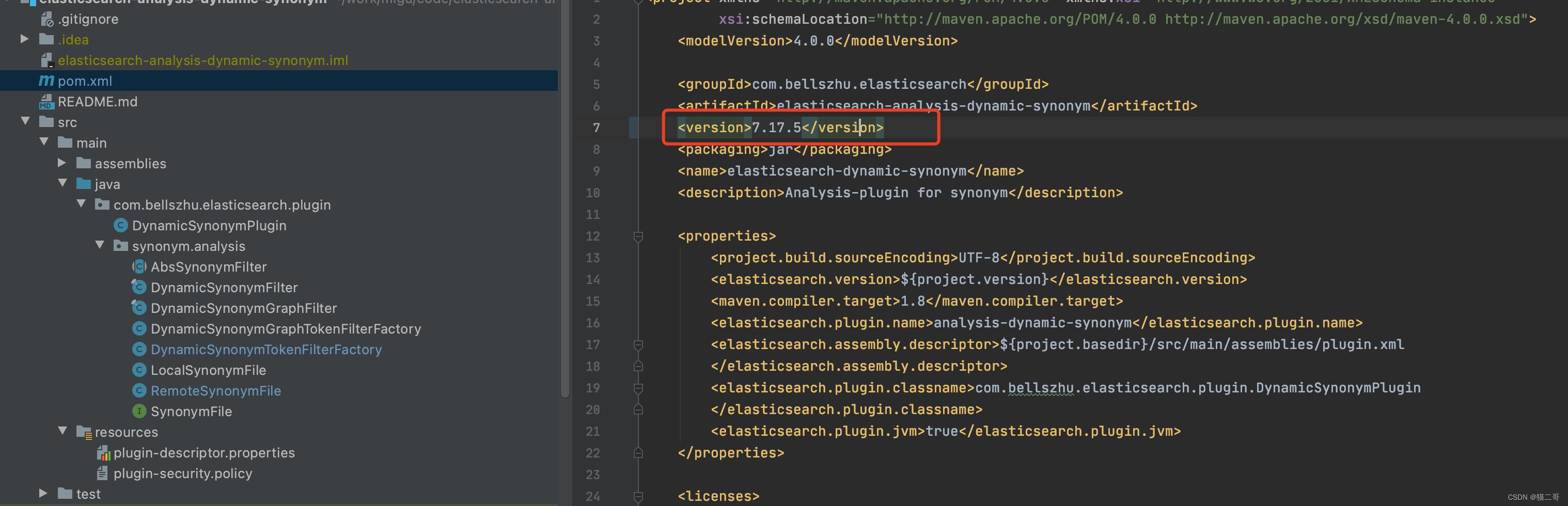
然后在命令行运行 mvn package
最后就会生成对应es版本的包:
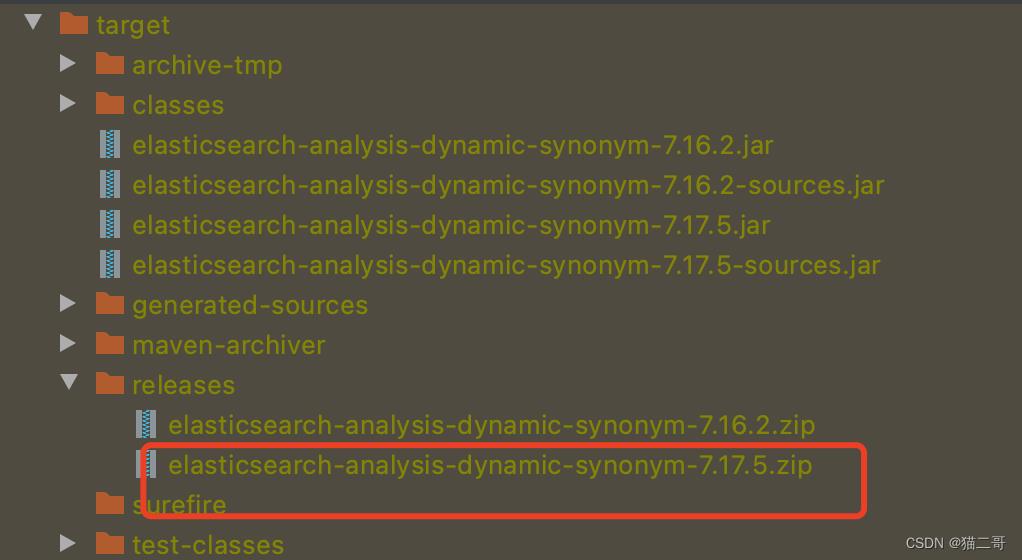
3 把它复制到/Users/自己的用户名/work/soft/elasticsearch/plugins 中,重启 es的容器。
启动中可能会报错误
Exception in thread "main" java.nio.file.NotDirectoryException: /usr/share/elasticsearch/plugins/.DS_Store
解决方案在es对应的本机磁盘上删除这文件,删除/Users/自己的用户名/work/soft/elasticsearch/plugins里面的.DS_Store文件。
插件到这里就准备完成!
验证:等下直接写代码验证
3使用 spring-boot-starter-data-elasticsearch 集成同义词
结论:springboot版本:2.4.1,同义词使用热更新方式
springboot 的es配置
spring:
elasticsearch:
rest:
uris: ["http://localhost:9200"]
connection-timeout: 100
read-timeout: 300
1实体类
VideoUserTestDO 用户信息对象
package com.ibird.pandaserviceadmin.es.model;
import java.util.List;
import javax.persistence.Id;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Field;
import org.springframework.data.elasticsearch.annotations.FieldType;
import org.springframework.data.elasticsearch.annotations.Setting;
import lombok.Data;
@Data
@Setting(settingPath = "es/settings.json")
@Document(createIndex = true, indexName = "video-user-test", shards = 1, replicas = 1)
public class VideoUserTestDO
@Id
String id;
@Field(type = FieldType.Text, searchAnalyzer = "synonym", analyzer = "ik_max_word")
String userName;
@Field(type = FieldType.Text, searchAnalyzer = "synonym", analyzer = "ik_max_word")
String nickName;
@Field(type = FieldType.Text, searchAnalyzer = "synonym", analyzer = "ik_max_word")
String info;
int hotNum;
@Field(type = FieldType.Text, searchAnalyzer = "synonym", analyzer = "ik_max_word")
String desc;
@Field(type = FieldType.Nested, store = true)
List<VideoUserVideoInfoDO> userVideoInfoDOs;
VideoUserVideoInfoDO 为nested对象
package com.ibird.pandaserviceadmin.es.model;
import javax.persistence.Id;
import org.springframework.data.elasticsearch.annotations.Field;
import org.springframework.data.elasticsearch.annotations.FieldType;
import lombok.Data;
@Data
public class VideoUserVideoInfoDO
@Id
@Field(type = FieldType.Keyword, store = true)
String id;
@Field(type = FieldType.Text, searchAnalyzer = "synonym", analyzer = "ik_max_word")
String name;
2 同义词setting配置
放在了resources/es目录下的settings.json
"index":
"analysis":
"analyzer":
"synonym":
"tokenizer": "ik_max_word",
"filter": [
"remote_synonym"
]
,
"filter":
"remote_synonym":
"type": "dynamic_synonym",
"synonyms_path": "http://192.168.2.100:8080/panda/video-user/synchronizeSynonym",
"interval": 10
,
"local_synonym":
"type": "dynamic_synonym",
"synonyms_path": "synonym.txt"
,
"synonym_graph":
"type": "dynamic_synonym_graph",
"synonyms_path": "http://192.168.2.100:8080/panda/video-user/synchronizeSynonym"
说重点:
synonym 为分析器的名字,就是我们在实体类上指定的searchAnalyzer。
remote_synonym 为我们为es调用我们接口获取同义词的接口。
interval 调用接口间隔时间,单位秒
3获取同义词接口
案列非完善
@GetMapping(value = "/video-user/synchronizeSynonym")
public String synchronizeSynonym(HttpServletRequest request, HttpServletResponse response) throws Exception
String eTag = request.getHeader("If-None-Match");
String modified = request.getHeader("If-Modified-Since");
StringBuilder sb = new StringBuilder();
sb.append("w").append(",").append("大爷").append("\\n");
sb.append("萱").append(",").append("xuan").append(",").append("旋").append("\\n");
// 更新时间
response.setHeader("Last-Modified", new Date().getTime() + "");
response.setHeader("ETag", "1");
response.setHeader("Content-Type", "text/plain;charset=UTF-8");
return sb.toString();
注意点:
1 下面3个必须有,因为是根据Last-Modified与etag来判断是否有更新。
response.setHeader(“Last-Modified”, new Date().getTime() + “”);
response.setHeader(“ETag”, “1”);
response.setHeader(“Content-Type”, “text/plain;charset=UTF-8”);
这个是插件的源码
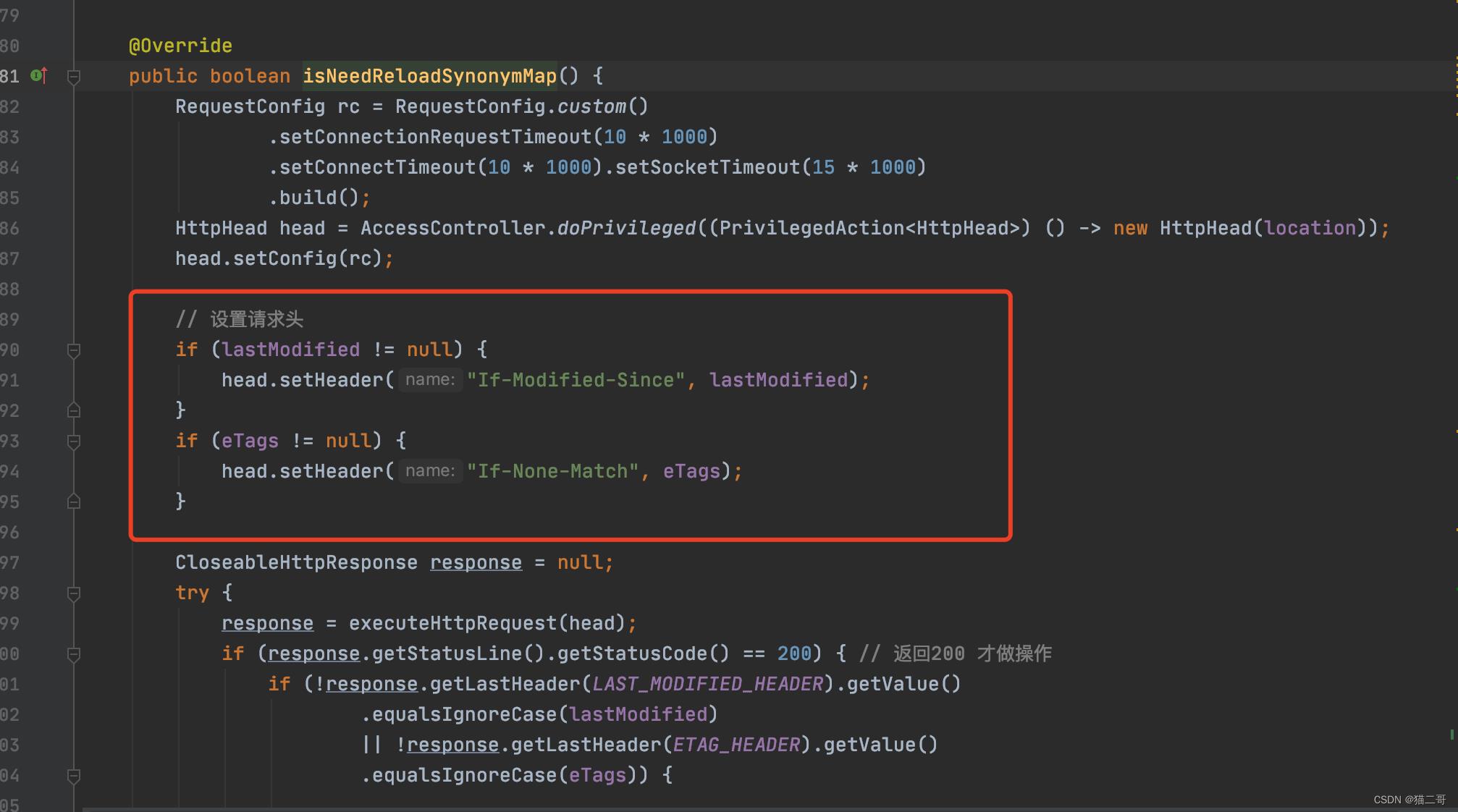
2 每次同步都是全量同步
那么这个接口的最终方式就是,根据你自定义lastModified来判断是否有更新,如果有更新,那么就全量把数据全量同步出去,如果没有就返回"“,如果返回空es不会更新老的值,所以有个关注点是,如果删除了所有的同义词,不能直接返回”",自己随便写一条正常的数据过去吧,比如1,1。
3接口如果报异常之后,es不会在定时去调用接口同步同义词,最后补充原因
4 初始化索引接口
@Autowired
VideoUserRepository videoUserRepository;
@Autowired
RestHighLevelClient restHighLevelClient;
@Autowired
ElasticsearchOperations elasticsearchOperations;
// 初始化索引
@GetMapping("/video-user/init")
public void init()
IndexOperations indexOperations = elasticsearchOperations.indexOps(VideoUserTestDO.class);
MappingBuilder builder = new MappingBuilder(elasticsearchOperations.getElasticsearchConverter());
String mapping = builder.buildPropertyMapping(VideoUserTestDO.class);
Document document = Document.parse(mapping);
try
if (indexOperations.exists())
indexOperations.delete();
LogUtils.info(log, "索引已经存在,重新创建。");
indexOperations.create();
indexOperations.putMapping(document);
LogUtils.info(log, "索引创建成功...");
catch (Exception e)
LogUtils.error(e, log, "索引创建失败.原因:");
重点:
1 spring虽然会帮我们自动生成索引,但是@Setting(settingPath = “es/settings.json”) 这个不会自动生成, 这个@Field(type = FieldType.Text, searchAnalyzer = “synonym”, analyzer = “ik_max_word”)的 searchAnalyzer,analyzer 不会自动生成。反正我实验没成功,还是手动生成好点。
2 init方法只能在没有索引的时候才用,如果在已有的索引上添加字段,那么直接去调用es接口。个人是这样处理了,如果有其他方法,告诉我下,我学习一下。
5保存数据到es
es操作对象类
package com.ibird.pandaserviceadmin.es.repository;
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
import com.ibird.pandaserviceadmin.es.model.VideoUserTestDO;
public interface VideoUserRepository extends ElasticsearchRepository<VideoUserTestDO, String>
@GetMapping("/video-user/save")
public void save()
for (int i = 1; i < 6; i++)
VideoUserTestDO tmp = new VideoUserTestDO();
tmp.setId(i + "");
tmp.setUserName("萱萱" + i);
tmp.setNickName("萱萱的昵称" + i);
tmp.setInfo("我是萱萱的介绍");
tmp.setDesc("我是描述" + i);
List<VideoUserVideoInfoDO> list = new ArrayList<>();
for (int j = 0; j < 5; j++)
VideoUserVideoInfoDO videoUserVideoInfoDO = new VideoUserVideoInfoDO();
videoUserVideoInfoDO.setId("" + j);
videoUserVideoInfoDO.setName("我是萱萱名字" + j);
list.add(videoUserVideoInfoDO);
tmp.setUserVideoInfoDOs(list);
videoUserRepository.save(tmp);
没啥好说的
6查询接口
@GetMapping("/video-user/search")
public String search(String word)
// boost评分权重
// 调用一个方法查询到他的同义词
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
boolQuery.should(QueryBuilders.termQuery("userName.keyword", word).boost(100));
boolQuery.should(QueryBuilders.matchQuery("userName", word).boost(10));
boolQuery.should(QueryBuilders.termQuery("userVideoInfoDOs.name.keyword", word).boost(10));
boolQuery.should(QueryBuilders.matchQuery("userVideoInfoDOs.name", word).boost(10));
searchSourceBuilder.from(0);
searchSourceBuilder.size(100);
FunctionScoreQueryBuilder functionScoreQueryBuilder = QueryBuilders.functionScoreQuery(boolQuery);
searchSourceBuilder.query(functionScoreQueryBuilder)
.sort("hotNum", SortOrder.DESC).sort("_score", SortOrder.DESC);
SearchRequest searchRequest = new SearchRequest("video-user-test");
searchRequest.source(searchSourceBuilder);
try
final SearchResponse search = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
final SearchHits hits = search.getHits();
final SearchHit[] hits1 = hits.getHits();
List<VideoUserTestDO> list = new ArrayList<>();
for (SearchHit documentFields : hits1)
VideoUserTestDO videoUserTestDO = JSON.parseObject(documentFields.getSourceAsString(), VideoUserTestDO.class);
list.add(videoUserTestDO);
return JSON.toJSONString(list);
catch (IOException e)
e.printStackTrace();
return "";
查询接口,没什么好说的,就是所有满足添加的should查询(或者关系),然后跟你感觉重要的字段增加boost权重。最后根据自定义的热度值和es算出来的_score得分排序,得出结果。
不知道_score怎么计算的
4 同义词插件问题
背景:采用远程热更新,es会调用应用提供的一个获取同义词的接口,如果接口报异常之后(服务重启,挂了),es不会在定时去调用接口同步同义词,当时重启es也可以解决。
原因如下:是使用ScheduledThreadPool 这个定时的线城池定时调用接口,如果远程调研的子线程远程调用异常(应用服务挂了,超时,网络问题等),主线程不会在调用该任务。
private static final ScheduledExecutorService pool = Executors.newScheduledThreadPool(1, r ->
Thread thread = new Thread(r);
thread.setName("monitor-synonym-Thread-" + id.getAndAdd(1));
return thread;
);
scheduledFuture = pool.scheduleAtFixedRate(new Monitor(synonymFile),
interval, interval, TimeUnit.SECONDS);
解决方案:
修改源码中的:
RemoteSynonymFile的这个方法reloadSynonymMap
public boolean isNeedReloadSynonymMap()
RequestConfig rc = RequestConfig.custom()
.setConnectionRequestTimeout(10 * 1000)
.setConnectTimeout(10 * 1000).setSocketTimeout(15 * 1000)
.build();
HttpHead head = AccessController.doPrivileged((PrivilegedAction<HttpHead>) () -> new HttpHead(location));
head.setConfig(rc);
// 设置请求头
if (lastModified != null)
head.setHeader("If-Modified-Since", lastModified);
if (eTags != null)
head.setHeader("If-None-Match", eTags);
CloseableHttpResponse response = null;
try
response = executeHttpRequest(head);
if (response.getStatusLine().getStatusCode() == 200) // 返回200 才做操作
if (!response.getLastHeader(LAST_MODIFIED_HEADER).getValue()
.equalsIgnoreCase(lastModified)
|| !response.getLastHeader(ETAG_HEADER).getValue()
.equalsIgnoreCase(eTags))
lastModified = response.getLastHeader(LAST_MODIFIED_HEADER) == null ? null
: response.getLastHeader(LAST_MODIFIED_HEADER)
.getValue();
eTags = response.getLastHeader(ETAG_HEADER) == null ? null
: response.getLastHeader(ETAG_HEADER).getValue();
return true;
else if (response.getStatusLine().getStatusCode() == 304)
return false;
else
logger.info("remote synonym return bad code ", location,
response.getStatusLine().getStatusCode());
catch (Exception e)
logger.error("远程调用同义词异常", e);
finally
try
if (response != null)
response.close();
catch (IOException e)
logger.error("failed to close http response", e);
return false;
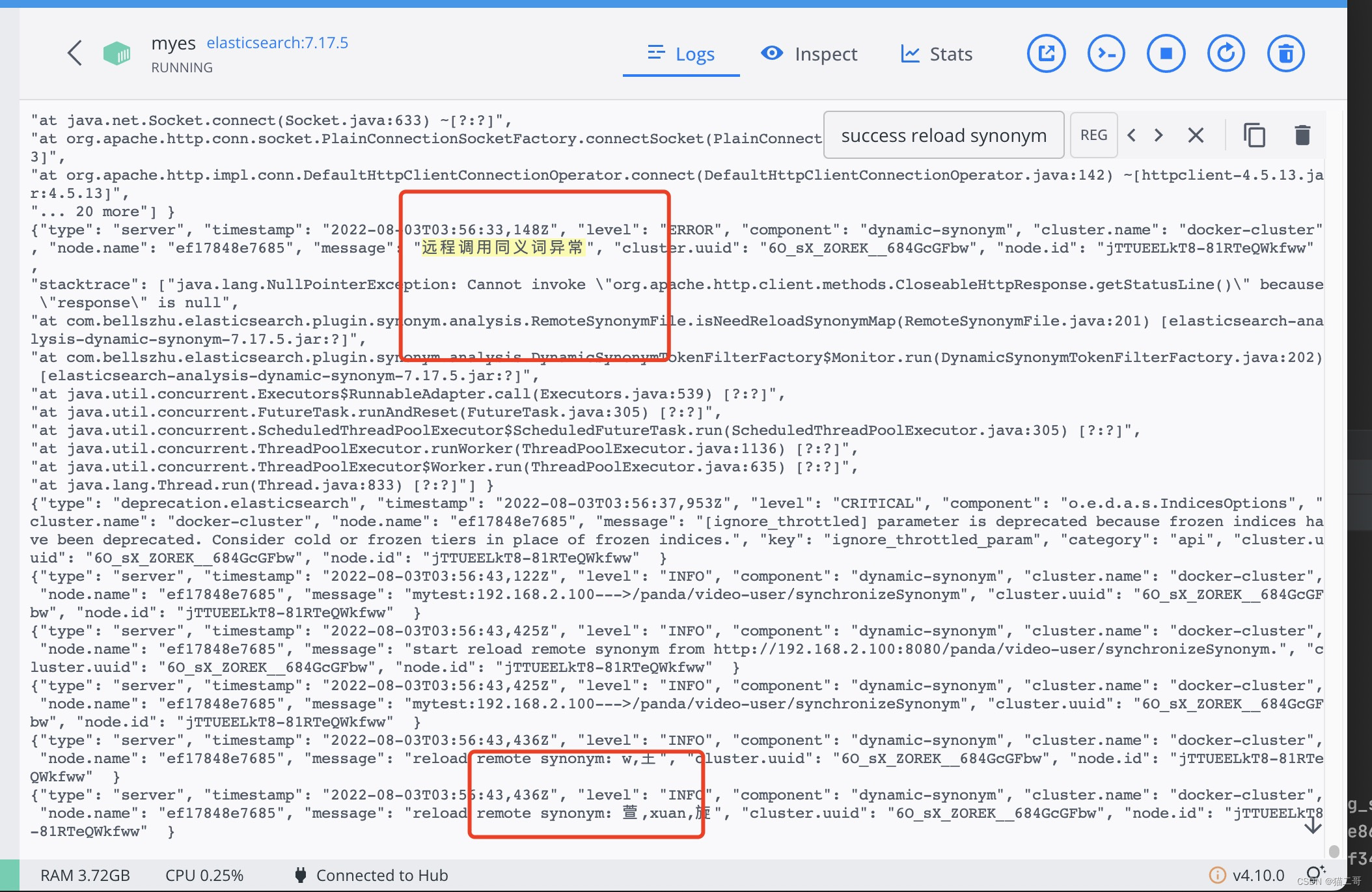
就是新增了一个catch,这样,就解决了
catch (Exception e)
logger.error("远程调用同义词异常", e);
效果如下:
以上是关于es使用同义词插件注意事项的主要内容,如果未能解决你的问题,请参考以下文章