关于 Android 稳定性优化你应该了解的知识点
Posted 初一十五啊
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了关于 Android 稳定性优化你应该了解的知识点相关的知识,希望对你有一定的参考价值。
前言
android 稳定性优化是一个需要长期投入,持续运营和维护的一个过程,不仅深入探讨了 Java Crash、Native Crash 和 ANR 的解决流程及方案,还分析了其内部实现原理和监控流程。本文对稳定性优化方面的知识做了一个全面总结,主要内容如下:
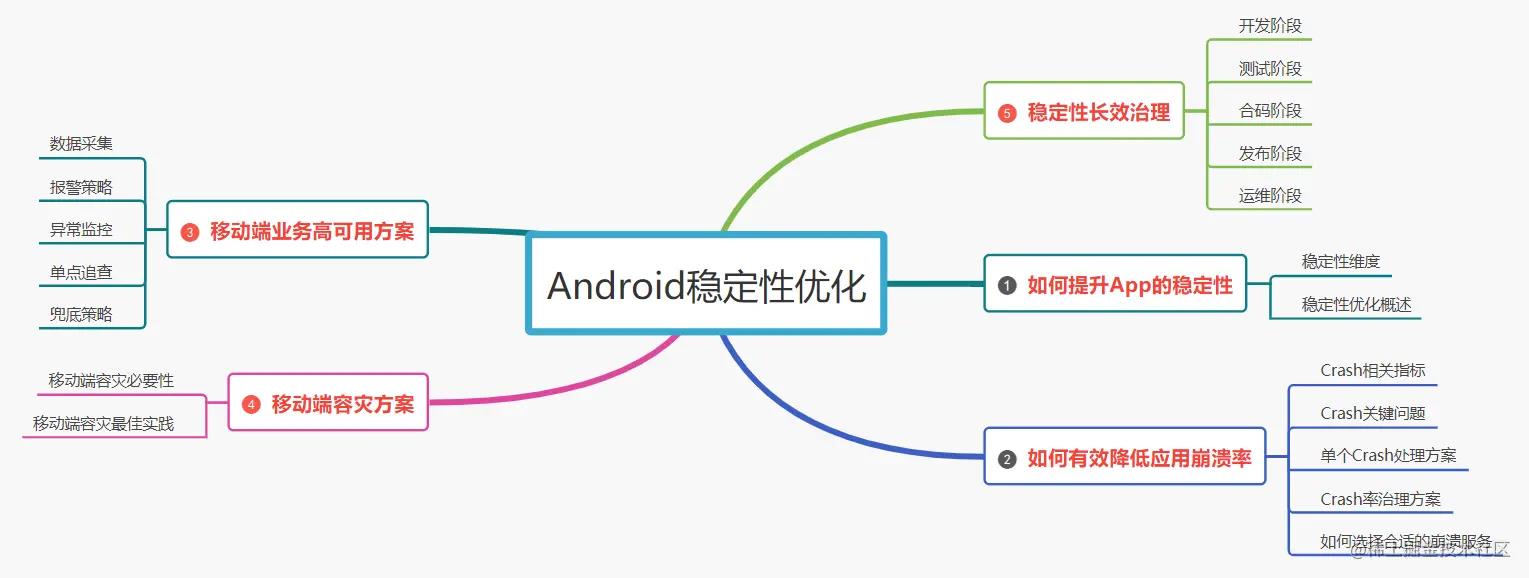
腾讯T10+最新最全Android笔记大全文档+23种设计模式
包含:
Android基础-性能优化-Framework-compose开源项目-音视频初中高-架构-车载-Flutter-Kotlin-鸿蒙+23种设计模式详解。
如何提升App的稳定性
一般性的App能接触到稳定性的需求其实并不多,只有大型的处于稳定运营期的App才会重视App的稳定性,稳定性实际上是一个大问题,一个稳定的产品才能够保证用户的留存率,所以稳定性是质量体系中最基本也是最关键的一环:
- 稳定性是大问题,Crash是P0优先级:对于用户来说很难容忍你的应用发生崩溃
- 稳定性可优化的面很广:不仅仅是指崩溃,像卡顿、耗电等也属于稳定性优化的范畴,对于移动端高可用这个标准来说,性能优化只是高可用的一部分,还有一部分就是应用业务流程功能上的可用
稳定性维度
- Crash维度:一般会将Crash单独作为一项重要指标进行突破,最常见的统计指标就是Crash率,后面会说到
- 性能维度:启动速度、内存、卡顿、流量、电量等等,在解决应用的Crash之后,就应该着手保障性能体系的稳定
- 业务高可用维度:业务层面的高可用是相当关键的一步,需要使用多种手段去保障App业务的主流程及核心路径的可用性
稳定性优化概述
如果App到了线上才发现异常,其实已经造成了损失,所以稳定性优化重点在于预防
- 重在预防、监控必不可少:从开发到测试到发布上线运维这些各个阶段都需要预防异常的发生,或者说要将发生异常造成的损失降到最低,用最小的代价暴露最多的问题,同时监控也是必不可少的一步,需要拥有一定的监控手段来更加灵敏的发现问题
- 思考更深一层、重视隐含信息:比如你发现了一个崩溃,但是你不能简单的只看这一个崩溃,要考虑这个崩溃是不是在其他地方也有同样或者类似的,如果有就考虑是否统一处理,今后该如何预防,总结经验
- 长效保持需要科学流程:在项目的每一个阶段建立完善的相关规范,保证长效的优化效果
如何有效降低应用崩溃率
Crash相关指标
1.UV、PV Crash率
- UV Crash率:等于Crash UV/DAU:主要针对于用户使用量的统计,它统计一段时间内所有用户中发生过崩溃的用户占比,和UV强相关,UV是指Unique Visitor一天内访问网站的人数(是以cookie为依据),一天内同一访客的多次访问只计算为1,一台电脑不同的浏览器的cookie值不同。
- PV Crash率:针对用户使用频率的统计,统计一段时间内所有用户启动次数中发生崩溃的占比,和PV强相关,PV是指PageView也就是页面点击量,每次刷新就算一次浏览,多次打开同一页面会累加。
- UV Crash方便评估用户影响范围,PV Crash方便评估相关Crash的影响严重程度
- 注意:沿用同一种衡量方式:不管你是使用UVCrash还是PVCrash作为主要指标,你应该一直使用它,因为和Crash率相关的会有一些经验值,这些经验值需要对应一个衡量指标
2.Java、Native Crash率
- Java Crash:在Java代码中,出现了未捕获的异常,导致程序异常退出
- Native Crash:一般都是因为在Native代码中访问非法地址,也可能是地址对齐出现了问题,或者发生了程序主动abort,这些都会产生相应的signal信号,导致程序异常退出。目前Native崩溃中最成熟的方案是BreakPad。
3.启动、重点流程Crash率
- 启动Crash率:在启动阶段用户还没有完全打开就发生了崩溃的占比,只要是用户打开App10s之内发生的崩溃都被视为启动Crash,它是Crash分类中最严重的一类,我们需要重点关注这个指标,而且降低的越低越好,并且我们应该结合客户端的容灾策略进行自主修复
4.增量、存量Crash率
- 增量Crash:指新增Crash,它是新版本Crash率变动的原因,如果没有新增的Crash,那么新版本的Crash率应该是和老版本Crash率保持一致,所以增量Crash是新版本中需要重点解决的问题
- 存量Crash:指老版本中已经存在的Crash,这些Crash一般都是难以解决或者是需要在特定场景下才会出现的难以复现的问题,这类问题需要长期投入精力持续解决
- 优先解决增量、持续跟进存量
5.Crash率评价指标
- 务必在千分之二以下:Java和Native的崩溃率加起来需要在千分之二以下才能算是合格的
- Crash率处于万分位视为优秀的标准
Crash关键问题
1.尽可能还原Crash现场
一旦发生崩溃,我们需要尽可能保留崩溃现场信息,这样有利于还原崩溃发生时的各种场景信息,从而推断出可能导致崩溃的原因,对于采集环节可以参考以下采集点:
- 采集堆栈、用户设备、OS版本、发生崩溃的进程、线程名、崩溃前后的Logcat
- 前后台、使用时长、App版本、小版本、渠道
- CPU架构、内存信息、线程数、资源包信息、行为日志
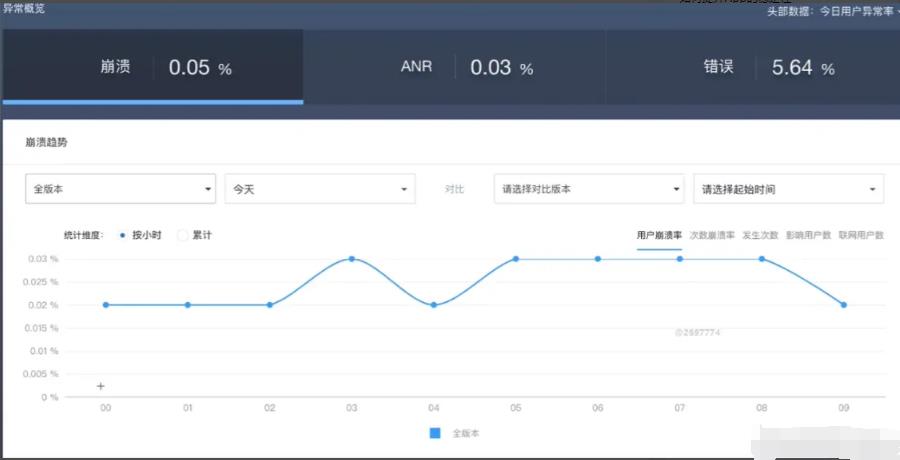
上面是一张Bugly后台的截图,对于成熟的性能监控平台不仅有Crash的单独信息,同时会对各种Crash进行聚合以及报警。
2.APM后台聚合展示
- Crash现场信息:包括Crash具体堆栈信息及其它额外信息
- Crash Top机型、OS版本、分布版本、发生地域:有了这些Top Crash信息之后就能够知道哪些Crash的影响范围比较大需要重点关注
- Crash起始版本、上报趋势、是否新增、持续版本、发生量级等等:可以从多个视角判断Crash发生的可能原因以及决定是否需要修复,在哪些版本上进行修复
3.Crash相关的整体架构

4.非技术相关的关键问题
建立规范的流程保证开发人员能够及时处理线上发生的问题:
- 专项小组轮值:成立专门小组来跟踪每个版本周期之内线上产生的Crash,保证一定有人跟进处理
- 自动分配匹配:可以自定义某些业务模块名称,自动分配给相应人员处理
- 处理流程全纪录:记录相应人员处理Crash的每一步,后期出现问题追究相关责任人也是有据可查的
单个Crash处理方案
- 根据堆栈及现场信息找答案:一般来说堆栈信息可以帮助我们解决90%的问题
- 找共性比如机型、OS、实验开关、资源包等:有些Crash信息通过堆栈找不到有用的帮助,不能直接解决,这种情况下可以通过Crash发生时的各种现场信息作辅助判断,分析这些Crash用户拥有哪些共性
- 线下复现、远程调试:有了共性之后尝试在线下进行复现,或者尝试能否进行远程调试
Crash率治理方案
- 解决线上常规Crash:抽出一定时间来专门解决所有常规的Crash,这些Crash一般相对来说比较容易解决
- 系统级Crash尝试Hook绕过:当然Android系统版本一直在不断的升级,随着新系统的覆盖率越来越高,老版本的系统Bug可能会逐渐减少
- 疑难Crash重点突破、更换方案:做到长期跟踪,团队合作重点突破,实在不行可以考虑更换实现方案
通过以上几点应该可以解决大部分的存量Crash,同时再控制好新增Crash,这样一来整体的Crash率一般都能够得到有效降低。
这一部分的内容有点杂而多,一般也是需要多端配合,所以不太好做具体演示,大家可以在网上多查找相关资料进行巩固学习。
如何选择合适的崩溃服务
- 腾讯Bugly: 除了有crash数据还有运营数据
- UC 啄木鸟:可以捕获Java、Native异常,被系统强杀的异常,ANR,Low Memory Killer、killProcess。技术深度以及捕获能力强
- 网易云捕:继承便捷,访问快,捕获以及上报速度及时,支持实时报警,提供多种报警选项,可以自定义参数。
- Google的Firebase
- crashlytics:服务器在国外,访问速度慢,会丢掉数据
- 友盟:crash之后会在再次启动的时候上报数据,所以不能立即获得这部分信息
移动端业务高可用方案
移动端高可用方案不仅仅是指性能方面的高可用,业务方面的高可用也是尤为重要的,如果业务都走不通,试问你性能做的再好又有何用呢?
- 高可用:性能+业务
- 业务高可用侧重于用户功能完整可用
- 业务高可用影响公司实际收入:比如支付流程不通
对于业务是否可用不像Crash一样,如果发生Crash我们可以收到系统的回调,业务不可用实际上我们是无从知道的,所以针对建设移动端业务高可用的方案总结以下几点:
1.数据采集
- 梳理项目主流程、核心路径、关键节点:一般需要对项目主流程和核心路径做埋点监控,比如用户下单需要从列表页到详情页再到下单页,这就是一个核心路径,我们可以监控具体每个页面的到达率和下单成功率
- AOP自动采集、统一上报:数据采集的时候可以采用AOP的方式,减少接入成本,上报的时候可以采取统一的上报减少流量和电量消耗,上传到后台之后再做详细的分析,得出所有业务流程的转化率,以及相应界面的异常率
2.报警策略
- 阈值报警:比如某个业务失败的次数超过了阈值就报警通知
- 趋势报警:对比前一天的异常情况,如果增加的趋势超过了一定的比例即便是未达阈值也要触发报警
- 特定指标报警、直接上报:比如支付SDK调用失败,这种错误无需跟着统一的数据上报,出现立即上报
3.异常监控
- Catch代码块:实际开发中我们为了避免程序崩溃,经常会写一些trycatch()来捕获相关异常,但是这样操作完成之后,程序确实不崩溃了,相应的功能也是无法使用的,所以这些被Catch住的异常也要上报,有利于分析功能不可用的原因
- 异常逻辑:比如我们需要对结果为true的调用方法进行处理,结果为false时不执行任务,但是我们也需要上报异常,统计一下出现这种情况的用户的占比情况,以便针对性的优化
这里简单的举个栗子,表明意思:
try
//业务处理
LogUtils.i("...");
catch (Exception e)
//如果未加上统计,就无法知道具体是什么原因导致的功能不可用
ExceptionMonitor.monitor(Log.getStackTraceString(e));
boolean flag = true;
if (flag)
//正常,继续执行相关任务
else
//异常,不执行任务,这种情况产生的异常也应该进行上报
ExceptionMonitor.monitor("自定义业务失败标识");
4.单点追查
- 需要针对性分析的特定问题:这些问题相对小众,很可能是和特定用户的操作习惯、账户体系相关,所以要尽可能获取多的数据重点分析
- 全量日志回捞,专项分析:很多日志信息默认都是只记录不上传,比如用户全部的行为日志,这些日志只有在需要的时候才有用,平时没必要上传,没啥用还浪费流量,如果需要排查特定用户的详细信息,也可以通过服务端下发指令客户端接收指令后上传
5.兜底策略
当你通过监控了解到业务不正常之后,请问该如何修复?这里就要用到兜底策略了,就是到了最后一步各种措施都做了,用户还是出现了异常,这种情况仍然还是要有相关联的配置手段来达到高可用。对于业务上的异常除了热修复的手段之外,还可以通过建立配置中心,将功能开关关闭。
- 配置中心,功能开关:实际项目中很多数据都是通过服务端动态下发配置的,将这些功能集合起来的处理平台就是配置中心。举个栗子:比如新版本上线了一个新功能,加了一个入口,上线之后发现功能不稳定,此时就可以通过服务端配置的方式将此功能开关关闭,这样即使用户无法使用新功能,但是至少不会发现业务的异常
- 跳转分发中心:熟悉组件化开发的朋友都知道做组件化module的拆分必不可少的就是要有一个路由,它的作用就是跳转分发中心,所有的跳转都是通过路由来做,如果匹配到需要跳转到有Bug的功能界面时可以统一跳转到一个异常处理的页面
移动端容灾方案
移动端容灾必要性
说到容灾,首先来看一下需要防范的灾是什么?主要分为两部分:性能异常和业务异常,只要是对用户的实际体验产生了很大的影响,都是需要防范的App线上灾害。
- 灾:性能、业务异常
传统的流程是如何处理线上出现的紧急问题的呢?传统的处理流程首先需要用户反馈出现的不正常情况,接着开发人员进行紧急的BUG修复,然后重新打包上传渠道进行更新,可见传统的流程比较繁琐,灵敏度较低,如果日活量较高,随着Bug在线上存活的时间延长对用户基数的影响是巨大的,势必是无法接受的
- 传统流程:用户反馈、重新打包、渠道更新,不可接受
移动端容灾最佳实践
1.功能开关
- 配置中心,服务端下发配置控制:首先对任何新上线的功能加上功能开关,可以通过配置中心的方式下发开关决定是否显示新功能的入口,出现异常情况可以随时关闭入口,这样可以保证上线的新功能处于可控状态
- 针对场景,功能新加或代码改动:一是新增了功能,二是出现了代码改动,比如重构代码,最好保留之前的老方案,在新方案上线之后如果有问题,可以切回之前的老方案
这里简单的做个演示:
public class ConfigManager
public static boolean mOpenClick = true; //默认值为true
mAdapter.setOnItemClickListener((view, position) ->
//控制点击事件是否开启
if (ConfigManager.mOpenClick) //mOpenClick的值从接口获取,由服务端控制
//处理具体业务
);
2.统跳中心
组件化之后的项目的页面跳转都是通过路由来做的,如果发现线上产生了异常,可以在路由跳转这一步拦截有Bug的跳转,重定向到备用方案,或者统一的错误处理中界面,更多的情况是为了对线上用户产生的影响降到最低,如果有Bug不能进行热修复,也没有合适的开关可用,会做一个临时的H5页面,让用户点击之后跳转到临时的H5页面,这样用户还是可以操作,只是在体验上稍微差一点,总归来说比不能用强的多
- 界面切换通过路由,路由决定是否重定向
- Native Bug不能热修则跳转到临时H5
3.动态化修复
目前为止,国内市场安卓的热修复方案已经比较成熟了,对于大型项目来说,一般都会支持热修复的能力,热修复技术就是用户不需要重新安装一个Apk,就可以实现比原有Apk有较大更新的能力,比如微信的Tinker和美团的Robust都是非常好的热修复实现方案。需要注意的是,热修复也只是一个功能,对于热修复也需要加上各种完善的统计,需要知道热修方案是否真正有效果,没有用造成更大的损失
- 热修复能力,可监控、灰度、回滚、清除
- 推拉结合、多场景调用保证到达率
- Weex、RN增量更新
4.安全模式
安全模式侧重于移动端发生严重Crash时的自动恢复,做的好的安全模式往往会有几级不同的策略,比如App多次启动失败,那就重置整个App到安装的状态,避免因为一些脏数据导致的App持续闪退,同时如果有Bug并且非常严重到了最严重的等级,可以采用阻塞性热修来解决,即:必须等热修成功之后才可进入主页面。需要注意的是,安全模式不仅仅可以针对App Crash,也可以针对一些组件,比如网络请求多次失败后也可以进入安全模式,暂时拒绝用户的网络请求,避免给服务端造成的额外压力
- 根据Crash信息自动恢复,多次启动失败重置App
- 严重Bug可阻塞性热修复
- 异常熔断:多次请求失败则主动拒绝
容灾方案总结:

这几种方式是由简单到复杂的递进,为了保障线上的稳定性,最好在应用中多加入几个稳定性保障方案。
稳定性长效治理
对于稳定性优化来说是一个细活,需要打持久战,不能一个版本优化了,后面又恶化了,因此需要在项目开发的整个周期内的不同阶段都加上相应的方案。
1.开发阶段
在开发阶段组内每个开发人员的编码实力都是不一样的,因此需要统一编码规范,然后结合一些手段增强人员的编码功底,尽可能的将问题消灭在编码阶段,尽可能的写出高质量的代码,同时要结合开发阶段的技术评审,以及每天的互相CodeReview机制,坚持几个月编码水平肯定会有明显的提升,开发阶段明显的问题应该就不会再有了,而且代码风格结构也会大体一致。同时开发阶段还需要做的事情就是架构优化,项目的架构应该根据项目的不同发展阶段来不断优化,这里说两点,第一能力收敛比如界面切换的能力用路由来实现,对网络请求要统一网络库统一使用方式,这样可以避免不正当的使用带来的Bug,第二统一容错,比如对于网络请求来说可以在网络请求回来的时候加上预先校验,判断回来的数据是否合法,如果不合法就不需要再把数据转给上层业务了
- 统一编码规范、增强编码功底、技术评审、CodeReview机制
- 架构优化:能力收敛、统一容错
2.测试阶段
- 功能测试、自动化测试、回归测试、覆盖安装
- 特殊场景、机型等边界测试
- 云测平台:辅助测试,满足对特殊机型的测试需求
3.合码阶段
开发时肯定是在自己的分支进行开发,测试通过之后才会往主干分支合入,合入之前首先需要进行代码的编译检查和静态扫描发现可能存在的问题,经过校验之后也不能直接合入,应该将自己的分支首先合入到一个和主干分支一样的分支中进行预编译,编译通过之后最好加上主流程的回归测试
- 编译检测,静态扫描
- 预编译流程、主流程自动回归
4.发布阶段
到了发布阶段一般来说App都是经过了开发自测、QA测试、内部测试等测试环节,相对来说比较稳定了,但是需要注意的是,很多问题你不可能全部测出来,所以必须谨慎对待
- 多轮灰度:灰度的量级要由小变多,争取以最小的代价暴露最多的问题
- 分场景、维度全面覆盖
5.运维阶段
任何一个小问题在海量用户面前都会影响巨大,因此这个阶段必须要依靠APM的灵敏监控
- APM灵敏监控
- 回滚、降级策略
- 热修复、容灾方案
如果你觉得以上的内容,还有点意犹未尽?毕竟学无止境。那么还能即时领取一份,【腾讯T10面试笔记文档大全】(部分资料整理来自互联网),内容如下:
即时领取→【腾讯T10面试笔记文档大全+23种设计模式】
腾讯T10+最新最全Android笔记大全文档
包含:
Android基础-性能优化-Framework-compose开源项目-音视频初中高-架构-车载-Flutter-Kotlin-鸿蒙+23种设计模式详解。
1.Android基础篇
涉及:注解,泛型,Retrofit,ButterKnife,动态代理和反射原理,AOP,JavaSSit,ASM,虚拟机面试,热修复Tinker.
2.性能优化能力
涉及:启动优化实战,内存优化,启动速度优化,卡顿,布局,崩溃优化及其处理,启动全流程分析(源码深度剖析)
3.Framework
涉及:Framework通信,Framework底层服务,Framework事件机制
4.Compose【开源项目】

5.音视频(涉及:C和C++基础语法,H264编码基础和进阶,H265编码原理和应用MediaCodec硬解码,Media内核源码,微信视频通话。初级-中-高)
6.架构
(涉及:Arraylist,Okhttp,Retrofit,图片加载,Dagger 2,MVC.MVP.MVVM,Jetpack Room
7.Android车载工程师
涉及:Android Auto,汽车媒体应用,构建Android Auto即时通信应用,构建车载导航和地图注点应用,构建Android Automotive OS视频应用,测试Android车载应用,分发Android汽车应用,适用于汽车的Google Play服务,Android Automotive OS的通知
8.Flutter
涉及:Dart语法,Flutter动画丶组件丶网络请求以及Flutter3.0简介。
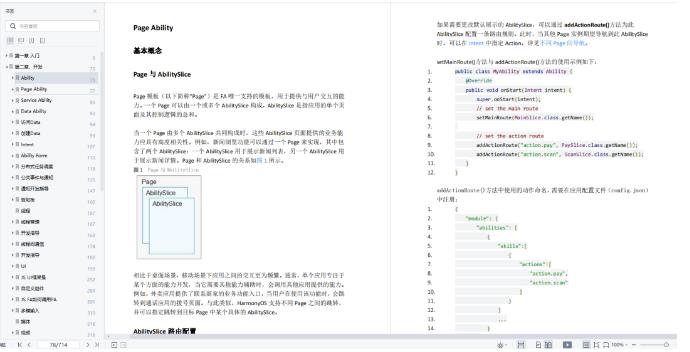
9.鸿蒙相关
涉及:Ability组件,分布式任务,事件总线,鸿蒙线程,UI自定义控件
10.Kotlin
涉及:对象.类.继承.变量.常量.拓展.函数等二十多个内容

从事互联网开发,最主要的是要学好技术
而学习技术是一条慢长而艰苦的道路,不能靠一时激情,也不是熬几天几夜就能学好的
必须养成平时努力学习的习惯,更加需要准确的学习方向达到有效的学习效果
希望大家都能够拿到心仪的offer,一起升职加薪😊!
腾讯T10+最新最全Android笔记大全文档+23种设计模式
包含:
Android基础-性能优化-Framework-compose开源项目-音视频初中高-架构-车载-Flutter-Kotlin-鸿蒙+23种设计模式详解。
作者:小尘
链接:https://juejin.cn/post/7127912072519614494
以上是关于关于 Android 稳定性优化你应该了解的知识点的主要内容,如果未能解决你的问题,请参考以下文章
Android-架构组件,节省你重复造轮子时间大厂面试题汇总