监控仪表系统Grafana 中文入门教程 | 构建你的第一个仪表盘
Posted 逆流°只是风景-bjhxcc
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了监控仪表系统Grafana 中文入门教程 | 构建你的第一个仪表盘相关的知识,希望对你有一定的参考价值。
Grafana 读音:/grəˈfɑːnˌɑː/
Grafana 中文入门教程
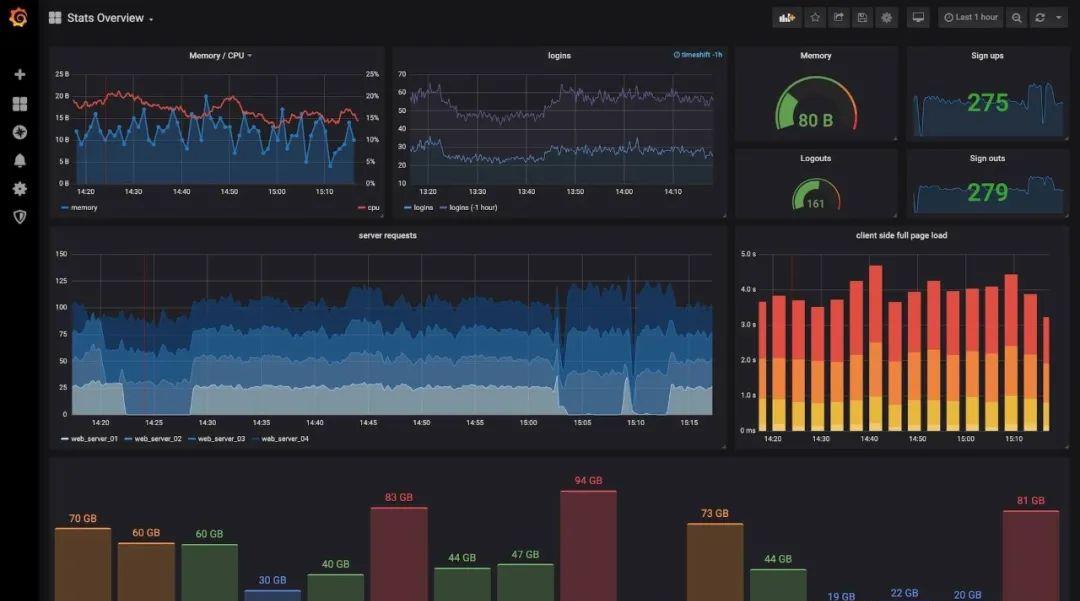
在大厂工作久了,时常对一些工具的存在觉得理所当然。
比如说,需要计算资源的时候,一个配置文件就可以要来两百台虚拟化好的机子。需要试下缓存?点下鼠标就可以要到几十个配置好的 Redis 结点。
最省心的是,这些工具都已经根据工作流配置好了:鉴权、优化、网络连接等等通通不用你操心。
但一切要自己撸起袖子干的时候,开始发现各种踩坑。拿 Grafana 和服务监控来说:
- 服务监控到底咋配置?怎样保证数据安全?
- 保证健康的服务到底应该监控些什么?
- 配置好后的仪表盘为啥消失了?
- 查询 Query 又该咋写?
1. Grafana 是什么
开始前首先要问一个问题,Grafana 到底是什么。
Grafana 读音:/grəˈfɑːnˌɑː/, 是一个监控仪表系统,它是由 Grafana Labs 公司开源的的一个系统监测 (System Monitoring) 工具。它可以大大帮助你简化监控的复杂度,你只需要提供你需要监控的数据,它就可以帮你生成各种可视化仪表。同时它还有报警功能,可以在系统出现问题时通知你。
Grafana 不对数据源作假设,它支持以下各种数据,也就是说如果你的数据源是以下任意一种,它都可以帮助生成仪表。同时在市面上,如果 Grafana 称第二,那么应该没有敢称第一的仪表可视化工具了。因此,如果你搞定了 Grafana,它几乎是一个会陪伴你到各个公司的一件称心应手的兵器。
Grafana 支持的数据源
- Prometheus 本文中的例子,你没听过也没关系不影响阅读,把它想象成带时间戳的 mysql 就好
- Graphite
- OpenTSDB
- InfluxDB
- MySQL/PostgreSQL
- Microsoft SQL Server
- 等等
2. 什么情况下会用到 Grafana 或者监控仪表盘
通常来说,对于一个运行时的复杂系统,你是不太可能在运行时一边检查代码一边调试的。因此,你需要在各种关键点加上监控。
用开车作为例子:车子本身是一个极其复杂的系统,而当你的车在高速上以 120 公里的速度狂奔时出现了噪音,你是不可能这时候边开车边打开发动机盖子来查原因的。通常来说,好一点的车会有内置电脑,在车子出问题时,告诉你左边轮胎胎压有问题,或是发动机缺水了之类。而这些检测,就是系统监控的一个例子。
对于驾驶员来说,他们开车时只关心几个指标:
- 我的位置是哪里,在路中间么(当然这个无法通过监控系统实现,得看路)
- 我的速度是多少 - 速度仪表盘
- 我的油、发动机水温等等关键指标是多少 - 其它仪表盘
通过仪表盘,你不一定能清楚地了解车子出问题的具体原因,但至少可以给你一个大概的方向。比如- 说,如果水温很高时出现了问题,你大概率可以尝试加点水降温来尝试是否解决问题。
把上面的车换成计算机系统或者一个软件系统也是一样:仪表盘就是你的速度表和水温表,通过这些表盘你可以实时了解你的系统运行情况。
仪表盘应用极广,我能想到的一些例子:
- 阿里在双十一控制室用了监控仪表盘,因此所有双十一的新闻基本上都可以看到这个仪表盘
- 各酷炫公司大厅里常常放一个仪表盘来展示实力(用户数啦、营收啦之类)
- 你的 PC 上的资源管理器、Mac 上的 Activity Monitor 都是某种意义上的仪表盘
用一个卡拉搜索的实践作例子:
我们希望卡拉搜索能提供游戏级的搜索性能,比 Elastic Search 还快十倍。那么这就要求我们 99% 的搜索结果在 5-10 毫秒内要完成。因此,我们就需要添加这么一个仪表盘,能实时知道用户搜索的延迟,并且当搜索延迟超过 10 毫秒时通知到我们。
综上,在任何需要监控系统运行状况的地方就大概率会用到仪表盘,而用到仪表盘的时候就可以用 Grafana (不管你用什么语言)
3. 安装和配置 Grafana
为了简化各种系统不一致的乱七八糟问题,我们用 Docker 来安装 Grafana。(如果还没有安装 Docker 可以参考我们的教程 [如何安装 Docker](/tutorials/how-to-install-and-use-docker-on-ubuntu)。
Docker 的配置文件如下,就算你从来没用过 docker 也不用操心,我会在下文里一行一行讲明白。请不要复制粘贴代码,直接到本文的 GitHub 页 clone 代码即可,我会保证 GitHub 上的代码处理最新状态:https://github.com/Kalasearch/grafana-tutorial[5]
version: '3.4'
services:
prometheus:
image: prom/prometheus
container_name: prometheus
hostname: prometheus
ports:
- 9090:9090
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml
prometheus-exporter:
image: prom/node-exporter
container_name: prometheus-exporter
hostname: prometheus-exporter
ports:
- 9100:9100
grafana:
image: grafana/grafana
container_name: grafana
hostname: grafana
ports:
- 3000:3000
volumes:
- ./grafana.ini:/etc/grafana/grafana.ini
在这里我们启动了三个服务
- Prometheus 普罗米修斯时序数据库,用来存储和查询你的监控数据
- Promethues-exporter 一个模拟数据源,用来监控你本机的状态,比如有几个 CPU,CPU 的负载之类
- Grafana 本尊
在 clone 了代码之后,在你的本地运行 docker-compose up,应该会看到类似:
那么就说明服务已经跑起来了。注意,在之后的所有步骤中,你的 docker 应该处于运行状态。
在跑起来服务之后,到你的浏览器中,复制 http://localhost:3000 应该就可以看到 Grafana 跑起来的初始登录界面。初始的用户名是 admin,密码也是 admin。输入之后,会要求你改密码
然后就可以进入 Grafana 的主界面了:

到这里,你的 Grafana 就已经搭起来了。注意到 Docker 的配置文件中我们创建了三个服务,这三个服务之间分别有什么关系呢?
或者说,Grafana 和时序数据库,数据源之间有什么关系呢?请看下文 Grafana 工作原理
4. Grfana 工作原理
上面说到,Grafana 是一个仪表盘,而仪表盘必然是用来显示数据的。
Grafana 本身并不负责数据层,它只提供了通用的接口,让底层的数据库可以把数据给它。而我们起的另一个服务,叫 Prometheus (中文名普罗米修斯数据库)则是负责存储和查询数据的。
也就是说,Grafana 每次要展现一个仪表盘的时候,会向 Prometheus 发送一个查询请求。
那么配置里的另一个服务 Prometheus-exporter 又是什么呢?
这个就是你真正监测的数据来源了,Prometheus-exporter 这个服务,会查询你的本地电脑的信息,比如内存还有多少、CPU 负载之类,然后将数据导出至普罗米修斯数据库。
在真实世界中,你的目的是监控你自己的服务,比如你的 Web 服务器,你的数据库之类。
那么你就需要在你自己的服务器中把数据发送给普罗米修斯数据库。当然,你完全可以把数据发送给 MySQL (Grafana 也支持),但普罗米修斯几乎是标配的时序数据库,强烈建议你用。
用一张图[6]来说明它们之间的关系:

这里,最左边的 Docker 服务会将服务的数据发送给中间的普罗米修斯(对应上文的 Prometheus-exporter),而最右边的 Grafana 会查询中间的普罗米修斯,来展示仪表盘。
关于普罗米修斯本身也可以写一篇很长的教程了,这里我们先暂时略去不表。
5. 搭建你的第一个仪表盘
现在我们来搭建你的第一个仪表盘。
第 1 步 - 设置数据源
进入 Grafana 后,在左侧你会发现有一个 Data Source 即数据源选项
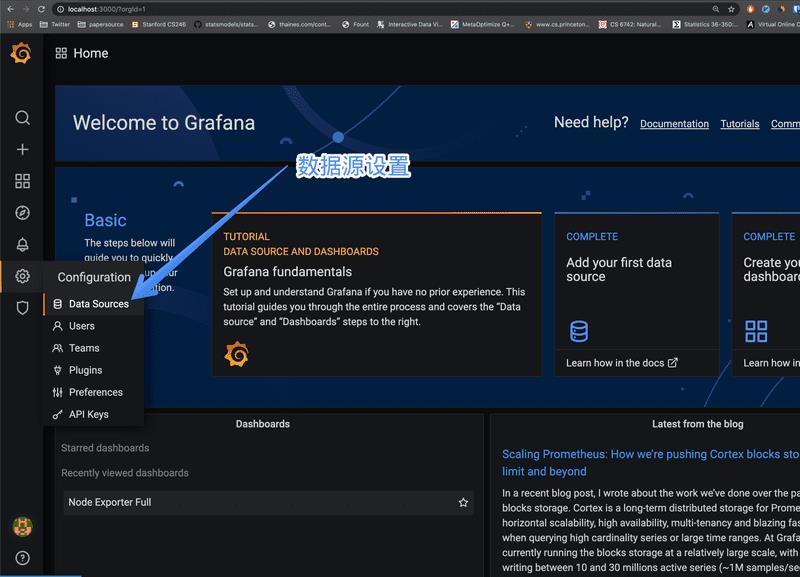
点击后进入,点 Add Data Source 即添加数据源,选择 Prometheus
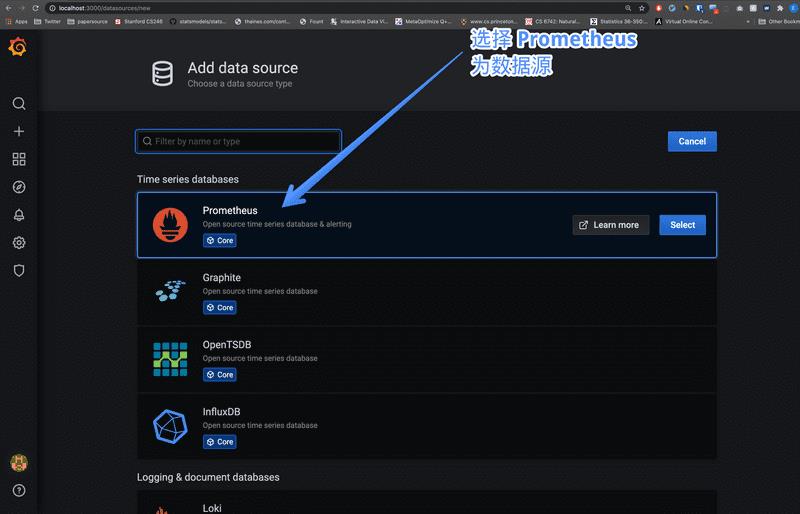
之后设置数据源 URL。请注意,Promethues 的工作原理(下一个教程中会讲)是通过轮询一个 HTTP 请求来获取数据的,而 Grafana 在获取数据源的时候也是通过一个 HTTP 请求,因此这个地方你需要告诉 Grafana 你的 Prometheus 的数据端点是什么。
这里我们填入 http://prometheus:9090 就可以了。
你可能会问,为什么不是 localhost:9090 呢?原因是,我们用了 docker-compose 起的三个服务,可以把它们想象成三台独立的服务器,因此需要用一个域名来互相通信。我们在 docker-compose.yml 中设置的普罗米修斯服务器的名字就叫 prometheus,因此这里需要用前者。

点确认时一定要确认出现 Data source is working 这个检测,这时表明你的 Grafana 已经跟普罗米修斯说上话了
第 2 步 - 导入 Dashboard
在 Grafana 里,仪表盘的配置可以通过图形化界面进行,但配置好的仪表盘是以 JSON 存储的。这也就是说,如果你把你的 JSON 数据分享出去,别人导入就可以直接导入同样的仪表盘(前提是你们的监测数据一样)。
对于我们的例子来说,回忆一下,因为我们用了 prometheus-exporter 也就是本机的系统信息监控,那么我们可以先找一个同样用了这个数据源的仪表盘。在 Grafana 网站上,你其实可以找到很多别人已经做好的仪表,可以用来监测非常多标准化的服务。
Grafana 的仪表盘市场:https://grafana.com/grafana/dashboards[8]
比如说针对以下一些服务的标准仪表盘就可以在这里找到
- JVM
- Spring Boot
- MySQL 监控
- Laravel 监控
那么,这里我们就用一个标准的仪表盘:https://grafana.com/grafana/dashboards/1860[9]
在左侧的加号里,点 Import 即导入,在出现的界面中填入 1860 即我们要导入的仪表盘编号即可。
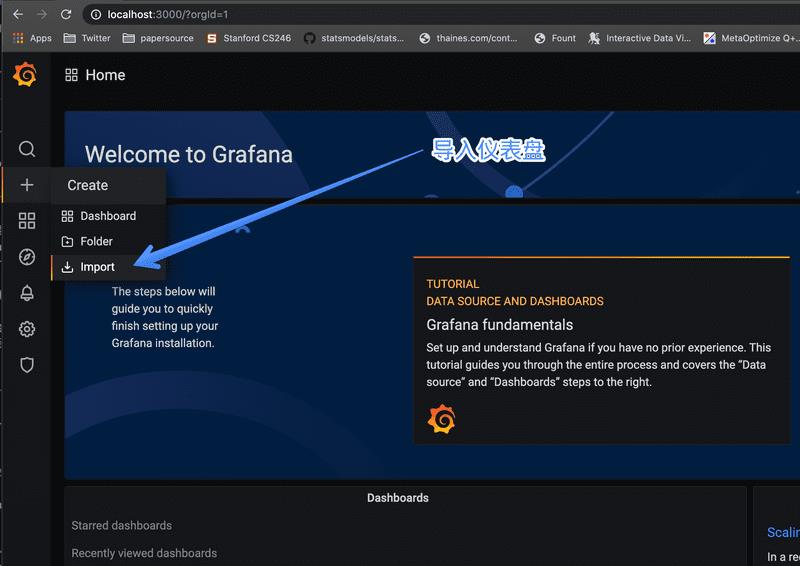
然后填入你需要的信息,比如仪表盘名字等
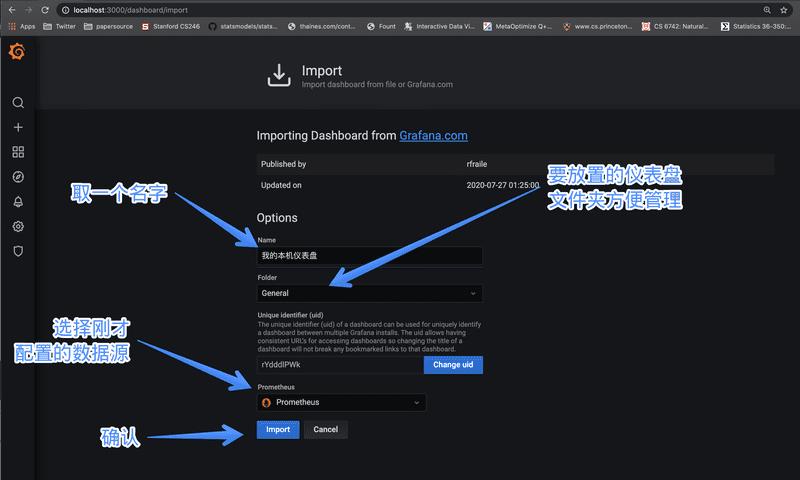
确认之后 Grafana 就会根据你的本机信息,生成类似 CPU 负载,内存和 I/O 之类的信息。我的磁盘状况如图:

要注意的是,这里的信息真正监控的是你的 Docker 中的系统信息。如果你只给你的 Docker 分配 1 个核和 2G 内存,那么这里应该看到的就是 1 个核和 2G 内存
第 3 步 - 生成和创建新的仪表盘
最后,在上面导入信息的基础上,你就可以开始创建和你的服务、业务相关的仪表盘了。
但在这步之前,你需要先在你的服务中开始记录一些数据。
如何在各种语言中记录你关注的数据?
拿卡拉搜索举例子,我们关注用卡拉搜索的 APP 的搜索响应速度,所以自然我们需要在所有搜索请求处记录延迟。
对于你的服务,你需要根据自己的业务确认哪些数据是重要的,关于如何记录数据,如何思考运维等,我会在之后的博客中继续深入讨论。如果你想更深入地了解这个领域,推荐阅读 Google 运维手册这本书,英文名叫《Google SRE Book》,免费的书。
包括如何用 Prometheus 查询数据
普罗米修斯本身也是个非常大的话题,我们会在之后的博客中继续讨论。普罗米修斯包括所有其它时序数据库通常都会定义一个查询语言,比如说 PromQL,如果需要熟练地构建仪表盘的话,需要对这个查询语言有一定了解。
如何手动生成一个仪表盘
假设你已经按上面的步骤生成了一个基本的仪表盘,那么现在可以开始手动添加仪表盘了。同样是点左侧的加号,点 Dashboard 就可以进入添加仪表盘的界面。
这里我们选择一个数据叫 scrape_duration_seconds,先不用管它的含义是什么,就当它是双 11 的销售额好了:

添加好后点右上角的 Apply 或 Save 你的仪表盘就被保存了。这时候,用一个大屏幕展示一下,庆祝一下双十一又过了千亿吧
6. 总结
这篇文章里我们从头到尾介绍了如何用 Grafana 生成仪表盘,如何配置和连接数据源,以及如何导入和创建一个仪表盘。
如果你的 App 或小程序需要搜索功能,也可以到卡拉搜索首页[10]了解一下我们的托管搜索服务。花 5 分钟接入,我们就可以帮你为你的用户提供比 ElasticSearch 还快 10 倍的搜索体验,提高转化率和用户留存。
本文参考了以下文章:
- How to explore prometheus with easy hello world projects[11]
- Node Exporter Guide[12]
- Grafana Tutorials[13]
- Grafana Simple Synthetic Monitoring[14]
- Grafana 快速入门[15]
基于grafana+prometheus构建Flink监控
先上一个架构图:
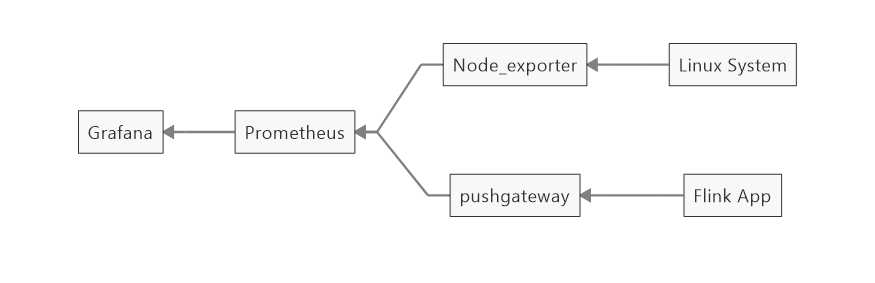
Flink App
: 通过report 将数据发出去
Pushgateway : Prometheus 生态中一个重要工具
Prometheus : 一套开源的系统监控报警框架 (Prometheus 入门与实践)
Grafana: 一个跨平台的开源的度量分析和可视化工具,可以通过将采集的数据查询然后可视化的展示,并及时通知(可视化工具Grafana:简介及安装)
Node_exporter : 跟Pushgateway一样是Prometheus 的组件,采集到主机的运行指标如CPU, 内存,磁盘等信息
以下安装,大部分参考博客: https://www.cnblogs.com/xiao987334176/p/9930517.html#autoid-0-0-0
1、docker pull 镜像
docker pull prom/node-exporter docker pull prom/pushgateway docker pull prom/prometheus docker pull grafana/grafana
查看下载的镜像

$ docker images REPOSITORY TAG IMAGE ID CREATED SIZE prom/prometheus latest d5b9d7ed160a 2 weeks ago 138MB grafana/grafana latest a6e14b4109af 2 weeks ago 253MB prom/pushgateway latest 20e6dcae675f 4 weeks ago 19.2MB prom/node-exporter latest e5a616e4b9cf 2 months ago 22.9MB
2、编辑prometheus.yml 、创建 Grafana 数据存储目录
$ mkdir /opt/grafana-storage # grafana 数据存储目录
$ cat /opt/prometheus/prometheus.yml # prometheus 配置
global:
scrape_interval: 60s
evaluation_interval: 60s
scrape_configs:
- job_name: prometheus
static_configs:
- targets: [‘localhost:9090‘]
labels:
instance: prometheus
- job_name: linux
static_configs:
- targets: [‘venn:9100‘]
labels:
instance: localhost
- job_name: ‘pushgateway‘
static_configs:
- targets: [‘venn:9091‘]
labels:
instance: ‘pushgateway‘
3、启动各个组件
docker run -d -p 3000:3000 --name=grafana -v /opt/grafana-storage:/var/lib/grafana grafana/grafana docker run -d -p 9100:9100 -v "/proc:/host/proc:ro" -v "/sys:/host/sys:ro" -v "/:/rootfs:ro" --net="host" prom/node-exporter docker run -d -p 9090:9090 -v /opt/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml prom/prometheus docker run -d -p 9091:9091 prom/pushgateway
查看docker进程
$ docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 4a689cf48e10 prom/pushgateway "/bin/pushgateway" 5 days ago Up 5 days 0.0.0.0:9091->9091/tcp infallible_goldstine fcc40433bf75 grafana/grafana "/run.sh" 5 days ago Up 5 days 0.0.0.0:3000->3000/tcp grafana 8ba942d0cf35 prom/prometheus "/bin/prometheus --c…" 5 days ago Up 5 days 0.0.0.0:9090->9090/tcp quizzical_colden b84b0f4be2b2 prom/node-exporter "/bin/node_exporter" 5 days ago Up 5 days fervent_poitras
查看端口
$ netstat -apn | grep -E ‘9091|3000|9090|9100‘ (Not all processes could be identified, non-owned process info will not be shown, you would have to be root to see it all.) tcp 0 0 172.17.0.1:39028 172.17.0.4:9091 ESTABLISHED - tcp6 0 0 :::9100 :::* LISTEN - tcp6 0 0 :::3000 :::* LISTEN - tcp6 0 0 :::9090 :::* LISTEN - tcp6 0 0 :::9091 :::* LISTEN - tcp6 0 0 192.168.229.129:45864 192.168.229.128:9091 TIME_WAIT - tcp6 0 0 192.168.229.129:45856 192.168.229.128:9091 TIME_WAIT - tcp6 0 0 192.168.229.129:45824 192.168.229.128:9091 TIME_WAIT - tcp6 0 0 192.168.229.129:45874 192.168.229.128:9091 TIME_WAIT - tcp6 0 0 192.168.229.129:45854 192.168.229.128:9091 TIME_WAIT - tcp6 0 0 192.168.229.129:45836 192.168.229.128:9091 TIME_WAIT - tcp6 0 0 192.168.229.129:45814 192.168.229.128:9091 TIME_WAIT - tcp6 0 0 192.168.229.128:9100 192.168.229.1:13405 ESTABLISHED - tcp6 0 0 192.168.229.129:45826 192.168.229.128:9091 TIME_WAIT - tcp6 0 0 192.168.229.129:45844 192.168.229.128:9091 TIME_WAIT - tcp6 0 0 192.168.229.128:9091 172.17.0.2:53930 ESTABLISHED - tcp6 0 0 192.168.229.129:45846 192.168.229.128:9091 TIME_WAIT - tcp6 0 0 192.168.229.128:9100 172.17.0.2:54776 ESTABLISHED - tcp6 0 0 192.168.229.129:45816 192.168.229.128:9091 TIME_WAIT - tcp6 0 0 192.168.229.129:45876 192.168.229.128:9091 ESTABLISHED 40846/java tcp6 0 0 192.168.229.129:45834 192.168.229.128:9091 TIME_WAIT - tcp6 0 0 192.168.229.129:45866 192.168.229.128:9091 TIME_WAIT -
4、查看组件页面
node_exporter: ip:9100/metrics
查看 prometheus: ip:9090/targets
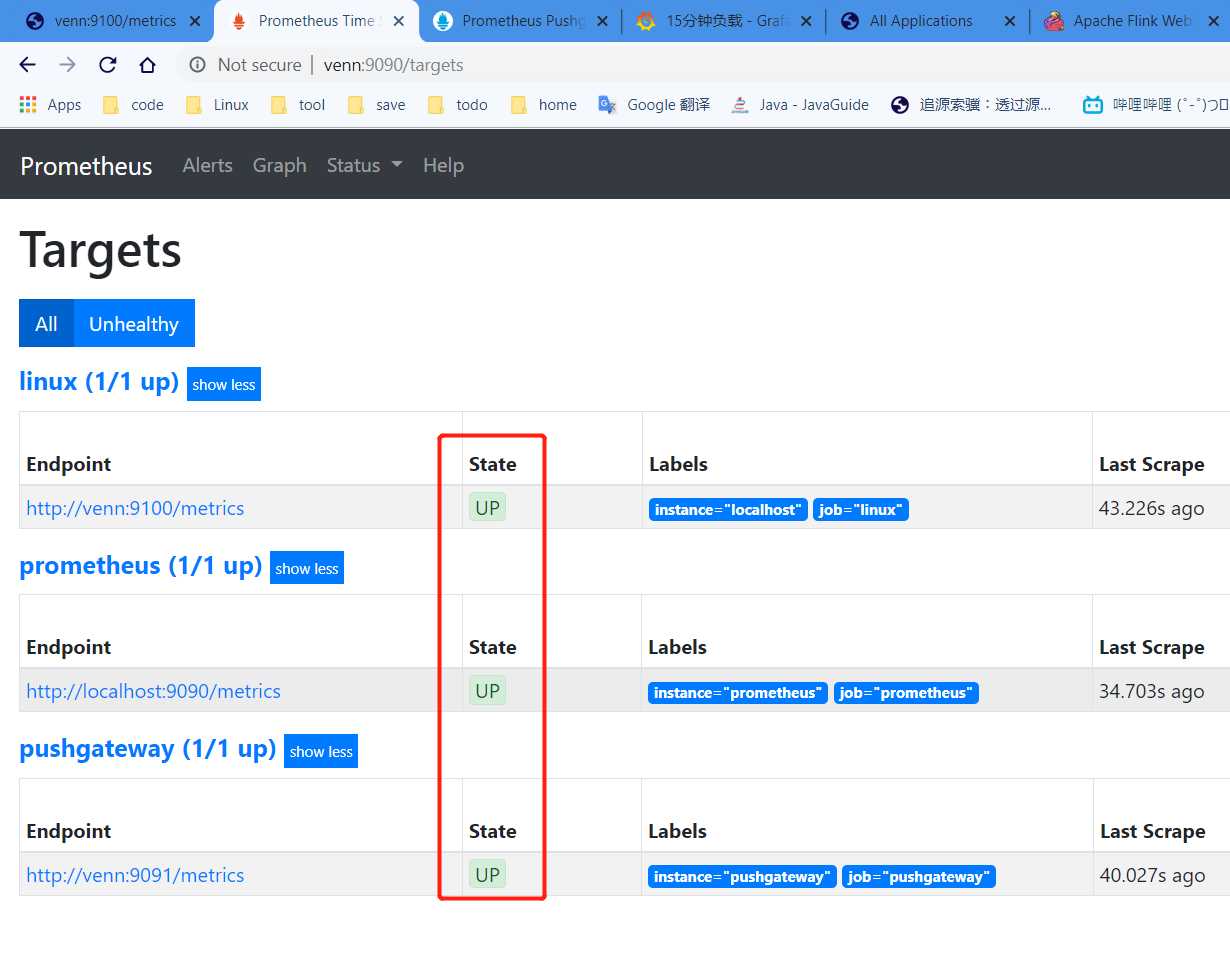
如果state 不是 UP 的,等一会就起来了
查看Grafana:

默认用户名密码 : amin/admin
此处不再赘述,配置数据源、创建系统负载监控参考博客:https://www.cnblogs.com/xiao987334176/p/9930517.html#autoid-0-0-0
5、配置Flink report :
在Flink 配置文件 flink-conf.yml 中添加如下内容:
##metrics metrics.reporter.promgateway.class: org.apache.flink.metrics.prometheus.PrometheusPushGatewayReporter metrics.reporter.promgateway.host: venn metrics.reporter.promgateway.port: 9091 metrics.reporter.promgateway.jobName: myJob metrics.reporter.promgateway.randomJobNameSuffix: true metrics.reporter.promgateway.deleteOnShutdown: false
启动一个任务(上一篇博客的案例迟到数据处理):
flink run -m yarn-cluster -ynm LateDataProcess -yn 1 -c com.venn.stream.api.sideoutput.lateDataProcess.LateDataProcess jar/flinkDemo-1.0.jar
查看任务webUI:
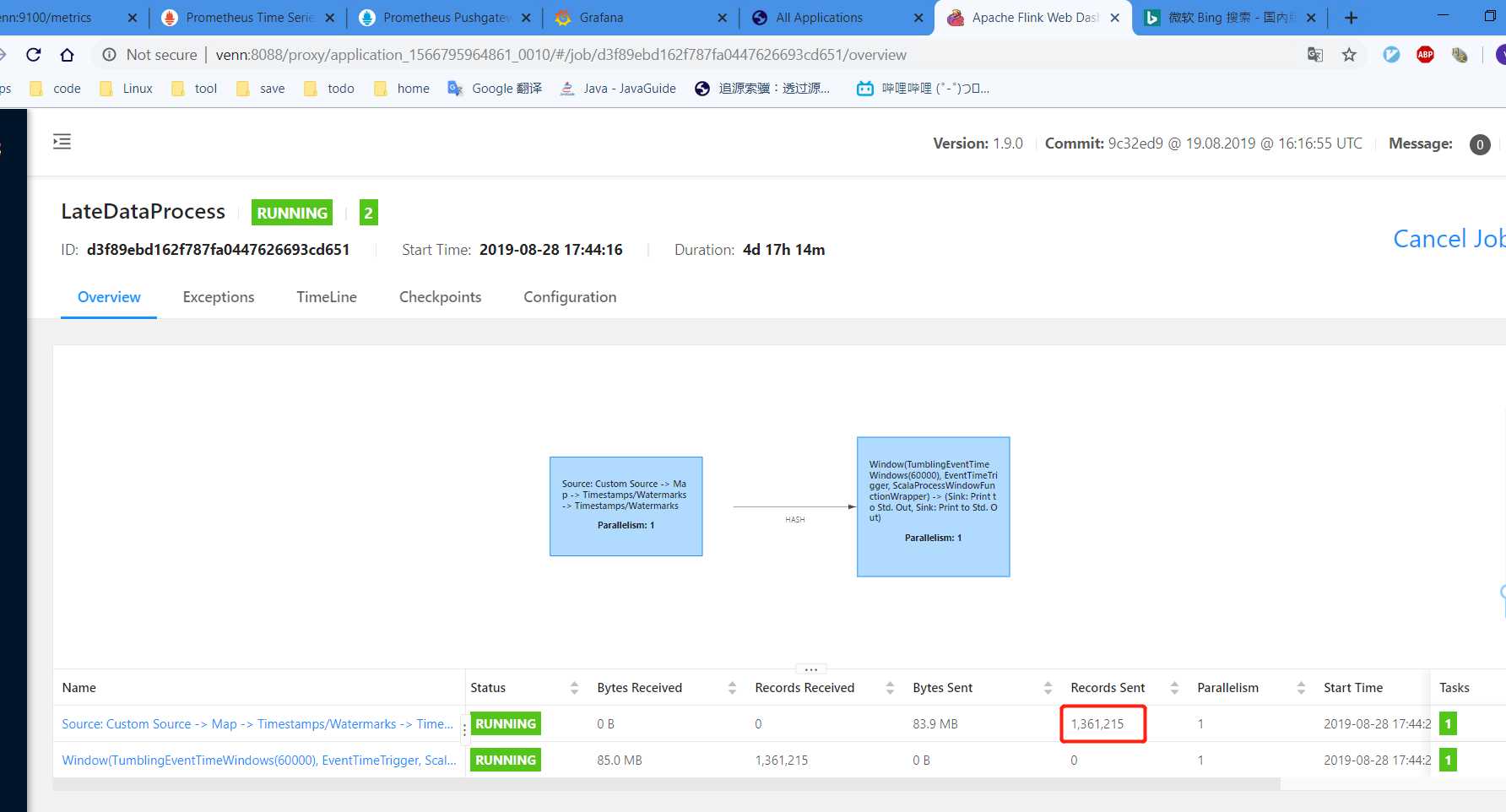
PS:任务已经跑了一段时间了
6、Grafana 中配置Flink监控
由于上面一句配置好Flink report、 pushgateway、prometheus,并且在Grafana中已经添加了prometheus 数据源,所以Grafana中会自动获取到 flink job的metrics 。
Grafana 首页,点击New dashboard,创建一个新的dashboard
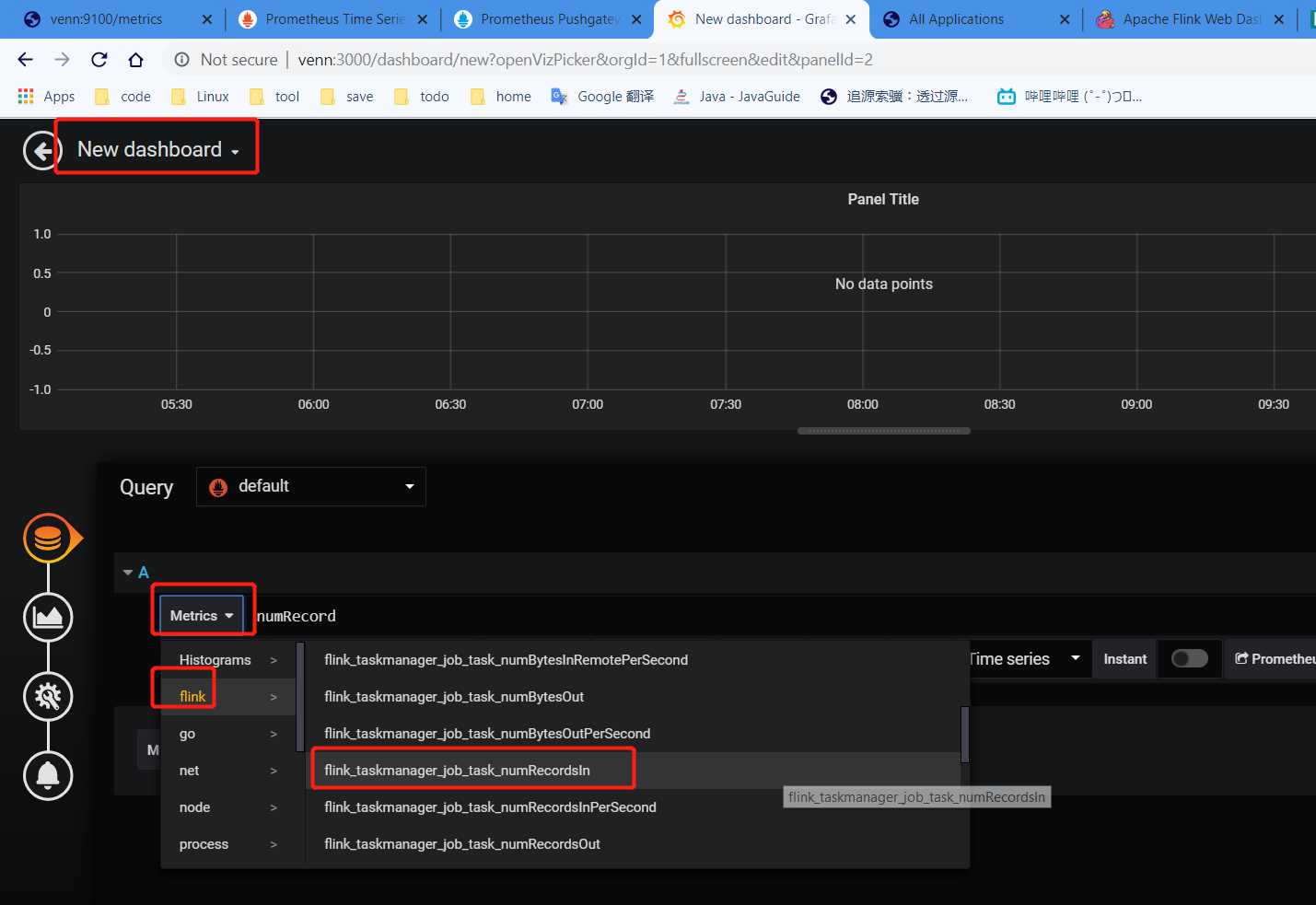
选中之后,即会出现对应的监控指标
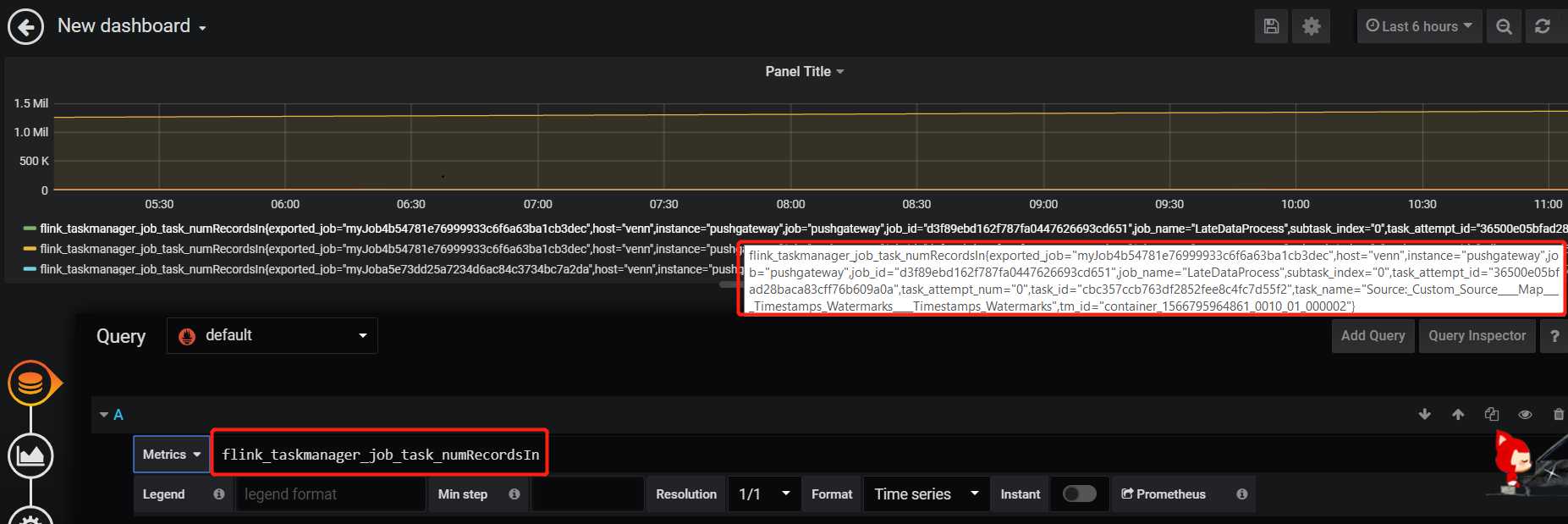
至此,Flink 的metrics 的指标展示在Grafana 中了
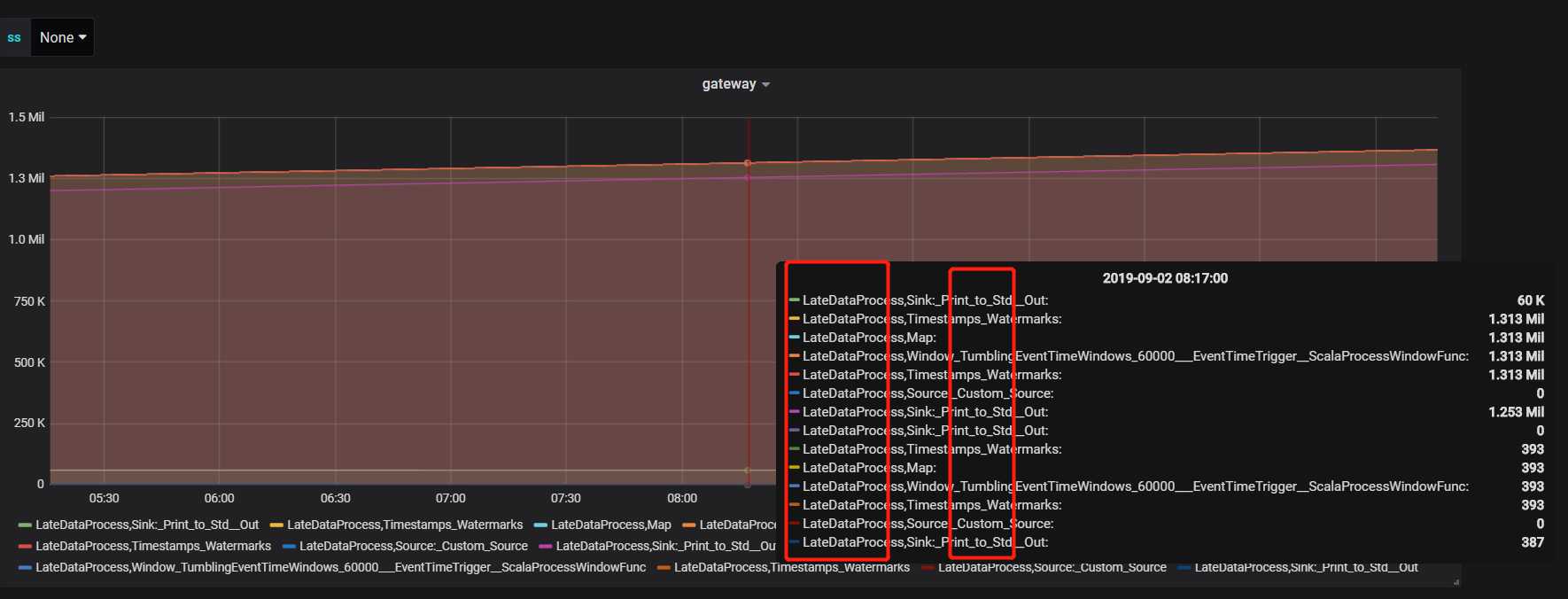
flink 指标对应的指标名比较长,可以在Legend 中配置显示内容,在{{key}} 将key换成对应需要展示的字段即可,如: {{job_name}},{{operator_name}}
对应显示如下:
以上是关于监控仪表系统Grafana 中文入门教程 | 构建你的第一个仪表盘的主要内容,如果未能解决你的问题,请参考以下文章