ElasticSearch分片与Lucene Index
Posted 心雨
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ElasticSearch分片与Lucene Index相关的知识,希望对你有一定的参考价值。
在ES中一个索引有一个或者多个分片构成,在创建索引的时候可以设置主分片和副本分片的数量,当主分片确定之后就不可以再修改了(因为路由需要基于这个数量来分发请求),而副本分片数量随时可以修改
PUT /myIndex
"settings" :
"number_of_shards" : 2, //该索引有2个分片
"number_of_replicas" : 1 //每个分片都有一个副本
这里我假设说是建立了两个节点,就是起了两个ES服务,shard1跟shard2就是创建的两个主分片,replica1和replica2就是两个副本分片,一般为了实现高可用,ES会将主分片和副本分片保存在不同的NODE节点中,这个动作由ES自动完成。
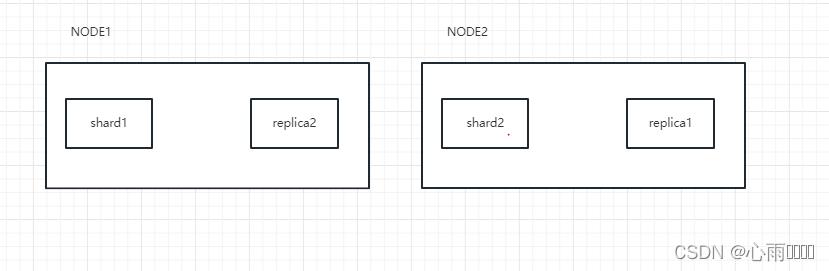
那么这一个个shard它又是什么呢?
shard = Lucene Index
我们知道ElasticSearch是一个分布式可扩展的实时搜索和分析引擎,是一个建立在全文搜索引擎Apache Lucene基础上的搜索引擎。那么Shard本质上就是一个个的Lucene Index。
在lucene里面由很多小的segment,每个segment内部都有许多中数据结构,比如说经常听说的Inverted Index(倒排索引),Sorted Fields,Document Values...,那么其中最重要的就是倒排索引了。
Inverted Index(倒排索引)
倒排索引主要包括两部分:

当我们进行搜索的时候,会将搜索的内容进行分词。然后在字典找到对应的term,从而就可以找到搜索相关的文件内容。
-
有序数据字典Dictionary(包括单词term和它出现的频率)
-
与单词对应的Postings(即存在这个单词的文件)
Sorted Fields(字段查找)
当想要查找包含某个特定的标题内容的文档时,就会用到这种结构。本质上它是一个简单的K-V集合,默认会存储整个文档的Json格式。
网图:

Document Values(为了排序、聚合)
它是为了解决排序、聚合而诞生的。这种结构本质上是一个列式的存储。
网图:

为了提高效率、ES可以将索引下的某一个Document Vlaue 全部读取到内存中进行操作,以此来提高访问速度,但是会消耗内存空间。
这几种数据结构、Inverted Index、Sorted Fields、Document Values 以及缓存,都在Segment内部。
当搜索时
Lucene会搜索所有的segment,然后将每个segment的搜索结果返回,然后返回给客户端。
缓存
当ES搜索文档的时候,会给文档建立相应的缓存、并且每秒都去刷新缓存。
segment合并
随着时间的增加,会有越来越多的segment,es会将这些segment合并,合并之后将原来的删掉,所以就会出现一种情况,你增加了更多的文档,索引占用的空间可能越来越小,因为引起了merge,从而有更多的压缩。
文档索引步骤顺序
新建单个文档所需要的顺序步骤:
网图:
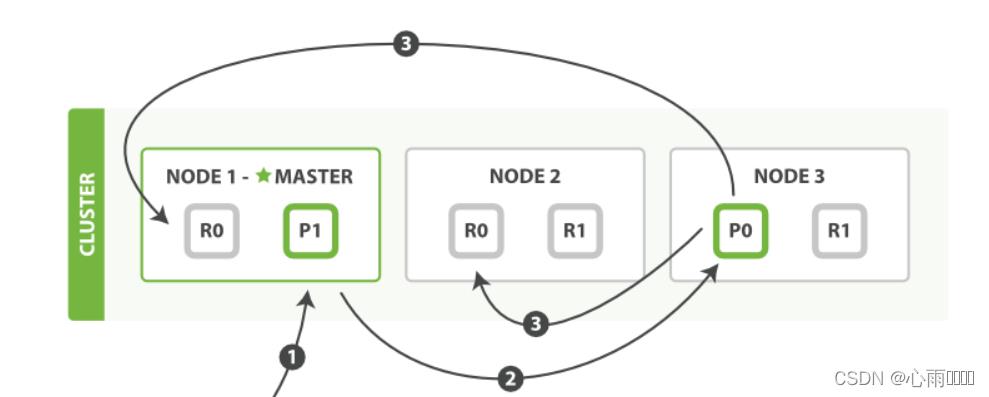
1,客户端向Node1发送新建索引或者删除请求。
2,节点使用文档的_id确定文档属于那个分片。请求会被转发到对应的Node。
3,在分片上面执行请求。如果执行成功了,那么请求会被转发到各个节点的副本分片上,如果都成功了,那么就会返回给客户端成功的信息。
整体流程,依然是妄(网)图。。。
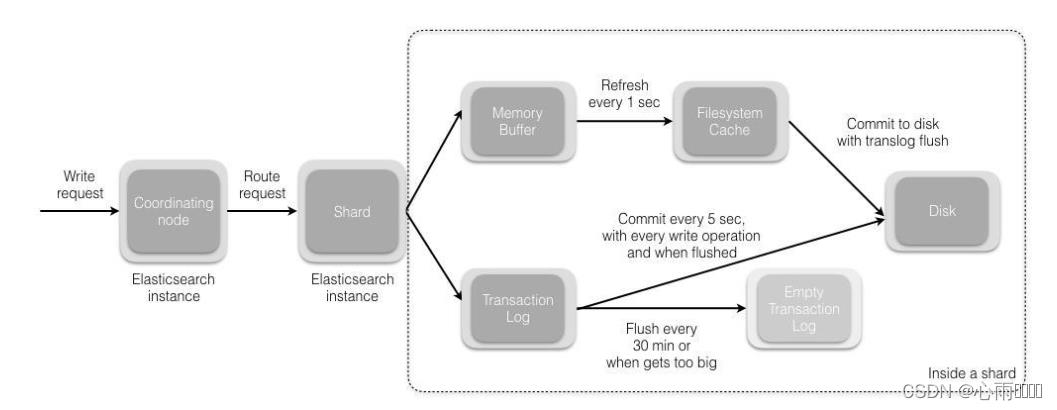
1,请求发送后会先来到协调节点,默认使用文档的id计算出来由哪一个分片来处理请求。
shard=hash(_id)%分片数量
2,分片接受到请求后,会先将请求写道memory buffer,然后定时(默认1s)写入到Filesystem。从memory buffer 到Filesystem cache的过程就叫refresh。
3,Transaction Log是用来保证数据可靠性的,因为refresh过程数据是有可能数据丢失的。在shard接受到请求后,同时会把请求写入translog中,当Filesystem cache中的数据写入到磁盘中后,才会被清除掉,这个过程教flush。
4,在flush过程中,内存中的缓存将会被清除,内容被写入一个新的段,段的fsync将会创建一个新的提交点,并将内容刷新到磁盘,旧的translog将被删除并开始一个新的trabslog。flush的触发机制默认30分钟,或者translog太大。
Elasticsearch的Refresh与Flush操作
初次接触到这两个概念,估计都会觉得他们没什么差别,都是为了在操作索引之后让索引可以被实时性的搜索,不过它们还是有点不同的。Elasticsearch底层依赖Lucene,这里我们介绍下Lucene的segment, Reopen,commit。
Segment
在ES中,基本的存储单元是shard(分片),但是在更底层的Lucene上稍微有点不同,ES的每一个shard是Lucene的一个index(索引),Lucene的索引由多个segment组成,每个segment就是ES文档的倒序索引,里面包含了一些term(词)的mapping(映射)。
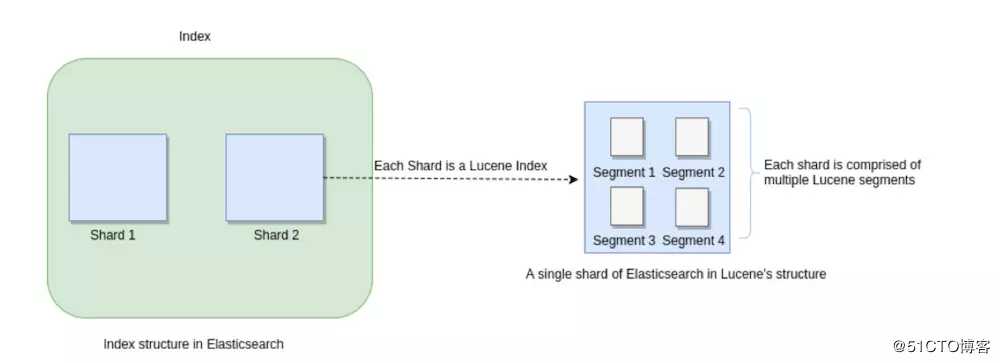
当每个ES的文档创建的时候,都会写入一个新的segment中,因此每次写入的都是新的segment,所以不需要修改之前的segment。在删除文档的时候,只是在它属于的segment哪里标记为已删除就可,没有真正的从磁盘中抹除。更新也是同样的,只是在对应之前segment哪里标记为逻辑删除,然后新建一个新的segment。
Lucene Reopen
Reopen是为了让数据可以可以被搜索到,尽管这个时候数据可以被搜索到,但是不一定保证数据已经被持久化到磁盘中。
Lucene Commit
Commit就是为了让数据持久化,每一次的Commit,不同segment的数据都会被持久化到磁盘中,虽然这样可以让数据更安全,但是每一次操作都会消耗系统资源,会有大量的IO操作。
Translog
ES在持久化的时候引入了一种新的方式,translog(transaction log),一个文档被索引之后,就会被添加到内存缓冲区,并且 追加到了translog.
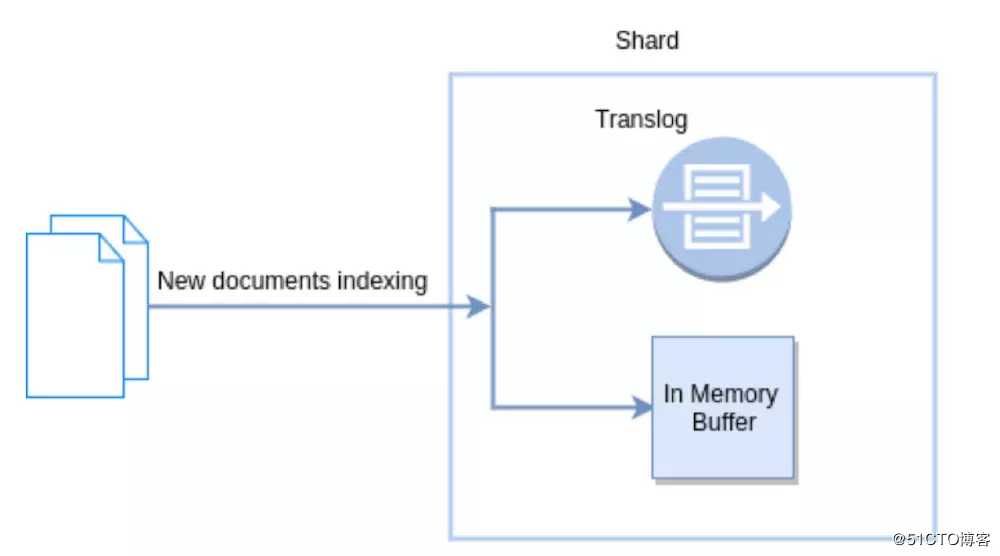
ES的Refresh
默认情况下,ES会每秒refresh一次,每次操作都会把内存缓冲区的内容拷贝到新创建的segment中去,这一步是在内存中操作的,这个时候新的文档就会被搜索了。也就是说ES是近实时性的搜索,差不多1s钟,才能让数据可以被搜索到。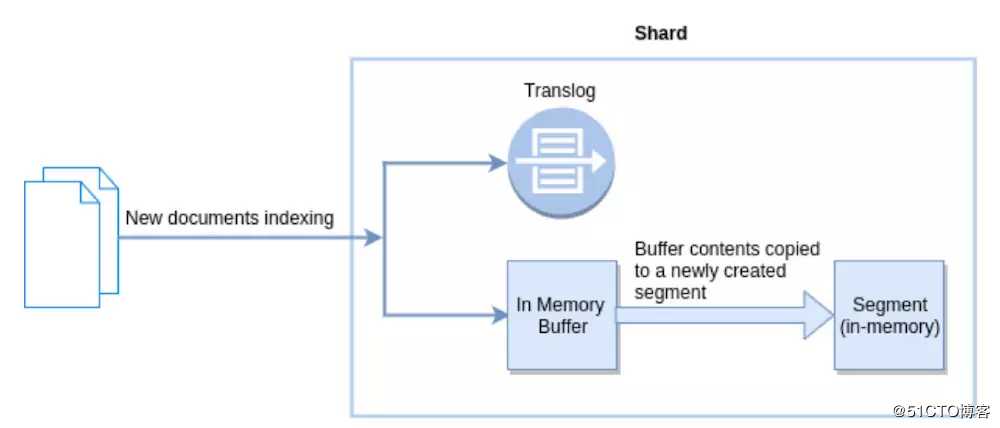
ES的Flush
Flush操作意味着,所有在内存缓冲区的文档被写到新的Lucene Segment中,也就是所有在内存中的segment被提交到了磁盘,同时清除translog。
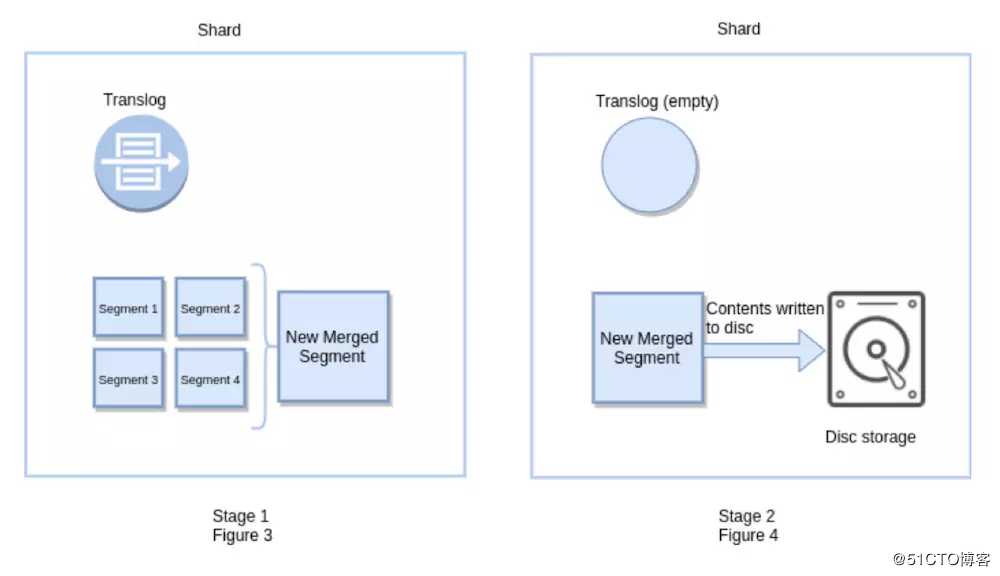
一般Flush的时间间隔会比较久,默认30分钟,或者当translog达到了一定的大小,也会触发flush操作。
最后
简单来说,ES的refresh操作是为了让最新的数据可以立即被搜索到。而flush操作则是为了让数据持久化到磁盘中,另外ES的搜索是在内存中处理的,因此Flush操作不影响数据能否被搜索到。
translog一般在进行flush的时候被清空,一般在fsync和commit的时候被持久化到磁盘,默认的translog是在6.x版本以后,每次请求都会fsync到磁盘。不过有些index.translog的配置可以设置
以上是关于ElasticSearch分片与Lucene Index的主要内容,如果未能解决你的问题,请参考以下文章