数据湖:分布式开源处理引擎Spark
Posted YoungerChina
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据湖:分布式开源处理引擎Spark相关的知识,希望对你有一定的参考价值。
系列专题:数据湖系列文章
1. 什么是Spark
Apache Spark是一种高效且多用途的集群计算平台。换句话说,Spark 是一种开源的,大规模数据处理引擎。它提供了一整套开发 API,包括流计算、机器学习或者SQL。Spark 支持批处理和流处理。批处理指的是对大规模数据一批一批的计算,计算时间较长,而流处理则是一条数据一条数据的处理,处理速度可达到秒级。
Spark 集成了许多大数据工具,例如 Spark 可以处理任何 Hadoop 数据源,也能在 Hadoop 集群上执行。大数据业内有个共识认为,Spark 只是Hadoop MapReduce 的扩展(事实并非如此),如Hadoop MapReduce 中没有的迭代查询和流处理。然而Spark并不需要依赖于 Hadoop,它有自己的集群管理系统。更重要的是,同样数据量,同样集群配置,Spark 的数据处理速度要比 Hadoop MapReduce 快10倍左右(?)。
Spark 的一个关键的特性是数据可以在内存中迭代计算,提高数据处理的速度。虽然Spark是用 Scala开发的,但是它对 Java、Scala、Python 和 R 等高级编程语言提供了开发接口。
Spark的应用非常广泛,各行业的众多组织都使用它,其中包括 FINRA、Yelp、Zillow、DataXu、Urban Institute 和 CrowdStrike。Apache Spark 已经成为最受欢迎的大数据分布式处理框架之一,在 2017 年拥有 365000 名会定期参加聚会的会员。
2. Spark的发展
2009年,Spark 诞生于伯克利大学的AMPLab实验室。最初 Spark 只是一个实验性的项目,代码量非常少,属于轻量级的框架。
2010年,伯克利大学正式开源了 Spark 项目。
2013年,Spark 成为了 Apache 基金会下的项目,进入高速发展期。第三方开发者贡献了大量的代码,活跃度非常高。
2014年,Spark 以飞快的速度称为了 Apache 的顶级项目。
2015年至今,Spark 在国内IT行业变得愈发火爆,大量的公司开始重点部署或者使用 Spark 来替代MapReduce、Hive、Storm 等传统的大数据计算框架。
如今,Spark 已成为 Hadoop 生态系统中最活跃的项目之一,大量组织都采用 Spark 和 Hadoop 来处理大数据。2017 年,Spark 拥有 365000 名会定期参加聚会的会员,这个数字在两年时间里成长 5 倍之多。从 2009 年开始,共有来自 200 多个组织的超过 1000 名开发人员为它做出过贡献。
3. Spark 如何运作?
Hadoop MapReduce 是一种用于处理大数据集的编程模型,它采用并行的分布式算法。开发人员可以编写高度并行化的运算符,而不用担心工作分配和容错能力。不过,MapReduce 所面对的一项挑战是它要通过连续多步骤流程来运行某项作业。在每个步骤中,MapReduce 要读取来自集群的数据,执行操作,并将结果写到 HDFS。因为每个步骤都需要磁盘读取和写入,磁盘 I/O 的延迟会导致 MapReduce 作业变慢。
开发 Spark 的初衷就是为了突破 MapReduce 的这些限制,它可以执行内存中处理,减少作业中的步骤数量,并且跨多项并行操作对数据进行重用。借助于 Spark,将数据读取到内存、执行操作和写回结果仅需要一个步骤,大大地加快了执行的速度。Spark 还能使用内存中缓存显著加快在相同数据集上重复调用某函数的机器学习算法的速度,进而重新使用数据。数据重用通过在弹性分布式数据集 (RDD) 上创建数据抽象—DataFrames 得以实现,而弹性分布式数据集是一个缓存在内存中并在多项 Spark 操作中重新使用的对象集合。它大幅缩短了延迟,使 Spark 比 MapReduce 快数倍,在进行机器学习和交互式分析时尤其明显。
4. 为什么使用Spark
Spark 诞生之前,在大数据处理领域,并没有一个通用的计算引擎。
- 离线批处理使用 Hadoop MapReduce
- 流处理需要使用 Apache Storm
- 即时查询使用 Impala 或者 Tez
- 执行图计算使用 Neo4j 或者 Apache Giraph
而Spark囊括了离线批处理、流处理、即时查询和图计算4大功能。
5. Spark组件
Spark 框架包括:
- Spark Core 是该平台的基础
- 用于交互式查询的 Spark SQL
- 用于实时分析的 Spark Streaming
- 用于机器学习的 Spark MLlib
- 用于图形处理的 Spark GraphX
这些组件解决了使用Hadoop时碰到的特定问题。
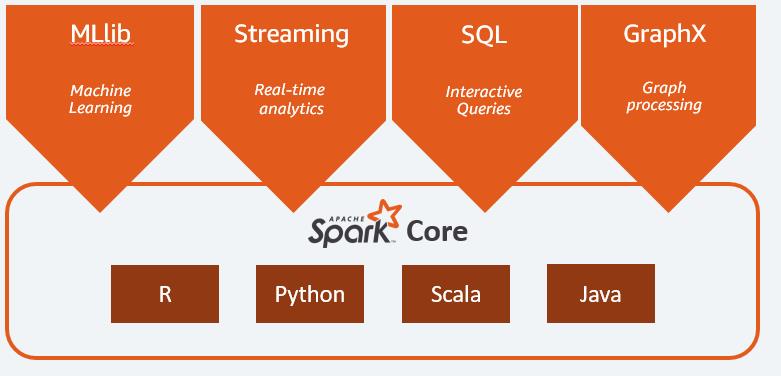
5.1 Spark Core
Spark Core是该平台的基础。它要负责内存管理、故障恢复、计划安排、分配与监控作业,以及和存储系统进行交互。您可以通过为 Java、Scala、Python 和 R 而构建的应用程序编程接口 (API) 使用 Spark Core。这些 API 会将复杂的分布式处理隐藏在简单的高级操作符的背后。
提供了内存计算的能力
5.2 Spark SQL交互式查询
Spark SQL 是提供低延迟交互式查询的分布式查询引擎,是Spark来操作结构化数据的程序包,可以使用SQL语句的方式来查询数据。其速度最高可比 MapReduce 快 100 倍。它包含一个基于成本的优化器、列式存储,能够生成代码并用于快速查询,它还可以扩展到具有数千个节点。业务分析师可以使用标准的 SQL 或 Hive 查询语言来查询数据。
开发人员可以使用以 Scala、Java、Python 和 R 提供的 API。它支持各种开箱即用的数据源,包括 JDBC、ODBC、JSON、HDFS、Hive,ORC 和 Parquet。其他热门存储—Amazon Redshift、Amazon S3、Couchbase、Cassandra、MongoDB、Salesforce.com、Elasticsearch,以及其他许多存储,都可以在 Spark 程序包生态系统中找到。
5.3 Spark Streaming实时计算
Spark Streaming 是利用 Spark Core 的快速计划功能执行流式分析的实时解决方案。它会提取迷你批处理中的数据,使用为批处理分析编写的相同应用程序代码实现对此类数据的分析。这样一来,开发人员的效率得到改善,因为他们可以将相同代码用于批处理和实时流式处理应用程序。
Spark Streaming 支持来自 Twitter、Kafka、Flume、HDFS 和 ZeroMQ 的数据,以及 Spark 程序包生态系统中的其他众多数据。
5.4 Spark MLlib机器学习
Spark 包含 MLlib,它是在大规模数据上进行机器学习所需的算法库。数据科学家可以在任何 Hadoop 数据源上使用 R 或 Python 对机器学习模型进行训练,这些数据源使用 MLlib 保存,并且被导入到基于 Java 或 Scala 的管道当中。
Spark 专为在内存中运行的快速交互式计算而设计,使机器学习可以快速运行。它的算法包含分类、回归、集群、协同过滤和模式挖掘等功能。
5.5 Spark GraphX图计算引擎
Spark GraphX 是构建在 Spark 之上的分布式图形处理框架。GraphX 提供 ETL、探索性分析和迭代图形计算,让用户能够以交互方式大规模构建、转换图形数据结构。它自带高度灵活的 API 和一系列分布式图形算法选项。
SparkR 是一个 R 语言包,它提供了轻量级的方式使得可以在 R 语言中使用 Apache Spark。在Spark 1.4中,SparkR 实现了分布式的 data frame,支持类似查询、过滤以及聚合的操作(类似于R中的data frames:dplyr),但是这个可以操作大规模的数据集。
6. Spark vs. Hadoop
除了 Spark 和 Hadoop MapReduce 的设计差异,很多组织还发现这两个大数据框架之间存在互补性,并且会同时使用二者来克服更广泛的业务挑战。
Hadoop 是一种开源框架,它将 Hadoop 分布式文件系统 (HDFS) 用于存储,将 YARN 作为管理由不同应用程序所使用的计算资源的方式,并且实现 MapReduce 编程模型来充当执行引擎。在一般 Hadoop 实现中,还会部署不同的执行引擎,如 Spark、Tez 和 Presto。
Spark 是一种专门用于交互式查询、机器学习和实时工作负载的开源框架。它没有自己的存储系统,但会在其他存储系统,如 HDFS,或其他热门存储,如 Amazon Redshift、Amazon S3、Couchbase、Cassandra 等之上运行分析。Hadoop 上的 Spark 会利用 YARN 来分享常见的集群和数据集作为其他 Hadoop 引擎,确保服务和响应的一致性水平。
7. 谁在使用Spark

Yelp 的广告定位团队设计了一些预测模型来确定用户与广告互动的几率。通过使用 Amazon EMR 上的 Apache Spark 处理大量数据来训练机器学习模型,Yelp 提高了收入和广告点击率。

Zillow 拥有并经营着最大的在线房地产网站之一。它在 Amazon EMR 上使用来自 Spark 的机器学习算法,以接近实时的方式处理大型数据集并用于计算 Zestimates。Zestimates 是一款房屋估值工具,为买方和卖方提供具体房屋的估计市价。

CrowdStrike 提供终端节点防护以防止出现违例。它们结合使用 Amazon EMR 和 Spark 来处理数百 TB 的事件数据,并将其汇总到主机上更高级别的行为描述中。通过这些数据,CrowdStrike 可以将事件数据汇集在一起并确定是否存在恶意活动。

Hearst Corporation 是一家大型多元化媒体信息公司,客户可查看 200 多个网站上的内容。利用 Amazon EMR 上的 Apache Spark 流传输,Hearst 的编辑人员可以实时了解哪些文章反响良好以及哪些主题是热门话题。

Bigfinite 使用在 AWS 上运行的高级分析技术存储与分析大量制药数据。 Amazon EMR 上的 Spark 被用于运行他们采用 Python 和 Scala 开发的专利算法。

图像内和屏幕内广告平台 GumGum 使用 Amazon EMR 上的 Spark 预测库存、处理点击流日志以及临时分析 Amazon S3 中的非结构化数据。Spark 的增强性能为 GumGum 节省了处理这些工作流程的时间和资金。

Intent Media 运用 Spark 和 MLlib 来大规模训练和部署机器学习模型。Spark 所具有的精密数据科学功能被用来帮助在线旅游公司优化其网站和应用程序的收入。

FINRA 是金融服务行业的领导者,他们希望通过从本地的 SQL 批处理迁移到位于云中的 Apache Spark,从而实时在数十亿个以时间排序的市场事件中挖掘数据见解。凭借 Amazon EMR 上的 Apache Spark,FINRA 现在可以测试市场下行时的真实数据,增强他们提供投资者保护和提升市场完整性的能力
8. 参考资料
[01]https://aws.amazon.com/cn/big-data/what-is-spark/
[02]https://www.hadoopdoc.com/spark/spark-intro
以上是关于数据湖:分布式开源处理引擎Spark的主要内容,如果未能解决你的问题,请参考以下文章
Spark重磅 | Apache Spark社区的Delta Lake开源
Spark+Flink+Iceberg打造湖仓一体架构实践探索