移动端人脸风格化技术的应用
Posted 阿里巴巴淘系技术团队官网博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了移动端人脸风格化技术的应用相关的知识,希望对你有一定的参考价值。

本文介绍了人脸风格化技术的整个流程,以及该技术在直播、短视频等场景下的应用。该技术可作为氛围营造、提高观感的有效手段,也可在买家秀等图文场景下起到人脸隐私保护、增添乐趣等作用。
前言
随着元宇宙、数字人、虚拟形象等概念的爆发,各种数字化协同互动的泛娱乐应用也在不断的落地。例如,在一些游戏中,玩家成为虚拟艺人参与到高还原度的现实艺人日常工作中,并会在特定情况下,与虚拟艺人在人脸表情等层面上形成强映射提升参与感。而由阿里巴巴天猫推出的超写实数字人AYAYI和井柏然联合“带逛”的杂志《MO Magazine》,则打破传统的平面阅读体验,以虚实结合的形式让读者获得沉浸式体验。

而在这些泛娱乐应用场景中,“人”必然是首要考虑的一步。而人工设计的数字、动画形象,存在过于“抽象”、代价高昂、缺乏个性化等问题。因此在人脸数字化上,我们通过研发具有良好控制感、ID感、风格化程度的人脸风格化技术,实现风格定制化的人脸形象切换。该项技术不仅可以在直播、短视频等娱乐消费场景下作为氛围营造、提高观感的有效手段,也可在买家秀等图文场景下起到人脸隐私保护、增添乐趣等作用。更进一步的想象,若不同的用户聚集在某个数字社区内,用该社区风格的数字形象聊天社交(例如“双城之战吧”的用户在元宇宙内用双城之战风格化形象友好交流),那是多具有代入感的事情。

双城之战动画

左图为原始AYAYI的形象,右图为风格化后的形象。
而为了将人脸风格化这项技术落地到我们的直播、买家秀、卖家秀等不同的泛娱乐业务场景,我们做到了:
低成本生产不同人脸风格化编辑的模型(本文所展示的所有效果均在没有任何设计资源的投入下实现的);
适当进行风格编辑以配合设计、产品、运营进行风格选型;
能够在人脸ID感和风格化程度之间做倾斜与平衡;
保证模型的泛化性,以适用于不同的人脸、角度、场景环境;
在保证清晰度等效果的前提下,降低模型对算力的要求。
接下来,我们先看一下demo,然后再介绍我们整个技术流程:感谢我们的产品mm——多菲~
整体方案
我们的整体算法方案采用三个阶段:
阶段一:基于StyleGAN的风格化数据生成;
阶段二:非监督图像翻译生成配对图像;
阶段三:使用配对图像进行移动端有监督图像翻译模型的训练。
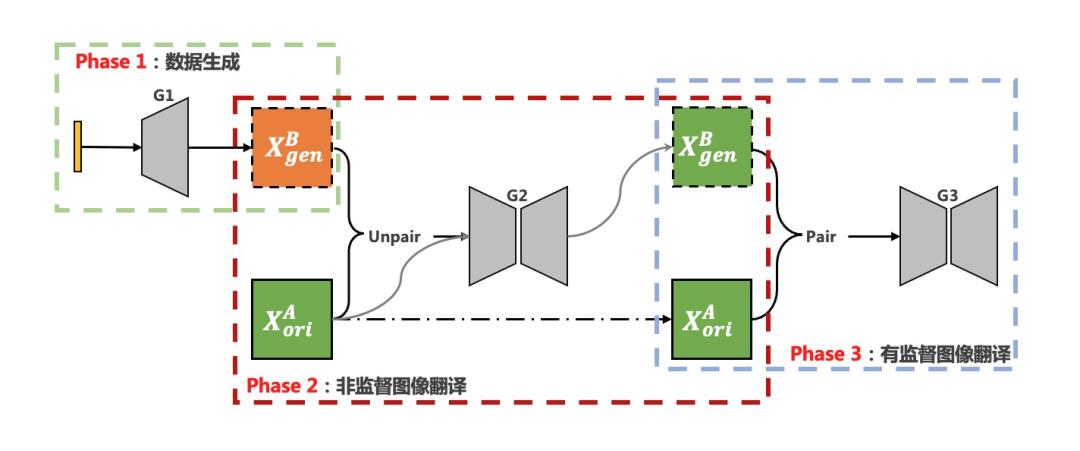
人脸风格化编辑整体算法方案
当然,也可以用二阶段方案:StyleGAN制作pair图像对,然后直接训练有监督小模型。但增加非监督图像翻译阶段,可以将风格化数据生产和配对图像数据制作两个任务解耦开来,通过对阶段内算法、阶段间数据的优化改进,结合移动端有监督小模型训练,最终解决低成本的风格化模型生产、风格的编辑及选型、ID感及风格化的倾斜、部署模型的轻量化等问题。
基于StyleGAN的数据生成
使用StyleGAN算法进行数据生成的工作上,主要针对3个问题的解决:
提升模型的生成数据丰富度和风格化程度:例如生成CG脸更像CG,且各个角度、表情、发型等形象更丰富;
提升数据生成效率:生成的数据良率高、分布更加可控;
风格编辑及选型:例如修改CG脸的眼睛大小。
下面我们针对这三方面展开。
▐ 丰富度和风格化
基于StyleGAN2-ADA的迁移学习遇到的第一个重要问题就是:模型的丰富度和模型的风格化程度之间的trade-off。使用训练集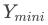 进行迁移学习时,受训练集数据的丰富度影响,迁移后的模型在人脸表情、人脸角度、人脸元素等方面的丰富度也会受损;同时,随着迁移训练的迭代代数增加、模型风格化程度/FID的提升,模型丰富度也会越低。这会使得后续应用模型生成的风格化数据集分布过于单调,不利于U-GAT-IT的训练。
进行迁移学习时,受训练集数据的丰富度影响,迁移后的模型在人脸表情、人脸角度、人脸元素等方面的丰富度也会受损;同时,随着迁移训练的迭代代数增加、模型风格化程度/FID的提升,模型丰富度也会越低。这会使得后续应用模型生成的风格化数据集分布过于单调,不利于U-GAT-IT的训练。
为了提升模型的丰富度,我们进行了如下改进:
调整、优化训练数据集的数据分布;
模型融合:因为源模型在大量数据上进行训练,所以源模型的生成空间具有非常高的丰富度;如果将迁移模型低分辨率层的权重替换为源模型对应层权重得到融合模型,则可使得新模型的生成图像在大的元素/特征上的分布与源模型一致,从而在低分辨率特征上获得与源模型一致的丰富度;

融合方式:Swap layer直接交换不同层的参数,容易造成生成图像的不协调、细节bad cases;而通过平滑的模型插值,可以获得更好的生成效果(下面的图示皆由插值融合方式的融合模型生成的)
对不同层的学习率以及特征进行约束、优化调整;
迭代优化:人工筛选新生产的数据,添加到原风格化数据集中以提升丰富度,然后在迭代训练优化直到得到一个能生成较高丰富度、满意风格化程度的模型。

原图,迁移模型,融合模型
▐ 数据生成效率
如果我们拥有一个丰富度高的StyleGAN2模型,那如何生成一个具有丰富分布的风格数据集呢?有两个做法:
随机采样隐变量,生成随机风格数据集;
使用StyleGAN inversion,输入符合一定分布的人脸数据,制作对应的风格数据集。
做法1可以提供更丰富的风格化数据(特别是背景的丰富度),而做法2可以提高生成数据的有效性和提供一定程度的分布控制,提升风格化数据生产效率。

原始图像,StyleGAN Inversion得到的隐向量送入“高级脸风格/动画风格” StyleGAN2生成器得到的图像
▐ 风格编辑及选型
原始风格不太好看是就没法用了
迁移训练后的模型风格就没法改了
No No No,每一个模型不止可以用来生成数据,也可沉淀为一个基础组件、基础能力。不止是想在原始风格上做微调、优化,甚至是想创造新的风格,都是可以的:
模型融合:通过融合多个模型、设置不同的融合参数/层数、使用不同的融合方式等,可以实现对劣势风格模型做优化,也可实现风格的调整;
模型套娃:将不同风格的模型串联,使得最终输出的风格携带了中间模型的一些五官、色调等风格特征。

融合过程中实现对漫画风格的微调(瞳孔颜色、嘴唇、肤色色调等)
通过风格创造及微调,可以实现不同风格的模型,从而实现不同风格人脸数据的生产。

通过基于StyleGAN的迁移学习、风格编辑优化、数据生成,我们便可以获得我们的第一桶金💰:具有较高丰富度的、1024×1024分辨率的、风格选型后的风格化数据集。
基于非监督图像翻译的配对数据制作
非监督图像翻译技术通过学习两个域之间的映射关系,可以将一个域的图像转换到另一个域上,从而提供制作图像对的可能。例如该领域出名的CycleGAN具有如下的结构:
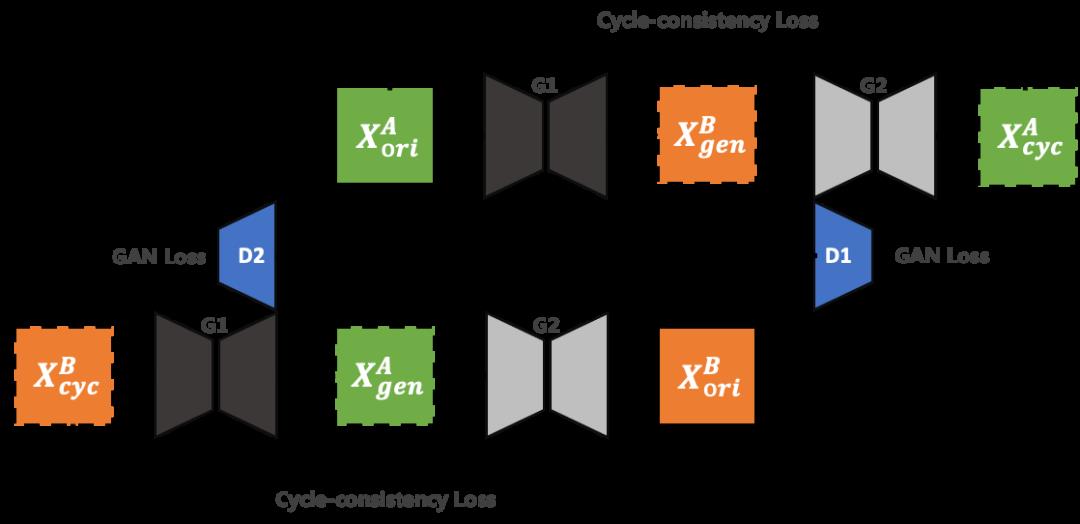
CycleGAN主要框架
我在上文讨论“模型丰富度”的时候说过:
这(低丰富度)会使得后续应用模型生成的风格化数据集分布过于单调,不利于U-GAT-IT的训练。
这是为什么么?因为CycleGAN的框架要求两个域的数据要基本符合双射关系,否则域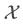 翻译到域
翻译到域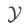 后,就很容易发生语义丢失。而StyleGAN2 inversion生成的图像存在一个问题,就是大部分的背景信息会丢失,变成简单的、模糊的背景(当然,有一些最新的论文极大缓解了这个问题,例如腾讯AI Lab的High-Fidelity GAN Inversion)。如果使用数据集
后,就很容易发生语义丢失。而StyleGAN2 inversion生成的图像存在一个问题,就是大部分的背景信息会丢失,变成简单的、模糊的背景(当然,有一些最新的论文极大缓解了这个问题,例如腾讯AI Lab的High-Fidelity GAN Inversion)。如果使用数据集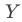 和真实人脸数据集
和真实人脸数据集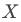 直接训练U-GAT-IT,就很容易发生数据集
直接训练U-GAT-IT,就很容易发生数据集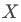 生成的对应图像
生成的对应图像 的背景丢失大量语义信息,导致很难形成有效的图像对。
的背景丢失大量语义信息,导致很难形成有效的图像对。
于是针对此提出了改进U-GAT-IT以实现固定背景的两种方式:基于增加背景约束的Region-based U-GAT-IT算法改进,基于增加掩膜分支的Mask U-GAT-IT算法改进。这两种方式存在ID感和风格化程度强弱和均衡的差异,结合超参的调整,为我们的ID感和风格化提供了一个控制余地。同时,我们也进行网络结构改进、模型EMA、边缘提升等手段进一步提升生成效果。

左为原图,中间和右边是非监督图像翻译的生成效果,差异在于对算法进行了ID感和风格化程度的控制
最终,使用训练好的生成模型对真人图像数据集进行推理翻译得到对应的配对风格化数据集。
有监督图像翻译
基于MNN不同算子及模块在移动端上的计算效率的研究,进行 移动端模型结构设计 及 模型计算量分档,并结合对CartoonGAN、AnimeGAN、pix2pix等研究的改进,最终得到了 轻量、高清晰度、高风格化程度的移动端模型:
模型 | 清晰度↑ | FID↓ |
Pixel-wise Loss | 3.44 | 32.53 |
+Perceptual loss + GAN Loss | 6.03 | 8.36 |
+Edge-promoting | 6.24 | 8.09 |
+Data Augmentation | 6.57 | 8.26 |
*清晰度使用 拉普拉斯梯度值求和 作为统计指标
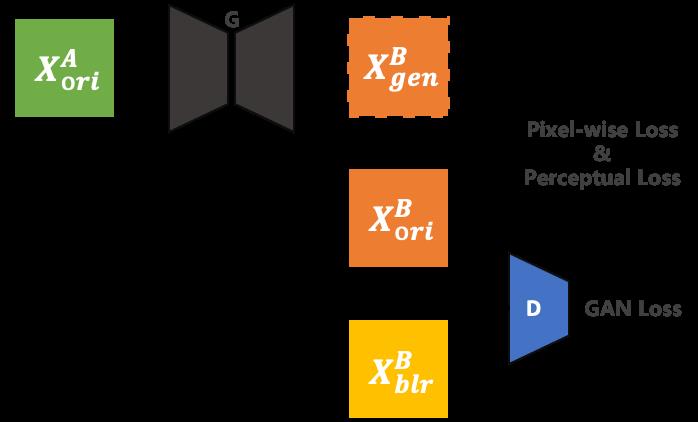
有监督图像翻译模型整体训练框架
在移动端上实现实时的变脸效果:
展望
优化数据集:不同角度图像数据、质量优化;
整体链路的优化、改进、重设计;
更好的数据生成:StyleGAN3、Inversion算法、模型融合、风格编辑/创造、few-shot;
非监督两域翻译:利用较高匹配度的生成数据对做半监督,生成模型结构优化(例如引入傅里叶卷积);
有监督两域翻译:vid2vid 、帧间稳定性提升、极限场景的优化、细节的稳定性;
全图风格化/数字创作:disco diffusion、dalle2,style transfer。
参考文献
Karras, Tero, Miika Aittala, Janne Hellsten, Samuli Laine, Jaakko Lehtinen, and Timo Aila. "Training generative adversarial networks with limited data." arXiv preprint arXiv:2006.06676 (2020).
Kim, Junho, Minjae Kim, Hyeonwoo Kang, and Kwanghee Lee. "U-gat-it: Unsupervised generative attentional networks with adaptive layer-instance normalization for image-to-image translation." arXiv preprint arXiv:1907.10830 (2019).
Pinkney, Justin NM, and Doron Adler. "Resolution Dependent GAN Interpolation for Controllable Image Synthesis Between Domains." arXiv preprint arXiv:2010.05334 (2020).
Tov, Omer, Yuval Alaluf, Yotam Nitzan, Or Patashnik, and Daniel Cohen-Or. "Designing an encoder for stylegan image manipulation." ACM Transactions on Graphics (TOG) 40, no. 4 (2021): 1-14.
Song, Guoxian, Linjie Luo, Jing Liu, Wan-Chun Ma, Chunpong Lai, Chuanxia Zheng, and Tat-Jen Cham. "AgileGAN: stylizing portraits by inversion-consistent transfer learning." ACM Transactions on Graphics (TOG) 40, no. 4 (2021): 1-13.
zllrunning. face-parsing.PyTorch. https://github.com/zllrunning/face-parsing.PyTorch, 2019. 5
Roy, Abhijit Guha, Nassir Navab, and Christian Wachinger. "Recalibrating fully convolutional networks with spatial and channel “squeeze and excitation” blocks." IEEE transactions on medical imaging 38, no. 2 (2018): 540-549.
Chen, Yang, Yu-Kun Lai, and Yong-Jin Liu. "Cartoongan: Generative adversarial networks for photo cartoonization." In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 9465-9474. 2018.
Zhang, Lingzhi, Tarmily Wen, and Jianbo Shi. "Deep image blending." In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pp. 231-240. 2020.
Wang, Xintao, Ke Yu, Shixiang Wu, Jinjin Gu, Yihao Liu, Chao Dong, Yu Qiao, and Chen Change Loy. "Esrgan: Enhanced super-resolution generative adversarial networks." In Proceedings of the European conference on computer vision (ECCV) workshops, pp. 0-0. 2018.
Wang, Xintao, Liangbin Xie, Chao Dong, and Ying Shan. "Real-esrgan: Training real-world blind super-resolution with pure synthetic data." In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 1905-1914. 2021.
Siddique, Nahian, Sidike Paheding, Colin P. Elkin, and Vijay Devabhaktuni. "U-net and its variants for medical image segmentation: A review of theory and applications." IEEE Access (2021).
Wang, Tengfei, et al. "High-fidelity gan inversion for image attribute editing." arXiv preprint arXiv:2109.06590 (2021).
团队介绍
我们是大淘宝技术多媒体生产&视频内容理解算法团队,依托于淘宝天猫数十亿级的视频/图像数据,致力于提供从看点商品多媒体生产到前台视频理解推荐的全链路视觉算法方案。在端云一体的图像/视频处理、跨模态视频内容理解、AR直播、3D数字场、内容智能生产、审核、检索和高层语义理解等技术领域上,持续探索及发力以驱动产品和商品创新;在支持淘宝直播、逛逛、点淘等天猫淘宝内容业务的同时,也通过自研的内容中台为阿里集团内的钉钉、闲鱼、优酷等内容业务提供视觉算法能力支持。我们不断吸引及欢迎机器学习、视觉算法、NLP算法、端侧智能等领域⼈才的加⼊,欢迎联系 judyzha.zjl@alibaba-inc.com。
✿ 拓展阅读

作者|郑煜伟(关良)
编辑|橙子君
以上是关于移动端人脸风格化技术的应用的主要内容,如果未能解决你的问题,请参考以下文章