Linux环境下文本处理,提取需要的内容?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Linux环境下文本处理,提取需要的内容?相关的知识,希望对你有一定的参考价值。
从一个文本里提取需要的内容,例如:
#
12
23
34
1.1.0
我要提取的是#以下,1.1.0这一行以上的内容,首行不要,1.1.0这行内容不变,但是不要这一行。
首行和1.1.0这一行之间有时候可能会有增减,多一行和少一行什么的,我需要的条件就是:只要首行到1.1.0之间的内容,他们有时候会多几行有时候少几行,所以没办法用行数来提取
用awk可以实现你的需求,示例如图:
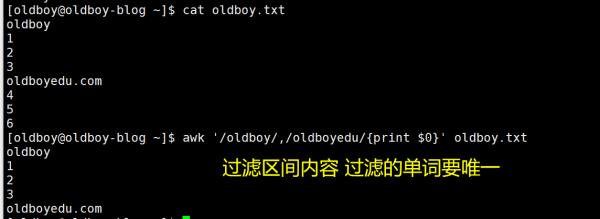
若#一定在第一行,可以用sed先获取第2行到1.1.0行,再用sed删除最后一行:
sed -n '2,/1\.1\.0/p' file.txt | sed '$d'
若#不一定在第一行,用sed先获取#行到1.1.0行,再用sed删除第一行和最后一行:
sed -n '/#/,/1\.1\.0/p' file.txt | sed '1d;$d'
Linux上验证通过,望采纳~ 参考技术B linux 文本编辑器有这个功能,可以进行光标的调整来获取你要的内容。很方便的!
linux:文本处理系列-1.行截取
参考技术A (自己)常用的文本文件的行处理命令示例文件:test.vcf
1、head -n 10 test.vcf
head : 默认是提取文件的前10行,-n 参数可以设定选择文件的前n行
2、tial -n 10 test.vcf
tail : 默认是提取文件的末尾10行, -n 参数可以设定选择文件末尾的n行
3、sed -n '10,20p' test.vcf
sed -n : 随意选择需要查看的行
sed命令是一个面向行处理的编辑器,可以和正则表达式配合使用,附上较全面的sed命令使用教程。
https://man.linuxde.net/sed
4、awk 截取行的指定长度字符串
less test.gz |awk 'if(NR%2==1)printelseprint substr($1,1,75)' | gzip -c > test.part.gz
说明:对test.gz文件指定行截取75bp,原来是150bp
5、对n行的第三列求和,求平均值
grep -v ‘#’ test.vcf |sed -n '20,35p' |awk -F '\t' 'sum+=$3;n++ENDprint sum,sum/n'
(linux 一行命令计算速度比Python快,简单计算喜欢用linux命令)
记得随时整理使用过的命令,没学过linux,靠着各种帖子,随时需要随时补给,有点懒。
以上是关于Linux环境下文本处理,提取需要的内容?的主要内容,如果未能解决你的问题,请参考以下文章