吃透Redis:数据结构篇-内存优化的数据结构设计
Posted 吃透Java
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了吃透Redis:数据结构篇-内存优化的数据结构设计相关的知识,希望对你有一定的参考价值。
数据类型
redis提供了 String、Hash、List、Set、Sorted Set 六种基本类型,以及 HyperLogLog、Bitmap 和 GEO 三种扩展类型。
- 如果你只需要存储简单的键值对,或者是对数字进行递增递减操作,就可以使用 String 存储;
- 如果除了需要存储键值数据,还想单独对某个字段进行操作,使用 Hash 就非常方便;
- 如果需要一个简单的分布式队列服务,List 就可以满足你的需求;
- 如果想得到一个不重复的集合,就可以使用 Set,而且它还可以做并集、差集和交集运算;
- 如果想实现一个带权重的评论、排行榜列表,那么,Sorted Set 就能满足你。
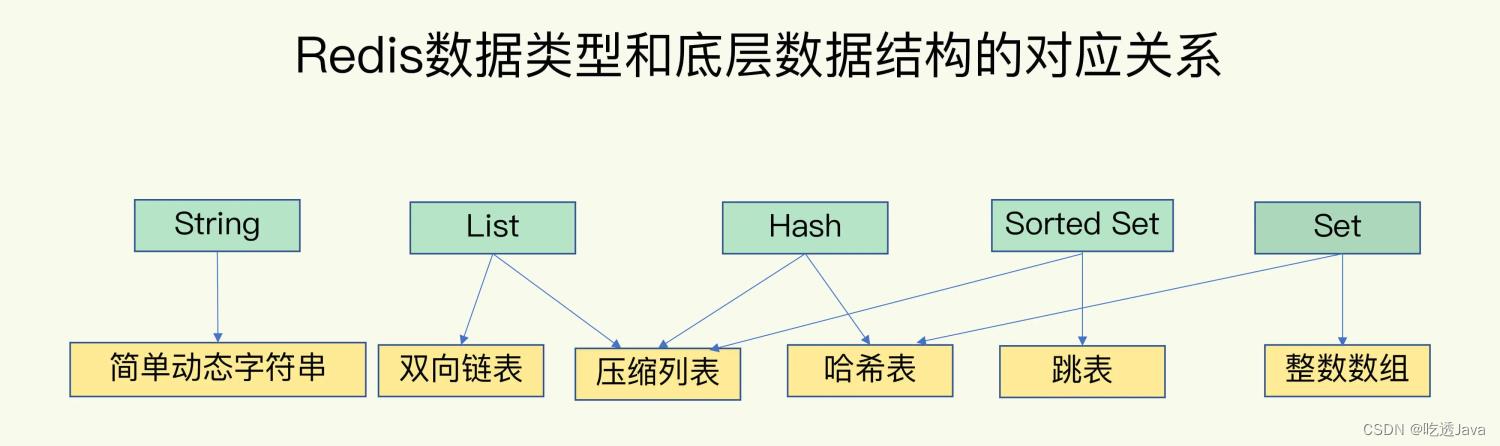
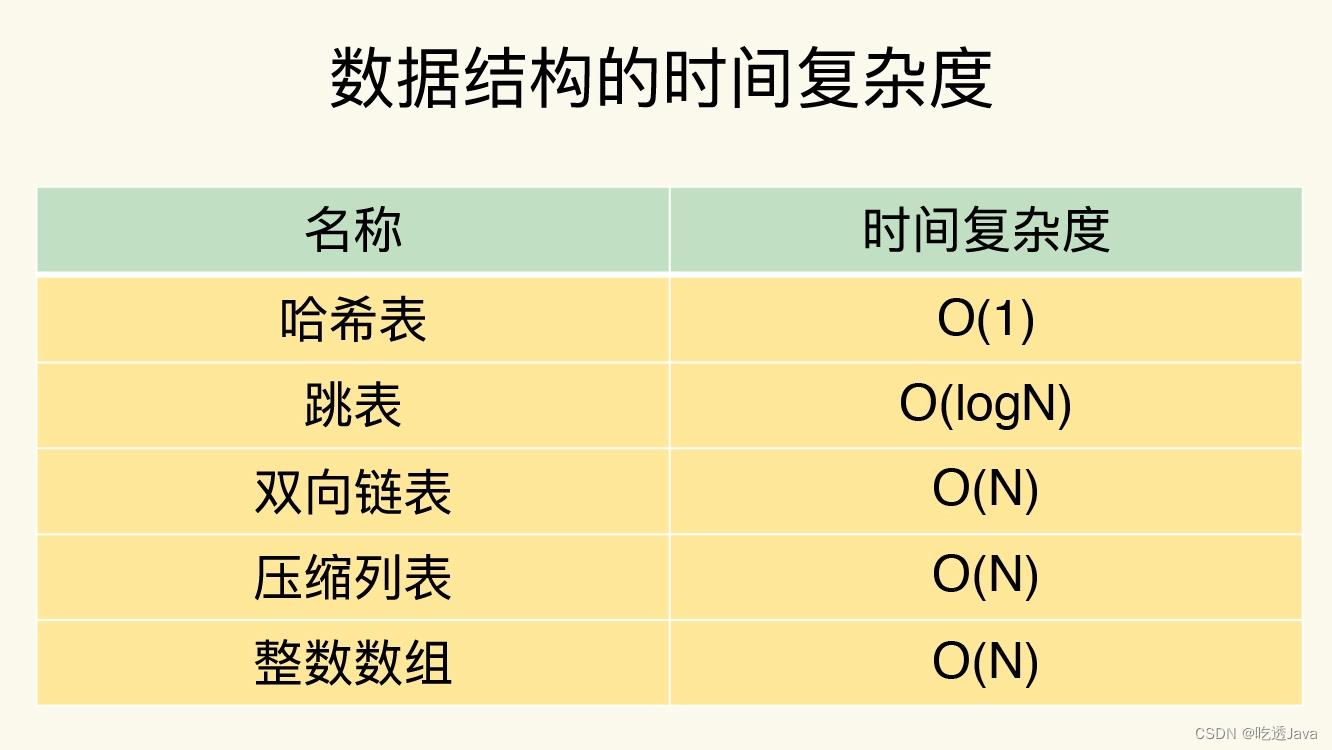
整数数组和压缩列表在查找时间复杂度方面并没有很大的优势,那为什么 Redis 还会把它们作为底层数据结构呢?
- 内存利用率,数组和压缩列表都是非常紧凑的数据结构,它比链表占用的内存要更少。Redis是内存数据库,大量数据存到内存中,此时需要做尽可能的优化,提高内存的利用率。
- 数组对CPU高速缓存支持更友好,所以Redis在设计时,集合数据元素较少情况下,默认采用内存紧凑排列的方式存储,同时利用CPU高速缓存不会降低访问速度。当数据元素超过设定阈值后,避免查询时间复杂度太高,转为哈希和跳表数据结构存储,保证查询效率。
SDS
Redis 设计了简单动态字符串(Simple Dynamic String,SDS)的结构,用来表示字符串。相比于 C 语言中的字符串实现,SDS 这种字符串的实现方式,会提升字符串的操作效率,并且可以用来保存二进制数据。
为什么 Redis 不用 c 语言中的 char?*
c语言中的char* 是以 \\0 为结尾判断的,那么在获取字符串的长度时,需要遍历字符数组中的每个元素,并且累加,直到判断到结尾标志符 \\0 。
- 操作效率低:获取长度需遍历,O(N)复杂度
- 二进制不安全:无法存储包含 \\0 的数据
SDS 的优势:
- 操作效率高:获取长度无需遍历,O(1)复杂度
- 二进制安全:因单独记录长度字段,所以可存储包含 \\0 的数据
- 兼容 C 字符串函数,可直接使用字符串 API
另外 Redis 在操作 SDS 时,为了避免频繁操作字符串时,每次「申请、释放」内存的开销,还做了这些优化:
- 内存预分配:SDS 扩容,会多申请一些内存(小于 1MB 翻倍扩容,大于 1MB 按 1MB 扩容)
- 多余内存不释放:SDS 缩容,不释放多余的内存,下次使用可直接复用这些内存
这种策略,是以多占一些内存的方式,换取「追加」操作的速度。
SDS 结构设计
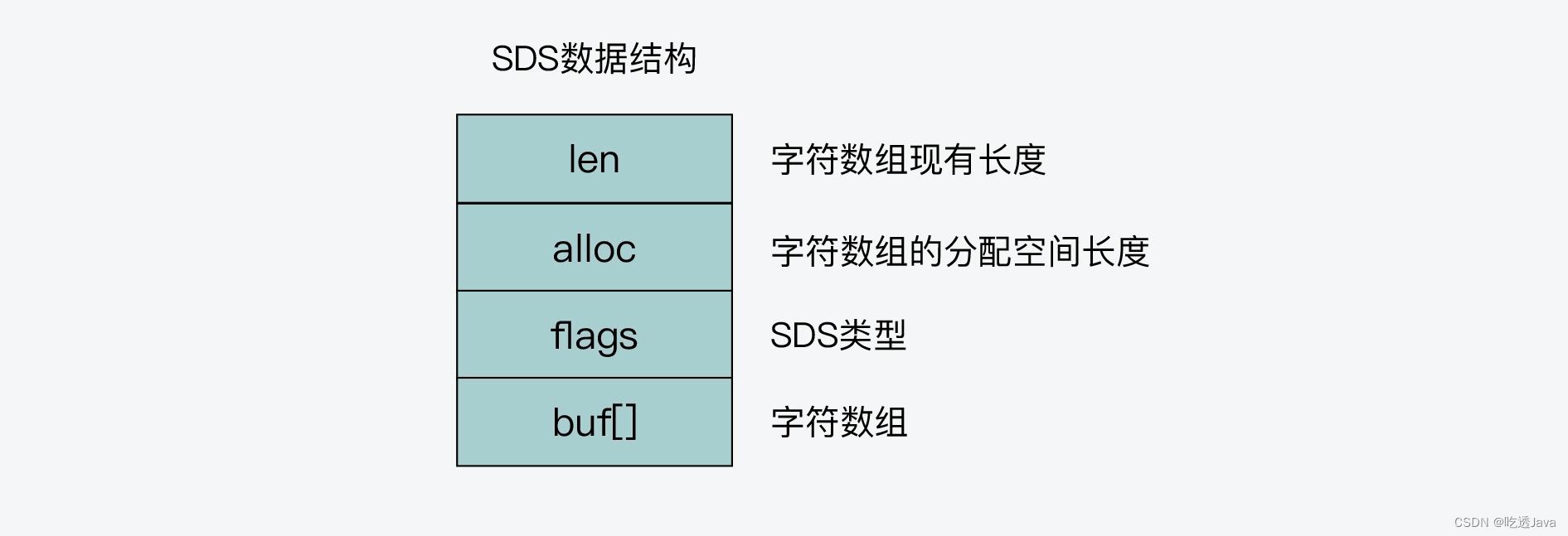
紧凑型字符串结构的技巧:
SDS 结构中有一个元数据 flags,表示的是 SDS 类型。事实上,SDS 一共设计了 4 种类型,分别是 sdshdr8、sdshdr16、sdshdr32 和 sdshdr64。这 4 种类型的主要区别就在于,它们数据结构中的字符数组现有长度 len 和分配空间长度 alloc,这两个元数据的数据类型不同。
- sdshdr8:标识 len 和 alloc 长度是用 8 位(也就是占用 1 个字节)来标识,也就是最大能表示 2^8 (256的长度)。
- sdshdr16:标识 len 和 alloc 长度是用 16 位 占用2个字节
- sdshdr32:标识 len 和 alloc 长度是用 32 位 占用4个字节
- sdshdr64:标识 len 和 alloc 长度是用 64 位 占用8个字节
SDS 之所以设计不同的结构头(即不同类型),是为了能灵活保存不同大小的字符串,从而有效节省内存空间。
压缩列表(ziplist)
List、Hash 和 Sorted Set 这三种数据类型,都可以使用压缩列表(ziplist)来保存数据,压缩列表本身就是一块连续的内存空间,它通过使用不同的编码来保存数据。
实际上,所谓的编码技术,就是指用不同数量的字节来表示保存的信息。在 ziplist 中,编码技术主要应用在列表项中的 prevlen 和 encoding 这两个元数据上。而当前项的实际数据 data,则正常用整数或是字符串来表示。
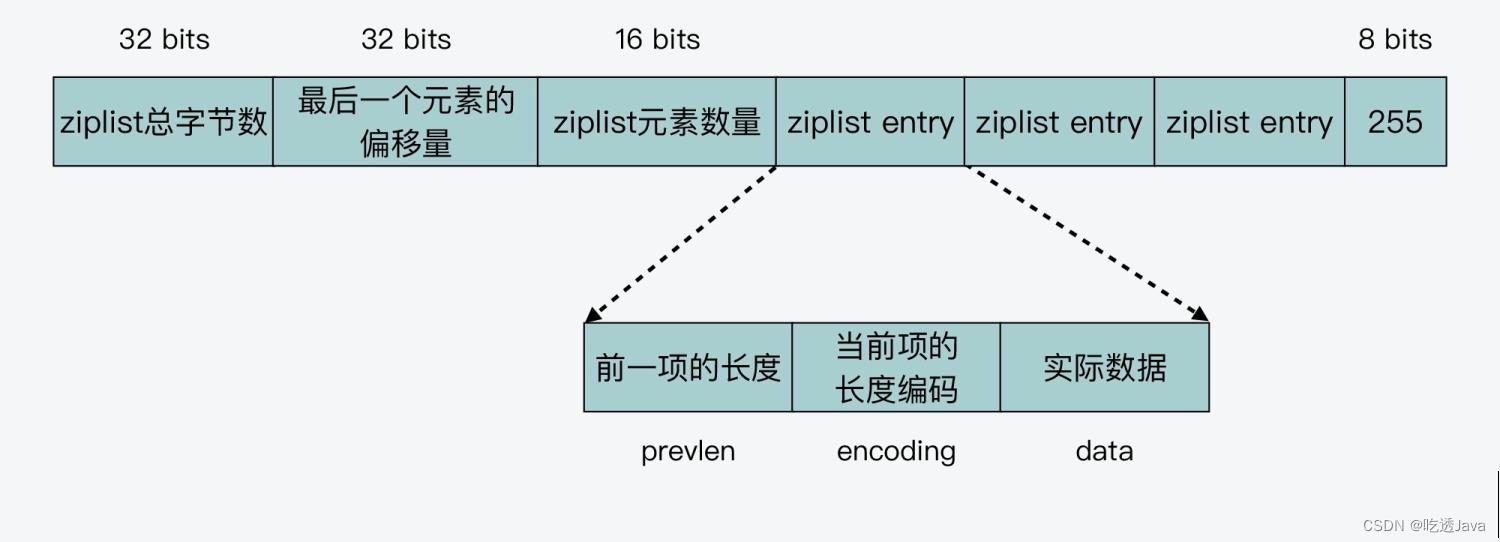
而为了方便查找,每个列表项中都会记录前一项的长度。因为每个列表项的长度不一样,所以如果使用相同的字节大小来记录 prevlen,就会造成内存空间浪费。
- prevlen:ziplist 在对 prevlen 编码时,先判断前一个列表项是否小于 254 字节。如果是的话,那么 prevlen 就使用 1 字节表示;否则,使用 5 字节表示。
- encoding:本元素编码,通过encoding我们可以知道此元素存储的类型(字符串/整型),同时字符串或是整型又能继续细分,可以知道字符串长度,整型占用字节数。
ziplist的查找
ziplist 头尾元数据的大小是固定的,并且在 ziplist 头部记录了最后一个元素的位置,所以,当在 ziplist 中查找第一个或最后一个元素的时候,就可以很快找到。但是,当要查找列表中间的元素时,ziplist 就得从列表头或列表尾遍历才行。
当 ziplist 保存的元素过多时,查找中间数据的复杂度就增加了。更糟糕的是,如果 ziplist 里面保存的是字符串,ziplist 在查找某个元素时,还需要逐一判断元素的每个字符,这样又进一步增加了复杂度。查询效率O(n)
因此,在使用 ziplist 保存 Hash 或 Sorted Set 数据时,都会在 redis.conf 文件中,通过 hash-max-ziplist-entries 和 zset-max-ziplist-entries 两个参数,来控制保存在 ziplist 中的元素个数。
- hash使用ziplist条件:数据长度小于64 或 列表长度小于512 ,并且可以通过redis.conf中的hash-max-ziplist-entries=512, hash-max-ziplist-value=64调整。
- zset使用ziplist条件:数据长度小于64 或 列表长度小于128,并且可以通过redis.conf中的zset-max-ziplist-entries=128, zset-max-ziplist-value=64调整。
ziplist的特点
- 连续内存存储:每个元素紧凑排列,内存利用率高
- 变长编码:存储数据时,采用变长编码(满足数据长度的前提下,尽可能少分配内存)
- 寻找元素需遍历:存放太多元素,性能会下降(适合少量数据存储)
- 级联更新:更新、删除元素,会引发级联更新(因为内存连续,前面数据膨胀/删除了,后面要跟着一起动)
连锁更新问题
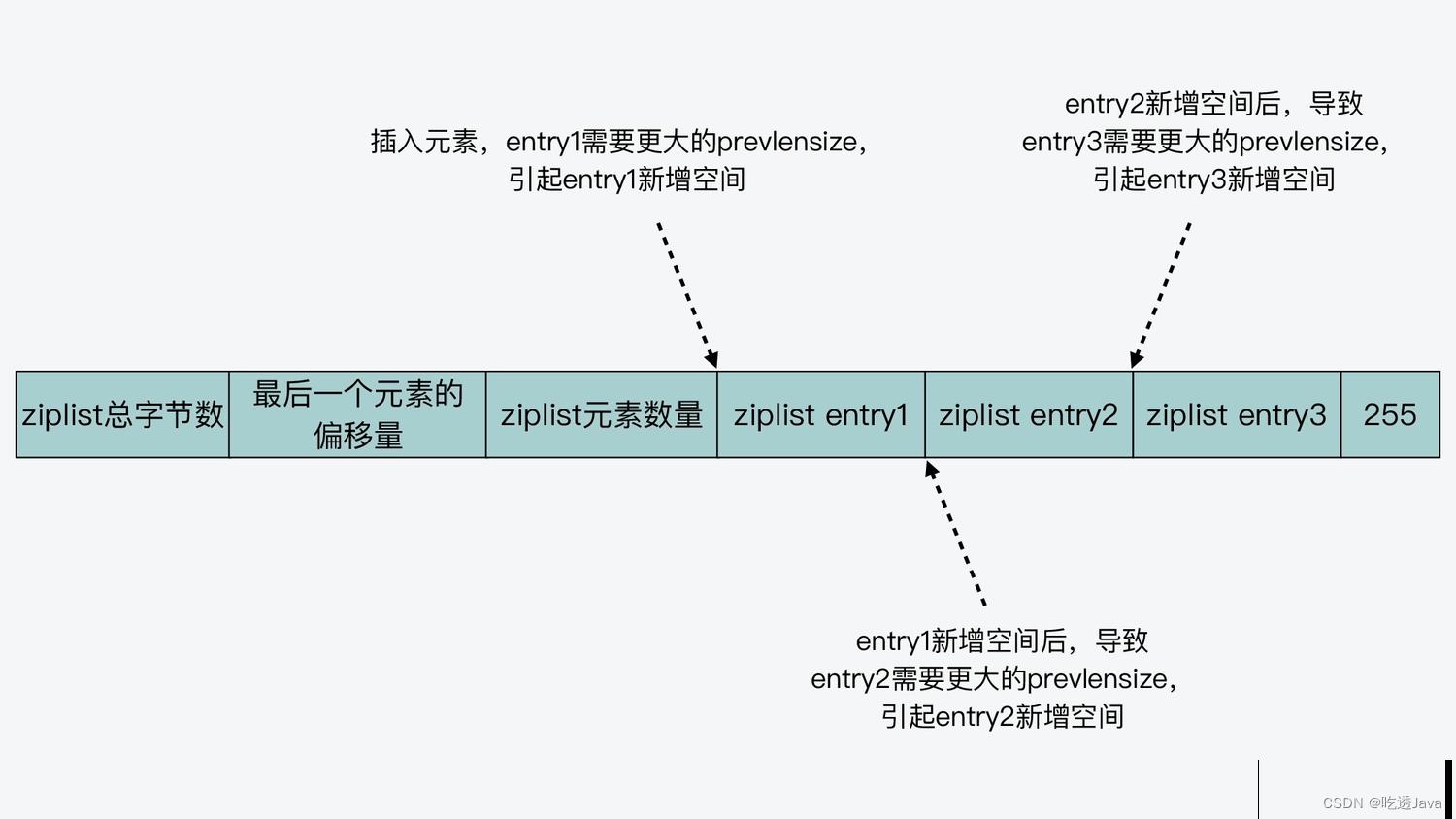
因为 ziplist 必须使用一块连续的内存空间来保存数据,所以当新插入一个元素时,ziplist 就需要计算其所需的空间大小,并申请相应的内存空间。
实际上,所谓的连锁更新,就是指当一个元素插入后,会引起当前位置元素新增 prevlensize 的空间。而当前位置元素的空间增加后,又会进一步引起该元素的后续元素,其 prevlensize 所需空间的增加。
这样,一旦插入位置后续的所有元素,都会因为前序元素的 prevlenszie 增加,而引起自身空间也要增加,这种每个元素的空间都需要增加的现象,就是连锁更新。
整形集合(intset)
整形集合(intset)是作为底层结构来实现 Set 数据类型的。和 SDS 嵌入式字符串、ziplist 类似,整数集合也是一块连续的内存空间,这一点我们从整数集合的定义中就可以看到。
typedef struct intset
uint32_t encoding;
uint32_t length;
int8_t contents[];
intset;
- encoding:指定了编码方式,总共有 int16、int32、int64 三种,分别占用 2、4、8 字节。当前编码方式不足以存储更大位数的整数时,需要升级编码,而整数集合中所有的数的编码需要保持一致。
- length:存储了整数集合的元素个数
- contents:整数集合的每个元素都是contents数组的各数组项,每一项在数组中按值的大小从小到大有序地排列,并且数组中不包含任何重复项。将contents属性声明为int8_t类型的数组,但实际contents数组并不保存任何int8_t类型的值,contents数组的真正类型取决于encoding属性的值。
由于 contents 的内存是动态分配的,所以每次进行元素插入或者删除的时候,都需要重新分配内存
在set集合中,使用intset需要满足两个条件:
- 所有元素均为整数
- 元素个数小于512
否则,会转换成哈希表结构来存储。
intset特点:
- Set 存储如果都是数字,采用 intset 存储
- 变长编码:数字范围不同,intset 会选择 int16/int32/int64 编码
- 有序:intset 在存储时是有序的,这意味着查找一个元素,可使用「二分查找」
- 编码升级/降级:添加、更新、删除元素,数据范围发生变化,会引发编码长度升级或降级
总结
降低内存开销,对于 Redis 这样的内存数据库来说非常重要,Redis 用于优化内存使用效率的两种方法:内存优化的数据结构设计和节省内存的共享数据访问。
内存优化的数据结构设计
对于实现数据结构来说,如果想要节省内存,Redis 就给我们提供了两个优秀的设计思想:
- 使用连续的内存空间,避免内存碎片开销。
- 针对不同长度的数据,采用不同大小的元数据,以避免使用统一大小的元数据,造成内存空间的浪费。
使用共享对象
在 Redis 实例运行时,有些数据是会被经常访问的,比如常见的整数,Redis 协议中常见的回复信息,包括操作成功(“OK”字符串)、操作失败(ERR),以及常见的报错信息。
所以,为了避免在内存中反复创建这些经常被访问的数据,Redis 就采用了共享对象的设计思想。这个设计思想很简单,就是把这些常用数据创建为共享对象,当上层应用需要访问它们时,直接读取就行。
使用共享对象其实可以避免重复创建冗余的数据,从而也可以有效地节省内存空间。不过,共享对象主要适用于只读场景,如果一个字符串被反复地修改,就无法被多个请求共享访问了。
redis为了充分提高内存利用率,从几个方面入手:
- 淘汰不在使用的内存空间
- 紧凑型的内存设计
- 实例内存共享
为了提高内存利用率,redis做出了以下努力:
- 设计实现了SDS
- 设计实现了ziplist
- 设计实现了intset
- 搭配redisObject设计了嵌入式字符串
- 设计了共享对象(共享内存大部是常量实例)
以上是关于吃透Redis:数据结构篇-内存优化的数据结构设计的主要内容,如果未能解决你的问题,请参考以下文章