C++的编译与链接简介
Posted -飞鹤-
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了C++的编译与链接简介相关的知识,希望对你有一定的参考价值。
1. 前言
了解C++编译连接过程,可以深入的理解C++编译的静态库、动态库的互相调用的规则,更容易发现调用过程中出现的各种问题。
1.1. 内核架构
内核主要是用来执行指令集的,指令集有很多,早期intel发明的x86指令集,32位地址总线,有哪此寄存器,有哪些汇编指令,如何加载执行可执行文件。后来AMD在x86的基础上扩展支持了64指令,这种新的架构也被称为x86-64,有时也会简称x64或AMD64。x64兼容32位,也即x64有两套指令集。x86,x64是intel和AMD共享专利的指令集,也即这两家的通用CPU指令集是一样的。指令集有很多,还有ARM公司的ARM指令集,还有开源的MIPS指令集。
1.2. 函数调用约定
函数调用过程中,会有一个参数入栈出栈的过程,但是参数是从左边先入栈还是从右边先入栈呢?这里有几种不同的规则。
1.__cdecl
所谓的C调用规则。按从右至左的顺序压参数入栈,由调用者把参数弹出栈。切记:对于传送参数的内存栈是由调用者来维护的。返回值在EAX中因此,对于象printf这样变参数的函数必须用这种规则。编译器在编译的时候对这种调用规则的函数生成修饰名的饿时候,仅在输出函数名前加上一个下划线前缀,格式为_functionname。
**2.__stdcall **
按从右至左的顺序压参数入栈,由被调用者把参数弹出栈。_stdcall是Pascal程序的缺省调用方式,通常用于Win32 Api中,切记:函数自己在退出时清空堆栈,返回值在EAX中。__stdcall调用约定在输出函数名前加上一个下划线前缀,后面加上一个“@”符号和其参数的字节数,格式为_functionname@number。如函数int func(int a, double b)的修饰名是_func@12
同样使用标准调用约定编译函数:
void __stdcall ASCEFunc(int a, int b);
在C++编译器中会编译成符号?ASCEFunc@@YGXHH@Z,而在C编译器中会编译成符号_ASCEFunc@8。C++复杂的函数符号名是为了支持函数的重载功能。
指定extern "C"即是指明用C编译器风格来编译。
3.__thiscall
仅仅应用于"C++"成员函数。this指针存放于CX寄存器,参数从右到左压。thiscall不是关键词,因此不能被程序员指定
2. 可执行文件
可执行文件 (executable file) 指的是可以由操作系统进行加载执行的文件。在不同的操作系统环境下,可执行程序的呈现方式不一样。
2.1. Windows
在windows操作系统下,可执行程序可以是 .exe,.sys,.dll,.com,.obj等类型文件。这类文件被称作PE(Portable Executable)文件,意为可移植的执行的文件。PE文件总的来说就是由DOS文件头,DOS加载模块,PE文件头,区段表和区段这5部分构成的。
一个典型的PE文件包含以下区段:
.text区段 存放可执行的二进制代码区段
.data区段 初始化数据块,比如全局变量
.idata区段 程序所使用的动态链接库等外接函数和文件信息。
.rsrc区段 存放程序的资源,图标,菜单,版本信息等。
2.2. Linux
Linux下可执行文件格式为ELF(Executable and Linkable Format),包括可扫行文件、中间目标文件".o"以及静态库".a"和动态链接库".so"文件。
1 .text字段:用于保存程序中的代码片段
2 .data字段:用于保存已经初始化的全局变量和局部变量
3 .bss字段:用于保存未初始化的全局变量和局部变量
4 .rodata:顾名思义,保存只读的变量
5 .comment:保存编译器版本信息
6 .symtab:符号表,各个目标文件链接的接口
7 .strtab:字符串表,保存符号的名字,因为各个字符串大小不一,所以统一把所有字符串放到这个段里,后续其他段通过某个符号在字符串标中的偏移可以取到符号。
8 .rela.text:因为程序声明使用了未在程序内部定义的函数或者变量,所以需要等到链接时(定义在别的目标文件或者库里)对这个符号的地址进行重新定位,不然会引用到错误的地址。
9 .shstrtab:和strtab类似,不过保存是段名,也就是说里面保存的字符串是所有段的名字
10 Section Header Table:段表,保存了所有段的信息,本身通过Elf头找到,可以解析出所有段的位置。
可以通过"objdump"和"readelf"来查看目标文件内的细节。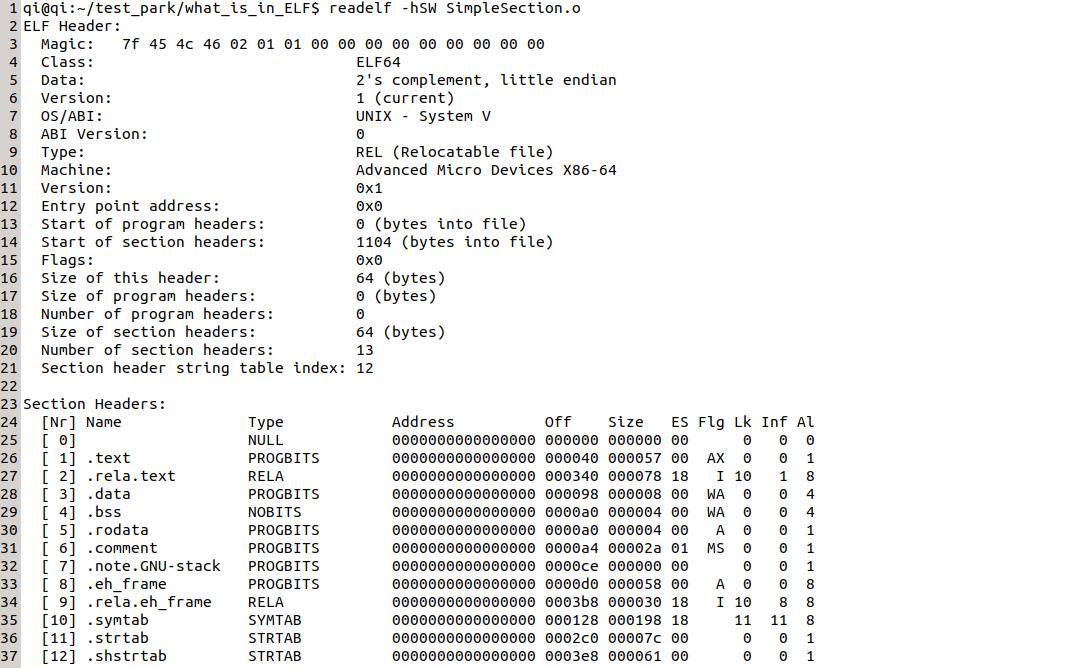
3. C++语言
C++语言是在C语言的基础上开发的,C++基本兼容C语言的语法。1998年,第一版C++标准发布,包括语言特性,C++标准库和STL库。此后经历了多次大的修改。
| 标准版本 | 发布时间 | 正式名称 | 更新内容 |
|---|---|---|---|
| C++ 03 | 2003年 | ISO/IEC 14882:2003 | 对C++ 98版本的漏洞做了部分修改。 [14] |
| C++ 11 | 2011年8月12日 | ISO/IEC 14882:2011 | 对容器类的方法做了三项主要修改: |
| 1、新增了右值引用,可以给容器提供移动语义。 | |||
| 2、新增了模板类initilizer_list,因此可将initilizer_list作为参数的构造函数和赋值运算符。 | |||
| 3、新增了可变参数模板(variadic template)和函数参数包(parameter pack),可以提供就地创建(emplacement)方法。 [15] | |||
| C++ 14 | 2014年8月18日 | ISO/IEC 14882:2014 | C++11的增量更新。主要是支持普通函数的返回类型推演,泛型lambda,扩展的lambda捕获,对constexpr函数限制的修订,constexpr变量模板化等。 [18] |
| C++ 17 | 2017年12月6日 | ISO/IEC 14882:2017 | 新增UTF-8 字符文字、折叠表达式(fold expressions):用于可变的模板、内联变量(inline variables):允许在头文件中定义变量;在if和switch语句内可以初始化变量;结构化绑定(Structured Binding):for(auto [key,value] : my_map)…;类模板参数规约(Class Template Argument Deduction):用pair p1, 2.0; 替代pair1, 2.0;;>;static_assert的文本信息可选;删除trigraphs;在模板参数中允许使用typename(作为替代类);来自 braced-init-list 的新规则用于自动推导;嵌套命名空间的定义;允许命名空间和枚举器的属性;新的标准属性:[[fallthrough]], [[maybe_unused]] 和 [[nodiscard]];对所有非类型模板参数进行常量评估;Fold表达式,用于可变的模板;A compile-time static if with the form if constexpr(expression);结构化的绑定声明,允许auto [a, b]=getTwoReturnValues()。 [24] |
| C++ 20 | 2020年12月7日 | ISO/IEC 14882:2020 | 新增模块(Modules)、协程(Coroutines)、范围 (Ranges)、概念与约束 (Constraints and concepts)、指定初始化 (designated initializers)、操作符“<=> != ==”;constexpr支持:new/delete、dynamic_cast、try/catch、虚拟、constexpr向量和字符串;计时:日历、时区支持。 [20] |
3. 编译器
常用的C++编译器有Microsoft C++和g++。编译器除了支持不同版本的语言特性外,同时也会提供相应的标准库。g++是开源的,且提供相应的标准库libstdc++.so (动态库),libstdc++.a(静态库)。Microsoft C++是与Visual Stduio同时发布的编译工具,收费不开源,其提供的标准库是msvcp100.dll(动态库),msvcprt.lib(静态库)。C++标准提出语言特性和标准库的功能,但是编译器厂商不一定会实现所有标准,可能会在不同版本中逐步实现,甚至像Microsoft会修改部分标准,提供一些不同的功能。
下面的连接有详细记录不同的编译器对C++标准的实现情况。
https://zh.cppreference.com/w/cpp/compiler_support#cpp2a
4. 编译
C++是分离编译的,即一个源文件一个源文件单独编译的。编译主要做两方面的工

4.1. 预编译
此阶段主要是由预处理器对预处理指令(#include、#define和#if)进行处理,简单来讲就是一个替换功能,将#include的文件都添加进入源文件,将#define的宏都展开,将#if 0内的代码都删除,将#if 1范围内的代码都使能。
4.2. 编译
编译即将预编译过的源文件编译生成为目标文件(MSVC的.obj文件,gcc下的.o文件)。函数是最小的可执行代码段,所以编译是以函数为最小单元进行的。编译函数A时,其中调用了函数B,此时编译器会直接去找函数B的声明,如果找不到,就直接报函数未定义了。如果找到了,编译器直接将函数B的声明分配一个对应的相对地址。函数A调用函数B时,就直接使用这个函数地址即可。也即,在编译此源文件时,函数B是否有定义(实现),不影响其编译。假如函数B在其他源文件中,此时的函数B不可能是真实地址。在编译期间的所有函数地址都只是一相相对地址,只有在链接时,才会为函数调用分配实际地址。

如上图,每一条汇编指令,都对应一条机器码指令。相同内核平台上的不同编译器,如MSVC和g++,其编译出的汇编指令可能略有不同,但是其汇编指令都是相同的。也即MSVC编译出的目标文件和g++编译出的目标文件有可能互相调用。但是不同编译器实现重载的方式不同,导致生成的函数名不一样。例如MSVC:
int Test1(char var1,unsigned long)-----“?Test1@@YGHPADK@Z”
void Test2() -----“?Test2@@YGXXZ”
这就导致g++如果想去MSVC生成的目标文件中Test2函数的定义时,可能找不到,因为规则不一样。C++编译的规则不一样,但是C语言的调用约定大家是统一的,都是*__cdecl**方式。这样只要MSVC导出一个C接口,也即通过extern "C"来修改函数编译约定,这样编译出的接口,g++也认识。
4.3. Debug & Release
- Debug,即用来调试的,那么代码不能被优化了,例如,函数不能内联了,for循环不能因为优化而变形自动展开了等。
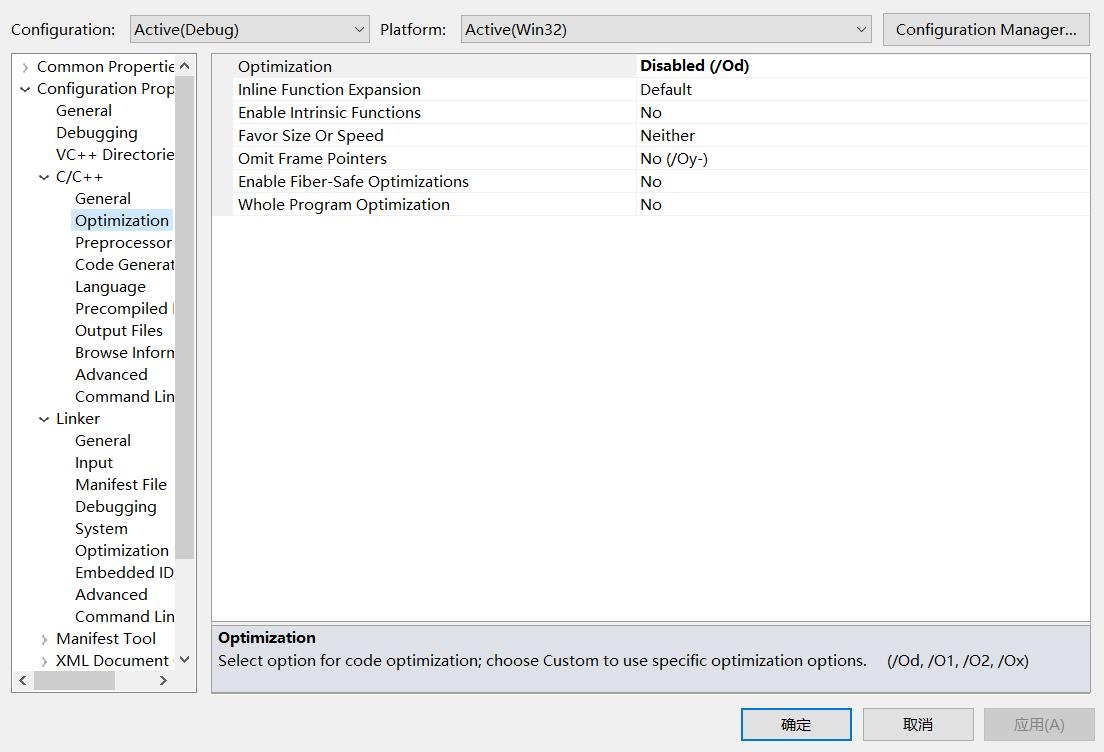
- Debug中还定义了一个宏_DEBUG。C++标准库中,MFC库中都有大量的Debug代码,用来检查参数的,会影响代码的效率。所以这些代码只在定义了宏_DEBUG才执行。
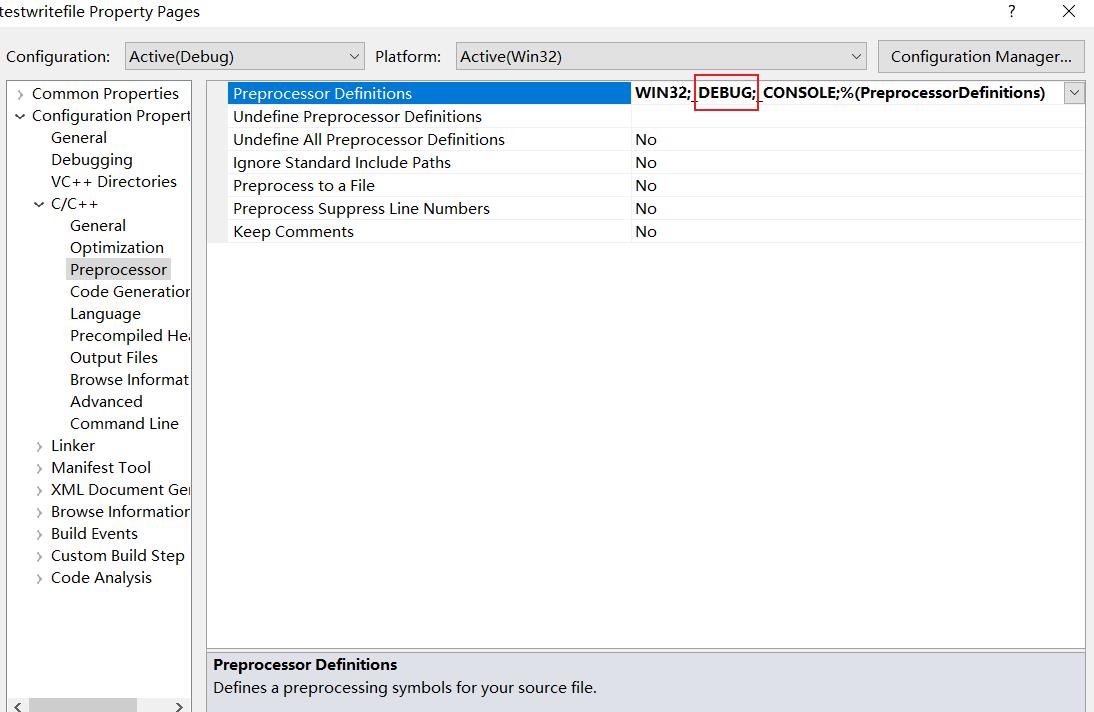
- 生成调试信息文件,调试文件即PDB文件。g++生成的调试信息直接嵌入到可执行文件中,方式和MSVC不一样。

Rlease下,如果也添加宏_DEBUG,并且关闭优化,那么其实际效果和Debug就一样了。
5. 链接
链接,主要是将许多编译源文件生成的目标文件以及各种资源文件(如图标、菜单等)合并成一个可执行文件。a.cpp对应的目标文件a.obj中的funA调用了b.cpp函数中的funB。那么链接a.obj时,就会去其他obj文件中找是否有funB的实现,如果找不到,就会报链接错误,没有找到funB的实现函数。找到funB函数的实现,就会将原来编译期间设置的相对地址改为一个实际的链接地址。
假设a.cpp是由MSVC编译的,b.cpp由g++编译的,那么funA如何正常调用funB呢?
必须extern “C” void funB();这样来限定其为C编译风格,这样才能正常调用。
5.2. 示例
#include <iostream>
int main(int argc, char *argv[])
std::cout << "Hello world!" << std::endl;
MSVC命令行编译链接:
call "C:\\Program Files (x86)\\Microsoft Visual Studio 10.0\\VC\\vcvarsall.bat"
cl /nologo /MDd /D "_DEBUG" /D "_AFXDLL" /c main.cpp
link /OUT:"main_vc.exe" /nologo /subsystem:console /TLBID:1 /DYNAMICBASE /NXCOMPAT main.obj
main_vc.exe
pause
g++命令编译链接:
g++ -std=c++11 -Wall -Wextra -g -Iinclude -c main.cpp -o main.o
g++ -std=c++11 -Wall -Wextra -g -Iinclude -o main.exe main.o -Llib
main.exe
pause
Demosrc.zip
6. 静态库
MSVC静态库以.lib结尾,g++静态库以.a结尾。静态库非常简单,可以理解为将几个.obj文件合并一个压缩文件。.lib文件都可以压缩工具解压为一个个.obj目标文件的。如:静态库math.lib/math.a中包含两个目标文件a.obj和b.obj。
此时有一个main.cpp的代码,其中用到了a.cpp和b.cpp中的函数,怎么办呢?
方法一:MSVC直接将a.obj和b.obj添加进工程中,链接的时候,自动会去a.obj或b.obj中去找。
g++ main.cpp a.o b.o -o main.exe
方法二:MSVC直接添加math.lib进程中,#pragma commet(lib, “math.lib”)
g++ main.cpp -o main.exe -L./ -ladd
C++标准库的静态库为Libcmtd.lib,MFC静态库为Nafxcwd.lib;
MSVC还提供MFC框架,封装了一些UI开发的,还有一些CFile等类。MFC的相关实现代码放在mfc100.dll中。MFC中有重新实现new,delete函数,添加了一些调试信息。mfc工程test.exe中有用到new,math.dll则一个纯C++工程,里面只用到标准C++库的函数,有new。MFC库中的new兼容标准库中的new。但是如果test.exe调用math.dll后,先连接C++标准库中的new时,可能就会有异常。此时必须告诉编译器,先链接mfc库中的new。
7. 动态库
MSVC的动态库以.dll结尾,g++的动态库以.so结尾。链接后生成的动态库,就是一个可执行代码,只不过其中没有启动代码,所以无法单独执行,只能被其他模块调用。动态库导出的函数接口,如果是C风格,那么只要支持C风格的编译器生成的exe都可以调用(基本上所有的语言都识别C风格的接口)。如果导出的接口是C++风格,那么就只能被相同的编译器使用了。
一份代码,MS2010可以编译,MS2019也可以编译,MS2010编译的main.cpp生成的main.exe,MS2019编译的math.cpp生成的math.dll。main.exe是否可以调用math.dll呢?math.dll导出的是C风格的接口,理论上main.exe应该是可以调用的。但是我们前面讲到编译器提供了两大功能,一个是编译链接器,一个是标准库。如果main.cpp中用到一个标准库的函数std::calc,math.cpp中也用到一这个标准库的函数std::calc。如果MS2019的标准库中这个函数有升级修改,添加新了参数。那么实际运行中,内存中先加载了MS2010中的标准库,在运行math.cpp中的std::calc时,会先去当前内存中有没有这个函数的实现,有就调用。此时已经有VS2010的标准库的std::calc的实现,那么就直接调用,然而实际的参数都改变了,这样调用就会异常了。
但是math.cpp中完全不用标准库的代码,这个时候就不会出现标准库不同导致的异常了。
当然这只是特殊情况,一般情况下,我们都多少会用到标准库的函数。因为exe/dll之间的相互调用,默认都应该保持相同版本的编译器来实现,避免可能细小的不同导致的异常。
MSVC支持标准C,即MSVC可以编译.c文件,标准C库的函数也可以使用。.cpp中也可以使用标准C的函数。MSVC编译.c时,使用的是C编译器,此时的标准库为msvcr100.dll中的实现函数。如果.cpp中使用标准C函数如strlen,其实现是在msvcrp100.dll中。msvcr100.dll和msvcrp100.dll是相同编译器编译的,其中C标准函数的实现是一样的,不会产生异常。
8. MSVC运行时库介绍
8.1. 静态库
标准C库,msvcrtd.lib(debug),msvcrt.lib(Release)
标准C++库,LIBCMTD.lib(Debug), LIBCMT.lib(Release)
MFC库:UAFXCWD.lib(Debug),UAFXCW.lib(Release)
8.2. 动态库
标准C库,msvcr100d.dll(debug),msvcr100.dll(Release)
标准C++库,msvcp100d.dll(Debug), msvcp100.dll(Release)
MFC库:MFC100D.DLL(Debug),MFC100.dll(Release)
8.3. 其他
MSVC还支持多字节和Unicode,上面的默认是多字节的库,其实Unicode的接口不一样,另外有一套库。
8.4. 选择
标准C/C++/MFC库,都是exe运行时需要加载的库,那么是选择使用这些库的静态版本还是动态版本呢?
前面说了静态库相当于obj的压缩集合,使用静态库,相当把所有文件编译进exe/DLL中,这样更方便,但是文件更大。如果使用动态库,那么运行时就必须加载这些库。装有MSVC的电脑,系统目录中已经装了这些动态库,所以这种方式下的exe会直接去系统目标中加载这些运行时库。但是如果想发布给别人的电脑,别人电脑上没有装这三个库,那么我们需要将我们开发电脑上的这三个文件(不同MSVC版本,dll名字不同,MS2010对应100)。
使用静态库,编译的最终结果更大,使用共享库发布版本需要附加3个运行时库。因为共享库在使用内存时更方便,一般建议使用共享库方式。但是有时只需要发布一个exe时,就需要静态库版本。
| 版 本 | 类 型 | 使用的library | 被忽略的library | 备注 |
|---|---|---|---|---|
| Release静态 | 多线程 | libcmt.lib | libc.lib, msvcrt.lib, libcd.lib, libcmtd.lib, msvcrtd.lib | MT |
| Release动态 | 使用DLL的多线程 | msvcrt.lib | libc.lib, libcmt.lib, libcd.lib, libcmtd.lib, msvcrtd.lib | MD |
| Debug静态 | 多线程 | libcmtd.lib | libc.lib, libcmt.lib, msvcrt.lib, libcmtd.lib, msvcrtd.lib | MTd |
| debug动态 | 使用DLL的多线程 | msvcrtd.lib | libc.lib, libcmt.lib, msvcrt.lib, libcd.lib, libcmtd.lib | MDd |

9. 调试原理
9.1. pdb
MSVC需要选择Debug版,并且生成PDB文件。PDB(Program Data Base),意即程序的基本数据,是VS编译链接时生成的文件。DPB文件主要存储了VS调试程序时所需要的基本信息,主要包括源文件名、变量名、函数名、FPO(帧指针)、对应的行号等等。因为存储的是调试信息,所以一般情况下PDB文件是在Debug模式下才会生成。这样在按F5进入调试时,当打一个断点(断点就是int3指令,即中断指令,即中断当前正在执行的代码。打断点,就是在直接修改正在执行的代码指令,通过PDB文件中函数代码行对应的机器码指令位置,将相应位置的代码改为int3,这样代码运行到此处即会中断停下来)。中断下来之后,程序进程内存中地有当前代码执行的堆栈,其和代码是一一对应的,PDB就是记录代码堆栈与源之间的对应关系,这样就可以找到相应变量当前的值,当前函数被谁调用的等调试信息。
PDB文件记录了当前源代码的绝对路径,并且PDB文件和生成的exe之间有md5校验,保证其是一一对应的。哪怕没有修改代码,重新编译生成的pdb文件和之前的exe也是不匹配的。
9.2. dump
代码发生异常中止时,可以生成dump文件(linux下生成coredump文件),dump文件可以复用工具手动操作生成,也可以在代码中集成自动生成。dump文件就是当前进程的整个内存,所以其中记录了寄存器,堆栈等信息,再结合PDB文件,就可以完成调试了。
10. 断点
函数断点,我们经常用,鼠标移到某一行,按下F9,即设置了最普通的断点。断点还有很多高级功能,熟练掌握,能够让我们调试更方便。
10.1. 条件断点
条件只要是表达式即可

10.2. 触发次数断点

10.3. 过滤断点

10.4. 数据断点。
断点除了我们常用的函数断点外,再就有的就是数据断点了。在Breakpoints窗口左上角可以选择New Data Breakpoint。

数据断点可以用来查找某个变量在复杂的代码里,究竟是在哪里产生的改变。另外,针对内存覆盖导致的崩溃,用数据断点也是比较方便。内存覆盖导致的崩溃,往往是某个重要变量被影响到了导致的。所以我只要找到重要变量,用数据断点监控起来就可以了。
11. 内存泄露
11.1. 开启检测
内存申请没有相应的释放,就会导致内存泄露。MSVC提供一个接口,用于检测内存泄露。
#include <crtdbg.h>
_CrtSetDbgFlag(_CRTDBG_ALLOC_MEM_DF|_CRTDBG_LEAK_CHECK_DF);
其原理是,在每处理调用new,malloc等申请内存的时候,都记录有哪些内存申请了并记录详细的函数及行数,然后在delete、free等释放内存的地方去年已经申请的内存。如果程序完全退出了,还有没有释放的内存,就通过output输出相关信息。如:
Dumping objects ->
d:\\marius\\vc++\\debuggingdemos\\debuggingdemos.cpp(103) : 341 normal block at 0x00F71F38, 8 bytes long.
Data: < > CD CD CD CD CD CD CD CD
Object dump complete.
MFC工程,默认已经调用了_CrtSetDbgFlag,开启了内存泄露检测。Win32工程没有开启,需要手动添加_CrtSetDbgFlag调用才能开启内存泄露检测。
11.2. 方法
但是有的时候,output报出的信息不太准确。此时可以使用第三方的内存检测工具。如:使用第三方工具,如Visual Leak Detector。下载安装,然后在你觉得最可能导致内存泄露的模块代码里,加上#include <vld.h>即可。如果有stdafx.h,#include <vld.h>直接放在这个文件里也是可以的。然后编译,调试运行,退出,然后就会在Output窗口里显示内存泄露的有关详细信息。
即便是第三方工具,有时也不太准确。所以修改的代码及时上传服务器,这样如果新添加的代码产生了内存泄露,和之前的代码一对比,就非常容易找到出问题的地方。
浅谈C++编译原理 ------ C++编译器与链接器工作原理
原文:https://blog.csdn.net/zyh821351004/article/details/46425823
第一篇:
首先是预编译,这一步可以粗略的认为只做了一件事情,那就是“宏展开”,也就是对那些#***的命令的一种展开。
例如define MAX 1000就是建立起MAX和1000之间的对等关系,好在编译阶段进行替换。
例如ifdef/ifndef就是从一个文件中有选择性的挑出一些符合条件的代码来交给下一步的编译阶段来处理。这里面最复杂的莫过于include了,其实也很简单,就是相当于把那个对应的文件里面的内容一下子替换到这条include***语句的地方来。
其次是编译,这一步很重要,编译是以一个个独立的文件作为单元的,一个文件就会编译出一个目标文件。(这里插入一点关于编译的文件的说明,编译器通过后缀名来辨识是否编译该文件,因此“.h”的头文件一概不理会,而“.cpp”的源文件一律都要被编译,我实验过把.h文件的后缀名改为.cpp,然后在include的地方相应的改为***.cpp,这样一来,编译器就会编译许多不必要的头文件,只不过头文件里我们通常只放置声明而不是定义,因此最后链接生成的可执行文件的大小是不会改变的)
清楚编译是以一个个单独的文件为单元的,这一点很重要,因此编译只负责本单元的那些事,而对外部的事情一概不理会,在这一步里,我们可以调用一个函数而不必给出这个函数的定义,但是要在调用前得到这个函数的声明(其实这就是include的本质,不就是为了给你提前提供个声明而好让你使用吗?至于那个函数到底是如何实现的,需要在链接这一步里去找函数的入口地址。因此提供声明的方式可以是用include把放在别的文件中的声明拿过来,也可以是在调用之前自己写一句void max(int,int);都行。),编译阶段剩下的事情就是分析语法的正确性之类的工作了。好啦,总结一下,可以粗略的认为编译阶段分两步:
第一步,检验函数或者变量是否存在它们的声明;
第二步,检查语句是否符合C++语法。
最后一步是链接,它会把所有编译好的单元全部链接为一个整体文件,其实这一步可以比作一个“连线”的过程,比如A文件用了B文件中的函数,那么链接的这一步会建立起这个关联。链接时最重要的我认为是检查全局空间里面是不是有重复定义或者缺失定义。这也就解释了为什么我们一般不在头文件中出现定义,因为头文件有可能被释放到多个源文件中,每个源文件都会单独编译,链接时就会发现全局空间中有多个定义了。
标准C和C++将编译过程定义为9个阶段(Phases of Translation):
1.字符映射(Character Mapping)
文件中的物理源字符被映射到源字符集中,其中包括三字符运算符的替换、控制字符(行尾的回车换行)的替换。许多非美式键盘不支持基本源字符集中的一些字符,文件中可用三字符来代替这些基本源字符,以??为前导。但如果所用键盘是美式键盘,有些编译器可能不对三字符进行查找和替换,需要增加-trigraphs编译参数。在C++程序中,任何不在基本源字符集中的字符都被它的通用字符名替换。
2.行合并(Line Splicing)
以反斜杠/结束的行和它接下来的行合并。
3.标记化(Tokenization)
每一条注释被一个单独的空字符所替换。C++双字符运算符被识别为标记(为了开发可读性更强的程序,C++为非ASCII码开发者定义了一套双字符运算符集和新的保留字集)。源代码被分析成预处理标记。
4.预处理(Preprocessing)
调用预处理指令并扩展宏。使用#include指令包含的文件,重复步骤1到4。上述四个阶段统称为预处理阶段。
5.字符集映射(Character-set Mapping)
源字符集成员、转义序列被转换成等价的执行字符集成员。例如:‘/a‘在ASCII环境下会被转换成值为一个字节,值为7。
6.字符串连接(String Concatenation)
相邻的字符串被连接。例如:"""hahaha""huohuohuo"将成为"hahahahuohuohuo"。
7.翻译(Translation)
进行语法和语义分析编译,并翻译成目标代码。
8.处理模板
处理模板实例。
9.连接(Linkage)
解决外部引用的问题,准备好程序映像以便执行。
第二篇:
一、C++编译模式
通常,在一个C++程序中,只包含两类文件——.cpp文件和.h文件。其中,.cpp文件被称作C++源文件,里面放的都是C++的源代码;而.h文件则被称作C++头文件,里面放的也是C++的源代码。
C+ +语言支持“分别编译”(separate compilation)。也就是说,一个程序所有的内容,可以分成不同的部分分别放在不同的.cpp文件里。.cpp文件里的东西都是相对独立的,在编 译(compile)时不需要与其他文件互通,只需要在编译成目标文件后再与其他的目标文件做一次链接(link)就行了。比如,在文件a.cpp中定义 了一个全局函数“void a() ”,而在文件b.cpp中需要调用这个函数。即使这样,文件a.cpp和文件b.cpp并不需要相互知道对方的存在,而是可以分别地对它们进行编译, 编译成目标文件之后再链接,整个程序就可以运行了。
这是怎么实现的呢?从写程序的角度来讲,很简单。在文件b.cpp中,在调用 “void a()”函数之前,先声明一下这个函数“void a();”,就可以了。这是因为编译器在编译b.cpp的时候会生成一个符号表(symbol table),像“void a()”这样的看不到定义的符号,就会被存放在这个表中。再进行链接的时候,编译器就会在别的目标文件中去寻找这个符号的定义。一旦找到了,程序也就可以 顺利地生成了。
注意这里提到了两个概念,一个是“定义”,一个是“声明”。简单地说,“定义”就是把一个符号完完整整地描述出来:它是变 量还是函数,返回什么类型,需要什么参数等等。而“声明”则只是声明这个符号的存在,即告诉编译器,这个符号是在其他文件中定义的,我这里先用着,你链接 的时候再到别的地方去找找看它到底是什么吧。定义的时候要按C++语法完整地定义一个符号(变量或者函数),而声明的时候就只需要写出这个符号的原型了。 需要注意的是,一个符号,在整个程序中可以被声明多次,但却要且仅要被定义一次。试想,如果一个符号出现了两种不同的定义,编译器该听谁的?
这 种机制给C++程序员们带来了很多好处,同时也引出了一种编写程序的方法。考虑一下,如果有一个很常用的函数“void f() ”,在整个程序中的许多.cpp文件中都会被调用,那么,我们就只需要在一个文件中定义这个函数,而在其他的文件中声明这个函数就可以了。一个函数还 好对付,声明起来也就一句话。但是,如果函数多了,比如是一大堆的数学函数,有好几百个,那怎么办?能保证每个程序员都可以完完全全地把所有函数的形式都 准确地记下来并写出来吗?
二、什么是头文件
很显然,答案是不可能。但是有一个很简单地办法,可以帮助程序员们省去记住那么多函数原型的麻烦:我们可以把那几百个函数的声明语句全都先写好,放在一个文件里,等到程序员需要它们的时候,就把这些东西全部copy进他的源代码中。
这 个方法固然可行,但还是太麻烦,而且还显得很笨拙。于是,头文件便可以发挥它的作用了。所谓的头文件,其实它的内容跟.cpp文件中的内容是一样的,都是 C++的源代码。但头文件不用被编译。我们把所有的函数声明全部放进一个头文件中,当某一个.cpp源文件需要它们时,它们就可以通过一个宏命令 “#include”包含进这个.cpp文件中,从而把它们的内容合并到.cpp文件中去。当.cpp文件被编译时,这些被包含进去的.h文件的作用便发 挥了。
举一个例子吧,假设所有的数学函数只有两个:f1和f2,那么我们把它们的定义放在math.cpp里:
/* math.cpp */
double f1()
//do something here....
return;
double f2(double a)
//do something here...
return a * a;
/* end of math.cpp */
并把“这些”函数的声明放在一个头文件math.h中:
/* math.h */
double f1();
double f2(double);
/* end of math.h */
在另一个文件main.cpp中,我要调用这两个函数,那么就只需要把头文件包含进来:
/* main.cpp */
#include "math.h"
main()
int number1 = f1();
int number2 = f2(number1);
/* end of main.cpp */
这 样,便是一个完整的程序了。需要注意的是,.h文件不用写在编译器的命令之后,但它必须要在编译器找得到的地方(比如跟main.cpp在一个目录下)。 main.cpp和math.cpp都可以分别通过编译,生成main.o和math.o,然后再把这两个目标文件进行链接,程序就可以运行了。
三、#include
#include 是一个来自C语言的宏命令,它在编译器进行编译之前,即在预编译的时候就会起作用。#include的作用是把它后面所写的那个文件的内容,完完整整地、 一字不改地包含到当前的文件中来。值得一提的是,它本身是没有其它任何作用与副功能的,它的作用就是把每一个它出现的地方,替换成它后面所写的那个文件的 内容。简单的文本替换,别无其他。因此,main.cpp文件中的第一句(#include "math.h"),在编译之前就会被替换成math.h文件的内容。即在编译过程将要开始的时候,main.cpp的内容已经发生了改变:
/* ~main.cpp */
double f1();
double f2(double);
main()
int number1 = f1();
int number2 = f2(number1);
/* end of ~main.cpp */
不多不少,刚刚好。同理可知,如果我们除了main.cpp以外,还有其他的很多.cpp文件也用到了f1和f2函数的话,那么它们也通通只需要在使用这两个函数前写上一句#include "math.h"就行了。
四、头文件中应该写什么
通 过上面的讨论,我们可以了解到,头文件的作用就是被其他的.cpp包含进去的。它们本身并不参与编译,但实际上,它们的内容却在多个.cpp文件中得到了 编译。通过“定义只能有一次”的规则,我们很容易可以得出,头文件中应该只放变量和函数的声明,而不能放它们的定义。因为一个头文件的内容实际上是会被引 入到多个不同的.cpp文件中的,并且它们都会被编译。放声明当然没事,如果放了定义,那么也就相当于在多个文件中出现了对于一个符号(变量或函数)的定 义,纵然这些定义都是相同的,但对于编译器来说,这样做不合法。
所以,应该记住的一点就是,.h头文件中,只能存在变量或者函数的声明, 而不要放定义。即,只能在头文件中写形如:extern int a;和void f();的句子。这些才是声明。如果写上int a;或者void f() 这样的句子,那么一旦这个头文件被两个或两个以上的.cpp文件包含的话,编译器会立马报错。(关于extern,前面有讨论过,这里不再讨论定义跟 声明的区别了。)
但是,这个规则是有三个例外的。
一,头文件中可以写const对象的定义。因为全局的const对象默 认是没有extern的声明的,所以它只在当前文件中有效。把这样的对象写进头文件中,即使它被包含到其他多个.cpp文件中,这个对象也都只在包含它的 那个文件中有效,对其他文件来说是不可见的,所以便不会导致多重定义。同时,因为这些.cpp文件中的该对象都是从一个头文件中包含进去的,这样也就保证 了这些.cpp文件中的这个const对象的值是相同的,可谓一举两得。同理,static对象的定义也可以放进头文件。
二,头文件中可 以写内联函数(inline)的定义。因为inline函数是需要编译器在遇到它的地方根据它的定义把它内联展开的,而并非是普通函数那样可以先声明再链 接的(内联函数不会链接),所以编译器就需要在编译时看到内联函数的完整定义才行。如果内联函数像普通函数一样只能定义一次的话,这事儿就难办了。因为在 一个文件中还好,我可以把内联函数的定义写在最开始,这样可以保证后面使用的时候都可以见到定义;但是,如果我在其他的文件中还使用到了这个函数那怎么办 呢?这几乎没什么太好的解决办法,因此C++规定,内联函数可以在程序中定义多次,只要内联函数在一个.cpp文件中只出现一次,并且在所有的.cpp文 件中,这个内联函数的定义是一样的,就能通过编译。那么显然,把内联函数的定义放进一个头文件中是非常明智的做法。
三,头文件中可以写类 (class)的定义。因为在程序中创建一个类的对象时,编译器只有在这个类的定义完全可见的情况下,才能知道这个类的对象应该如何布局,所以,关于类的 定义的要求,跟内联函数是基本一样的。所以把类的定义放进头文件,在使用到这个类的.cpp文件中去包含这个头文件,是一个很好的做法。在这里,值得一提 的是,类的定义中包含着数据成员和函数成员。数据成员是要等到具体的对象被创建时才会被定义(分配空间),但函数成员却是需要在一开始就被定义的,这也就 是我们通常所说的类的实现。一般,我们的做法是,把类的定义放在头文件中,而把函数成员的实现代码放在一个.cpp文件中。这是可以的,也是很好的办法。 不过,还有另一种办法。那就是直接把函数成员的实现代码也写进类定义里面。在C++的类中,如果函数成员在类的定义体中被定义,那么编译器会视这个函数为 内联的。因此,把函数成员的定义写进类定义体,一起放进头文件中,是合法的。注意一下,如果把函数成员的定义写在类定义的头文件中,而没有写进类定义中, 这是不合法的,因为这个函数成员此时就不是内联的了。一旦头文件被两个或两个以上的.cpp文件包含,这个函数成员就被重定义了。
五、头文件中的保护措施
考 虑一下,如果头文件中只包含声明语句的话,它被同一个.cpp文件包含再多次都没问题——因为声明语句的出现是不受限制的。然而,上面讨论到的头文件中的 三个例外也是头文件很常用的一个用处。那么,一旦一个头文件中出现了上面三个例外中的任何一个,它再被一个.cpp包含多次的话,问题就大了。因为这三个 例外中的语法元素虽然“可以定义在多个源文件中”,但是“在一个源文件中只能出现一次”。设想一下,如果a.h中含有类A的定义,b.h中含有类B的定 义,由于类B的定义依赖了类A,所以b.h中也#include了a.h。现在有一个源文件,它同时用到了类A和类B,于是程序员在这个源文件中既把 a.h包含进来了,也把b.h包含进来了。这时,问题就来了:类A的定义在这个源文件中出现了两次!于是整个程序就不能通过编译了。你也许会认为这是程序 员的失误——他应该知道b.h包含了a.h——但事实上他不应该知道。
使用"#define"配合条件编译可以很好地解决这个问题。在一 个头文件中,通过#define定义一个名字,并且通过条件编译#ifndef...#endif使得编译器可以根据这个名字是否被定义,再决定要不要继 续编译该头文中后续的内容。这个方法虽然简单,但是写头文件时一定记得写进去。
[转]C++编译器与链接器工作原理
这里并没不是讨论大学课程中所学的《编译原理》,只是写一些我自己对C++编译器及链接器的工作原理的理解和看法吧,以我的水平,还达不到讲解编译原理(这个很复杂,大学时几乎没学明白)。
要明白的几个概念:
1、编译:编译器对源文件进行编译,就是把源文件中的文本形式存在的源代码翻译成机器语言形式的目标文件的过程,在这个过程中,编译器会进行一系列的语法检查。如果编译通过,就会把对应的CPP转换成OBJ文件。
2、编译单元:根据C++标准,每一个CPP文件就是一个编译单元。每个编译单元之间是相互独立并且互相不可知。
3、目标文件:由编译所生成的文件,以机器码的形式包含了编译单元里所有的代码和数据,还有一些期他信息,如未解决符号表,导出符号表和地址重定向表等。目标文件是以二进制的形式存在的。
根据C++标准,一个编译单元(Translation Unit)是指一个.cpp文件以及这所include的所有.h文件,.h文件里面的代码将会被扩展到包含它的.cpp文件里,然后编译器编译该.cpp文件为一个.obj文件,后者拥有PE(Portable Executable,即Windows可执行文件)文件格式,并且本身包含的就是二进制代码,但是不一定能执行,因为并不能保证其中一定有main函数。当编译器将一个工程里的所有.cpp文件以分离的方式编译完毕后,再由链接器进行链接成为一个.exe或.dll文件。
下面让我们来分析一下编译器的工作过程:
我们跳过语法分析,直接来到目标文件的生成,假设我们有一个A.cpp文件,如下定义:
int n = 1;
void FunA()
++n;
它编译出来的目标文件A.obj就会有一个区域(或者说是段),包含以上的数据和函数,其中就有n、FunA,以文件偏移量形式给出可能就是下面这种情况:
偏移量 内容 长度
0x0000 n 4
0x0004 FunA ??
注意:这只是说明,与实际目标文件的布局可能不一样,??表示长度未知,目标文件的各个数据可能不是连续的,也不一定是从0x0000开始。
FunA函数的内容可能如下:
0x0004 inc DWORD PTR[0x0000]
0x00?? ret
这时++n已经被翻译成inc DWORD PTR[0x0000],也就是说把本单元0x0000位置的一个DWORD(4字节)加1。
有另外一个B.cpp文件,定义如下:
extern int n;
void FunB()
++n;
它对应的B.obj的二进制应该是:
偏移量 内容 长度
0x0000 FunB ??
这里为什么没有n的空间呢,因为n被声明为extern,这个extern关键字就是告诉编译器n已经在别的编译单元里定义了,在这个单元里就不要定义了。由于编译单元之间是互不相关的,所以编译器就不知道n究竟在哪里,所以在函数FunB就没有办法生成n的地址,那么函数FunB中就是这样的:
0x0000 inc DWORD PTR[????]
0x00?? ret
那怎么办呢?这个工作就只能由链接器来完成了。
为了能让链接器知道哪些地方的地址没有填好(也就是还????),那么目标文件中就要有一个表来告诉链接器,这个表就是“未解决符号表”,也就是unresolved symbol table。同样,提供n的目标文件也要提供一个“导出符号表”也就是exprot symbol table,来告诉链接器自己可以提供哪些地址。
好,到这里我们就已经知道,一个目标文件不仅要提供数据和二进制代码外,还至少要提供两个表:未解决符号表和导出符号表,来告诉链接器自己需要什么和自己能提供些什么。那么这两个表是怎么建立对应关系的呢?这里就有一个新的概念:符号。在C/C++中,每一个变量及函数都会有自己的符号,如变量n的符号就是n,函数的符号会更加复杂,假设FunA的符号就是_FunA(根据编译器不同而不同)。
所以,
A.obj的导出符号表为
符号 地址
n 0x0000
_FunA 0x0004
未解决符号为空(因为他没有引用别的编译单元里的东西)。
B.obj的导出符号表为
符号 地址
_FunB 0x0000
未解决符号表为
符号 地址
n 0x0001
这个表告诉链接器,在本编译单元0x0001位置有一个地址,该地址不明,但符号是n。
在链接的时候,链接在B.obj中发现了未解决符号,就会在所有的编译单元中的导出符号表去查找与这个未解决符号相匹配的符号名,如果找到,就把这个符号的地址填到B.obj的未解决符号的地址处。如果没有找到,就会报链接错误。在此例中,在A.obj中会找到符号n,就会把n的地址填到B.obj的0x0001处。
但是,这里还会有一个问题,如果是这样的话,B.obj的函数FunB的内容就会变成inc DWORD PTR[0x000](因为n在A.obj中的地址是0x0000),由于每个编译单元的地址都是从0x0000开始,那么最终多个目标文件链接时就会导致地址重复。所以链接器在链接时就会对每个目标文件的地址进行调整。在这个例子中,假如B.obj的0x0000被定位到可执行文件的0x00001000上,而A.obj的0x0000被定位到可执行文件的0x00002000上,那么实现上对链接器来说,A.obj的导出符号地地址都会加上0x00002000,B.obj所有的符号地址也会加上0x00001000。这样就可以保证地址不会重复。
既然n的地址会加上0x00002000,那么FunA中的inc DWORD PTR[0x0000]就是错误的,所以目标文件还要提供一个表,叫地址重定向表,address redirect table。
总结一下:
目标文件至少要提供三个表:未解决符号表,导出符号表和地址重定向表。
未解决符号表:列出了本单元里有引用但是不在本单元定义的符号及其出现的地址。
导出符号表:提供了本编译单元具有定义,并且可以提供给其他编译单元使用的符号及其在本单元中的地址。
地址重定向表:提供了本编译单元所有对自身地址的引用记录。
链接器的工作顺序:
当链接器进行链接的时候,首先决定各个目标文件在最终可执行文件里的位置。然后访问所有目标文件的地址重定义表,对其中记录的地址进行重定向(加上一个偏移量,即该编译单元在可执行文件上的起始地址)。然后遍历所有目标文件的未解决符号表,并且在所有的导出符号表里查找匹配的符号,并在未解决符号表中所记录的位置上填写实现地址。最后把所有的目标文件的内容写在各自的位置上,再作一些另的工作,就生成一个可执行文件。
说明:实现链接的时候会更加复杂,一般实现的目标文件都会把数据,代码分成好向个区,重定向按区进行,但原理都是一样的。
明白了编译器与链接器的工作原理后,对于一些链接错误就容易解决了。
下面再看一看C/C++中提供的一些特性:
extern:这就是告诉编译器,这个变量或函数在别的编译单元里定义了,也就是要把这个符号放到未解决符号表里面去(外部链接)。
static:如果该关键字位于全局函数或者变量的声明前面,表明该编译单元不导出这个函数或变量,因些这个符号不能在别的编译单元中使用(内部链接)。如果是static局部变量,则该变量的存储方式和全局变量一样,但是仍然不导出符号。
默认链接属性:对于函数和变量,默认链接是外部链接,对于const变量,默认内部链接。
外部链接的利弊:外部链接的符号在整个程序范围内都是可以使用的,这就要求其他编译单元不能导出相同的符号(不然就会报duplicated external symbols)。
内部链接的利弊:内部链接的符号不能在别的编译单元中使用。但不同的编译单元可以拥有同样的名称的符号。
为什么头文件里一般只可以有声明不能有定义:头文件可以被多个编译单元包含,如果头文件里面有定义的话,那么每个包含这头文件的编译单元都会对同一个符号进行定义,如果该符号为外部链接,则会导致duplicated external symbols链接错误。
为什么公共使用的内联函数要定义于头文件里:因为编译时编译单元之间互不知道,如果内联被定义于.cpp文件中,编译其他使用该函数的编译单元的时候没有办法找到函数的定义,因些无法对函数进行展开。所以如果内联函数定义于.cpp里,那么就只有这个.cpp文件能使用它。
以上是关于C++的编译与链接简介的主要内容,如果未能解决你的问题,请参考以下文章