chatGPT model说明
Posted Wonder-King
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了chatGPT model说明相关的知识,希望对你有一定的参考价值。
聊天界面
chat.openai.com
https://chat.openai.com/auth/login
chatGPT说明
最佳配置:
- 网址:/v1/chat/completions
- 模型:gpt-3.5-turbo/gpt-4
GPT-4 是一个大型多模态模型(今天接受文本输入并发出文本输出,将来会出现图像输入),由于其更广泛的常识和高级推理,它可以比我们以前的任何模型更准确地解决难题能力。与 一样gpt-3.5-turbo,GPT-4 针对聊天进行了优化,但也适用于传统的完成任务。在我们的聊天指南中了解如何使用 GPT-4 。
GPT-4 目前处于有限测试阶段,只有获得访问权限的人才能访问。请加入候补名单,以便在容量可用时获得访问权限。
| 最新款 | 描述 | 最大tokens | 训练数据 |
|---|---|---|---|
| gpt-4 | 比任何 GPT-3.5 模型都更强大,能够执行更复杂的任务,并针对聊天进行了优化。将使用我们最新的模型迭代进行更新。 | 8,192 个tokens | 截至 2021 年 9 月 |
| gpt-4-0314 | 2023 年 3 月 14 日的快照gpt-4。与 不同的是gpt-4,此模型不会收到更新,并且只会在 2023 年 6 月 14 日结束的三个月内提供支持。 | 8,192 个tokens | 截至 2021 年 9 月 |
| gpt-4-32k | 与基本gpt-4模式相同的功能,但上下文长度是其 4 倍。将使用我们最新的模型迭代进行更新。 | 32,768 个tokens | 截至 2021 年 9 月 |
| gpt-4-32k-0314 | 2023 年 3 月 14 日的快照gpt-4-32。与 不同的是gpt-4-32k,此模型不会收到更新,并且只会在 2023 年 6 月 14 日结束的三个月内提供支持。 | 32,768 个tokens | 截至 2021 年 9 月 |
对于许多基本任务,GPT-4 和 GPT-3.5 模型之间的差异并不显着。然而,在更复杂的推理情况下,GPT-4 比我们之前的任何模型都更有能力。
GPT-3.5 模型可以理解并生成自然语言或代码。我们在 GPT-3.5 系列中功能最强大且最具成本效益的模型gpt-3.5-turbo已针对聊天进行了优化,但也适用于传统的完成任务。
| 最新款 | 描述 | 最大tokens | 训练数据 |
|---|---|---|---|
| gpt-3.5-turbo | 功能最强大的 GPT-3.5 模型,并针对聊天进行了优化,成本仅为text-davinci-003. 将使用我们最新的模型迭代进行更新。 | 4,096 个tokens | 截至 2021 年 9 月 |
| gpt-3.5-turbo-0301 | 2023 年 3 月 1 日的快照gpt-3.5-turbo。与 不同的是gpt-3.5-turbo,此模型不会收到更新,并且只会在 2023 年 6 月 1 日结束的三个月内提供支持。 | 4,096 个tokens | 截至 2021 年 9 月 |
| text-davinci-003 | 可以以比curie, babbage, 或 ada 模型更好的质量、更长的输出和一致的指令遵循来完成任何语言任务。还支持在文本中插入补全。 | 4,097 个tokens | 截至 2021 年 6 月 |
| text-davinci-002 | 类似的能力,text-davinci-003但训练有监督的微调而不是强化学习 | 4,097 个tokens | 截至 2021 年 6 月 |
| code-davinci-002 | 针对代码完成任务进行了优化 | 8,001 个tokens | 截至 2021 年 6 月 |
我们建议使用gpt-3.5-turbo其他 GPT-3.5 模型,因为它的成本较低。
OpenAI 模型是不确定的,这意味着相同的输入可以产生不同的输出。temperature 设置为 0 将使输出大部分具有确定性,但可能会保留少量可变性。
虽然新gpt-3.5-turbo模型针对聊天进行了优化,但它非常适合传统的完成任务。原始的 GPT-3.5 模型针对文本补全进行了优化。
我们用于创建嵌入和编辑文本的端点使用它们自己的一组专用模型。
进行试验gpt-3.5-turbo是了解 API 功能的好方法。在您了解要实现的目标之后,您可以继续使用gpt-3.5-turbo或使用其他模型并尝试围绕其功能进行优化。
您可以使用GPT 比较工具,让您并排运行不同的模型来比较输出、设置和响应时间,然后将数据下载到 Excel 电子表格中。
GPT-3 模型可以理解和生成自然语言。这些模型被更强大的 GPT-3.5 代模型所取代。但是,原始 GPT-3 基本模型(davinci、curie、ada和babbage)是当前唯一可用于微调的模型。
| 最新款 | 描述 | 最大tokens | 训练数据 |
|---|---|---|---|
| text-curie-001 | 非常有能力,比davinci更快,成本更低。 | 2,049 个tokens | 截至 2019 年 10 月 |
| text-babbage-001 | 能够执行简单的任务,速度非常快,成本更低。 | 2,049 个tokens | 截至 2019 年 10 月 |
| text-ada-001 | 能够执行非常简单的任务,通常是 GPT-3 系列中最快的型号,而且成本最低。 | 2,049 个tokens | 截至 2019 年 10 月 |
| davinci | 功能最强大的 GPT-3 模型。可以完成其他模型可以完成的任何任务,而且通常质量更高。 | 2,049 个tokens | 截至 2019 年 10 月 |
| curie | 非常有能力,但比davinci更快,成本更低。 | 2,049 个tokens | 截至 2019 年 10 月 |
| babbage | 能够执行简单的任务,速度非常快,成本更低。 | 2,049 个tokens | 截至 2019 年 10 月 |
| ada | 能够执行非常简单的任务,通常是 GPT-3 系列中最快的型号,而且成本最低。 | 2,049 个tokens | 截至 2019 年 10 月 |
Codex 模型现已弃用。他们是我们 GPT-3 模型的后代,可以理解和生成代码。他们的训练数据包含自然语言和来自 GitHub 的数十亿行公共代码。了解更多。
他们最擅长 Python,精通 javascript、Go、Perl、php、Ruby、Swift、TypeScript、SQL 甚至 Shell 等十几种语言。
以下 Codex 模型现已弃用:
| 最新款 | 描述 | 最大tokens | 训练数据 |
|---|---|---|---|
| code-davinci-002 | 功能最强大的 Codex 型号。特别擅长将自然语言翻译成代码。除了补全代码,还支持在代码中插入补全。 | 8,001 个tokens | 截至 2021 年 6 月 |
| code-davinci-001 | 早期版本code-davinci-002 | 8,001 个tokens | 截至 2021 年 6 月 |
| code-cushman-002 | 几乎与 Davinci Codex 一样强大,但速度稍快。这种速度优势可能使其成为实时应用程序的首选。 | 最多 2,048 个tokens | |
| code-cushman-001 | 早期版本code-cushman-002 | 最多 2,048 个tokens |
| 网站地址 | 型号名称 | |
|---|---|---|
| /v1/chat/completions | gpt-4, gpt-4-0314, gpt-4-32k, gpt-4-32k-0314, gpt-3.5-turbo, gpt-3.5-turbo-0301 | |
| /v1/completions | text-davinci-003, text-davinci-002, text-curie-001, text-babbage-001, text-ada-001, davinci, curie, babbage, ada | |
| /v1/edits | text-davinci-edit-001, code-davinci-edit-001 | |
| /v1/audio/transcriptions | whisper-1 | |
| /v1/audio/translations | whisper-1 | |
| /v1/fine-tunes | davinci, curie, babbage, ada | |
| /v1/embeddings | text-embedding-ada-002, text-search-ada-doc-001 | |
| /v1/moderations | text-moderation-stable, text-moderation-latest |
此列表不包括我们的第一代嵌入模型和我们的DALL·E 模型。
随着 的发布gpt-3.5-turbo,我们的一些模型现在正在不断更新。为了减少模型更改以意外方式影响我们用户的可能性,我们还提供将在 3 个月内保持静态的模型版本。随着模型更新的新节奏,我们还让人们能够贡献评估,以帮助我们针对不同的用例改进模型。如果您有兴趣,请查看OpenAI Evals存储库。
以下模型是将在指定日期弃用的临时快照。如果您想使用最新的模型版本,请使用标准模型名称,例如gpt-4或gpt-3.5-turbo。
| 型号名称 | 弃用日期 | |
|---|---|---|
| gpt-3.5-turbo-0301 | 2023 年 6 月 1 日 | |
| gpt-4-0314 | 2023 年 6 月 14 日 | |
| gpt-4-32k-0314 | 2023 年 6 月 14 日 |
ChatGPT 辅助专利写作
前言
总结一些在专利写作中使用 ChatGPT 的命令。
文章目录
一、专利概述
专利组成部分
- 著录项目
- 说明书摘要
- 摘要附图
- 权利要求书
- 说明书
- 说明书附图
1. 著录项目
- 申请文件的第一页即为著录项目;
- 包括 申请公布号、申请公布日,申请号、申请日;
- 顺序:先申请专利,再申请公布,申请公布日的时间晚于申请日;

2. 说明书摘要
- 字数:不超过
300字; - 本质和论文中的摘要是相同的,通过最简明扼要的语言提取出专利的核心内容;
- 包括研究目的、研究方法、结果和结论。
3. 权利要求书
- 权利要求书是专利文件中的核心部分,具有明确的法律效力,能够对专利保护范围进行清晰且明确的界定;
- 由若干项权利要求组成,包括:
- 独立权利要求:要求从整体上反映发明或实用型专利的主要技术内容,记载构成发明或者实用新型必要的技术特征;
- 从属权利要求:要求是在独立权利要求的基础上限定了新的技术特征,是对独立权利要求技术方案的进一步限定;
4. 说明书
- 包括内容:
- 技术领域、背景技术、发明内容、附图说明和具体实施方式,其中最重要的两部分为发明内容和具体实施方式;
- 发明内容:通过细粒度的讲解方法来讲解发明中所包含的具体模块、模块中对应的具体操作步骤;
- 具体实施方式:是对发明内容的实例化,即通过实际的例子更加细粒度的介绍发明内容;
- 技术领域、背景技术、发明内容、附图说明和具体实施方式,其中最重要的两部分为发明内容和具体实施方式;
5. 说明书附图
- 用于说明具体的操作步骤或者外观设计,是专利中必不可少的部分,具有固定的格式。
6. 权利书和说明书的区别
- 说明书是纯技术上的事情,用于解释这项专利;
- 说明书要尽量详细丰富;
- 权利要求书是类似条约的东西,给定了申请人希望保护的技术方案;
- 可以理解为结合说明书进行的总结和概括;
- 权利要求书来源基于说明书的技术解释,保护范围最好不超出说明书中记载的技术方案;
- 权利要求书要尽可能简洁;
二、ChatGPT 辅助写作命令
- 【咒语】
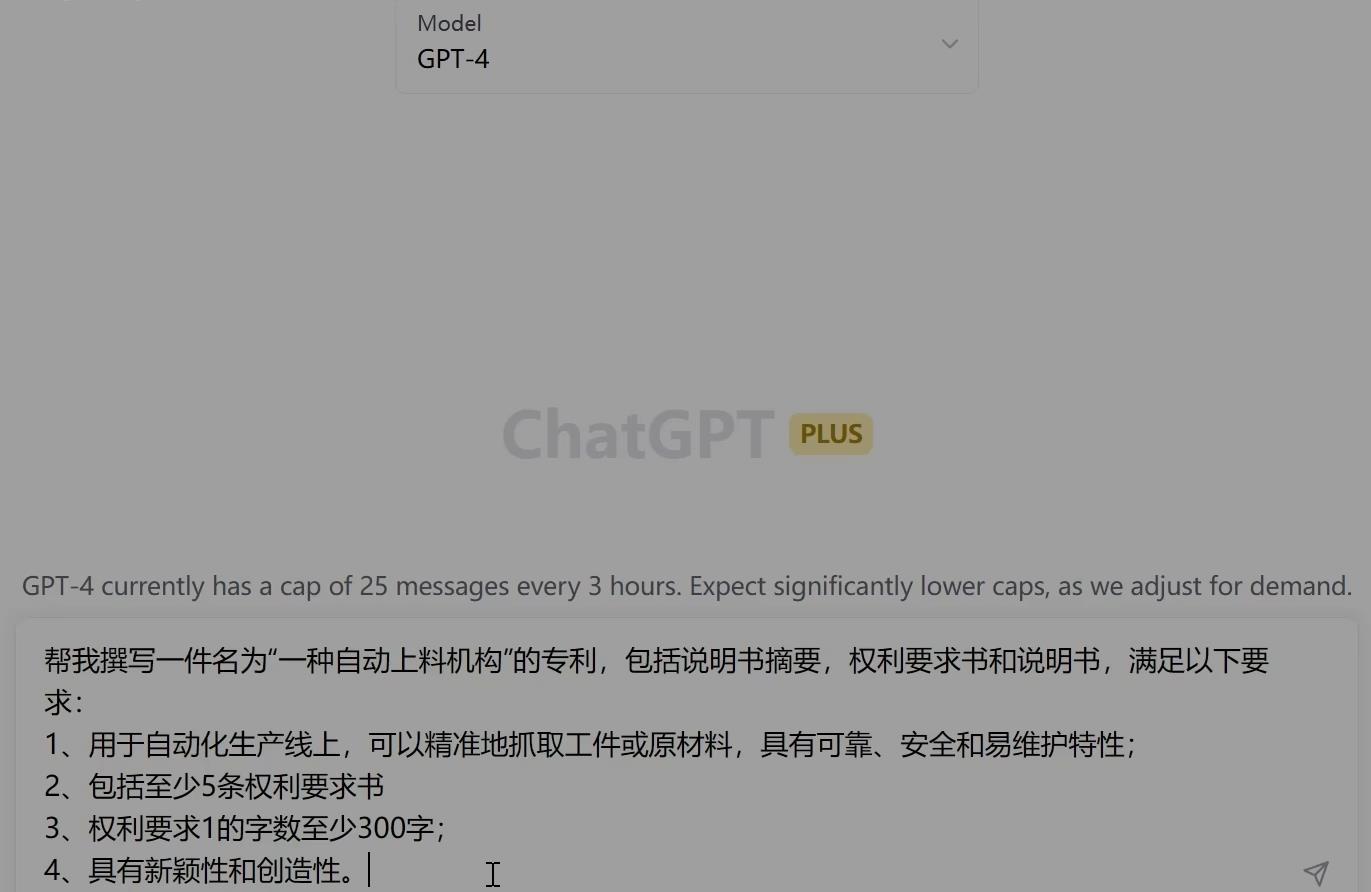
- 配图绘制
- 可以借助 midjourney 来完成
- 科研绘图教程教程,后续会更新!
以上是关于chatGPT model说明的主要内容,如果未能解决你的问题,请参考以下文章
java调用chatgpt接口,实现专属于自己的人工智能助手
PPT《挑战用chatgpt完成流水线操作的ppt,再也不用担心每周肝组会报告ppt了#人工智能 #chatgpt应用领域 快学起来!!!》- 知识点目录