Kafka消息底层存储结构介绍
Posted 刘Java
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kafka消息底层存储结构介绍相关的知识,希望对你有一定的参考价值。
此前,我们学习了RocketMQ的底层消息存储架构:RocketMQ的底层消息存储架构以及优化措施,现在我们来学习一下Kafka的底层消息存储架构,看看他们有什么区别?
实际上,如果你看完了这两篇文章,你会发现RocketMQ和Kafka的底层消息存储架构有很多相似之处,为什么呢?因为RocketMQ借鉴了Kafka的设计,不仅仅是底层存储,还包括其他高性能设计,然而,RocketMQ作为一款受欢迎的开源MQ,必然有其独特之处!
文章目录
1 消息存储结构
向kafka的某个topic中写消息,实际上就是向内部的某个partition写消息,读取消息也是从某个partition上读取消息。
一个topic的实际物理存储实际上对应着一个个的文件夹,文件夹名字是按照topic-num进行目录划分的,topic就是topic名字,num就是partition编号,从0开始。
partition文件夹下面也不仅仅是一个日志文件,而是有多个文件,这些多个文件可以从逻辑上将文件名一致的文件集合就称为一个 LogSegment日志段文件组。partion相当于一个巨型文件,被平均分配到多个大小相等的LogSegment数据文件中,每个LogSegment内部的消息数量不一定相等,这种分段存储的特性特性方便旧的LogSegment file快速被删除,同时加快了文件查找速度。
每个逻辑segment段主要包含:消息日志文件(以log结尾)、偏移量索引文件(以index结尾)、时间戳索引文件(以timeindex结尾)、快照文件(以.snaphot结尾)等等文件。
如下表示一个某个topic文件夹下的主要文件结构:
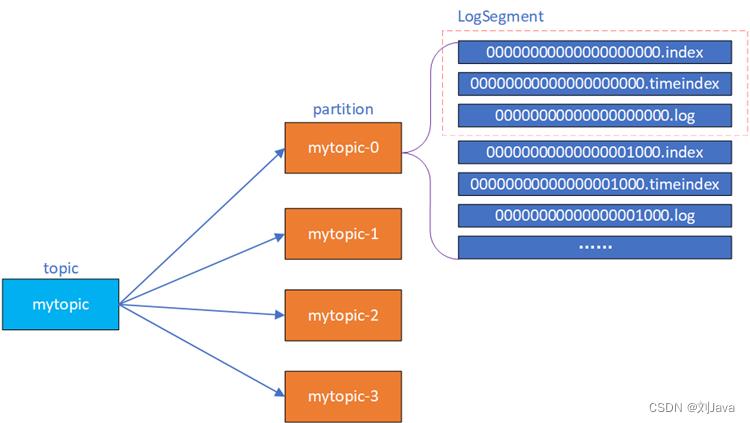
每组 LogSegment 都有一个基准偏移量,用来表示当前 LogSegment 中第一条消息的 offset。消息offset是一个 64 位的长整形数,固定20位十进制整数,长度未达到,用 0 进行填补。每个partition的消息offset单独维护,一个partition下的全局offset从0开始。
换个角度来看,每组 LogSegment 的基准偏移量就是上一组LogSegment的最大消息偏移量+1,每一个LogSegment的索引文件和日志文件都由自己的基准偏移量作为文件名,因此第一组LogSegment的索引文件和日志文件名都是00000000000000000000。
2 相关存储文件
2.1 数据日志文件
log文件作为日志文件,存储了消息内容以及该消息相关的元数据。Kafka会将消息以追加的方式顺序持久化到partition下面的最新的日志段下面的日志文件中,即只有最后一个logSegment文件才能执行写入操作。
每一个条消息日志的主要包含offset,MessageSize,data三个属性(还有一些其他属性):
- offset:8字节,表示Message在这个partition中的全局偏移量,这是一个逻辑值而不是实际无力偏移量,它唯一确定了partition中的一条Message所在的逻辑位置,可以看作是partition中Message的id,offset从0开始。
- MessageSize:4字节,表示消息内容的大小;
- data:Message的具体内容,大小不固定。
2.2 偏移量索引文件
index文件作为偏移量索引文件,主要用于加快查找消息的速度。该文件中的每一条索引记录都对应着log文件中的一条消息记录。
一条索引记录包含相对offset和position两个属性(均为4字节):
- 相对offset:因为数据文件分段以后,每个数据文件的起始offset不为0,相对offset表示这条Message相对于其对应的数据文件中最小offset(也就是基准offset)的大小。举例,分段后的一个数据文件的offset是从20开始,那么offset为25的Message在index文件中的相对offset就是25-20 = 5。存储相对offset可以减小索引文件占用的空间。
- position:表示该条Message在数据文件中的物理位置。只要打开对应log文件并移动文件指针到这个position就可以读取对应的Message内容了。
相对offset大小为4字节,因此最大值为Integer.MAX_VALUE。在写入消息时会对要写入的相对offset进行校验,超过该值时将会自动进行日志段切分。
假设某个LogSegment段中的数据文件名1234.log,索引文件中某个索引条目为(3,497)为例,那么这个索引条目对应的消息就是在数据文件中的第4个消息,该消息全局offset为1238,该消息的物理偏移地址(相对数据文件)为497。
2.2.1 稀疏索引
index索引文件中并没有为数据文件中的每条Message建立索引,而是采用了稀疏索引,默认每间隔4k的数据建立一条索引,时间戳索引文件(以timeindex结尾)也是这个规则。通过log.index.interval.bytes属性可以更新间隔数量大小。
稀疏索引避免了索引文件占用过多的空间,从而可以将索引文件长期保留在内存中,但缺点是没有建立索引的Message也不能一次性定位到其在数据文件的位置,从而需要做一次顺序扫描,但是这次顺序扫描的范围就很小了。
某个index文件内容可能如下:
offset:0 position:0
offset:20 position:320
offset:43 position:1220
Kafka还采用了mmap的方式直接将 index 文件映射到内存中(Java中就是MappedByteBuffer),这样对 index 的操作就不需要操作磁盘 IO,大大的减少了磁盘IO次数和时间。
2.3 时间戳索引文件
和index偏移量索引文件一样,timeindex时间戳索引文件也是采用稀疏索引,默认每写入4k数据量的间隔记录一次时间索引项。
每个时间戳索引分为2部分,共占12个字节:
- timestamp:当前日志分段文件中建立索引的消息的时间戳;
- relativeoffset:时间戳对应消息的相对偏移量;
某个timeindex文件内容可能如下:
timestamp: 1627378362898 relativeoffset:0
timestamp: 1627378362998 relativeoffset:20
timestamp: 1627378363198 relativeoffset:43
3 查找消息
3.1 根据offset查找消息
假设kafka要根据offset来查找消息:
- 根据 offset 的值,查找对应的index 索引文件。由于索引文件命名是以该文件的第一个绝对offset 进行命名的,所以,使用二分查找能够根据offset 快速定位到对应的索引文件。
- 找到index索引文件后,根据相对offset进行定位,找到索引文件中小于等于当前offset对应的相对offset的最大索引,并得到position,即message的物理偏移地址。比如该offset的相对偏移量为100,而索引文件中存在的相对偏移量有(50,80,110),那么最后找到的就是相对偏移量为80的消息的物理偏移地址。
- 得到position以后,再到对应的log文件中,直接从对应position位置开始,查找offset对应的消息,向后依次顺序遍历,将每条消息的offset与目标offset进行比较,直到找到消息。
可以看到,由于index是稀疏索引,因为可能在索引文件中并不能直接定位到所要查找的消息的位置,还是可能需要去log文件中做一次遍历查找,但是这次扫描的范围就很小了。
3.2 根据时间戳查找消息
如果我们根据时间戳来查找消息,那么我们需要横跨三个文件:timeindex时间戳索引文件,index偏移量索引文件,log日志数据文件。因此相比于使用offset来查找消息要更慢一些。
假设我们需要根据1627378362999这个时间戳来查询消息。
- 将 1627378362999和每个日志分段中最大时间戳 largestTimeStamp 逐一对比,直到找到一个不小于1627378362999的日志分段。日志分段中的 largestTimeStamp 的计算是先查询该日志分段所对应时间戳索引文件,找到最后一条索引项,若最后一条索引项的时间戳字段值大于 0 ,则取该值,否则去查找该日志分段的最近修改时间。
- 找到相应日志分段之后,使用二分法进行定位,与偏移量索引方式类似,找到不大于 1627378362999最大索引项,也就是 [1627378362998 20]。
- 拿着偏移量为 320到偏移量索引文件中使用二分法找到不大于 20最大索引项,即 [20,320] 。
- 日志文件中从 320 的物理位置开始顺序查找时间戳不小于1627378362998数据。
4 相关配置
| 配置项 | 默认值 | 说明 |
|---|---|---|
| log.index.interval.bytes | 4096 (4K) | 增加索引项的写入日志字节间隔大小,该值会影响索引文件中的区间密度和查询效率 |
| log.segment.bytes | 1073741824 (1G) | 一个日志段的日志文件最大大小 |
| log.roll.ms | 当前日志分段中消息的最大时间戳与当前系统的时间戳的差值允许的最大范围,毫秒维度 | |
| log.roll.hours | 168 (7天) | 当前日志分段中消息的最大时间戳与当前系统的时间戳的差值允许的最大范围,小时维度 |
| log.index.size.max.bytes | 10485760 (10MB) | 触发偏移量索引文件或时间戳索引文件分段字节限额 |
5 segment切分
- 当日志分段文件的大小超过broker参数log.segment.bytes,默认值为1073741824,即1GB。
- 当日志分段中的最大时间戳与当前系统的差值大于log.roll.ms或log.roll.hours,前者优先级高。默认只配置了log.roll.hours,值为168,即7天。
- 偏移量索引文件或者时间戳索引文件大小超过broker参数log.index.size.max.bytes,默认大小为10485760,即10MB。
- 新追加消息的offset与当前日志段的基础offset(baseOffset)插值大于Integer.MAX_VALUE时,也就是相对位移量超过了最大值。
6 总结
- parition中的消息采用多个小文件段的方式存储,很容易实现消息定期清除或删除已经消费完的文件。
- 通过索引文件可以快速定位message在日志文件中的位置。
- 索引文件通过Mmap技术直接映射到内存中,这样对索引的操作就不需要操作磁盘IO,也减少了数据在内存中的拷贝次数。
- 索引文件采用稀疏存储,可以大幅降低索引文件映射到内存中时占用的内存空间大小。
以上是关于Kafka消息底层存储结构介绍的主要内容,如果未能解决你的问题,请参考以下文章