运维告诉我CPU飙升300%,为什么我的程序上线就奔溃了
Posted 烟花散尽13141
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了运维告诉我CPU飙升300%,为什么我的程序上线就奔溃了相关的知识,希望对你有一定的参考价值。
线上服务CPU飙升
前言
- 功能开发完成仅仅是项目周期中的第一步,一个完美的项目是在运行期体现的
- 今天我们就来看看笔者之前遇到的一个问题CPU飙升的问题。 代码层面从功能上看没有任何问题但是投入使用后却让我头大
问题描述
- 系统上点击数据录入功能在全局监控中会受到相关消息的通知。此时服务器CPU飙升300%
问题定位
- 首先我们先梳理下
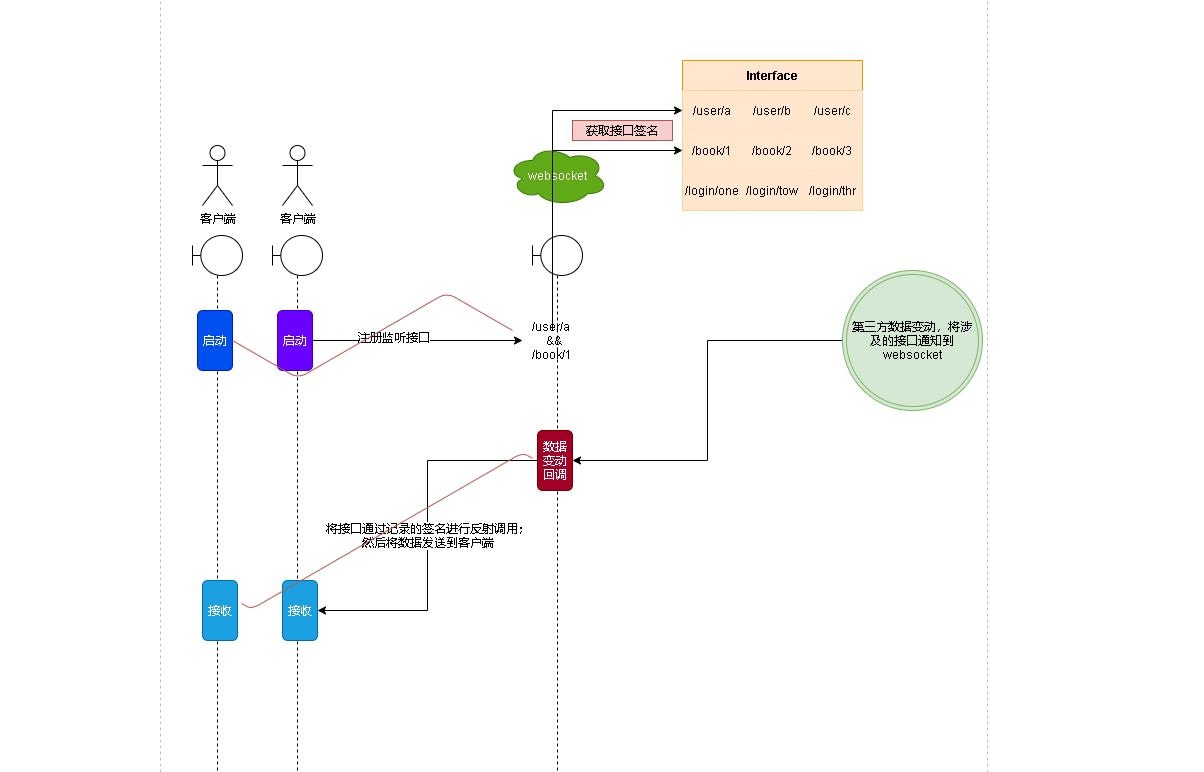
Websocket的数据发送的简单原理示意图。往往定位问题得清楚我们的逻辑是什么 - 当一个客户端启动时除了和
Websocket建立连接之外,我们还需要向Websocket服务注册当前客户端需要哪些接口的实时数据 - 我在代码内部是通过一个Map来存储这些接口签名信息的。然后客户注册时候将这些接口和客户端绑定在一起
- 当我们监听程序坚挺到数据变动就会对绑定到相关接口的客户端发送最新数据
业务定位
- 业务上很好定位,问题就是出现在我们的监听程序中。当监听到数据给
websocket客户端发送订阅的最新变动接口时就会出现CPU飙升。持续时间还很长,稍等一会就会降下来 - 这很明显是我们推送消息的时候出现了问题
隔离业务看本质
- 作为一个合格的程序员呢,必须摆脱业务才能有所收获 。业务是我们代码的外壳所有的问题基本上都是我们本质的问题。我们线上使用用户1W内。在这种的并发场景下应该是不会出问题的。现在出了问题肯定我们的程序逻辑有缺陷
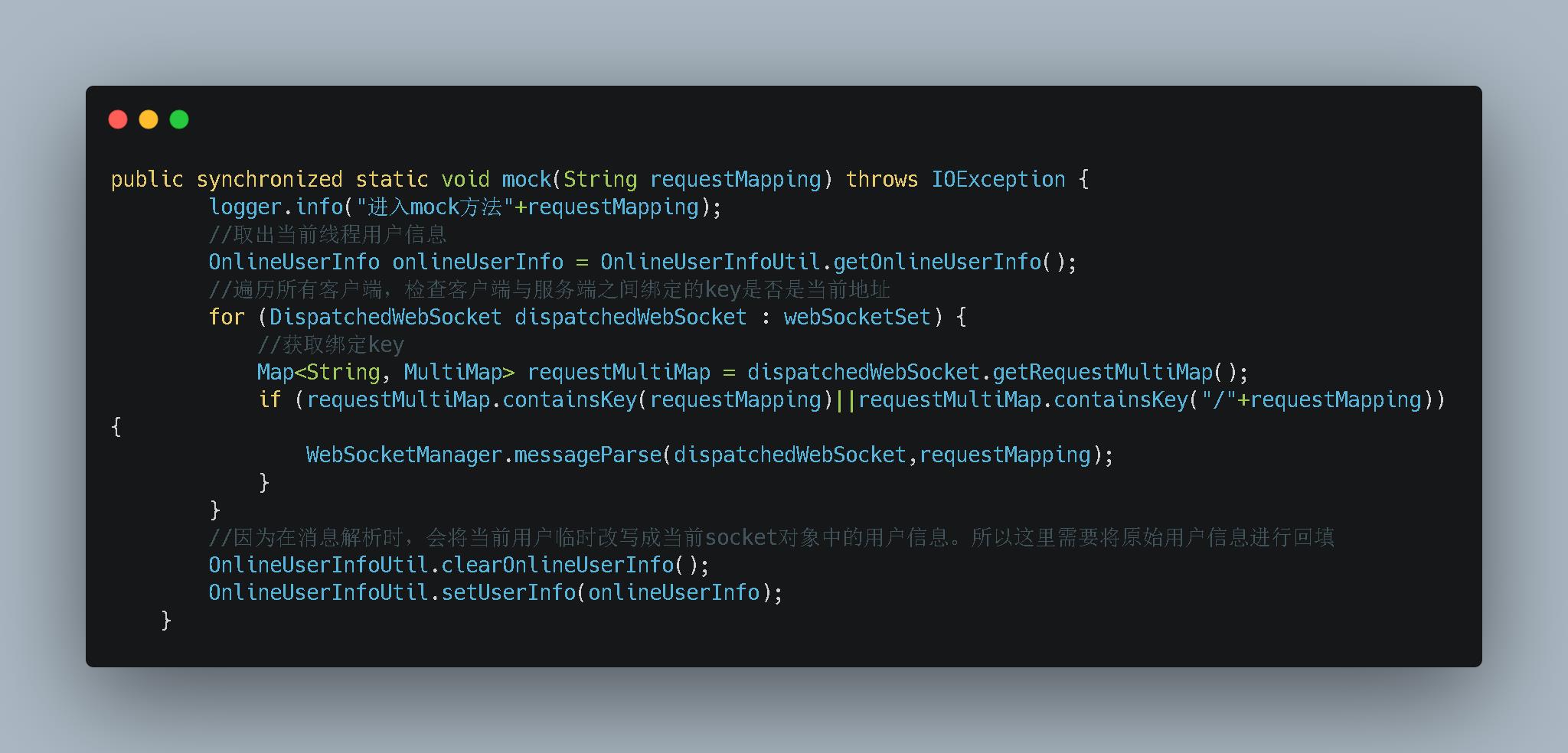
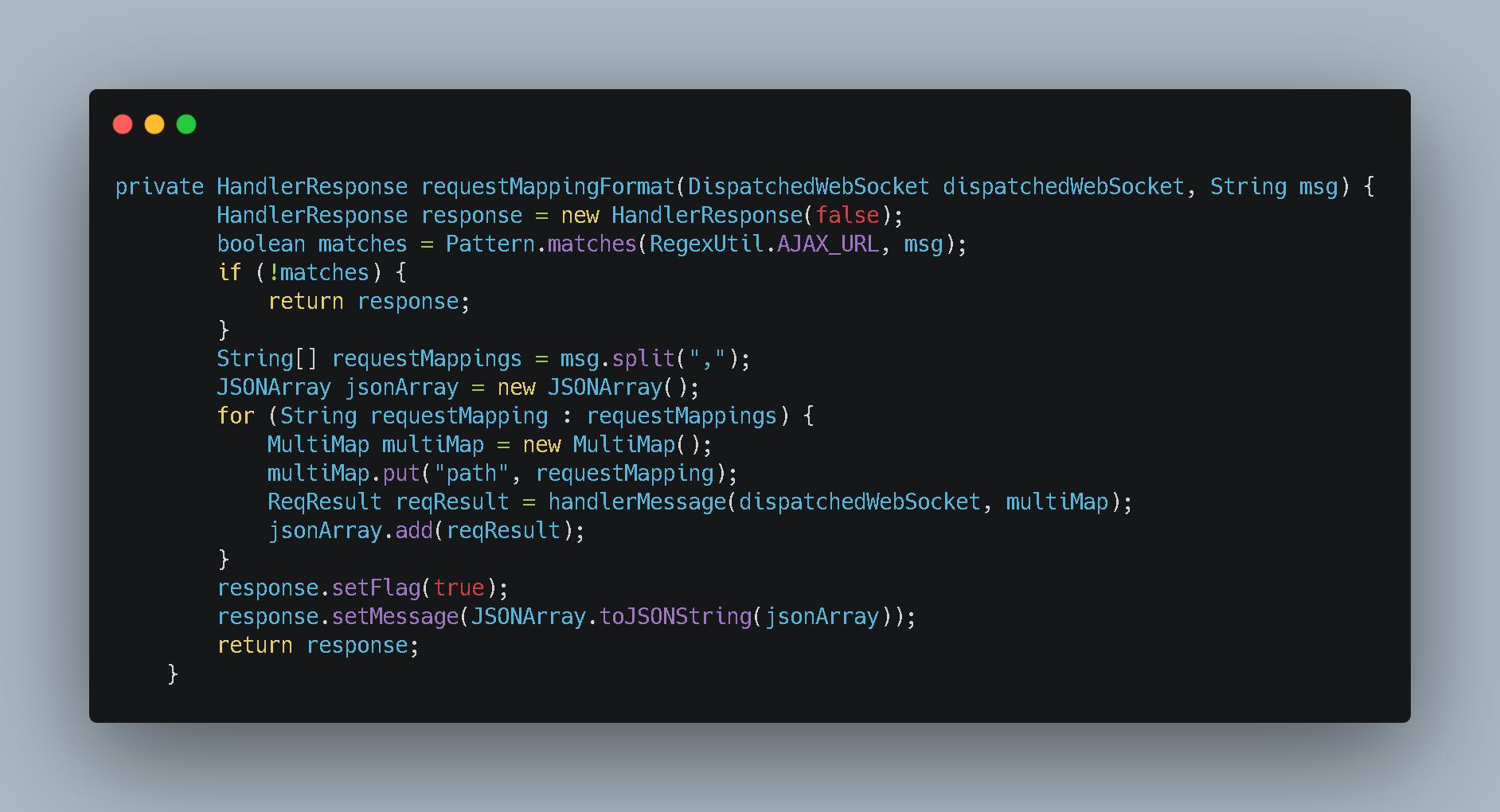
- 上面是我们的发送消息的代码。代码也很简单。先获取所有符合发送条件的客户端 。然后通过客户端内部提供的
sendMessage方法进行推送。 - 但是这个时候的
message是我们的接口信息。在内部会基于客户端保存的方法签名进行反射调用从而获取最新数据。在推送给客户端的 - 在上面的代码中核心的是
WebsocketManager.messageParse。这段是获取消息然后发送。里面获取消息是基于resultful格式解析的
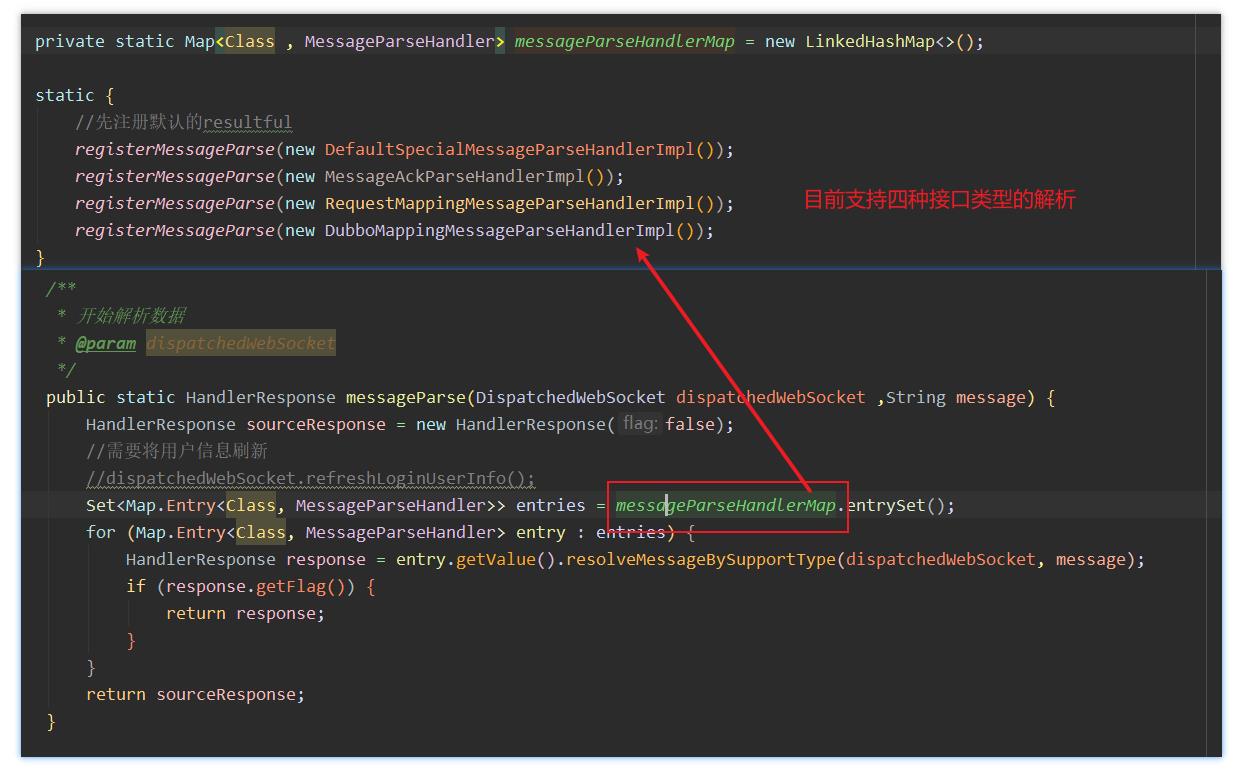
- 这个方法内部我们有内置了我们的四种解析方式。这里我们只需要关心
RequestMappingMessageParseHandlerImpl这个协议。
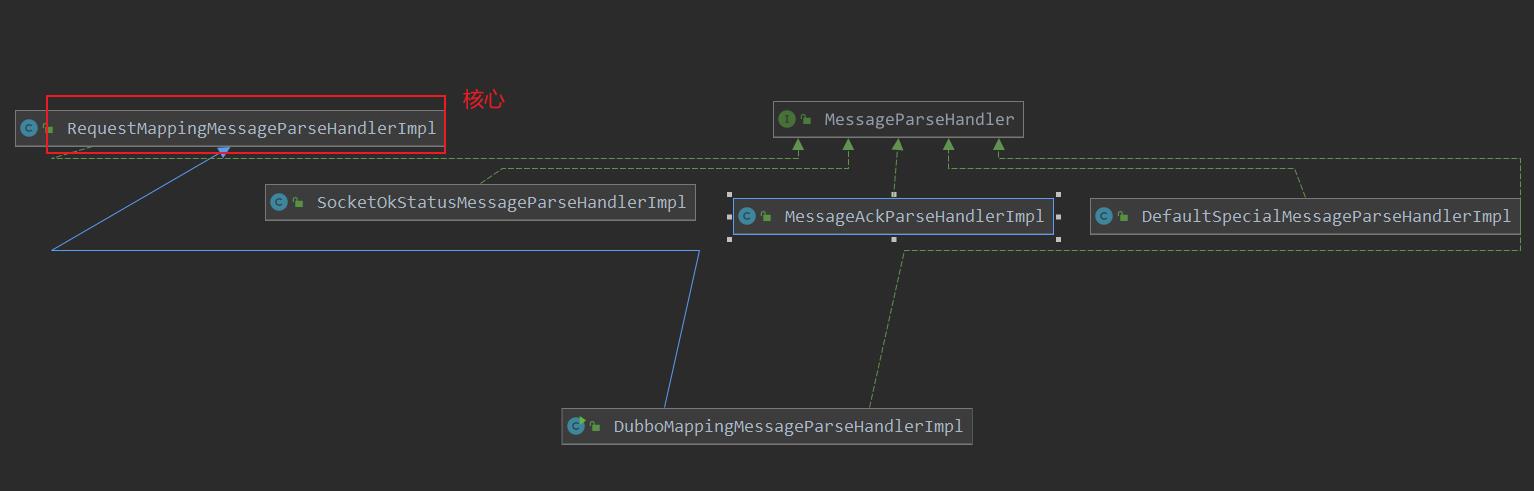
- 关于我们内部的协议这里也不需要太在意。这是我们自己的一个设计。根据上面的图示我们也能看的出来里面
RequestMappingMessageParseHandlerImpl是核心
产生原因
- 上面我们简单的梳理了下代码的逻辑。
- 仔细分析下我们是遍历所有客户端然后在反射调用接口数据进行返回的。实际上在消息推送时我们没必要在每个客户端内部调用数据。我们完全可以先调用数据然后在遍历客户端进行发送。
- 这也是导致CPU过高的问题。我们1W个用户同事在线的可能有5000+ 。 那么我们需要5000次以上的反射着肯定是吃不消的。这也是为什么本文开头说功能正常不代表业务正常。
解决方案
- 这就是量变引起质变。在多客户的情况下我们的设计弊端就暴露出来。这里也是笔者自己给自己挖坑。既然找到问题我们就好解决了。下面我们对代码做了一下改动
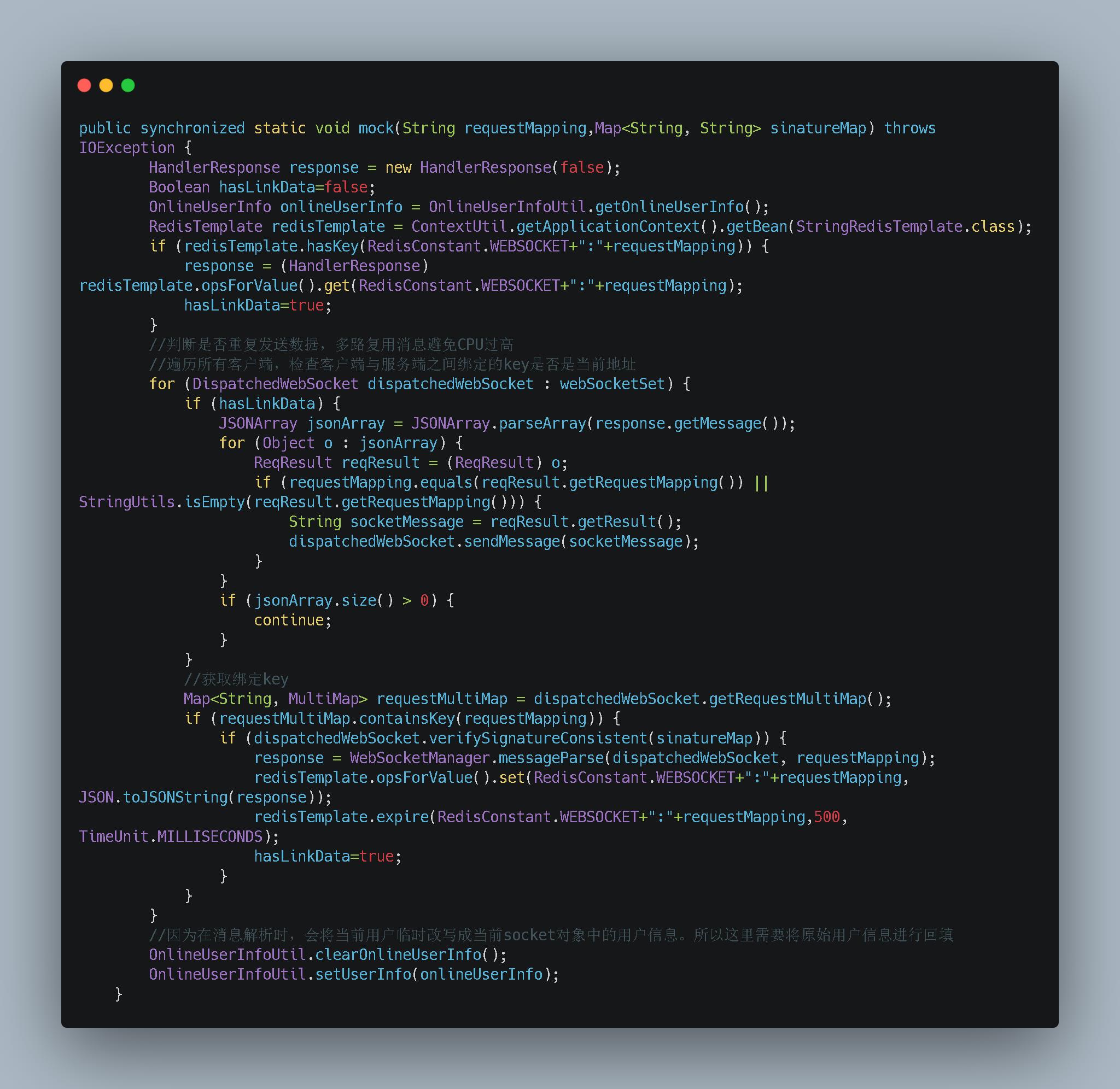
-
我将数据缓存起来。因为在同一批次推送时本来也应该保证数据一致性。而且我们系统对数据实时性也是可以接受一定时间延迟的。我在这里又加上缓存这样就解决了我们循环的问题
-
经过测试本次改动在CPU上大概优化了100倍。
总结
- 功能开发完成仅仅代表功能的实验没有问题
- 单用户和多用户完全是两种不同的用户形态。我们功能设计初期就应该尽量考虑数据量的问题
- 唯一做的好的地方是我通过责任链模式将数据解析隔离出来。否则这样的问题定位将会更加麻烦
以上是关于运维告诉我CPU飙升300%,为什么我的程序上线就奔溃了的主要内容,如果未能解决你的问题,请参考以下文章