MongoDB3.2 - 4.2 新特性解读
Posted 朱培
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MongoDB3.2 - 4.2 新特性解读相关的知识,希望对你有一定的参考价值。
MongoDB 是一个基于分布式文件存储的数据库。由 C++ 语言编写。旨在为 WEB 应用提供可扩展的高性能数据存储解决方案。
MongoDB 是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。
一、副本集
3.2版本
- 引入raft协议选举机制(pv1)、早期协议bully(简单的协调者竞选算法 pv0)
相对于bully协议,raft协议的好处是:消除选举锁,引入term,弱化priority。
早期的bully协议是加了一个全局锁,因为从库投票完之后可能会产生多次投屏的情况,30s的全局锁防止重复投票;raft引入了一个term这样一个选举周期(类似一个自增的这样一个周期的概念),如果从库在这个周期内选不出来主,那么又随机开始下一个周期的投票,term会加1;raft弱化了优先级,主库故障会切换时优先级高的会被优先选为主,raft就弱化了这个权重。raft协议的效率会更高。
- 增加electionTimeoutMillis 复制配置参数,决定主库不可连通的超时时间。通过心跳来检测主从是否正常,如果说从库连不上主库了,不会立即发起选举,而是先等一会,等这个时间超时,超过之后才发发起选举,减少了误选举的次数
3.4版本
2020年1月31日之后不再维护。
-
改进初始化全量数据同步与索引创建顺序及数据拷贝过程中同时拉取oplog(类似于mysql里面的binlog), oplog默认是磁盘容量的5%(最小1G,最大50G)

改进的原因:如果拷贝集合数据的这个过程耗时很长,同时业务的写入非常高,再加上创建索引有需要很长的时间。oplog可能会被覆盖,oplog的这个集合是可以循环的,如果写满了就会被覆盖掉旧的。线上问题:就是当遇到一个大的实例的时候,加从节点可能会一直加不上,因为在拉增量oplog的时候的那个记录点已经被覆盖了。3.4就解决了从库加不进的问题,同时减少了索引创建的过程。如果有10GB的数据,包含64个集合,每个集合包含2个索引字段,文档平均1KB,3.4版本的全量同步性能约有20%的提升,如果数据集很大,并且在同步的过程中有写入,提升的效果会更明显。 -
增加全量数据拷贝过程重试逻辑,减少重做次数。如果网络抖动,就认为这次拷贝中断了,那这对于运维来说很痛苦。所以加入了重试逻辑。
-
初始化同步过程中遇到rename集合会导致同步直接失败重做
-
新增catchUpTimeoutMillis复制配置参数,决定新主获取更新数据的最大时间。作为一个候选者节点的时候,去拉去缺失的数据的时间,如果超过这个时间依然没有拿到最新的数据,那么就进入新的一轮的选举周期
-
增加writeConcernMajorityJournalDefault参数 决定majority写是写内存还是磁盘。配置复制集时,增加 writeConcernMajorityJournalDefault 选项,默认为 true,即当指定 WriteConcern 为 majority 时,数据写到大多数节点并且 journal 成功刷盘后,才向客户端确认成功;如果为 false,数据写到大多数节点的内存,就向客户端确认。
3.6版本
- 废弃早期bully协议(简单的协调者竞选算法 pv0)
- 增加replSetResizeOplog 命令及oplogInitialFindMaxSeconds 超时参数,早期需要重启和主库的切换,非常容易出故障,3.6之后直接可以在线修改。对于一个大的oplog,如果一个流式备份,如果没有这个超时机制就会卡在那边,一般来说是60s的超时设置。
- 修复了3.4版本全量数据同步过程rename集合导致重做的问题,
4.0版本
- 直接删除bully协议(pv0)及master-slave集群结构模式
- 直接删除 使用wt引擎的副本集节点不允许使用 storage.journal.enabled: false。必须开启journal
- 增加rollbackTimeLimitSecs及createRollbackDataFiles参数控制oplog回滚最大时
间差和是否在本地创建回滚文件。从库和主库延迟30分钟,那么就不执行回滚了。 - 通过读snapshot解决从库oplog应用加全局锁导致业务读与应用oplog相互阻塞的问题。
4.2版本
- 从 4.2开始,管理员可以限制主数据库应用其写入的速率,以将延迟保持在可配置的最大值以下。默认情况下,流量控制为enabled。如果未启用FCV(功能兼容版本) 或禁用了read concern majority权限,则启用的流控制无效。
- 日记和内存存储引擎:如果副本集成员使用内存中的存储引擎 ,但副本集已 writeConcernMajorityJournalDefault设置为true,则副本集成员记录启动情况警告。
二、分片集群
3.2版本
config节点废弃镜像模式(SCCC), 引入配置副本集模式(CSRS)引擎必须是wt。在之前的版本中存储metadata元数据信息是通过3个镜像存储的,config节点变化之后要更新配置3个节点。这种镜像模式最大的问题就是当某个节点挂了或需要维护,整个集群都需要停服。在3.2中改为副本集的方式,便于维护。
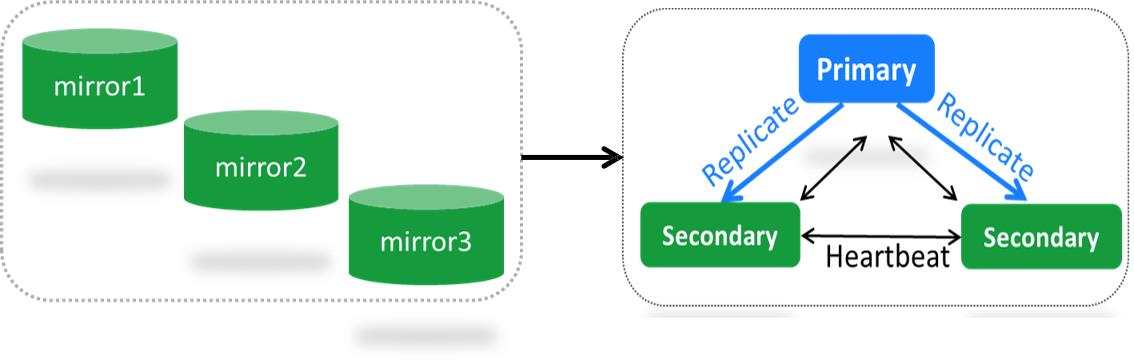
3.4版本
- 分片集群所有组件都能相互感知整个分片集群的存在即配置信息避免错误分片的添加(分片集群必须配置配置 sharding.clusterRole)。之前版本可能引发的线上问题:一个分片属于两个集群,导致数据不一致。
- 不再支持config节点镜像模式(SCCC) ,引入Zones 分片策略以替换Tag模式。能将某些数据分配到指定的一个或多个 shard 上,这个特性将极大的方便 sharding cluster 的跨机房部署
- 对于wiredTiger引擎 secondaryThrottle 默认设置 false ,大大提高chunk迁移速度。之前的版本分片1迁移到分片2,都发生在主库,还需要将数据同步写入到从库,大大降低chunk的速度。3.4版本加快了迁移的速度。
- 数据均衡发起由路由节点转移到config副本集主库节点,增加并行balance机制(N/2)及balancer启动、关闭及状态查看命令。早期的版本,如果部署了多个节点,那么每个节点都会发起balance的任务,首先获得分布式锁的节点才能发起。之前的版本需要从A->B迁移完之后才能迁移C->D,而3.4版本可以并行,A->B和C->D可以同时进行,提高迁移速度。

3.6版本
- 强制分片必须是副本集模式不允许单节点模式
- 增加ShardingTaskExecutorPoolMaxConnecting 控制monos路由节点到分片节 点的连接频率
- 增加orphanCleanupDelaySecs 参数控制chunk迁移后原文档清理最迟时间,
4.0版本
- Chunk 迁移过程中数据fetch与apply都已经实现并发操作性能提升近40%
- 创建删除集合或删除数据库及添加分片等操作开始支持写大多数(majority)
4.2版本
- 可以更新文档的分片键值,除非分片键字段是不可变_id字段。在4.2版本之前,文档的分片键字段值是不可变的。
- 分片群集上可以使用多文档事务
三、读一致性改进
3.2版本
首次引入读相关特性(readConcern),复制版本必须为pv1, 支持local及majority两种策略,其中读majority(仅wt引擎支持)可实现读不回滚。在t3这个时间节点之后可实现不回滚。

3.4版本
增加linearizable(线性一致性)的支持
- 只能用于读primary及读单个文档
- 使用时建议增加maxTimeMS参数
读主库的单个文档的时候,读到的数据一定是在读操作之前写入的数据,这个数据也是写入到大多数节点的,加入这个超时参数,直接给主库发送线性读的情况下,如果从节点挂了,在没有加超时参数的情况下,这个读就可能会一直挂起,就可能引发故障。

3.6版本
增加“available”(可用性)的支持
- 用于分片集合读增加数据容错性但可能读到orphan (孤立)文档
- 读非分片集合的表现和local模式一样
分片集合的读:更宽松的一个隔离级别,甚至可以读到孤立文档,就是chunk迁移之后还留在原来的分片一些文档,理论上对业务来说是不可见的,但是如果你想要看到,那么可以配置这个参数。available用的不多,除非对一致性要求非常低。
4.0版本
- 增加“snapshot”(快照读)模式,以支持多文档事务读
- 读可见性区分是否关联因果一致性( causally consistent session)
快照读的示例:
假设 x:1 在读事务T1开启前已经写入
事务+snapshot读+写大多数+非因果一致性会话= 读已写大多数的数据快照 (x:2)
事务+snapshot读+写大多数+因果一致性会话= 读T1开启前已写majority快照 (x:1)

4.2版本
- MongoDB 增加了可重试读功能,对于一些临时的网络问题,用户无需自己实现重试逻辑,MongoDB 会自动重试处理,保证用户业务的连续性。
四、引擎相关的改进
3.2版本
• WiredTiger 核心特性:
- 压缩比:对于mongodb来说主要还是存储文档,所以大多数都是文档型数据,如果加入压缩特性,那么可以节约很多的空间,2~7倍。
锁粒度:早期的基本上是全局的库就别或表集合级别的粒度, WiredTiger是记录级别的粒度,并发性大大的提高
空洞率:早期的空洞率会很高,更新记录时如果原来分配的空间不够,会迁移到新的空间,空间分配是2n。新版的空洞率20%左右。例如一个400G的数据,导出后再导入,可能就占用只有250G了。
Cache:早期的内存是叫给操作系统来控制的,WiredTiger 通过cacheSize参数来控制
- 自3.0引入WiredTiger引擎后3.2版本在企业版本引入了WT加密配置项
- 3.2版本WiredTiger作为默认引擎且已支持fsyncLock 创建一致性备份
- 增加ephemeralForTest(测试引擎)及inMemory (内存引擎仅用于企业版)
3.4~4.0 版本
4.0开始WiredTiger引擎的副本集及分片集群不允许关闭 journal
4.0开始废弃MMAP V1引擎
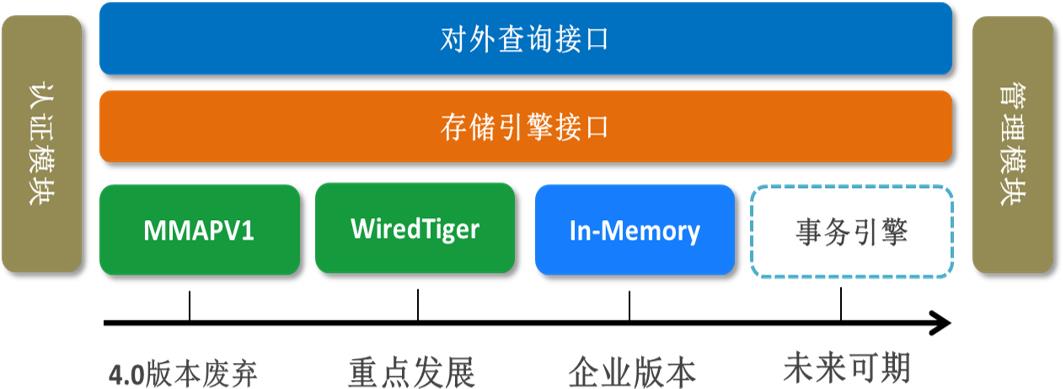
4.2版本
- 4.2删除不推荐使用的MMAPv1存储引擎。
- 4.2开始,副本集和分片群集上支持多文档事务,其中:
主节点使用WiredTiger存储引擎,并且
从节点使用WiredTiger存储引擎或 内存中存储引擎。
五、重要改进
ChangeStreams
3.6版本首次引入集合粒度的”变更流”,早期如果想获取某个集合的变更情况,需要去抓取oplog,而新版本中可以直接用变更流进行抓取。
4.0版本添加库及实例粒度的增强支持
4.0版本真正实现了只捕获“写大多数”
主要特点:
• 可只捕获变更或完整文档、可灵活指定过滤指定操作
• 分片集群中事件完全有序(通过一个全局逻辑锁来实现的)、非mongo shell 下断线重连。
• 只发布”写大多数”的变更 、变更流遵从权限控制系统,
多文档事务
MongoDB 4.0 支持副本集事务,极大的丰富了应用场景;4.0 的事务存在最大修改 16MB、事务执行时间不能过长的限制,在 4.2 支持分布式事务的这些问题都解决了。分布式事务的支持也意味用户修改分片key的内容成为可能,因为修改分片key的内容,可能会导致key要迁移到其他shard,而在4.2之前,无法保证这个迁移动作(目标上新写、源上删掉)的原子性,而借助分布式事务,这个问题也就迎刃而解。MongoDB 采用二阶段提交的方式,实现在多个 Shard 间发生的修改,要么同时发生,要么都不发生,保证事务的 ACID 特性。
- session.startTransaction() // 开启事务
- session.commitTransaction() // 提交事务
- session.abortTransaction() // 回滚事务

事务使用需要注意的问题:
只有副本集集群模式才支持;在MongoDB 4.0中,仅使用WiredTiger存储引擎的副本集支持事务。系统库/集合是不支持多文档事务;
事务部支持catalog操作(例如创建一个集合,删除一个索引),及explain(执行计划)在事务中都是不支持的;
读优先级策略值只支持读主库。
认证安全
权限管理
3.0版本首次具备完整的基于角色的权限管理体系, 后期版本持续增强
鉴权开启
3.4版本引入了transitionToAuth配置,确保集群可在线开通鉴权
白名单
3.6版本为了安全起见bindIp 默认绑定是的127.0.0.1 、 ipv6默认绑定::1
3.6版本自定义用户及角色引入authenticationRestrictions限制客户端及服务端的ip
认证策略
3.6版本开始废弃MONGODB-CR认证策略、 需要注意的是4.0版本彻底删除
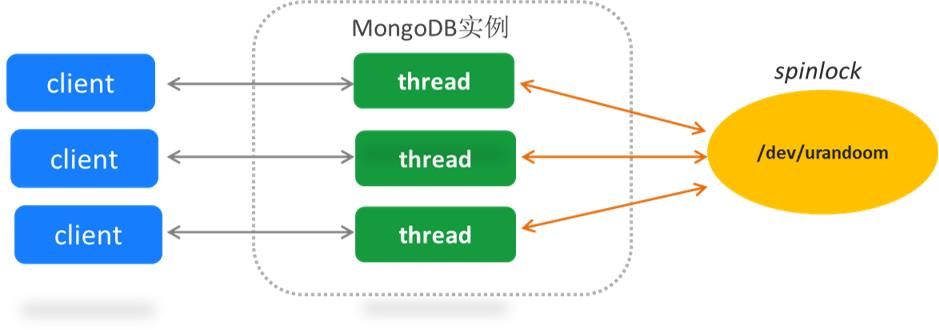
自从3.0开始引入SCRAM-SHA-1策略(3.0-3.4都有性能问题)以来、4.0又新增SCRAM-SHA-256
SCRAM-SHA-1如果在高并发端连接的情况下,如果要获取一个随机的加密盐,如果要保证返回的不同,需要加一个spinlock的锁,所以可能会有性能问题。
优点:
可调迭代数 (默认15000) 客户及服务端随机加盐
比md5更强的hash函数 客户及服务端双向认证
4.2版本 引入「字段级加密」的支持,实现对用户JSON文档的Value 进行自动加密。整个过程在 Driver 层完成,传输、存储到服务端的文档Value都是密文,MongoDB 4.2 Drvier 支持丰富的加密策略,可以针对集合、字段维度开启加密,加密过程对开发者完全透明。
模型校验
3.2开始引入validation功能,因为同一个字段可能存储的数据会用混,可能存的时间可能存的数字。
3.6版本支持$jsonSchema
定义字段校验
db.createCollection( "test",
validator: $or:
[
phone: $type: "long" ,
email: $regex: /@huolala\\.cn$/ ,
status: $in: [ "bad", "good" ]
]
,
validationAction: "error"
)
不符合校验规则的插入:
db.test.insert( phone: 123456,email:"test@mongodb.com", status: "bad" )
符合校验规则的插入:
db.test.insert( phone: NumberLong(123456),email:"test@huolala,cn", status: "good" )
聚合框架
3.2版本首次引入 $ lookup 支持关联查询
3.4增加$grahpLookup支持层次递归查询
3.6版本进一步增强(支持多个关联字段)
4.2增加merge操作符,又称按需式物化视图,能不断的将增量分析结果与原来的结果进行汇总(老的版本只支持out,把当次分析结果写到某个集合)。

其他改进
- 3.4版本开始支持视图(view)
语法:
db.createView(<view>, <source>, <pipeline>, <options>)
用例:
db.createView( 'test_view', // 视图名称
'sourceCollection', // 原集合
[ $project: 'vField': '$name', age: 1 ] // 定义视图字段
)
规定:
索引、只读、 视图上的视图、自然排序、shard集合、关联查询
-
3.6版本引入可重试写(Retryable Writes)
场景:
网络错误或遇到副本集切换
规定:
• 只重试一次解决暂时的网络错误
• 只支持副本集和shard集群
• 要求WiredTiger或in-memory存储引擎,mmapv1 不支持
• 对于4.0版本多文档事务按整个事务进行
• 无可以写primary 则等待serverSelectionTimeoutMS (默认30秒)(主库切换或选举过程中)
用例:
uri = “mongodb://example.com:7007/?retryWrites=true” -
4.0版本引入Free Cloud Monitoring (仅支持单节点及副本集)
db.enableFreeMonitoring() // 开启云监控
“state” : “enabled”,
“message” : “To see your monitoring data, navigate………”,
“url” : “https://cloud.mongodb.com/freemonitoring/…”,
“userReminder” : “”,
“ok” : 1
db.disableFreeMonitoring() // 关闭云监控
db.getFreeMonitoringStatus() // 查看监控状态
3.2版本引入部分索引
• 与稀疏索引包含关系
• 唯一性索引约束范围
3.6版本嵌套字段查询可使用”覆盖索引”
3.6版本支持因果一致性
一个操作逻辑上依赖它之前的操作即认为两操作具备因果关系
因果一致性可为读写提供如下保障: • 读自己的写
• 单调性读 (w1->w2,r1->r2 如果r1 读到w2,那r2必然不会读w1)
• 单调性写(删除之前的插入) • 读然后写(先查询然后更新或插入)
4.2版本 引入 Wildcard Index,可以针对一系列的字段自动建索引,满足丰富的查询需求。而以前的版本中经常会遇到一些场景,某个字段包含很多个属性,很多属性都可能需要用于查询,现在的解决方案时,针对每个属性,必须提前知道它的访问行为,建立必要的索引。
3.6版本listdatabase改进
listDatabases命令添加nameOnly参数执行命令不加锁否则请求库级锁
3.6版本dropDatabase改进
dropDatabase等待drop完所有集合命令传播到大多少副本集成员后执行
4.0版本listCollections 改进
listCollections命令添加nameOnly参数执行命令不加锁否则请求集合级锁
4.0版本killOp改进
killOp杀mongos集群查询操作可直接在mongos路由节点执行
4.0版本 show tables 改进
处于安全考虑show tables 默认不再显示系统表system.*
4.2版本新增的通配符索引,也比较特殊,说白了就是某个字段不确定,某些字段确定,但是可能需要针对不确定的字段做快速搜索匹配,这个和全文索引差别还比较大,应该是为Document级别的数据提供了更多的索引灵活度。
以上是关于MongoDB3.2 - 4.2 新特性解读的主要内容,如果未能解决你的问题,请参考以下文章