人工智能前沿知识
Posted 阿牛大牛中
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了人工智能前沿知识相关的知识,希望对你有一定的参考价值。
本来想着初试完学习一下李沐大神的《动手学深度学习》这本书的,但是时间仓促,完全来不及。只能先自行了解一些知识,之后再深入了解。
这里为面试应答,问了chatgpt一些关于AI前沿的知识:
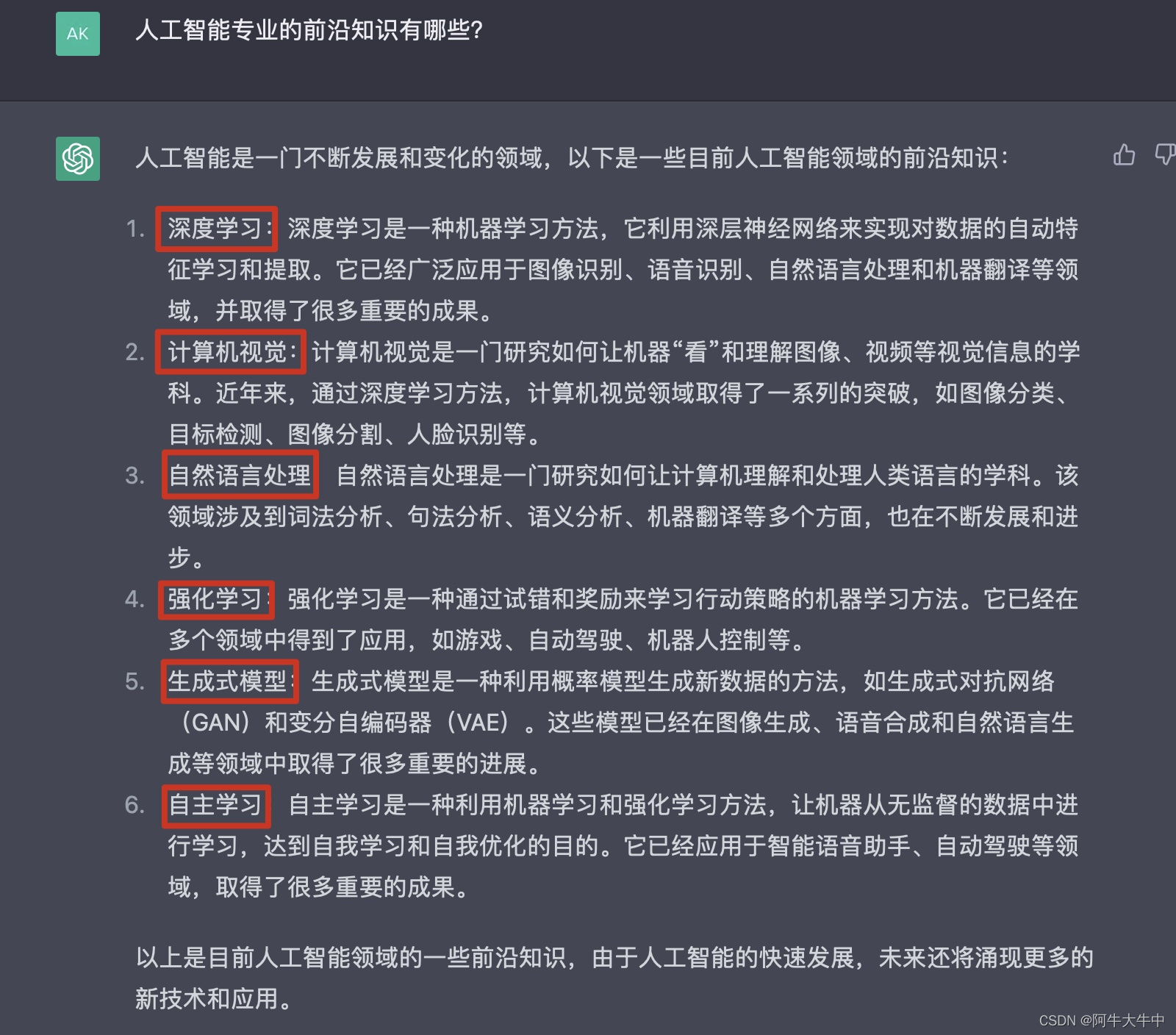
还需要再了解一番:
文章目录
- 1、人工智能、机器学习、深度学习三者关系?
- 2、介绍一下人工智能?
- 3、介绍一下什么是机器学习?
- 4、介绍一下什么是深度学习?
- 5、介绍一下什么是神经网络?
- 6、常见的神经网络模型有哪些?
- 7、自然语言处理是什么?
- 8、介绍一下什么是强化学习?
- 9、介绍一下什么是生成式模型?
- 10、介绍一下什么是自主学习?
- 11、介绍一下什么是计算机视觉?
- 12、介绍一下什么是云计算?
- 13、介绍一下什么是大数据?
- 14、大数据和机器学习的关系?
- 14、介绍一下什么是数据挖掘?
- 15、介绍一下什么是物联网?
- 16、介绍一下什么是区块链?
- 17、说一下你所了解的ChatGPT。
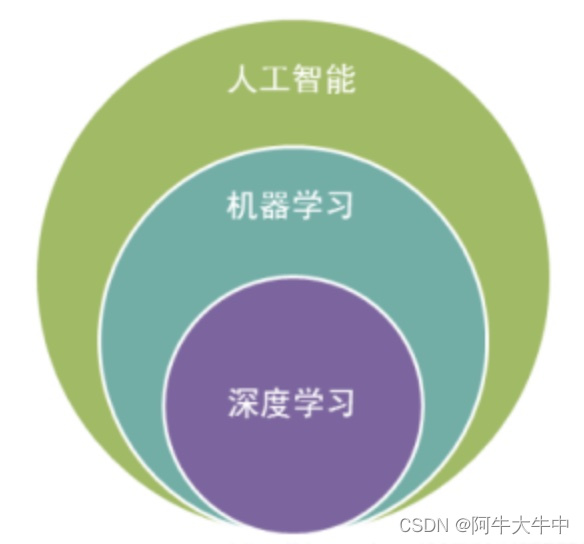
1、人工智能、机器学习、深度学习三者关系?
-
人工智能(Artificial Intelligence,简称AI)是一个广泛的概念,指的是使计算机系统能够表现出类似于人类智能的各种能力,如语言理解、推理、学习和解决问题等。
-
机器学习(Machine Learning,简称ML)是人工智能的一个子领域,它是一种基于数据和统计学方法的计算机算法,可以让计算机系统自动从数据中学习和改进,以便更准确地执行任务。与传统的计算机程序不同,机器学习算法可以自动学习特征并不断优化预测结果。
-
深度学习(Deep Learning,简称DL)则是机器学习的一种特殊形式,它基于神经网络模型,并且可以利用多层非线性变换来对数据进行抽象和表达。相对于传统机器学习算法,深度学习算法在处理复杂数据上表现更加出色,并且可以学习到更高层次的抽象特征。深度学习已经在图像识别、自然语言处理等领域取得了重大的突破和应用。
因此,可以将它们的关系概括为:深度学习是机器学习的一种特殊形式,而机器学习是人工智能领域的一个子领域,三者之间存在着较为密切的联系和关联。
2、介绍一下人工智能?
人工智能(Artificial Intelligence, AI)是指通过模拟、延伸和扩展人类智能的理论、方法、技术和应用系统,使机器能够感知环境、理解自然语言、分析数据、学习知识、做出决策和行动,从而实现智能化的机器系统。通常包括知识表示、推理与规划、机器学习、计算机视觉、自然语言处理、智能控制、仿真等多个方向。
人工智能技术的应用十分广泛,包括但不限于:语音识别、图像识别、自然语言处理、智能机器人、智能客服、自动驾驶、智能家居、医疗辅助诊断、金融风控、智能推荐等。随着技术的不断进步和应用的不断深入,人工智能正成为推动经济发展和社会进步的重要力量之一。
3、介绍一下什么是机器学习?
机器学习是一种人工智能领域的技术,其主要目标是使计算机系统能够从数据中学习和自动改进。机器学习可以让计算机通过统计学和算法来分析数据、识别模式并进行预测。其核心思想是让机器能够从数据中自主学习,而不是通过人为规则或明确编程来指定其行为。
- 机器学习可以分为监督学习、无监督学习和强化学习三种类型。
- 在监督学习中,机器学习算法可以使用带标签的训练数据来学习预测模型,这些模型可以用于预测未来的结果。
- 在无监督学习中,机器学习算法尝试找到数据中的模式和结构,而无需任何标签。
- 在强化学习中,机器学习算法学习如何在一个动态环境中采取最优的行动来最大化其获得的回报。
机器学习应用广泛,可以用于图像和语音识别、自然语言处理、推荐系统、金融风险评估、医疗诊断和预测等领域。随着数据的不断增长和计算能力的提高,机器学习技术已成为许多行业的核心竞争力。
4、介绍一下什么是深度学习?
深度学习是一种机器学习技术,通过构建多层神经网络来学习和表示数据。这些神经网络中的每一层都包含许多节点,这些节点将输入数据进行变换,并将输出传递到下一层以进行进一步的处理。通过反向传播算法,网络可以自动学习数据之间的复杂关系,并生成可以用于分类、回归、聚类等任务的预测模型。
深度学习的一个重要特点是它可以自己学习特征,而不需要手动设计特征提取器。与传统的机器学习技术相比,深度学习可以处理更复杂的数据结构和更高维度的数据,并且可以在处理自然语言处理、图像和视频、语音识别、推荐系统等领域的任务方面取得出色的成果。
深度学习在图像识别、自然语言处理、语音识别等方面已经取得了显著的成功,如 ImageNet 图像分类竞赛、AlphaGo 在围棋中的胜利等,正在被越来越多的行业广泛应用。
5、介绍一下什么是神经网络?
神经网络是一种用于机器学习和深度学习的算法模型,其结构和功能与人类的神经系统类似。它由一系列相互连接的节点(称为神经元)和边组成,可以自主地学习从输入数据到输出数据之间的映射关系。
神经网络的每个神经元都有一个输入、一个输出和一组可调参数(称为权重),它们接受来自其他神经元的输入,对其进行加权处理,并传递到下一个神经元。神经网络的学习过程就是通过调整权重来优化模型的性能,使其可以更好地对输入数据进行分类、预测或者其他任务。
- 神经网络模型通常可以分为三层:输入层、隐藏层和输出层。
- 输入层接受原始的数据输入
- 隐藏层通过多次非线性变换来抽取数据的特征
- 输出层则根据特征的表示来进行预测或分类
近年来,随着计算能力和数据量的增加,深度神经网络(Deep Neural Networks)成为了一种强有力的机器学习工具。深度神经网络通常由多个隐藏层组成,可以学习到更复杂的特征表示,从而在图像、语音、自然语言处理等领域中取得了显著的成果。
6、常见的神经网络模型有哪些?
下面是一些常见的神经网络模型:
- 前馈神经网络(Feedforward Neural Network,简称FNN):也称为多层感知机(Multilayer Perceptron,简称MLP),是最常见的神经网络模型之一。它由输入层、若干个隐藏层和输出层组成,每个神经元与下一层的所有神经元相连,每个神经元都有一组可调权重和偏置。
- 卷积神经网络(Convolutional Neural Network,简称CNN):是一种广泛应用于图像和视觉处理的神经网络模型。它通过卷积和池化操作来提取图像的特征,并将其送到全连接层进行分类或预测。卷积神经网络具有平移不变性和对图像变换的鲁棒性。
- 循环神经网络(Recurrent Neural Network,简称RNN):是一种能够处理序列数据的神经网络模型。它通过循环结构和共享权重来处理序列数据中的时序关系,并利用上一时刻的输出作为下一时刻的输入。循环神经网络可以应用于自然语言处理、语音识别、时序预测等领域。
- 长短时记忆网络(Long Short-Term Memory,简称LSTM):是一种特殊的循环神经网络,通过引入记忆单元和门结构来有效地捕捉长时依赖关系。长短时记忆网络常用于序列到序列(Sequence-to-Sequence)的任务,如机器翻译和语音合成。
- 自编码器(Autoencoder,简称AE):是一种无监督学习的神经网络模型,它通过将输入数据编码为低维度的表示,然后解码回原始数据,来学习数据的内在结构。自编码器可以应用于数据降维、特征提取、数据压缩等任务。
以上仅是常见的一些神经网络模型,随着研究的不断深入,也会不断涌现出新的模型和变种。
7、自然语言处理是什么?
自然语言处理(Natural Language Processing,简称NLP)是一门研究人类语言与计算机之间交互的技术,旨在使计算机能够理解、处理、生成自然语言。
自然语言是人类日常交流中使用的语言,它具有高度的复杂性和多义性,因此使得计算机对自然语言进行理解和处理成为了一个具有挑战性的问题。自然语言处理的任务包括文本分类、情感分析、命名实体识别、语言翻译、问答系统、机器翻译等。
自然语言处理涉及到多个学科领域,包括语言学、计算机科学、数学、统计学等,需要应用机器学习、深度学习、统计学、语言模型等技术手段,以及各种自然语言数据集和语料库。
近年来,随着计算能力和数据量的增加,自然语言处理得到了迅速发展。自然语言处理的技术应用已经渗透到我们的日常生活中,如语音助手、机器翻译、智能客服等。
8、介绍一下什么是强化学习?
强化学习(Reinforcement Learning)是一种机器学习的分支,它涉及智能体(Agent)在与环境交互中学习如何做出最优决策的问题。在强化学习中,智能体会采取一系列的行动,并通过环境的反馈来学习如何最大化一个长期的奖励。
强化学习的核心思想是**让智能体通过不断地尝试和错误,从而学习到最优的决策策略。**这个学习过程涉及到一个环境、一个智能体和一系列的行动。智能体在环境中接收观察信息,并根据这些信息做出决策。然后,它会得到一个奖励信号,这个奖励信号反映了它的行动的好坏。强化学习的目标是找到一个最优的策略,使智能体可以最大化长期的奖励。
强化学习在许多领域都有应用,包括自动驾驶、机器人控制、游戏智能体、电力管理、金融投资等。强化学习也是实现人工智能的重要途径之一,它能够帮助机器学习在复杂的环境中做出决策,从而实现自主的智能行为。
9、介绍一下什么是生成式模型?
生成式模型(Generative Model)是一类机器学习模型,它可以从数据中学习到数据的分布模型,并使用这个模型来生成新的数据。生成式模型可以用于生成各种类型的数据,包括文本、图像、音频等。
生成式模型通常使用概率模型来描述数据的分布。这些模型可以使用各种统计方法,如朴素贝叶斯、高斯混合模型、隐马尔可夫模型等。这些模型通常使用训练数据来估计模型的参数,然后使用这些参数来生成新的数据。
生成式模型可以被应用于许多领域,包括图像生成、自然语言处理、语音合成等。在图像生成领域,生成式对抗网络(GAN)是一种非常流行的生成式模型。GAN使用两个神经网络,一个生成器和一个鉴别器,来学习图像的分布,并生成逼真的图像。在自然语言处理领域,循环神经网络(RNN)和变分自编码器(VAE)也是流行的生成式模型。
总之,生成式模型是一种强大的机器学习技术,它可以用来生成各种类型的数据,并被广泛应用于多个领域。
10、介绍一下什么是自主学习?
自主学习(Self-Supervised Learning)是一种机器学习方法,它使用无需人工标注的数据来训练模型。在自主学习中,模型通过自己对数据进行探索和理解,从而学习到数据中的特征和模式。自主学习可以被看作是无监督学习的一种扩展,因为它不需要人为地提供标签或注释。
自主学习的目标是让模型学习数据的内在结构,并在不同的任务中使用这些学习到的特征。例如,在计算机视觉领域,自主学习可以让模型从大量的未标注图像中学习视觉特征,然后在图像分类、目标检测等任务中使用这些特征。
自主学习使用的技术包括自编码器、生成式对抗网络(GAN)、对比学习等。这些技术通常需要大量的数据来进行训练,但是它们可以在没有标注的情况下自己发现数据的模式和特征,从而提高模型的表现。
总之,自主学习是一种无监督学习的扩展,它可以让模型在没有人工标注的数据上进行学习,并从中发现数据的特征和模式。自主学习是机器学习领域的重要研究方向之一,它可以帮助我们更好地利用未标注数据来提高模型的性能。
11、介绍一下什么是计算机视觉?
计算机视觉(Computer Vision)是指让计算机像人一样“看”并理解图像和视频的能力。计算机视觉是人工智能和机器学习等领域的一个重要分支,旨在通过算法和技术使计算机能够感知、理解和解释图像和视频,并从中提取有用的信息。
计算机视觉技术**的核心是图像处理、模式识别和机器学习。**常见的计算机视觉任务包括图像分类、目标检测、图像分割、姿态估计、人脸识别等。在实际应用中,计算机视觉可以被应用到自动驾驶、安防监控、医疗影像分析、工业质检、智能家居、游戏开发等领域。
随着深度学习的发展,计算机视觉技术也得到了极大的发展。通过使用深度神经网络等深度学习技术,计算机视觉可以在许多任务上取得超越人类的表现,例如图像分类和目标检测等。随着计算机视觉技术的不断发展和进步,它将会在各个领域发挥越来越大的作用。
12、介绍一下什么是云计算?
云计算(Cloud Computing)是一种基于互联网的计算方式,它通过将计算、存储、网络等资源提供给用户使用,来实现按需获取、弹性伸缩、共享利用的目的。
云计算将计算资源集中在云平台上,用户通过互联网连接到云平台,可以按照自己的需求使用计算资源,无需自己购买、配置和维护硬件设备。云计算的优势包括:
- 可以根据需要动态分配计算资源,提高资源的利用率和可扩展性,降低了成本和风险。
- 用户可以通过互联网随时随地访问计算资源,方便快捷,减少了地理位置和时间限制。
- 云计算平台通常具有高可用性、高安全性、高性能、高可靠性等特点,可以保证计算资源的稳定和安全。
云计算包括三种服务模式:
- 基础设施即服务(Infrastructure as a Service,IaaS):提供基础的计算、存储、网络等基础设施,用户可以根据自己的需求选择配置,如亚马逊的AWS、Microsoft的Azure等。
- 平台即服务(Platform as a Service,PaaS):除了基础设施,还提供应用程序开发、测试、运行和管理的平台环境,如谷歌的Google App Engine、微软的Windows Azure等。
- 软件即服务(Software as a Service,SaaS):提供应用程序的使用服务,用户可以直接使用已经开发好的应用程序,如谷歌的Gmail、微软的Office 365等。
云计算已经广泛应用于各行各业,包括企业管理、科学研究、教育培训、医疗保健等领域。
13、介绍一下什么是大数据?
大数据(Big Data)是指数据规模巨大、类型繁多、生成速度快,难以用传统的数据管理和处理工具进行处理和分析的数据集合。
随着互联网和物联网的发展,各种信息和数据以指数级增长的速度产生,这些数据包括文本、图片、视频、音频等各种形式的数据,而这些数据的特点是数量巨大、来源广泛、结构复杂、价值多样。对这些数据进行收集、存储、管理、处理和分析,成为了一个巨大的挑战,同时也蕴含了无限的商业价值和科学价值。
大数据的处理需要应用到各种技术,包括数据挖掘、机器学习、自然语言处理、图像识别、分布式存储、高速网络传输等,同时也需要各种硬件设备和基础设施的支持。大数据的应用场景包括智能交通、智能制造、智能医疗、金融风控、电子商务、社交媒体等领域。
为了更好地处理大数据,人们开发了各种工具和技术,如Apache Hadoop、Apache Spark、NoSQL数据库、云计算等,这些工具和技术大大提高了大数据的处理效率和质量,同时也推动了大数据的应用和发展。
14、大数据和机器学习的关系?
大数据和机器学习是密不可分的。**机器学习需要大量的数据来进行训练,而大数据技术可以帮助机器学习算法有效地处理和分析海量数据。**因此,大数据和机器学习常常被一起提及。
机器学习算法需要大量的数据来训练模型,而大数据技术可以帮助机器学习算法从大规模数据中提取有用的信息。例如,我们可以使用大数据技术来收集和存储用户的交易数据、浏览历史、社交媒体活动等信息,并使用机器学习算法来分析这些数据,以提供个性化的推荐服务和广告。
另一方面,机器学习算法也可以帮助我们更好地处理和分析大数据。例如,我们可以使用机器学习算法来预测客户的购买行为、分析市场趋势、检测网络攻击等。机器学习算法可以从大规模数据中学习模式,并自动调整模型以适应新的数据。
因此,大数据和机器学习是互相促进的关系,它们共同推动了数据驱动的应用和业务的发展。随着大数据和机器学习技术的不断发展,它们将继续为各行各业带来更多的价值。
14、介绍一下什么是数据挖掘?
数据挖掘(Data Mining)是从大量数据中提取隐含的、先前未知的、有用的信息和知识的过程。数据挖掘结合了机器学习、统计学、人工智能、数据库等领域的理论和方法,可以自动发现数据中的模式、规律和趋势,从而为决策提供支持。
- 数据挖掘的过程包括数据预处理、特征提取、模型选择、模型训练、模型评估和应用等步骤。
- 数据预处理包括数据清洗、数据集成、数据变换等过程,旨在消除数据中的噪声、冗余、缺失等问题;
- 特征提取则是从原始数据中提取出有意义的、能够区分不同样本的特征;
- 模型选择包括选择合适的模型算法、参数等;
- 模型训练则是使用已知数据来训练模型;模型评估是评价模型的性能和效果;
- 应用是将训练好的模型应用到实际的数据中,进行预测和分类等任务。
数据挖掘的应用范围广泛,包括金融风险评估、广告推荐、医疗诊断、客户关系管理、欺诈检测、市场营销等领域。数据挖掘已经成为数据分析的重要手段之一,可以帮助企业和机构从数据中获得更多的价值和信息,提高决策效率和准确性。
15、介绍一下什么是物联网?
物联网(Internet of Things,IoT)是指一种通过互联网连接、交换数据的智能化设备和系统的网络。物联网使得各种物理设备、传感器、车辆、家居等都可以连接到互联网,并通过互联网互相通信和交换数据,从而实现自动化、智能化的控制和管理。
物联网技术包括传感器、通信技术、云计算、人工智能等多种技术,它们共同构成了物联网的基础。通过物联网,我们可以远程监控和控制各种设备,例如家居设备、智能城市设施、智能医疗设备等。同时,物联网还可以为各种行业提供大量的实时数据,这些数据可以被用于数据分析和人工智能应用,帮助我们更好地理解和控制各种设备和系统。
物联网在智能家居、智能交通、智能制造、智慧城市等领域有着广泛的应用。随着技术的发展和成本的降低,物联网正在成为各行各业数字化转型和智能化升级的重要驱动力。
16、介绍一下什么是区块链?
区块链(Blockchain)是一种去中心化的分布式数据库技术,它通过加密技术、共识算法和智能合约等多种技术手段来保证数据的安全性和可信度。区块链技术最初是为了支持比特币等数字货币的交易而发明的,但随着技术的不断发展,它已经逐渐被应用于多个领域,如金融、物流、医疗等。
区块链的特点是去中心化、公开透明、数据不可篡改。它通过将数据存储在多个节点上,并使用加密技术和共识算法来保证数据的安全性和完整性。每个区块链节点都有完整的数据副本,所有节点之间可以实现数据同步和共享。区块链还可以使用智能合约技术来实现自动化的合约执行,进一步提高数据的可信度和效率。
区块链技术具有很大的应用前景,可以应用于数字货币、金融、供应链管理、物联网、医疗、版权保护等多个领域。区块链技术的发展也在推动着数字经济的发展和普及,未来区块链技术将继续发挥重要作用。
17、说一下你所了解的ChatGPT。
ChatGPT是一个由OpenAI开发的大型语言模型,它是目前最先进的自然语言处理技术之一。ChatGPT使用深度学习技术来学习自然语言处理任务,并能够理解人类语言的含义、语法和语境,能够回答问题、翻译语言、产生文本等任务。
ChatGPT使用的技术是基于深度神经网络的,它通过大规模的训练数据和复杂的网络结构来学习语言模式和规律。它可以对自然语言进行多种任务的处理,如文本生成、语言翻译、对话生成等,这些功能可以在聊天机器人、智能客服、搜索引擎、自动文本摘要、自动化写作等多个领域得到应用。
ChatGPT的发展代表了自然语言处理技术的最新进展,也为人们提供了更加智能、高效的自然语言处理服务。
科技前沿丨面向知识图谱的自适应中文分词技术
来源:《中国人工智能学会通讯》2017年第4期
科技前沿
CAAI 2017年 第7卷 第4期 李 思,徐蔚然,高 升
面向知识图谱的自适应中文分词技术
引言
知识图谱用于描述真实世界中存在的各种实体和概念,知识图谱技术提供了一种从海量文本和图像中抽取结构化知识的手段[1]。知识图谱的构建可分为信息抽取、知识融合和知识计算三部分,其中信息抽取是知识图谱构建的基础,主要面向各种非结构化数据、半结构化数据和自由文本数据。这里,自由文本数据作为一种非结构化数据,是构建知识图谱的主要数据来源。因此,从中文自由文本中获取知识需要利用自然语言处理技术进行信息抽取,诸如实体识别、关系抽取等。在实体识别过程中,中文分词系统的性能对实体识别的准确率起着至关重要的作用。中文实体识别,首先要通过分词系统进行词语识别;准确的中文分词可给出明确的实体边界,错误的中文分词对实体识别带来不可逆转的影响。
知识图谱的构建是面向领域的构建,知识图谱中代表性实体也均带有领域特征。通用中文分词系统在知识图谱构建中,由于缺乏领域先验知识,分词系统的性能会骤然下降。为了得到较好的分词结果,面向知识图谱的中文分词系统需要具有较强的领域自适性。自适应的中文分词系统可以对不同领域的非结构化数据依据数据自身的分布情况进行高精度切分,为特定领域的知识图谱的构建提供坚实的基础。本文将围绕自适应中文分词系统进行相关工作的介绍。
中文分词任务是众多中文自然语言处理任务的基石。对于知识图谱构建来说,高精度的词语切分有助于命名实体或概念的识别。随着自然语言处理技术的不断发展,人们已不局限于新闻等标准语料的分析与挖掘,医疗、金融、生物、科技等专业领域的数据也开始采用自然语言处理技术进行文本自动处理。但由于大多数专业领域缺乏相应的分词标注数据,且不同领域的文本用词方法及行文表达方式不同,采用通用分词工具进行专业领域文本标注时,分词性能较差。因此,建立具有良好领域适应性的中文分词系统是知识图谱构建技术的主要研究问题之一。这里,具有良好领域适应性是指,当需要进行标注的文本类型与分词系统的训练语料不同时,分词系统仍然保持良好的分词效果。本文所指的文本类型不同,包括文本所涉及的话题领域不同、文本的行文表达方式不同等。
分词系统现存挑战
从语言学角度,词是最小的能够独立运用的语言单位。计算机对文本的理解过程同样也以词为最小的语义单位。中文自然语言文本中,并不存在空格等显式标志指示词的边界。因此,在计算机进行自然语言理解的基础性工作就是对文本进行自动分词的处理,即计算机自动在汉语文本中在词与词之间添加边界标记。例如,“三峡工程引进第一笔外资。”经过计算机自动分词后,句子中词与词之间被添加了边界标记并显示为“三峡工程 引进 第一 笔 外资 。”
中文分词系统性能主要受两类关键问题的影响 [2]。一是歧义切分,这主要是因为字不能作为独立的语言单位,字的多义使得词语在切分过程中需要依据上下文信息给出适当的切分方案。例如,“门把手坏了。”和“门把手夹坏了。”,第一句中“把手”是词,第二句中“把”和“手”单独成词。二是未登录词,该类词并未在分词系统的训练语料和所使用的词表中出现过。未登录词主要由专有名词和新产生的中文词构成。专有名词主要涉及人名、地名、组织机构名、专业术语、商品名等。新产生的中文词主要来自于网络新词,例如“喜大普奔”等。在建立面向专业领域的分词系统过程中,未登录词对系统性能的影响极为明显。
中文分词常用方法及相关工作
现有常用的中文分词语料库主要有Chinese TreeBank[3]、 Sinica Balanced Corpus [4]、北京大学人民日报语料库 [5] 和 LIVAC[6]。国 际 中 文 自 动 分 词 评 测( 简 称 SIGHAN Bakeoff)1 对中文分词工作的发展产生了巨大的推动作用。该评测针对特定任务,提供包含训练语料、测试语料和标准答案在内的分词数据集。近年来,中文分词工作不再局限于标准的新闻语料,针对特定领域的中文分词语料逐渐丰富,诸如小说语料 [7]、中文专利语料 [8]、微博语料 [9]。
当前大部分分词工作将分词任务转化为基于字的序列标注任务,即通过字在词语中所占位置进行标注,例如,B、I、E、S 分别表示字为词组中的首字、中间字、尾字、单字词;本文所举例句可被标注为“三 _B 峡 _E 工 _B 程 _E 引 _B 进 _E 第 _B 一 _E 笔 _S 外 _B 资 _E 。_S”。大部分中文分词工作主要是针对新闻语料。常规分词标注系统常采用如下分类器:最大熵马尔科夫模型 [10]、条件随机场 [11]、结构化感知器 [12] 等。
随着深度学习算法的广泛应用,很多中文分词研究工作也引入了深度学习算法,带来了一定的效果提升。Cai 等人 [13] 并没有采用序列标注的分词方式,而是直接评估对句子的不同切分的似然度,搜索句子的不同切分得到一个似然度得分最高的切分作为分词结果。Zhang 等人 [14] 将原本使用离散特征的基于词的模型改进为神经网络模型,用字向量和词向量替代原有的离散字和词的特征,用神经网络代替线性模型;并对离散特征的模型和神经网络模型进行了组合,得到了一个组合模型。Xu 等人 [15] 提出了使用双向长短期记忆神经网络 (Long Short\u0002Term Memory,LSTM) 得到各个字符周围的局部特征,再使用门控递归神经网络 (Gated Recursive Neural Network,GRNN) 结合长距离依赖性 (long range dependencies)。
目前,中文分词系统已经在新闻文本领域获得了很高的正确率,一些分词系统的 F1值已经超过 98%[16]。越来越多的研究注意力开始转向其他缺乏标注语料的文本领域。标注语料的缺乏,使得这些新的领域的分词问题具有更大的挑战性。已有的一些研究工作开始关注文学文本,诸如网络小说 [7];还有一些针对微博这类非正式语言的文本分词研究工作 [9]。虽然文学文本工作和微博文本工作都存在各自领域问题带来的挑战,但这些文本中所使用的词汇及语言表述方式仍属于日常生活用语范围,一般情况下对于一个母语是中文的人来说,不需要进行任何的专业培训即可以很好地理解文本。
科技文本诸如专利文本与上述文本有很大的不同。专利文本中包含了大量的科技用语和专业词汇,这使得即使使用母语的一般读者在阅读理解专利文本的时候也会感到很困难;通常需要经过一定的专业培训,读者才可能较清晰地理解文本所表达的意思。从文本自动分词角度来讲,专利文本中常用的科技用语和专业词汇很难从拥有大量标注数据结果的日常用语类文本中找到。这类词汇通常被认定为“未登录词”。中文分词系统一个永恒的研究难点就是如何能够有效切分出这些“未登录词”。美国情报高级研究计划 署 (Intelligence Advanced Research Projects Activity,IARPA) 下属科研项目 FUSE2 (Foresight and Understanding from Scientific Exposition)即通过对大量专利等科技文献进行分析研究,预测新兴技术的潜在方向和发展趋势。该项目中包括了对中文专利文本的分析,并建立了针对中文专利文本的分词和词性标注系统作为后续分析工作的基础。到目前为止,只有为数不多的针对中文专利文本的分词研究工作 [17]。目前常用的分词系统在专利分词任务上表现不佳。
领域自适应常用方法及相关工作
领域自适应方法,可有效解决缺乏领域内标注语料而产生的标注系统性能低下的问题。跨领域标注中,训练集数据和测试集数据并不是从同一个分布中抽样得到的。领域自适应算法描述了如何处理不同来源的训练集数据和测试集数据,导致的标注系统性能下降的问题。领域自适应的目标是让一个分类器在训练集上训练,同时能够在测试集上有较好的表现。由于部分文本专业性较强,人工标注难度大,在这种情况下,采用领域自适应系统是一个不错的选择。一般的,训练集数据的分布称为始源域,把测试集数据的分布称为目标域。
领域自适应方法可分为全监督领域自适应和半监督领域自适应 [18]。这两种具体的领域自适应方法的主要区别在于是否能够得到目标领域的标注数据。全监督领域自适应算法中,包含大量始源域的标注数据和少量目标领域的标注数据;而半监督领域自适应算法中,仅能得到始源域的标注数据,但目标域没有任何已人工标注的信息。显而易见,一般情况下全监督领域自适应的效果会高于半监督领域自适应。实际的应用中,在初始研究阶段,只能拿到大量未标注的目标领域的数据,可选用半监督领域自适应方法;待可获得小部分人工标注后,可采用全监督领域自适应方法提升系统性能。领域自适应的目标是,当数据领域发生变化时,系统仅需做出较少的调整,即可在新领域数据中得到较好的序列标注结果。
在全监督领域自适应方法中,Daumé III[18] 放大了始源域和目标域数据的特征空间,然后使用合并的特征空间训练交叉域模型。全监督方法的弊端在于仍需要花费大量的人力进行目标领域数据的标注。Kim等人[19]借鉴了文献 [18] 的思想,实现了基于神经网络的领域自适应方法。Zhang 等人 [20] 设计了一种基于门控机制的自适应神经网络可进行跨领域学习。通常情况下,在已标注数据中,始源域数据量远超目标域数据量,如果将始源域数据和目标域数据直接简单合并在一起作为训练语料,很容易将目标域中特有信息掩盖。为了有效融合已标注目标域和始源域数据中的有效信息,基于门控循环单元(Gated Recurrent Unit,GRU)的领域自适应神经网络模型,将始源域信息有序添加至目标域输入中。GRU由更新门和控制门组成,表述如下:
其中,ut 为更新门,rt 为控制门, t 为候选激活值,ht 为输出向量;⊙为矩阵元素点乘;Wu、Uu、Wr 、Ur 、W、U 和 bu、br、b 是权重参数矩阵和偏置顶;σ 和 tanh 是逻辑斯蒂克函数和双曲正切函数。本课题拟采用的门控领域自适应神经网络模型如图 1 所示。
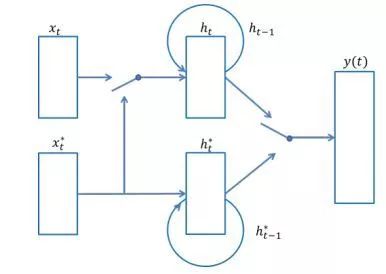
图 1 门控领域自适应神经网络
图 1 中,xt 表示目标域数据的向量;xt*表示始源域数据的向量;y(t) 为结果预测。本方法拟通过更新门和控制门,实现不同领域的标注语料的融合,从而实现全监督领域自适应标注:
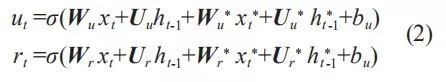
近年来,已经有一些学者开始关注跨领域自动分词的研究 [7,17]。领域词典的使用可有效提高跨领域字词系统的性能 [7]。目前,基于神经网络自适应的中文分词系统的研究还不是很成熟。Li 等人 [17] 在研究过程中发现,常用领域自适应方法是存在一定适用范围的,当目标域标注数据达到一定数量级后,领域自适应方法所产生的效果微乎其微。
结束语
知识图谱用于描述真实世界中存在的各种实体和概念,如何从海量非结构化数据中识别实体是知识图谱构建的关键问题之一。中文知识图谱构建过程中,分词系统对词语的准确切分,可直接实现多数实体和概念的边界划分;可以说,分词系统的性能对知识图谱的构建起着关键性影响。中文分词系统在标准数据集(诸如新闻语料)上的表现接近完美,但在其他缺乏标注的特定领域数据上的表现差强人意,特别是某些专业性较强的领域,由于存在大量未登录词,使得分词系统面临巨大挑战;这就需要面向知识图谱的中文分词系统具有较强的领域自适性。因此,建立具有领域自适应性的分词系统将会是中文分词研究的热点问题之一,也是建立高精度的面向知识图谱中文分词系统的有效途径之一。
参考文献
[1] 漆桂林 , 高桓 , 吴天星 . 知识图谱研究进展 . 情报工程 , 2017, 3(1).
[2] 孙茂松 , 邹嘉彦 . 汉语自动分词研究评述 . 当代语言学 , 2001, 3(1):22-32.
[3] Nianwen Xue, Fei Xia, Fu-Dong Chiou, and Martha Palmer. The Penn Chinese TreeBank: Phrase Structure Annotation of a Large Corpus. Natural Language Engineering. 2005. 11(2), 207-238.
[4] Keh-Jiann Chen, Chu-Ren Huang, Li-Ping Chang, and Hui-Li Hsu. Sinica Corpus: Design Methodology for Balanced Corpora. In Proceedings of the 11th Pacific Asia Conference on Language, Information and Computation. 1996. 167-176.
[5] Huiming Duan, Xiaojing Bai, Baobao Chang, and Shiwen Yu. Chinese word segmentation at Peking University. In Proceedings of the second SIGHAN workshop on Chinese language processing. 2003. 152-155.
[6] Benjamin K. T’sou, Hing-Lung Lin, Godfrey Liu, Terence Chan, Jerome Hu, Ching hai Chew, and John K.P. Tse. A Synchronous Chinese Language Corpus from Different Speech Communities: Construction and Application. International Journal of Computational Linguistics and Chinese Language Processing, 1997. 2(1), 91-104.
[7] Meishan Zhang, Yue Zhang, Wanxiang Che, and Ting Liu. Type-Supervised Domain Adaptation for Joint Segmentation and POS-Tagging. In Proceedings of EACL’14. 2014. 588-597.
[8] Si Li, and Nianwen Xue. Effective Document-Level Features for Chinese Patent Word Segmentation. In Proceedings of ACL’14. 2014. 199-205.
[9] Xipeng Qiu, Peng Qian, Zhan Shi, Overview of the NLPCC-ICCPOL 2016 Shared Task: Chinese Word Segmentation for Micro-blog Texts, In Proceedings of The Fifth Conference on Natural Language Processing and Chinese Computing & The Twenty Fourth International Conference on Computer Processing of Oriental Languages, 2016.
[10] Nianwen Xue. Chinese Word Segmentation as Character Tagging. International Journal of Computational Linguistics and Chinese Language Processing. 2003. 8(1), 29-48.
[11] Fuchun Peng, Fangfang Feng, and Andrew McCallum. Chinese Segmentation and New Word Detection using Conditional Random Fields. In Proceedings of COLING’04. 2004.
[12] Yue Zhang and Stephen Clark. Chinese Segmentation Using a Word-based Perceptron Algorithm. In Proceedings of ACL’07. 2007. 840-847.
[13] Deng Cai, and Hai Zhao. Neural Word Segmentation Learning for Chinese. In Proceedings of ACL’16. 2016.
[14] Meishan Zhang, Yue Zhang, and Guohong Fu. Transition-Based Neural Word Segmentation. In Proceedings of ACL’16, 2016.
[15] Jingjing Xu, and Xu Sun. Dependency-based Gated Recursive Neural Network for Chinese Word Segmentation. In Proceedings of ACL’16. 2016.
[16] Weiwei Sun. A Stacked Sub-Word Model for Joint Chinese Word Segmentation and Part-of-Speech Tagging. In Proceedings of ACL’11. 2011. 1385-1394.
[17] Si Li, and Nianwen Xue. Towards Accurate Word Segmentation for Chinese Patent. arXiv preprint
arXiv:1611.10038. 2016.
[18] Hal Daumé III. Frustratingly easy domain adaptation. In Proceedings of ACL’07. 2007. 256-263.
[19] Young-Bum Kim, Karl Stratos, and Ruhi Sarikaya. Frustratingly Easy Neural Domain Adaptation. In Proceedings of COLING 2016. 2016.
[20] Jian Zhang, Xiaofeng Wu, Andy Way, and Qun Liu. Fast Gated Neural Domain Adaptation: Language Model as a Case Study. In Proceedings of COLING 2016. 2016.
1. http://www.sighan.org/
2. http://www.iarpa.gov/index.php/research-programs/fuse
作者介绍:李思

博士,北京邮电大学信息与通信工程学院讲师。在 ACL、EMNLP、SIGIR 等知名会议发表多篇论文。主要研究方向为自然语言处理。
作者介绍:徐蔚然

博士,北京邮电大学模式识别与智能系统实验室教师。主要研究方向为信息抽取、知识图谱等。
作者介绍:高升

博士,北京邮电大学信息与通信工程学院副教授,法国巴黎六大客座研究员。在 IEEE Trans.、DMKD、KBS、WWW、AAAI、CIKM、ECML 等国际知名期刊和会议上发表了 50 余篇学术论文。主要研究方向为统计关系学习、自然语言理解与社会计算等。
CAAI会员中心
CAAI推荐
点击“阅读原文”,加入CAAI 。
以上是关于人工智能前沿知识的主要内容,如果未能解决你的问题,请参考以下文章