语音驱动嘴型与面部动画生成的现状和趋势
Posted 行者AI
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了语音驱动嘴型与面部动画生成的现状和趋势相关的知识,希望对你有一定的参考价值。
本文首发于行者AI
引言
随着硬件与虚拟现实设备的快速发展,人们说话时的面部表情、唇部动作,甚至是头部与肢体的动作都可以帮助听众理解对话内容。视觉和听觉的双模态信息融合的交互方式,不仅能提高用户对内容的理解度,还能提供一种更为准确的交互体验,提高歌唱的艺术性和观赏度。
语音驱动嘴型和面部动画生成技术可以让开发者快速构建一些基于数字人的应用,如虚拟主持人、虚拟客服和虚拟教师等。除了能提供更友好的人机交互方式之外,该技术在感知研究、声音辅助学习等方面具有重要应用价值,同时,能够在游戏和电影特效等娱乐化方面降低作品制作成本。
语音驱动嘴型与面部动画生成技术,可以让用户输入文本或语音,通过某种规则或者深度学习算法生成对应的虚拟形象的表情系数,从而完成虚拟形象的口型和面部表情的精准驱动。基于深度学习的语音驱动嘴型与面部动画生成技术具有------特点。基于深度学习的嘴型与面部动画生成算法可以自动从训练集中学习训练集中嘴型生成规则和面部表情生成规则和技巧。而基于规则的嘴型和面部表情生成算法可能存在规则复杂,多样性不足,不同的风格对应的作曲规则差距过大等缺陷。
本文将从下面几个方面介绍语音驱动的嘴型和面部生成算法:
- 当前主流语音驱动的嘴型和面部动画生成技术的一些缺陷。
- 能够解决上述缺陷的算法介绍。
1.当前语音驱动嘴型和面部动画生成技术的一些缺陷
语音驱动嘴型和面部动画生成技术需要解决以下几点缺陷:
- 数据少
开源的语音与3D模型同步数据集少。而自行采集数据需要通过专业的动作捕捉软件录制专业演员的表演视频,成本较高。现有的语音驱动面部动画生成技术可操作性不强,要求在训练样本比较比较充分的情况下才能获得比较好的判断效果,否则对于形变、尺度改变、光照改变等干扰,就不能很好地哦安定。
- 真实性
现今绝大多数研究学者仅仅关注语音驱动三维人脸口型动画,忽略了语音驱动人脸面部姿势,导致生成的虚拟人的人脸木讷呆滞,没有任何表情信息的反馈。因此很多语音驱动面部动画生成技术并不能反映人脸最真实的状况,甚至会产生恐怖谷效应。
- 同步性
深度学习合成的嘴型和面部动画存在合成动画不够连续,跳变现象较多,且动画流畅度和自然度欠佳的不足。语音常常比生成的视频帧超前。
2.能够解决上述缺陷的算法介绍
现有的语音驱动嘴型和面部动画生成算法可以部分解决上述缺陷,下面分别介绍几种现有的语音驱动嘴型和面部动画生成算法。
2.1数据少
2.1.1《Capture, Learning, and Synthesis of 3D Speaking Styles》 [1]
提供了一个独特的 4D 人脸数据集 VOCASET,它包括以 60 fps 的帧速率捕捉到的 4D 扫描(共 29 分钟),以及来自 12 名说话者的同期声。
此外本论文提出了模型 VOCA (Voice Operated Character Animation) 可使用任意语音信号作为输入(即使不是英语也可以),然后将大量成人面部转化为逼真的动图。除此之外,VOCA可以改变说话风格,与身份相关的面部姿势(头部,下巴和眼球旋转),还适用于训练集中未出现过的人物形象。
该模型的主要结构如下图:
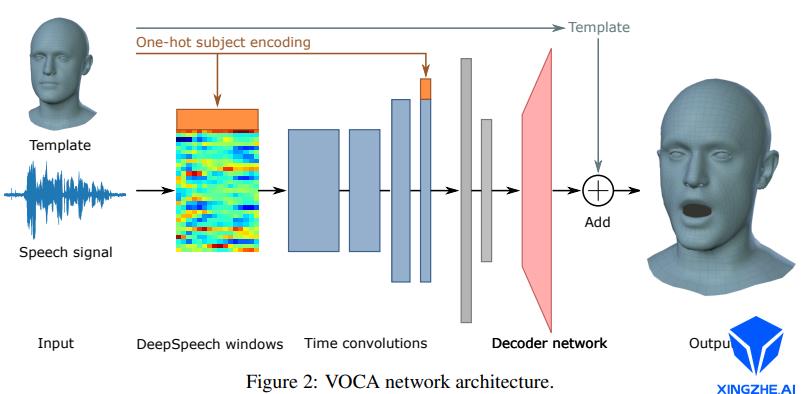
该算法的网络架构如下图
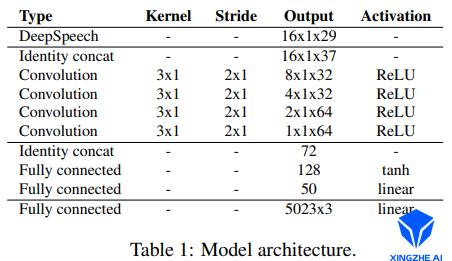
输入:音频、具体人物目标模板。
输出:60fps 3D mesh。
语音特征提取:采用DeepSpeech模型。
编码网络:加入了身份信息,拼接one-hot向量到语音特征上。
解码网络:最后的fc层,输出5023*3个顶点的偏移量,加上模板平均脸,得到说话的表情脸。
2.1.2《Audio-Driven Facial Animation by Joint End-to-End Learning of Pose and Emotion》[2]
该模型的输入使用3~5分钟的高质量动画视频数据训练网络也能获得较好的结果,而且对不同性别、口音、语种的人声训练,都能获得较好的训练效果。
该算法的主要结构如下图:
给定一个音频窗口数据,模型负责输出窗口中心时间点的脸部表情参数。作者用与一个固定拓扑的脸部mesh的逐顶点差分向量表示表情。实际inference时,沿着音频的时间滑窗,每一个step进行推理驱动mesh动画。每个窗口单独作为输入。每个step单独推理,虽然没有像RNN网络一样记忆前后帧的关系,但是滑窗窗口本身窗口让模型具备了前后帧稳定性。
2.2真实性
2.2.1《A Deep Learning Approach for Generalized Speech Animation》 [3]
这个算法采用音视频数据库训练模型。其中音频已经标注了对应的音位信息,使用AMM (Active Appearance Model)从视频中提取人脸表情相关的参数;根据音位和人脸表情动画参数数据集,训练模型。推断过程中,使用语音识别等已有的技术,从音频中提取音位信息,并输入给训练好的模型,输出对应的人脸表情参数。最终将人脸表情参数转移到目标卡通模型脸上,即可驱动卡通模型的面部表情动作。
由于这个算法采用了标准的AAM模型描述模型并使用了滑动窗口预测器,因此可以在成本较低的条件下精准生成自然动作和可视化的协同发音效果。
该算法的主要结构如下图:
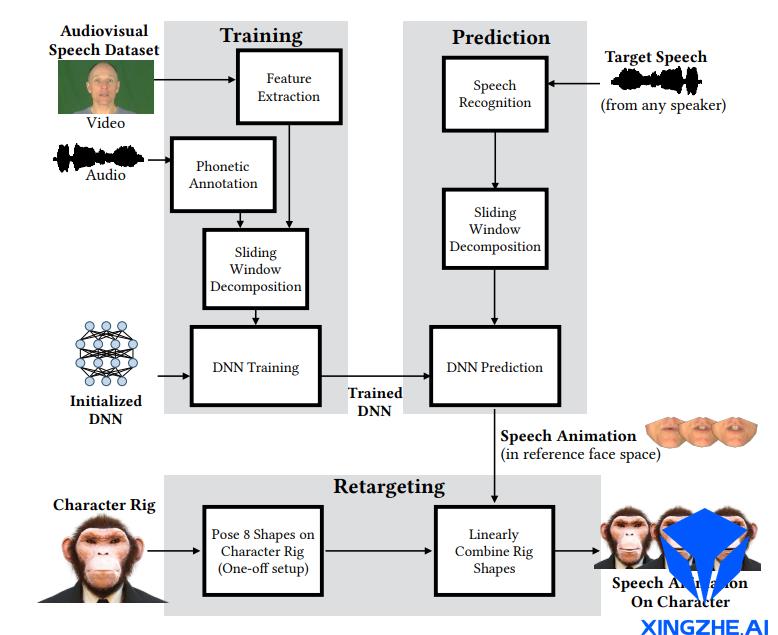
音频特征与人脸表情动画特征之间为序列到序列的映射。常用的学习序列到序列的映射的方法(up to 2017)包括滑动窗口(sliding window model)和循环定义网络(recurrently defined model)。其中前者强调序列的局部短时相关性,而后者强调序列的长时相关性。基于以下的归纳偏置,论文采用了滑动窗口方法。
- 由于协同发音与时序相关,因此在时序上协同发音对应的动画特征序列长度变化很大
协同发音通常具备局部的短时相关性,而与较长序列无关。例如’prediction’和‘construction’中的’-tion’发音相同,而与其之前的字母序列无关。 - 循环定义网络,包括RNN和LSTM网络虽然具备seq2seq的学习能力,但是不符合上述的归纳偏置,需要大量的训练数据才能得到较好的预测效果。论文也通过实验证明滑动窗口方法具有较好的性能特征。
使用滑动窗口方法进行模型训练的流程如下图所示(针对单个表情系数):
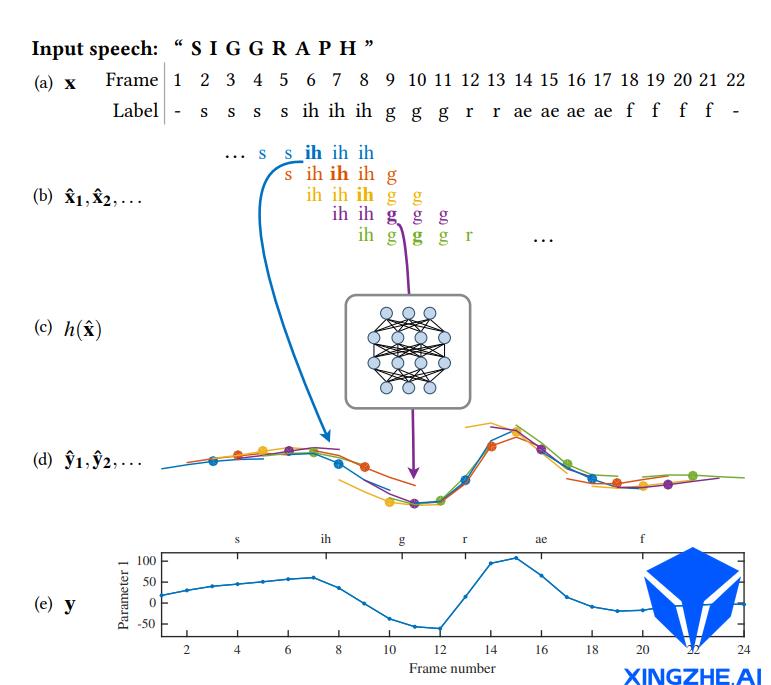
步骤一:首先将输入的音位帧序列按照长度为的滑动窗口,划分为连续重叠子序列,如图(b)
步骤二:将每个窗口内的序列作为输入,传递给前馈神经网络,输出对应长度为的表情参数序列,如图©和(d)
步骤三:使用逐帧平均,在融合得到每帧对应的表情参数,如图(e)
2.2.2《Audio-Driven Facial Animation by Joint End-to-End Learning of Pose and Emotion》
提出了一种端到端的卷积网络,从输入的音频直接推断人脸表情变化对应的顶点位置的偏移量。为了解决声音驱动过程中,情绪变化对表情驱动效果的影响,网络自动从数据集中学习情绪状态潜变量。推理阶段,可将情绪潜变量作为用户输入控制参数,从而输出不同情绪下的说话表情。让最终生成的嘴型效果更加真实。
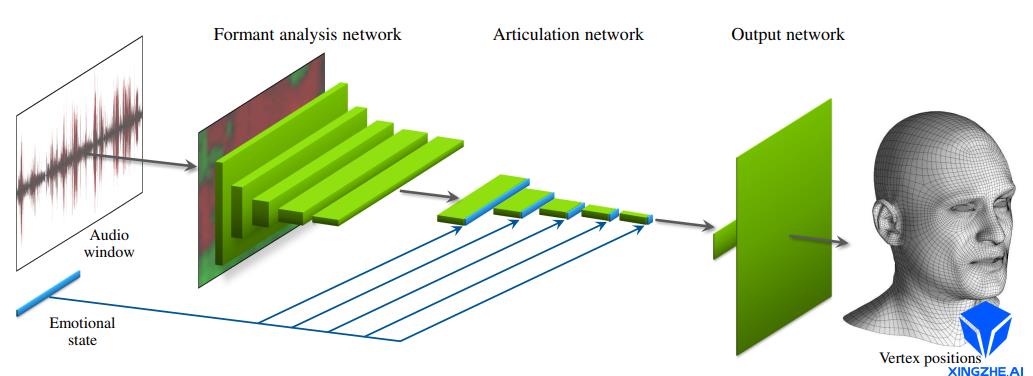
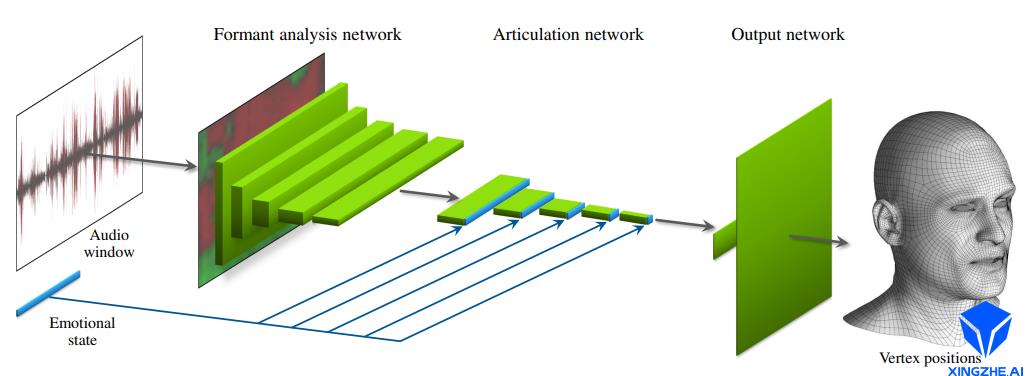
其网络结构完成了对情绪的处理,让最终生成的结果更加真实。根据功能,网络主要划分为三个部分:频率分析层(Formant Analysis Network)、发音分析层(Articulation Network)、顶点输出层(Output Network)。
- Formant Analysis Network
频率分析层包括一个固定参数的自相关处层(autocorrelation)、以及5个卷积层。自相关层使用线性预测编码(Linear Predictive Coding, LPC)提取音频的前K个自相关系数。由于自相关系数描述了原始音频信号共振峰的能量普分布,因此可以用系数来描述音频的特征。自相关层以多帧音频信号为输入,经过处理输出WH的2D音频特征图。其中W表示帧数,H表示自相关系数的维度。2D音频特征图再经过五层的13的卷积,对自相关系数进行压缩,最终输出W*1的特征向量。语音处理层的网络结构如下所示:
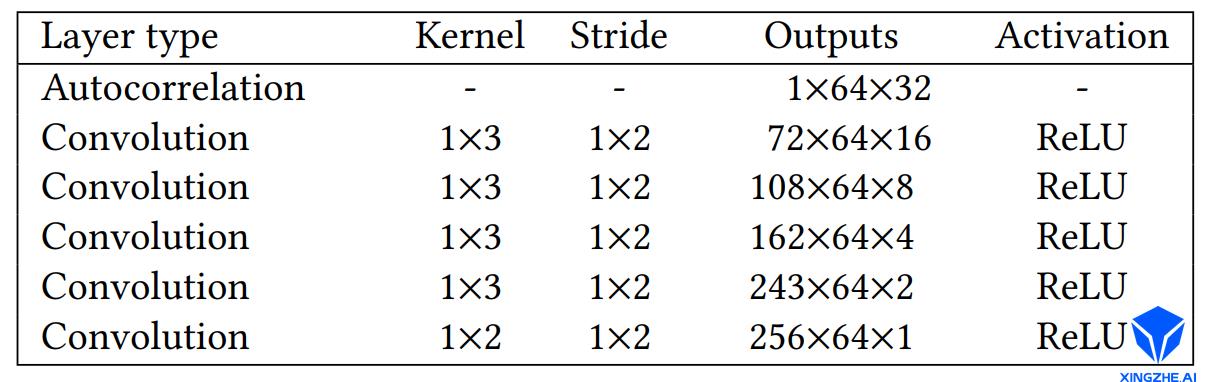
语音单帧时间长度为16ms,因此语音处理网络主要是针对音频的短时特征进行提取,包括语调、重音、以及特殊音位信息等。
- Articulation Network
语音处理层输出的音频特征向量维度为256 * W * 1。其中256为特征图的通道数。发音分析层包含5个卷积层,每层的卷积核为3*1,用于在时序上提取相邻序列帧的关联特征,输出发音特征图。由于发音不仅与声音频率相关,而且与说话者的情绪和类型等紧密相关。语音处理层同时接受训练提取的情绪状态,向量长度为E,直接连接到发音特征图,与发音特征图联合学习与表情的关系。语音处理层的网络结构如下图所示:
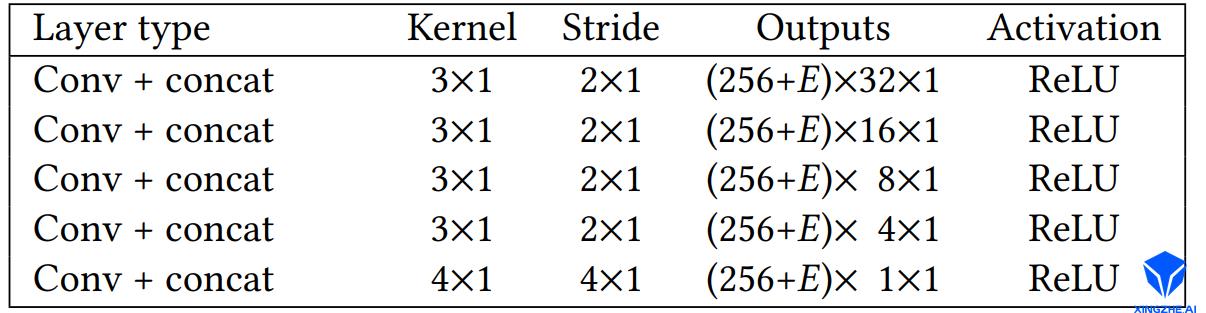
经过语音处理层处理后,最终输长度为(256+E)的特征向量,其中256为音频特征,E为情绪特征。在训练阶段,情绪向量的输入为E维的随机高斯分布采样。针对带情绪的输入样本,训练过程中存储语音处理层输出的特征向量,其中的E维特征向量即为自动学习到的该训练样本数据所蕴含的情绪状态。将不同情绪数据下学习到的情绪特征向量组合构成了情绪状态矩阵。在推断过程中,用户可以选择该矩阵的任意一组向量作为情绪输入(而非随机高斯分布采样),控制输出表情中包含指定的情绪。亦可通过线性组合不同的情绪向量作为输入,从而产生包含新情绪的表情动画。通过此中自动学习数据中蕴含的情绪,避免了手工标数据集的注情绪状态标签所造成的歧义和不准确性。情绪特征向量并没有实际的语义信息,因此并不能通过one-hot向量来描述不同的情绪,一个语义明确的情绪对应的情绪向量可能每一维度值都有取值。
- Output Network
语音处理层输出的(256+E)维的特征向量即为从训练集上学习到的人脸说话表情动画的特征。输出网络通过两层全连接层实现从特征到人脸表情顶点坐标的映射。第一层实现了从语音特征到人脸表情基系数的映射,第二层实现了从表情系数到每个顶点坐标值的映射。第二层的权重矩阵对应的其实就是传统表情驱动中的多线性人脸表情模型,因此可以预先用150个预计算的PCA分量进行初始化。输出网络的结构图如下所示:

2.3同步性
2.3.1《Audio-Driven Facial Animation by Joint End-to-End Learning of Pose and Emotion》
提出了一种端到端的卷积网络,从输入的音频直接推断人脸表情变化对应的顶点位置的偏移量。引入三个损失函数用于训练中约束时间稳定性,以及动画过程中保证响应速度。
该算法的主要结构如下图:
损失函数包括三项,分别为位置项、运动项、以及情绪正则项。对于包含多项的损失函数,一个较大的挑战在于如何给各项选择合适的权重值,用于调和量纲的不同以及重要程度。论文对每一项都进行归一化处理,避免了额外增加权重。
- Position term
位置项。描述了网络预测的人脸表情与gt人脸表情之间的逐顶点均方差值:
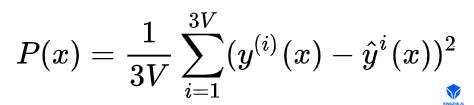
其中V为人脸模型的顶点数。y描述的是将所有顶点按照分量展开后组成的长度为3V的向量。
- Motion term
运动项。位置项只约束了单帧预测的误差,没有考虑帧间的关系,容易导致帧间表情动作的波动,通过约束预测输出帧间顶点运动趋势与数据集上顶点在帧间运动趋势一致,可以有效避免表情动作的抖动,保证动作的平滑。训练通常采用minbatch策略。假设minbatch中训练样本数为B,则按相邻两帧为一组,划分为B/2组,计算组内前后两帧输出差值,作为顶点运动速度。计算符号定义为m[.],则运动项的定义为:
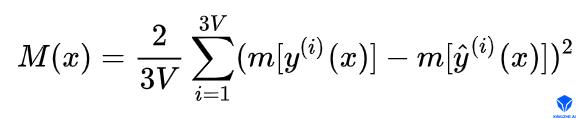
- Regularization term
正则项。为了避免学习到的情绪状态包含跟语音特征相似的特征,需要网络能够自动区分学习语言音频发音特征和情绪特征。考虑到语音频率的短时变化性,情绪在相对较长时间是不变的,可以通过约束情绪状态特征变化过快来引导网络通过音频发音特征描述短时的语音变化,而情绪特征描述长时的情绪变化。通过直接约束两帧情绪状态的变化速度为0即可达到目标:
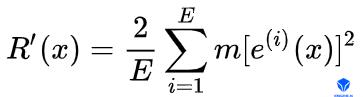
其中 $ e^(i)(x) $ 表示训练样本x时对应的情绪状态特征向量的第i个分量。为了避免网络通过增大权重,而抑制e变量各分量为0来满足该正则项要求,通过借鉴BN的思想,对其进行归一化处理.
3.总结
随着深度学习技术的发展和语音生成嘴型和面部动画技术的进步,会有越来越多的方案能够解决这些缺陷。
参考文献
[1]D. Cudeiro, T. Bolkart, C. Laidlaw, A. Ranjan and M. J. Black, “Capture, Learning, and Synthesis of 3D Speaking Styles,” 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019, pp. 10093-10103, doi: 10.1109/CVPR.2019.01034.
[2] Tero Karras, Timo Aila, Samuli Laine, Antti Herva, and Jaakko Lehtinen. 2017. Audio-driven facial animation by joint end-to-end learning of pose and emotion. ACM Trans. Graph. 36, 4, Article 94 (August 2017), 12 pages.
[3]Sarah Taylor, Taehwan Kim, Yisong Yue, Moshe Mahler, James Krahe, Anastasio Garcia Rodriguez, Jessica Hodgins, and Iain Matthews. 2017. A deep learning approach for generalized speech animation. ACM Trans. Graph. 36, 4, Article 93 (August 2017), 11 pages.
我们是行者AI,我们在“AI+游戏”中不断前行。
前往公众号 【行者AI】,和我们一起探讨技术问题吧!
以上是关于语音驱动嘴型与面部动画生成的现状和趋势的主要内容,如果未能解决你的问题,请参考以下文章