Streamsets爬取CSDN博客之星统计数据并入库
Posted webmote
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Streamsets爬取CSDN博客之星统计数据并入库相关的知识,希望对你有一定的参考价值。
StreamSets 在爬取数据上也有着惊人的表现,它可以方便的调用接口,并简单的转换为json对象,然后进行入库,整个操作过程行云流水一般。
学习系列
- 数据对接-ETL之StreamSet学习之旅一
- 数据对接-ETL之StreamSet学习之旅二
- 数据对接-ETL之StreamSet学习之旅三
- 数据对接-ETL之StreamSet学习之旅四
- 数据对接-ETL之StreamSet学习之旅五
- 数据对接-ETL之StreamSet学习之旅六
- 数据对接-ETL之StreamSet学习之旅七 微服务
- 数据对接-ETL之StreamSet学习之旅八定时启动
- 数据对接-ETL之StreamSet学习之旅十与RabbitMq面对面
- 数据对接-ETL之StreamSet学习之旅九Pipelines的状态监听之WebHook钉钉篇
- 数据对接-ETL之StreamSet学习之旅十一Mysql同步到Snowflake
1、配置定时器
由于StreamSets在之前版本没有定时器,所以想设定固定间隔是个很麻烦的事情,而现在有了定时器CRON,则可以方便的加入定时功能。
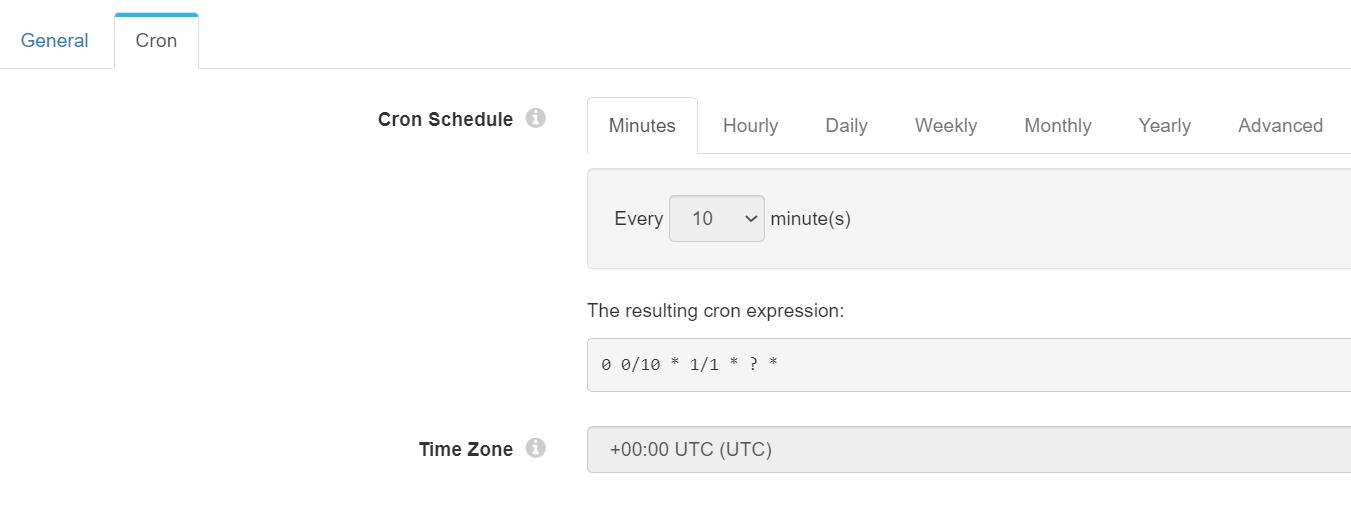
其配置如下所示, 按照图中的配置,仅需要配置为每10分钟1次即可。当然,你可以按照你的频率进行额外的调整。
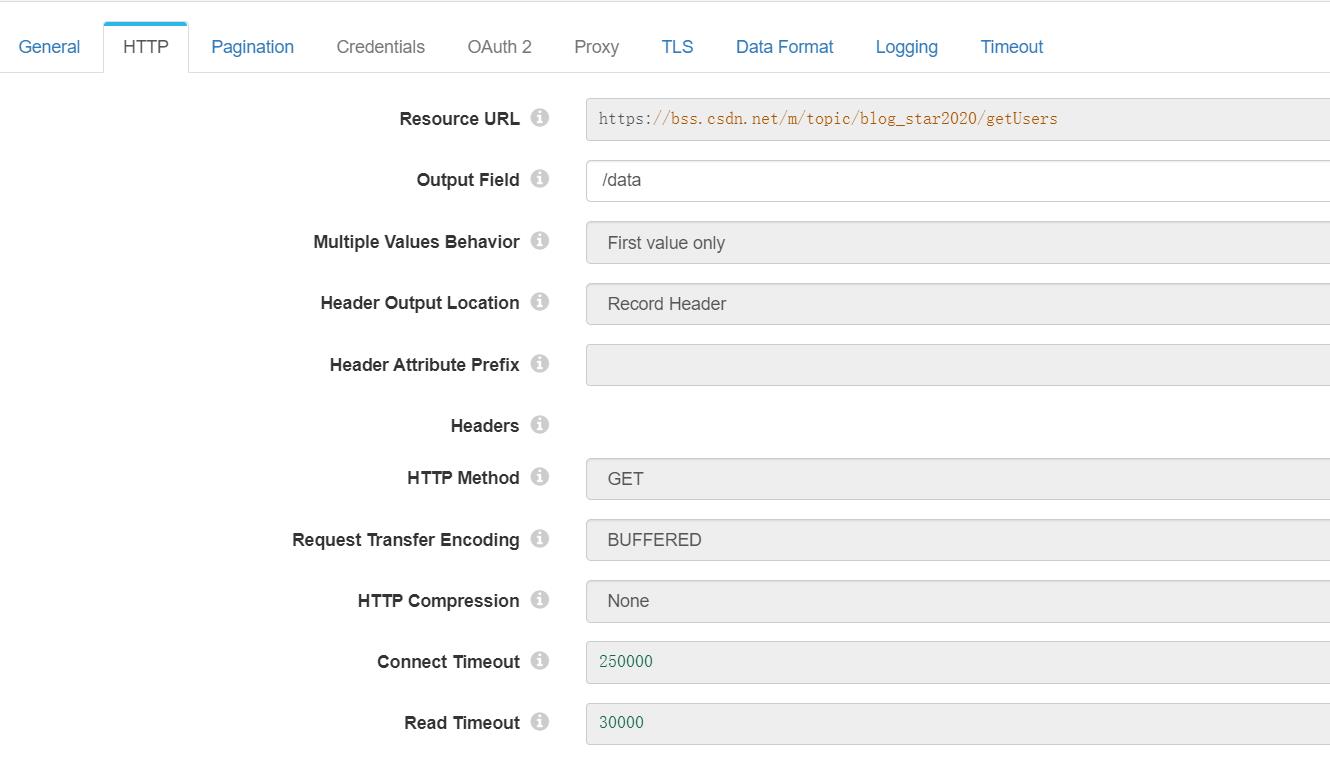
2、http获取数据

其需要配置HTTP项,配置内容如下:
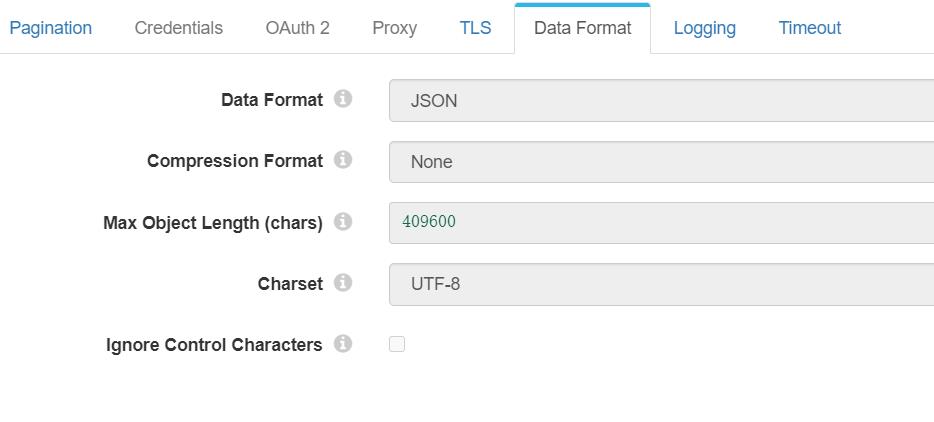
我们把采集到的数据放在 /data 字段内。除了http的配置,我们还需要配置数据格式为json,并且特别需要配置最大数据长度为足够长,否则无法获取到数据。
3、增加流判断
流判断需要使用表达式进行编写,这里需要判断采集http接口返回的状态码是否为200,所以写作为$record:value("/data/code")==200
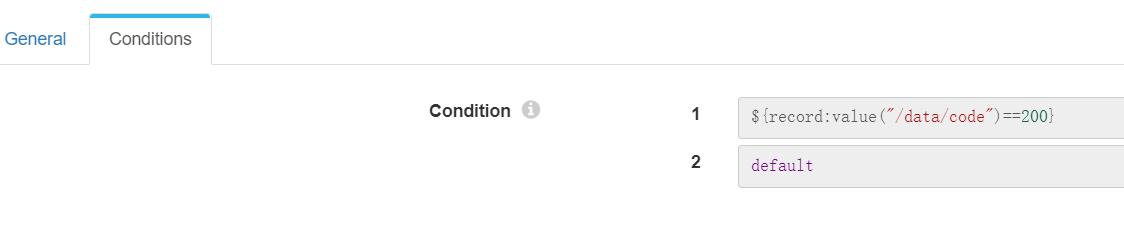
4、数组转批量流记录
采集回来的数据在数组内,在StreamSets软件中,对数组的处理功能很弱,StreamSets的一个核心概念就是流。所以如果把数组转为批量的流记录,则处理起来轻而易举。
这里选用组件“Field Pivoter”。
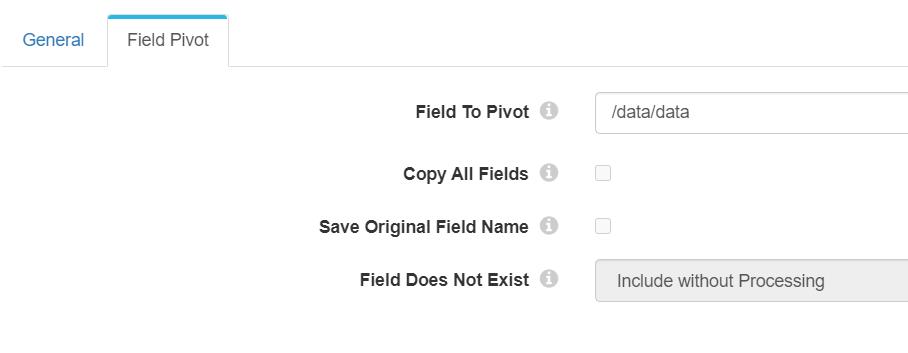
配置如下:选好数组所在的字段,如果字段不存在,不处理错误。
后续数据可以直接入库了,不过因为返回的数据内有ID,而数据库内采用了id作为主键,默认会映射id过去,因此,这里需要先删除id字段。配置如下:
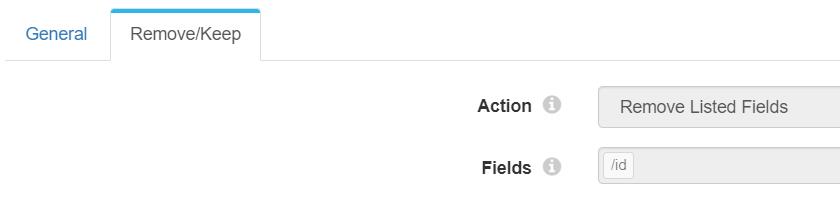
5、数据入库
这里采用mysql作为数据的持久化存储介质,我们选用了 组件“JDBC Tee”作为入库的助手,配置如下:
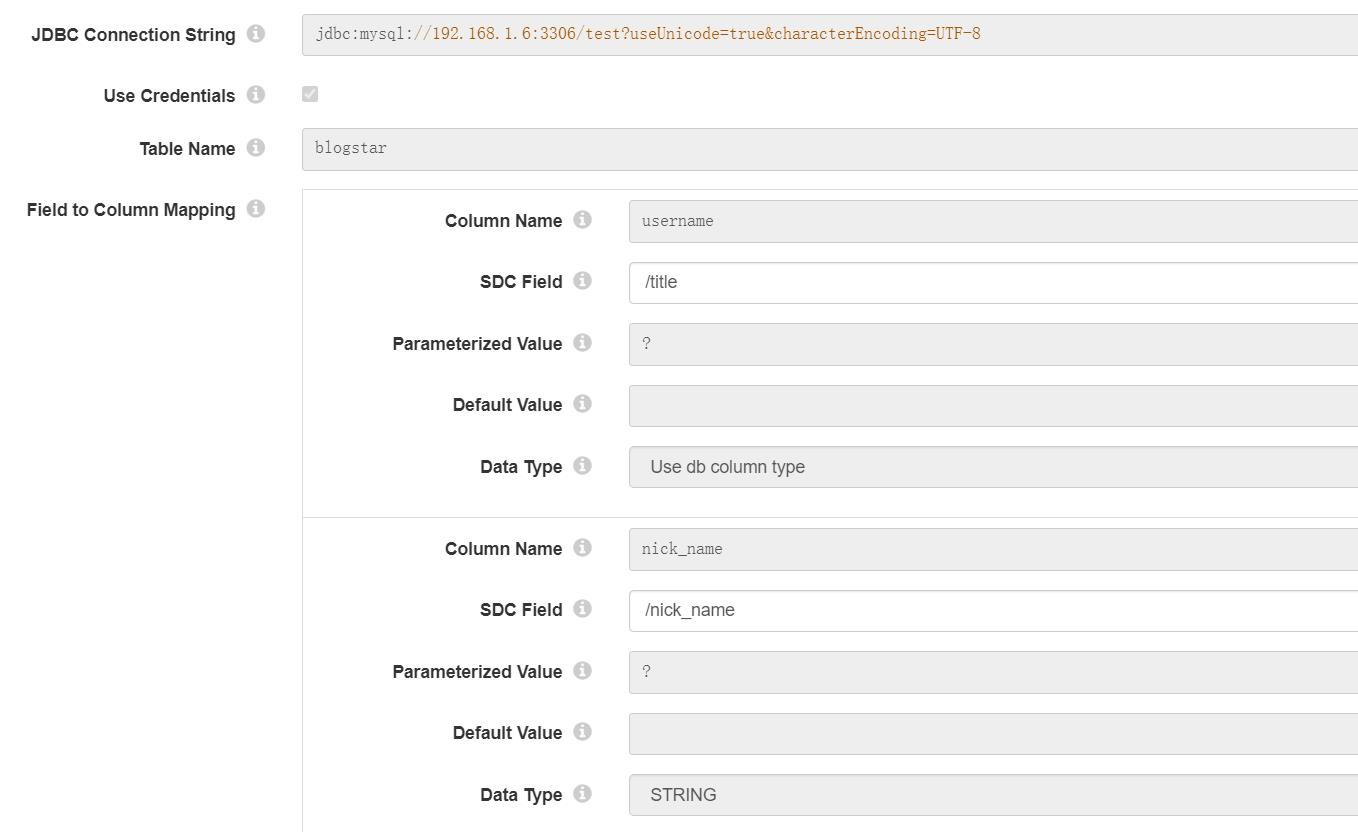
这里字段没有拷贝全面,需要把所有名称映射不同的字段进行配置,名称相同,就可以不配置了,会自动映射过去。
数据的操作选择为 插入。
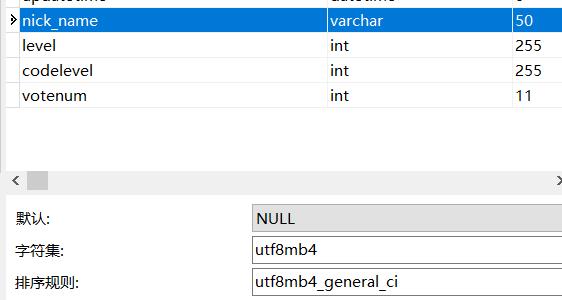
6、表结构
mysql内,数据表结果如下:
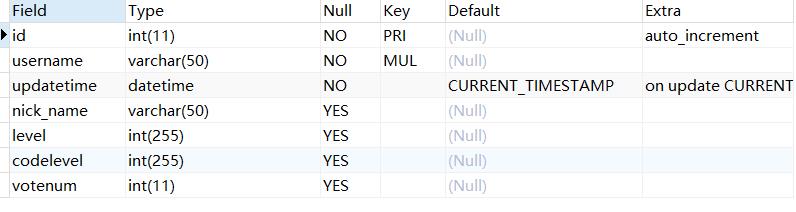
7 整体视角
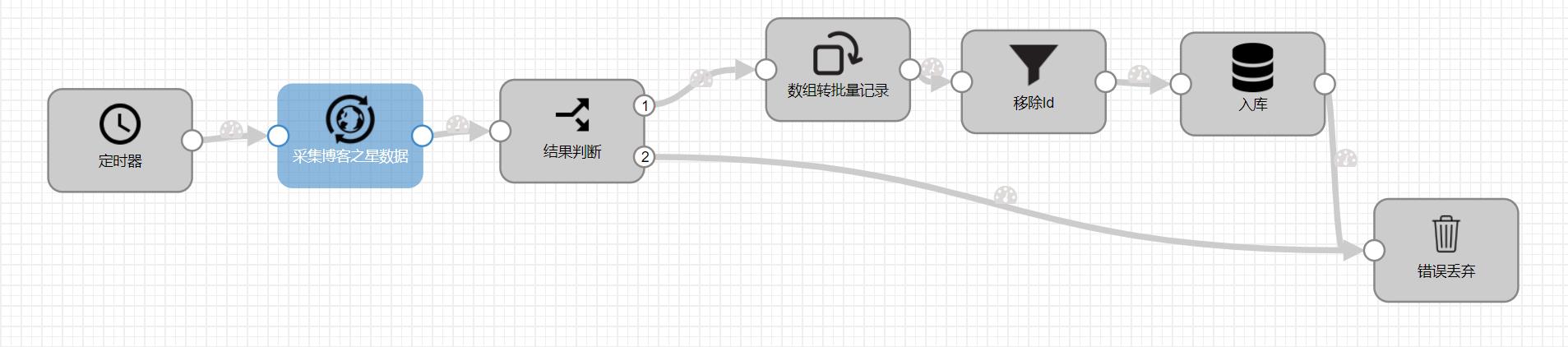
8 入库时小坑
在保存 nick_name时,提示错误 SQLState: HY000 Error Code: 1366 Message: Incorrect string value: '\\xE8\\xB0\\错误,初始以为是utf-8编码问题,查找后发现并不是。
其原因是 nick_name 允许包含 Emoji 表情字符,而这个表情字符需要utf8mb4才能保存下,因此只需要修改表内的nick_name字段为 utf8mb4即可。当然修改整个数据库的字符集为 utf8mb4也可以,我这里就简单处理了下,仅修改表的字段。
9、运行后就不用管了
StreamSets运行新建立的管道,然后就可以了。数据陆续的入库了,查看下表数据。
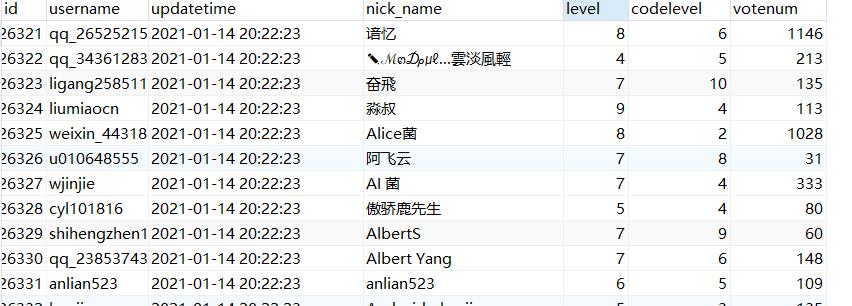
后续就可以作为数据源进行相关分析了,大佬们的票是哗哗的涨,我就躲在角落里瑟瑟发抖。
以上是关于Streamsets爬取CSDN博客之星统计数据并入库的主要内容,如果未能解决你的问题,请参考以下文章