Python深度学习之路-3.1性能评价指标
Posted Vax_Loves_1314
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python深度学习之路-3.1性能评价指标相关的知识,希望对你有一定的参考价值。
1.理解混淆矩阵
所谓混淆矩阵,是指将模型对各个测试数据的预测结果分为真阳性、真阴性、假阳性和假阴性并对符合各个观点的预测结果的数量进行统计的一种表格。
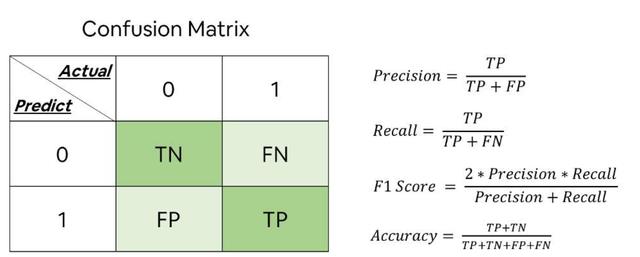
其中,真阳性和真阴性表示机器学习模型的回答是正确的,假阳性和假阴性则表示机器学习的模型回答是错的。
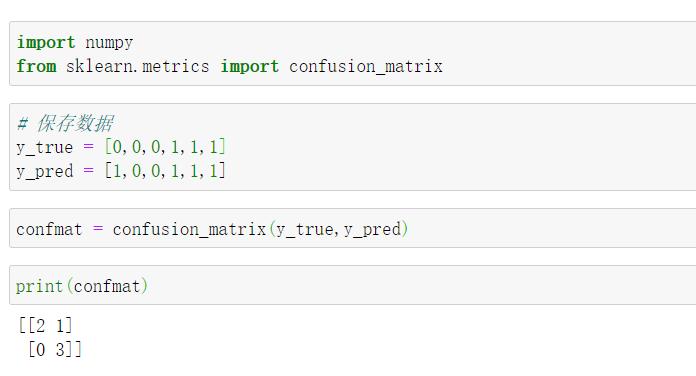
2.编程实现混淆矩阵
使用sklearn.metrics模块中的confusion_matrix()函数对混淆矩阵中的数据进行观察。
confusion_matrix()函数的使用方法如下
from sklearn.metrics import confusion_matrix
confmat = confusion_matrix(y_true,y_pred)
其中,y_true中保存的是正确答案数据的实际分类的数组,y_pred中保存的是预测结果数组。产生的混淆矩阵的格式如下图所示:
- 混淆矩阵练习:
3.准确率
所谓准确率,是指在所有的事件中,预测结果与实际情况相符(被分类到TP和TN中)的事件所占的比例。具体的计算公式如下:
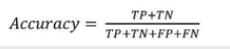
因而3.2中的最后结果准确率为(2+3)/(2+1+0+3)=83.333
4.F值
当数据中存在偏差的话,使用“准确率”这一指标来评估模型是非常危险的,在机器学习中较为广泛使用的是精确率、召回率、F值这些指标来进行性能评估。
- 精确率表示的是预测为阳性的数据中,实际上属于阳性的数据所占的比例
- 召回率表示的是属于阳性的数据中心,被预测为阳性的数据所占的比例
- F值是由精确率和召回率两者组合计算的值(调和平均)
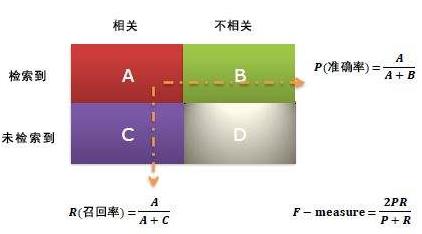
精确率、召回率、F值都是使用0-1范围内的数值来表示的,越是靠近1的值表示性能越好。
5.编程实现
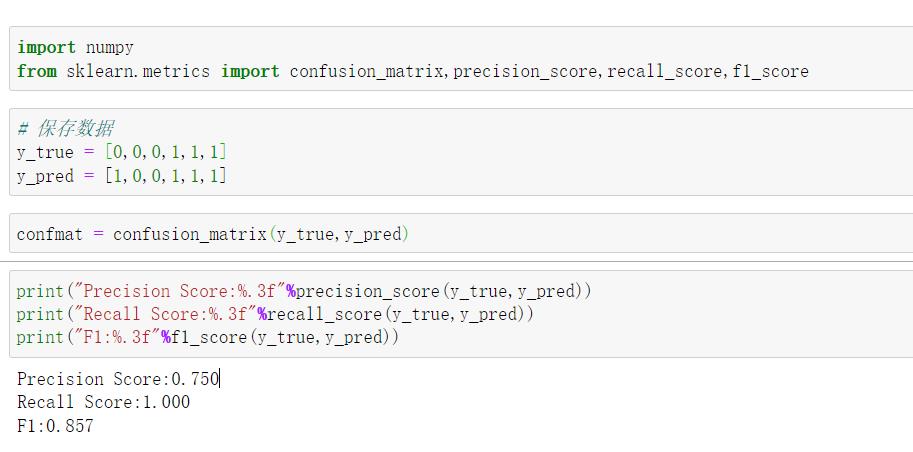
以上是关于Python深度学习之路-3.1性能评价指标的主要内容,如果未能解决你的问题,请参考以下文章