《程序员面试金典(第6版)》面试题 08.04. 幂集(回溯算法,位运算,C++)不断更新
Posted 阿宋同学
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《程序员面试金典(第6版)》面试题 08.04. 幂集(回溯算法,位运算,C++)不断更新相关的知识,希望对你有一定的参考价值。
题目描述
-
幂集。编写一种方法,返回某集合的所有子集。集合中不包含重复的元素。
-
说明:解集不能包含重复的子集。
-
示例:
输入: nums = [1,2,3]
输出:
[
[3],
[1],
[2],
[1,2,3],
[1,3],
[2,3],
[1,2],
[]
]
解题思路与代码
- 其实这道题,一看就是属于子集问题,让你在一个N个数的集合里有多少符合条件的子集。
- 回溯算法是一种试探性的搜索算法,它在解决某些组合问题,字节问题,排列问题等时非常有效,所以呢,这道题,我们就可以去用回溯法去解决。
方法一 : 回溯法
这里就用我最崇拜的carl哥的回溯三部曲模版,来带大家解这道题。
第一步,找出回溯函数模板返回值
第二步,确定回溯函数终止条件
第三步,回溯搜索的遍历过程
关于回溯算法的参数,一般是在写回溯逻辑的时候,发现缺哪个参数就加哪个参数的。不存在与在哪一个步骤就一定要确定好参数是啥。
这个是回溯法的大致模版
void backtracking(参数)
if (终止条件)
存放结果;
return;
for (选择:本层集合中元素(树中节点孩子的数量就是集合的大小))
处理节点;
backtracking(路径,选择列表); // 递归
回溯,撤销处理结果
这道题具体的代码如下:
class Solution
public:
vector<vector<int>> result;
vector<vector<int>> subsets(vector<int>& nums)
if(nums.empty()) return ;
int begin = 0;
int end = nums.size();
vector<int> vec;
result.push_back();
backtracking(nums,vec,begin,end);
return result;
void backtracking(vector<int>& nums,vector<int>& vec,int begin,int end)
if(begin >= end)
return;
for(int i = begin; i < end; ++i)
vec.push_back(nums[i]);
result.push_back(vec);
backtracking(nums,vec,++begin,end);
vec.pop_back();
;
-
需要特别注意的是,在
backtracking(nums,vec,++begin,end);这一行代码中,需要特别注意第二个传入参数。 -
这里可以写
++ begin与i + 1但是不能去写 begin + 1,这是因为,当我们使用++begin作为递归调用的参数时,begin的值在循环迭代中会被改变,而使用begin + 1作为参数时,begin的值在循环迭代中保持不变。这是它们之间的关键区别。 -
使用++begin能够得到正确的结果,因为它确保了begin在每次递归调用之后递增。这样,当递归返回到当前层次时,begin的值已经递增了,从而避免了重复子集的产生。
-
而使用
begin + 1作为参数,在递归调用时虽然传递了正确的下一个值,但在循环迭代中,begin的值保持不变。这导致递归返回到当前层次时,重复使用了相同的begin值,从而产生了重复的子集。 -
i + 1也能达到与++begin同样的效果,这是因为,它们之间都可以保证每次递归调用都是从当前元素的下一个元素开始,所以是对的。而不是从下一个元素开始,这将导致生成重复的子集。
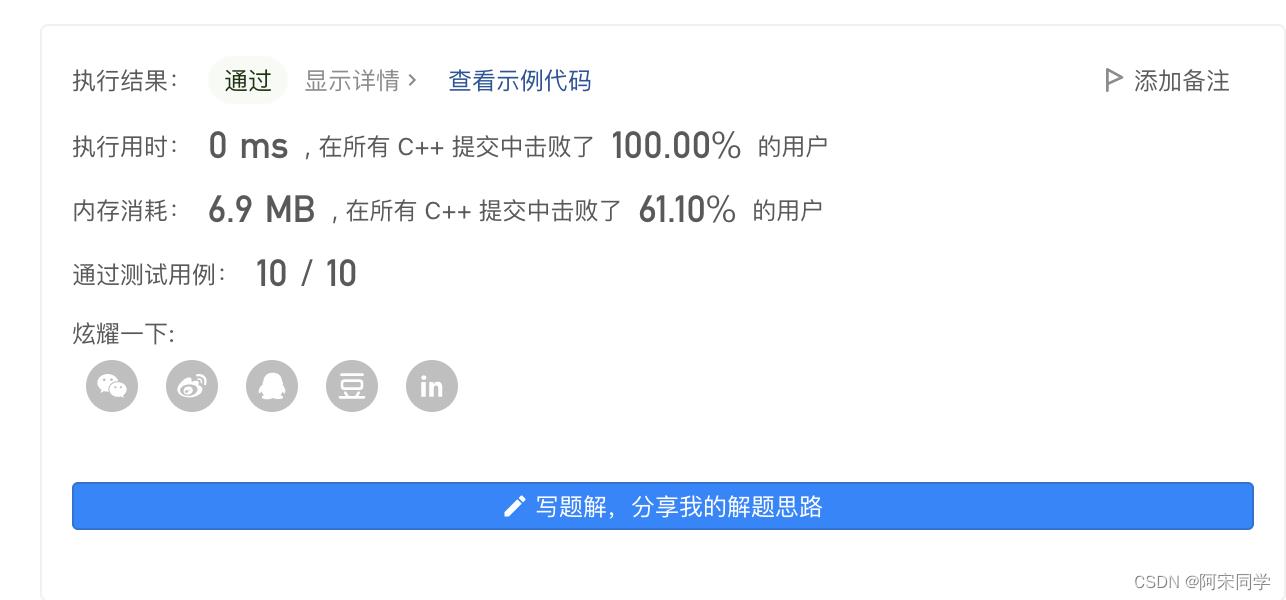
复杂度分析
-
时间复杂度:
对于给定长度为n的nums数组,这段代码会生成所有可能的子集。子集的个数是2n,因为每个元素都有两种选择:包含在子集中或不包含。在这个实现中,我们使用回溯法遍历所有可能的子集。在最坏的情况下,我们需要遍历所有子集并将它们添加到结果集合中。因此,时间复杂度为O(2n * n),其中O(2^n)是遍历所有子集的时间,O(n)是在每次递归调用中复制子集到结果集合的时间。 -
空间复杂度:
递归栈空间:在最坏的情况下,递归栈的深度等于数组的长度n,因此递归栈空间复杂度为O(n)。
结果集合空间:有2^n 个子集。由于子集中的元素总数是固定的,即n个元素,所以实际上我们不需要将每个子集的大小计入空间复杂度。因此,结果集合的空间复杂度应为O(2^n)。
综上所述,这段代码的空间复杂度应为O(n + 2^n)。递归栈空间为O(n),结果集合空间为O( 2^ n) 。
总结
这道题是一道很好的拿回溯模版练手的好题。可以更好的去理解回溯算法。
《程序员面试金典(第6版)》面试题 08.08. 有重复字符串的排列组合(回溯算法,全排列问题)C++
题目描述
有重复字符串的排列组合。编写一种方法,计算某字符串的所有排列组合。
示例1:
- 输入:S = “qqe”
输出:[“eqq”,“qeq”,“qqe”]
示例2:
- 输入:S = “ab”
输出:[“ab”, “ba”]
提示:
- 字符都是英文字母。
字符串长度在[1, 9]之间。
解题思路与代码
这道题一看还是一道关于排列的问题。只要有关排列的问题,我们都可以通过回溯法去解决。
方法一: 回溯法 + 使用unordered_set数据结构进行去重
如果没有做过《程序员面试金典(第6版)》面试题 08.07. 无重复字符串的排列组合(回溯算法,全排列问题)C++
这道题的小伙伴,先去做一下这道题。
这道题与上面链接的那道题非常像,只不过,这里字符串中的字符开始出现有重复的字符了。所以我们做这道题的时候就需要去重。我们直接用unordered_set这种数据结构去去一下重好了。代码与上道题的代码没什么区别,这里给出这道题的代码:
class Solution
public:
vector<string> permutation(string S)
unordered_set<string> result;
backtracking(S,result,0);
vector<string> vec;
for(auto a : result)
vec.push_back(a);
return vec;
void backtracking(string& S,unordered_set<string>& result,int begin)
if(begin == S.size())
result.insert(S);
return;
for(int i = begin;i < S.size(); ++i)
swap(S[i],S[begin]);
backtracking(S,result,begin+1);
swap(S[i],S[begin]);
;
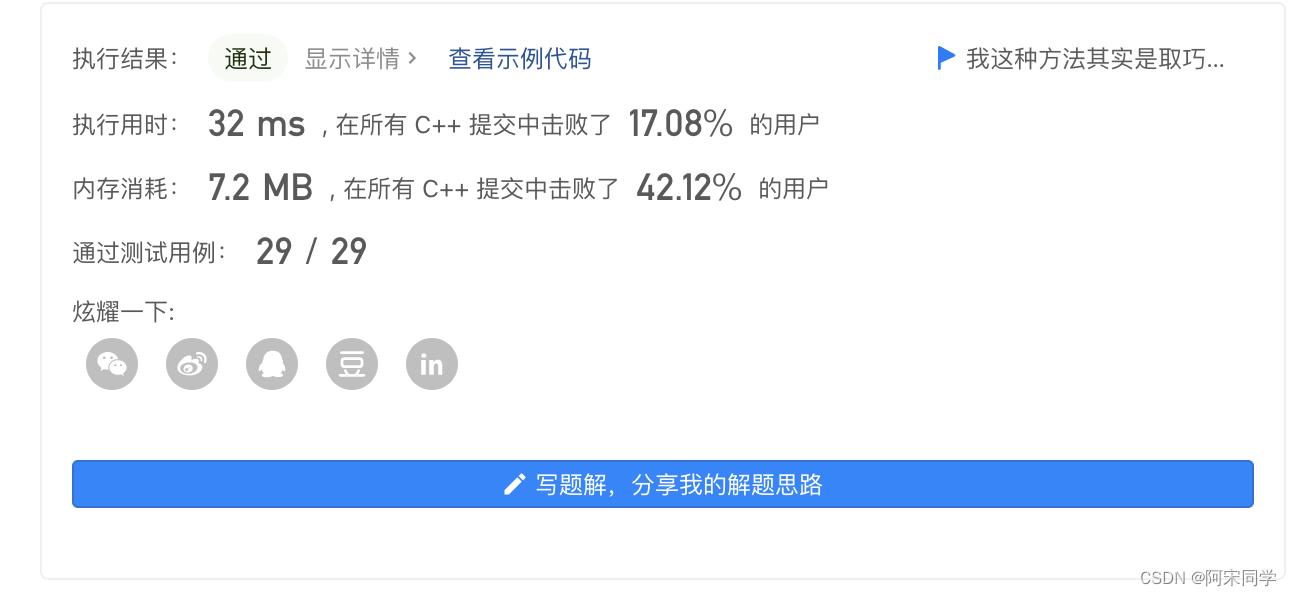
复杂度分析
时间复杂度:
-
这段代码的时间复杂度主要取决于两个部分:backtracking 函数的执行次数以及将结果从 unordered_set 转移到 vector 的时间。
-
backtracking 函数的执行次数:对于长度为 n 的字符串,我们需要对每个字符进行排列组合,这会产生 n! 个排列。在回溯算法中,我们会遍历整个排列空间。因此,backtracking 函数的执行次数为 O(n!)。
-
将结果从 unordered_set 转移到 vector:result 中最多有 n! 个元素。遍历 result 并将其中的元素插入 vector 的时间复杂度为 O(n!)。
-
综合这两部分,总的时间复杂度为 O(n!)。
空间复杂度:
-
空间复杂度主要取决于三个方面:递归调用栈的深度、结果存储在 unordered_set 中所占用的空间,以及结果向量 vec 所占用的空间。
-
递归调用栈的深度:在回溯算法中,递归调用栈的深度等于字符串的长度 n。因此,递归调用栈的空间复杂度为 O(n)。
-
结果存储在 unordered_set 中所占用的空间:result 中最多有 n! 个元素,每个元素是一个长度为 n 的字符串。因此,结果存储在 unordered_set 中所占用的空间复杂度为 O(n * n!)。
-
结果向量 vec 所占用的空间:vec 中有 n! 个元素,每个元素是一个长度为 n 的字符串。因此,结果向量所占用的空间复杂度为 O(n * n!)。
-
由于这三部分空间是算法使用的空间,因此总的空间复杂度为这三者之和,即 O(n) + O(n * n!) + O(n * n!) = O(2 * n * n!) = O(n * n!)。
-
所以,这段代码的时间复杂度为 O(n!),空间复杂度为 O(n * n!)。
方法二 :对代码一的方法进行优化。
在这道题里,因为可能有重复的字符,方法一是直接用unordered_set在结果处进行去重,重复的答案不会被存进集合中,但这种方法不会减少递归的此时。那有没有一种方法,可以在做交换的时候就进行剪枝操作而进行去重呢,而去减少递归的次数呢?
答案当然是有,我们可以通过一个unordered_set去记住在当前的这一层循环里出现过哪些字符,如果出现了重复的字符,那我们就跳过这次交换,直接进入下一次交换。这样也同样达到了去重的目的,也减少了递归的次数。但是不好的一点是增加了内存的存储空间,因为每一层递归都要创建一个unordered_set去存储出现过的字符。
具体代码如下:
class Solution
public:
vector<string> permutation(string S)
vector<string> result;
backtracking(S, result, 0);
return result;
void backtracking(string &S, vector<string> &result, int begin)
if (begin == S.size())
result.push_back(S);
return;
unordered_set<char> used_chars; // 用于存储已经在当前位置出现过的字符
for (int i = begin; i < S.size(); ++i)
if (used_chars.find(S[i]) != used_chars.end())
continue; // 如果当前字符已经在当前位置出现过,则跳过这次交换
used_chars.insert(S[i]); // 记录当前字符
swap(S[i], S[begin]);
backtracking(S, result, begin + 1);
swap(S[i], S[begin]);
;
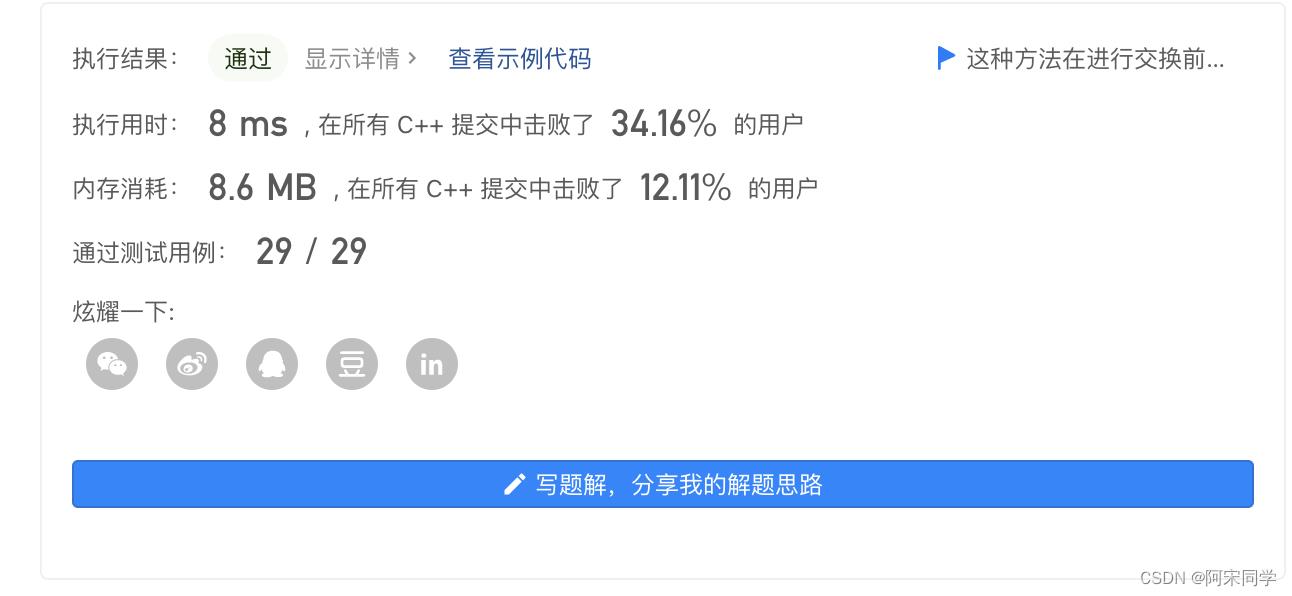
复杂度分析
通过这种剪枝策略,我们避免了搜索重复的路径,从而降低了时间复杂度。然而,在最坏情况下(如所有字符都不同),算法的时间复杂度仍然是 O(n!)。空间复杂度与之前的分析相同,为 O(n * n!)。虽然这种剪枝策略不能在理论上改进时间复杂度,但在有重复字符的情况下,实际运行效率会有所提升,但是同样每一层都会多创建出一个unordered_set去存储至多n个字符,会多消耗一部分的内存空间。
方法三,对代码二的再次优化!
这一次我们写了一个hasDuplicate函数来检查有没有重复出现的字符。这样就不会使用额外的内存空间去存储字符了。
因为begin的值肯定是要比i小的,因为i会递增,而begin不会,从而我们在这个函数中,去递增begin,看看有没有会出现与i相当的字符,如果出现了,就说明有重复,就要跳过这个循环!
class Solution
public:
vector<string> permutation(string S)
vector<string> result;
backtracking(S,result,0);
return result;
void backtracking(string& S,vector<string>& result,int begin)
if(begin == S.size())
result.push_back(S);
return;
for(int i = begin; i < S.size(); ++i)
if(hasDuplicate(S,begin,i)) continue;
swap(S[i],S[begin]);
backtracking(S,result,begin+1);
swap(S[i],S[begin]);
bool hasDuplicate(string& S, int begin,int end)
for(int i = begin; i < end; ++i)
if(S[i] == S[end]) return true;
return false;
;
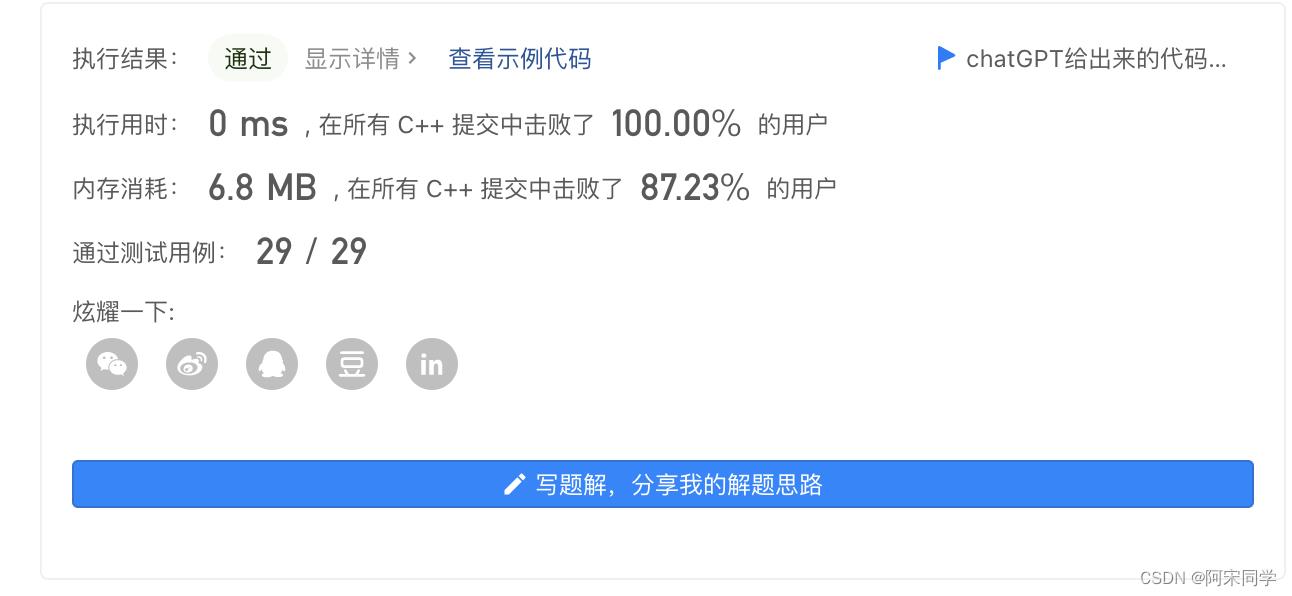
复杂度分析
时间复杂度:
- permutation 函数的时间复杂度主要取决于 backtracking 函数。在最坏情况下,回溯算法将尝试所有可能的排列组合,即 n!。
- hasDuplicate 函数的时间复杂度为 O(n)(在 for 循环内部进行比较)。
- backtracking 函数中调用了 hasDuplicate 函数,所以在最坏情况下,总时间复杂度为 O(n! * n)。
空间复杂度:
- 结果向量 result 的空间复杂度为 O(n!),因为它需要存储所有排列组合。
- 递归栈的空间复杂度为 O(n),因为最深的递归调用次数等于字符串的长度。
- 总的空间复杂度为 O(n! + n)。
综上所述,该算法的时间复杂度为 O(n! * n),空间复杂度为 O(n! + n)。
虽然说,代码1,2,3的时间复杂度都是O(n!),但是在代码三的实际时间复杂度要比1,2快了不少。
总结
这道题不算一道特别难的题。但是呢,剪枝和去重,才是这道题的重中之重。写出简洁并且高效的回溯算法并不容易。我们还得去多学习多总结!
以上是关于《程序员面试金典(第6版)》面试题 08.04. 幂集(回溯算法,位运算,C++)不断更新的主要内容,如果未能解决你的问题,请参考以下文章