论文阅读:MPViT : Multi-Path Vision Transformer for Dense Prediction
Posted BlueagleAI
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文阅读:MPViT : Multi-Path Vision Transformer for Dense Prediction相关的知识,希望对你有一定的参考价值。
中文标题:基于多路视觉Transformer的密集预测

提出问题
创新点
- 提出了一种具有多路径结构的多尺度嵌入方法,以同时表示密集预测任务的精细和粗糙特征。
- 全局到局部的特征交互(GLI),以同时利用卷积的局部连通性和转换器的全局上下文。
网络结构

- 建立了一个四阶段的特征层次图来生成不同尺度的特征映射。
- 步骤:
- 第1层:对于输入HxWx3,我们设计了一个由两个3x3,步长为4,输出通道数为 C 2 C_2 C2的卷积。
- 第2-5层:反复叠加MS-PatchEmbed(multi-scale patch embedding)以及MP-Transformer(multi-path Transformer)
Multi-Scale Patch Embedding
- 输入特征
X
i
∈
R
H
i
−
1
×
W
i
−
1
×
C
i
−
1
X_i \\in \\mathbbR^H_i-1 \\times W_i-1 \\times C_i-1
Xi∈RHi−1×Wi−1×Ci−1, 学习一个
F
k
×
k
(
⋅
)
F_k\\times k(·)
Fk×k(⋅)将
X
i
X_i
Xi排布成新Tokens
F
k
×
k
∈
R
H
i
×
W
i
×
C
i
F_k \\times k \\in \\mathbbR^H_i \\times W_i \\times C_i
Fk×k∈RHi×Wi×Ci,它的通道数为
C
i
C_i
Ci。F的构型为一个大小
k
×
k
k \\times k
k×k,步长s,padding为p的卷积。

- 通过改变 k × k k \\times k k×k的大叫改变Patch的尺寸。卷积补丁嵌入层使我们能够通过改变stride和padding来调整标记的序列长度(输出尺寸)。
- 接着我们得到 F 3 × 3 , F 5 × 5 , F 7 × 7 F_3\\times 3, F_5\\times 5,F_7\\times 7 F3×3,F5×5,F7×7
Global-to-Local Feature Interaction
- 虽然变形金刚中的自我关注可以捕获大范围依赖关系(即全局上下文),但它很可能会忽略每个补丁中的结构性信息和局部关系。
- 此外,Transformer受益于shape-bias[52],允许他们专注于图像的重要部分。
[52]卷积神经网络利用滤波器将图像中的Patchs赋予相同的权重,这类似于视觉皮层中的一个神经元对特定刺激的反应。通过训练这些滤波器的权值,CNN可以学习每个特定类别的图像表示,并已被证明与视觉皮层的处理有许多相似之处。然而,这种局部连通性可能会导致全局环境的丢失;例如,它可能会鼓励人们倾向于根据纹理而不是形状进行分类。
而Transformer则是以自监督为主干,这种机制允许我们在上下文(不同patch间)中增强某些信息的相关性。
- 卷积可以利用平移不变性中的局部连通性——图像中的每个补丁都由相同的权值处理。这种归纳偏差鼓励CNN在对视觉对象进行分类时,对纹理有更强的依赖性,而不是形状。
- 因此,MPViT以一种互补的方式将cnn的局部连接与全局上下文转换器结合起来。
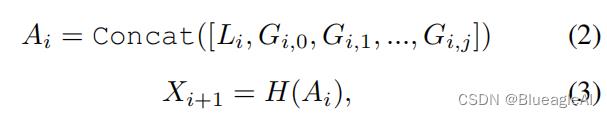
- 分别使用卷积以及Transformer对tokens F k × k F_k \\times k Fk×k提取特征。 H ( ⋅ ) H(·) H(⋅)是特征通道融合器。
参考文献
[1] Lee Y, Kim J, Willette J, et al. Mpvit: Multi-path vision transformer for dense prediction[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022: 7287-7296.
[52] Shikhar Tuli, Ishita Dasgupta, Erin Grant, and Thomas L Griffiths. Are convolutional neural networks or transformers more like human vision? arXiv preprint arXiv:2105.07197, 2021. 4
mpvit
import math
from functools import partial
import numpy as np
import torch
from einops import rearrange
from timm.data import IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD
from timm.models.layers import DropPath, trunc_normal_
from timm.models.registry import register_model
from torch import einsum, nn
__all__ = [
"mpvit_tiny",
"mpvit_xsmall",
"mpvit_small",
"mpvit_base",
]
def _cfg_mpvit(url="", **kwargs):
"""configuration of mpvit."""
return
"url": url,
"num_classes": 12,
"input_size": (3, 224, 224),
"pool_size": None,
"crop_pct": 0.9,
"interpolation": "bicubic",
"mean": IMAGENET_DEFAULT_MEAN,
"std": IMAGENET_DEFAULT_STD,
"first_conv": "patch_embed.proj",
"classifier": "head",
**kwargs,
class Mlp(nn.Module):
"""Feed-forward network (FFN, a.k.a.
MLP) class.
"""
def __init__(
self,
in_features,
hidden_features=None,
out_features=None,
act_layer=nn.GELU,
drop=0.0,
):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
"""foward function"""
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class Conv2d_BN(nn.Module):
"""Convolution with BN module."""
def __init__(
self,
in_ch,
out_ch,
kernel_size=1,
stride=1,
pad=0,
dilation=1,
groups=1,
bn_weight_init=1,
norm_layer=nn.BatchNorm2d,
act_layer=None,
):
super().__init__()
self.conv = torch.nn.Conv2d(in_ch,
out_ch,
kernel_size,
stride,
pad,
dilation,
groups,
bias=False)
self.bn = norm_layer(out_ch)
torch.nn.init.constant_(self.bn.weight, bn_weight_init)
torch.nn.init.constant_(self.bn.bias, 0)
for m in self.modules():
if isinstance(m, nn.Conv2d):
# Note that there is no bias due to BN
fan_out = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(mean=0.0, std=np.sqrt(2.0 / fan_out))
self.act_layer = act_layer() if act_layer is not None else nn.Identity(
)
def forward(self, x):
"""foward function"""
x = self.conv(x)
x = self.bn(x)
x = self.act_layer(x)
return x
class DWConv2d_BN(nn.Module):
"""Depthwise Separable Convolution with BN module."""
def __init__(
self,
in_ch,
out_ch,
kernel_size=1,
stride=1,
norm_layer=nn.BatchNorm2d,
act_layer=nn.Hardswish,
bn_weight_init=1,
):
super().__init__()
# dw
self.dwconv = nn.Conv2d(
in_ch,
out_ch,
kernel_size,
stride,
(kernel_size - 1) // 2,
groups=out_ch,
bias=False,
)
# pw-linear
self.pwconv = nn.Conv2d(out_ch, out_ch, 1, 1, 0, bias=False)
self.bn = norm_layer(out_ch)
self.act = act_layer() if act_layer is not None else nn.Identity()
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2.0 / n))
if m.bias is not None:
m.bias.data.zero_()
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(bn_weight_init)
m.bias.data.zero_()
def forward(self, x):
"""
foward function
"""
x = self.dwconv(x)
x = self.pwconv(x)
x = self.bn(x)
x = self.act(x)
return x
class DWCPatchEmbed(nn.Module):
"""Depthwise Convolutional Patch Embedding layer Image to Patch
Embedding."""
def __init__(self,
in_chans=3,
embed_dim=768,
patch_size=16,
stride=1,
act_layer=nn.Hardswish):
super().__init__()
self.patch_conv = DWConv2d_BN(
in_chans,
embed_dim,
kernel_size=patch_size,
stride=stride,
act_layer=act_layer,
)
def forward(self, x):
"""foward function"""
x = self.patch_conv(x)
return x
class Patch_Embed_stage(nn.Module):
"""Depthwise Convolutional Patch Embedding stage comprised of
`DWCPatchEmbed` layers."""
def __init__(self, embed_dim, num_path=4, isPool=False):
super(Patch_Embed_stage, self).__init__()
self.patch_embeds = nn.ModuleList([
DWCPatchEmbed(
in_chans=embed_dim,
embed_dim=embed_dim,
patch_size=3,
stride=2 if isPool and idx == 0 else 1,
) for idx in range(num_path)
])
def forward(self, x):
"""foward function"""
att_inputs = []
for pe in self.patch_embeds:
x = pe(x)
att_inputs.append(x)
return att_inputs
class ConvPosEnc(nn.Module):
"""Convolutional Position Encoding.
Note: This module is similar to the conditional position encoding in CPVT.
"""
def __init__(self, dim, k=3):
"""init function"""
super(ConvPosEnc, self).__init__()
self.proj = nn.Conv2d(dim, dim, k, 1, k // 2, groups=dim)
def forward(self, x, size):
"""foward function"""
B, N, C = x.shape
H, W = size
feat = x.transpose(1, 2).view(B, C, H, W)
x = self.proj(feat) + feat
x = x.flatten(2).transpose(1, 2)
return x
class ConvRelPosEnc(nn.Module):
"""Convolutional relative position encoding."""
def __init__(self, Ch, h, window):
"""Initialization.
Ch: Channels per head.
h: Number of heads.
window: Window size(s) in convolutional relative positional encoding.
It can have two forms:
1. An integer of window size, which assigns all attention heads
with the same window size in ConvRelPosEnc.
2. A dict mapping window size to #attention head splits
(e.g. window size 1: #attention head split 1, window size
2: #attention head split 2)
It will apply different window size to
the attention head splits.
"""
super().__init__()
if isinstance(window, int):
# Set the same window size for all attention heads.
window = window: h
self.window = window
elif isinstance(window, dict):
self.window = window
else:
raise ValueError()
self.conv_list = nn.ModuleList()
self.head_splits = []
for cur_window, cur_head_split in window.items():
dilation = 1 # Use dilation=1 at default.
padding_size = (cur_window + (cur_window - 1) *
(dilation - 1)) // 2
cur_conv = nn.Conv2d(
cur_head_split * Ch,
cur_head_split * Ch,
kernel_size=(cur_window, cur_window),
padding=(padding_size, padding_size),
dilation=(dilation, dilation),
groups=cur_head_split * Ch,
)
self.conv_list.append(cur_conv)
self.head_splits.append(cur_head_split)
self.channel_splits = [x * Ch for x in self.head_splits]
def forward(self, q, v, size):
"""foward function"""
B, h, N, Ch = q.shape
H, W = size
# We don't use CLS_TOKEN
q_img = q
v_img = v
# Shape: [B, h, H*W, Ch] -> [B, h*Ch, H, W].
v_img = rearrange(v_img, "B h (H W) Ch -> B (h Ch) H W", H=H, W=W)
# Split according to channels.
v_img_list = torch.split(v_img, self.channel_splits, dim=1)
conv_v_img_list = [
conv(x) for conv, x in zip(self.conv_list, v_img_list)
]
conv_v_img = torch.cat(conv_v_img_list, dim=1)
# Shape: [B, h*Ch, H, W] -> [B, h, H*W, Ch].
conv_v_img = rearrange(conv_v_img, "B (h Ch) H W -> B h (H W) Ch", h=h)
EV_hat_img = q_img * conv_v_img
EV_hat = EV_hat_img
return EV_hat
class FactorAtt_ConvRelPosEnc(nn.Module):
"""Factorized attention with convolutional relative position encoding
class."""
def __init__(
self,
dim,
num_heads=8,
qkv_bias=False,
qk_scale=None,
attn_drop=0.0,
proj_drop=0.0,
shared_crpe=None,
):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim**-0.5
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
# Shared convolutional relative position encoding.
self.crpe = shared_crpe
def forward(self, x, size):
"""foward function"""
B, N, C = x.shape
# Generate Q, K, V.
qkv = (self.qkv(x).reshape(B, N, 3, self.num_heads,
C // self.num_heads).permute(2, 0, 3, 1, 4))
q, k, v = qkv[0], qkv[1], qkv[2]
# Factorized attention.
k_softmax = k.softmax(dim=2)
k_softmax_T_dot_v = einsum("b h n k, b h n v -> b h k v", k_softmax, v)
factor_att = einsum("b h n k, b h k v -> b h n v", q,
k_softmax_T_dot_v)
# Convolutional relative position encoding.
crpe = self.crpe(q, v, size=size)
# Merge and reshape.
x = self.scale * factor_att + crpe
x = x.transpose(1, 2).reshape(B, N, C)
# Output projection.
x = self.proj(x)
x = self.proj_drop(x)
return x
class MHCABlock(nn.Module):
"""Multi-Head Convolutional self-Attention block."""
def __init__(
self,
dim,
num_heads,
mlp_ratio=3,
drop_path=0.0,
qkv_bias=True,
qk_scale=None,
norm_layer=partial(nn.LayerNorm, eps=1e-6),
shared_cpe=None,
shared_crpe=None,
):
super().__init__()
self.cpe = shared_cpe
self.crpe = shared_crpe
self.factoratt_crpe = FactorAtt_ConvRelPosEnc(
dim,
num_heads=num_heads,
qkv_bias=qkv_bias,
qk_scale=qk_scale,
shared_crpe=shared_crpe,
)
self.mlp = Mlp(in_features=dim, hidden_features=dim * mlp_ratio)
self.drop_path = DropPath(
drop_path) if drop_path > 0.0 else nn.Identity()
self.norm1 = norm_layer(dim)
self.norm2 = norm_layer(dim)
def forward(self, x, size):
"""foward function"""
if self.cpe is not None:
x = self.cpe(x, size)
cur = self.norm1(x)
x = x + self.drop_path(self.factoratt_crpe(cur, size))
cur = self.norm2(x)
x = x + self.drop_path(self.mlp(cur))
return x
class MHCAEncoder(nn.Module):
"""Multi-Head Convolutional self-Attention Encoder comprised of `MHCA`
blocks."""
def __init__(
self,
dim,
num_layers=1,
num_heads=8,
mlp_ratio=3,
drop_path_list=[],
qk_scale=None,
crpe_window=
3: 2,
5: 3,
7: 3
,
):
super().__init__()
self.num_layers = num_layers
self.cpe = ConvPosEnc(dim, k=3)
self.crpe = ConvRelPosEnc(Ch=dim // num_heads,
h=num_heads,
window=crpe_window)
self.MHCA_layers = nn.ModuleList([
MHCABlock(
dim,
num_heads=num_heads,
mlp_ratio=mlp_ratio,
drop_path=drop_path_list[idx],
qk_scale=qk_scale,
shared_cpe=self.cpe,
shared_crpe=self.crpe,
) for idx in range(self.num_layers)
])
以上是关于论文阅读:MPViT : Multi-Path Vision Transformer for Dense Prediction的主要内容,如果未能解决你的问题,请参考以下文章