ChatGPT能代替Oracle DBA吗?用Oracle OCP(1z0-083)的真题测试一下。
Posted 姚远Oracle ACE
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ChatGPT能代替Oracle DBA吗?用Oracle OCP(1z0-083)的真题测试一下。相关的知识,希望对你有一定的参考价值。
让我们来看看ChatGPT不能通过Oracle OCP的考试?
文章目录
关于博主,姚远:
- Oracle ACE(Oracle和mysql数据库方向)。
- Oracle MAA 大师。
- 华为云MVP。
- 《MySQL 8.0运维与优化》的作者。
- 拥有 Oracle 10g和12c OCM等20+数据库认证。
- 曾任IBM公司数据库部门经理,主导过多个大型数据中心核心库的设计。
- 现在一家第三方公司任首席数据库专家,服务2万+客户。
引言
ChatGPT已经通过了很多考试,姚远老师是Oracle OCP和MySQL OCP讲师,我很好奇ChatGPT能不能通过Oracle OCP的考试呢?让我们拿Oracle 19c OCP考试(1z0-082)的真题对ChatGPT进行一个测试。
测试过程
第1道题ChatGPT就做错了,姚远老师心里不禁窃喜,看来ChatGPT也不咋地,我们也许不会失业,让我们来看看第一道题的题目:
Which two statements are true about space-saving features in an Oracle Database?
A.An index created with the UNUSABLE attribute has no segment.
B.Private Temporary Tables(PTTs) store metadata in memory only.
C.Private Temporary Tables(PTTs) when used, are always dropped at the next commit statement. D.An index that is altered to be UNUSABLE will retain its segment
E. A table that is truncated will always have all of its extents removed
ChatGPT的答案是B和C,B是对的,但ChatGPT选择了一个错误的答案C:
Private Temporary Tables(PTTs) when used, are always dropped at the next commit statement.
实际上PTT有两种:Transaction-specific (ON COMMIT DROP DEFINITION)和session-specific (ON COMMIT PRESERVE DEFINITION)。这两种在commit时都会删除表中的数据,但第二种是不会删除表定义的,因此C是错的。
ChatGPT忽略了一个正确的答案A,于是姚远老师问ChatGPT:你为什么没有选择A,请你做一个实验,创建一个UNUSABLE的索引试试?
ChatGPT回答:作为一个AI语言模型,我没有直接的物理数据库来创建索引。…
现在我知道ChatGPT为什么会做错了,因为ChatGPT没有实验环境。
我自己实验了一下:
SQL> create index in_1 on table_1(no) unusable;
Index created.
SQL> select segment_name,blocks from user_segments where segment_name in ('IN_1');
no rows selected
SQL> alter index in_1 rebuild;
Index altered.
SQL> select segment_name,blocks from user_segments where segment_name in ('IN_1');
SEGMENT_NAME BLOCKS
-------------------- ----------
IN_1 8
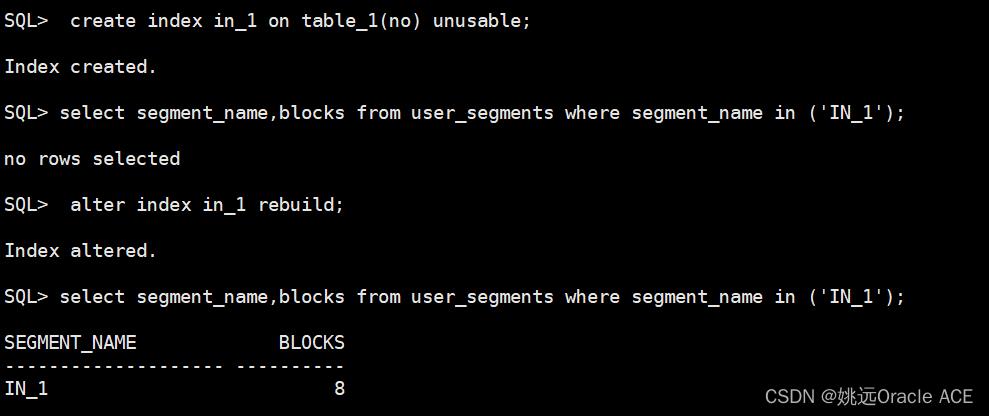
发现创建索引时为unusable是不创建段的,只有重建索引才会有段。
第2道题是关于视图的,ChatGPT对 WITH CHECK的限制很清楚,做对了。
第3道题是PMON进程的作业,ChatGPT还知道从12c后PMON注册监听的功能交给了LRRG进程负责,也做对了。
第4道题是集合的 INTERSECT操作,ChatGPT也做对了。
第5道题是用户的最小权限原则,ChatGPT也做对了。
第6 道题是关于回滚段的题目,ChatGPT做错了,ChatGPT认为:Undo segments can be stored in the SYSTEM tablespace.这个选项是错的,ChatGPT给出的理由是: Undo segments are stored in the undo tablespace, not in the SYSTEM tablespace.
实际上在自动回滚段管理时,如果没有undo表空间,回滚段是可以放在系统表空间中的,在Oracle的官方文档中有下面的内容:
When the database instance starts, the database automatically selects the first available undo tablespace. If no undo tablespace is available, then the instance starts without an undo tablespace and stores undo records in the SYSTEM tablespace. This is not recommended, and an alert message is written to the alert log file to warn that the system is running without an undo tablespace.
感觉ChatGPT做这个选择有点想当然。
第7道题是日期的计算,也做对了。
第8道题做错了,ChatGPT选择了一个下面这个选项:
Directory Naming requires setting the TNS_ADMIN environment variable on the client side.
实际上TNS_ADMIN环境变量不是必需设置的,只有ORACLE_HOME设置了即可。
第9道题错了,ChatGPT选择了一个错误的答案 :
Any user can create a PUBLIC synonym.
实际上即使创建PUBLIC的同义词,也需要 CREATE PUBLIC SYNONYM的系统权限。
ChatGPT还忽略了一个正确的答案:A synonym can have a synonym。
第10道题是关于直接路径导入的压缩格式,这个知识点在Oracle官方文档上面写的清清楚楚,ChatGPT做对了
第11道题是关于延迟段创建特性,ChatGPT也做对了
总结和分析
测试进行到这里,ChatGPT一共做了11道题,错了4道题,正确率为63.6%,而Oracle 19C OCP的1Z0-082的及格线是60%,ChatGPT涉险过关!
更多的Oracle OCP和MySQL OCP题库的解析可以参见:
Oracle 19c OCP和MySQL 8.0 OCP应试指南和题库讲解
姚远老师分析了ChatGPT解题的特点,发现ChatGPT对于在业界答案没有争议的题目做得很好,但ChatGPT也有两个弱点,一个是ChatGPT没有真正的一个Oracle数据库进行实验,因此在解答需要实验验证的题目时很吃亏;另一个是ChatGPT不擅长解决概念上比较绕的问题。但总体来说,ChatGPT已经可以胜任一个初级DBA的工作了,只是对ChatGPT的给出的答案需要一个资深的DBA进行二次验证。
大家觉得ChatGPT能代替Oracle DBA吗?请留言聊一下。
卷完职场卷AI,测试真的会被ChatGPT代替吗?
送走最后一车货,最后三个工人,老王吃力的关上大铁门。左手从口袋摸出一盒烟,轻轻一颠,滑落一根,右手娴熟的夹住。掏出打火机,点燃,一丝青烟腾起,萦绕在指头。
夕阳穿过玻璃,照射在伤痕累累的旧机器上,空旷而寂静。面对空无一人的厂房,老王想起父亲带他来厂房的那个清晨:阳光明媚,厂房异常热闹,忙忙碌碌的嘈杂声格外喜庆。
转眼几十年过去了,厂子从织布到纺丝,从生产手套到加工衣服,终究还是走到了关闭的地步。他听说这是低端制造,利润少、污染大。老王不懂这些,但是他心里清楚东西不好卖了,工人也不好招。自己也老了,不愿折腾了,索性关门养老去吧。
老王是不幸的,也是幸运的,时代抛弃了老王,但是留给他一个温暖的归宿。然而,大多数人被时代抛弃时连声招呼都没有。
初见ChatGpt
大清早,我的朋友小叨激动的告诉我,又一个划时代的技术出现了,一个新时代即将来临了。比尔·盖茨、马斯克看了都说牛,你快看看,接着就是一堆链接。浏览一会后,有点明白什么是ChatGpt,直觉这是一个深度神经网络性质的进步。
OpenAI官网对ChatGpt有个描述:”optimizing Language Models for Dialogue”,简单说这是一个持续优化的用于对话的语言模型。
说到语言模型,大家应该会想到NLP(自然语言处理),ChatGpt核心就是一个自然语言处理模型。特殊之处在于:
-
规模大,拥有1750亿个参数,语言理解能力强;
-
同时,附加了互联网资源(海量信息库),增加了新特性(文本生产能力),能够以顺滑自然的方式于人类互动聊天。
从当前的信息看,ChatGpt可以编写论文、撰写求职信、编写儿童读物、聊天、写代码等等。根据ChatGpt所展现的能力,给予其时间,加以优化和升级,可以预测ChatGpt未来10年将逐步替代很多职业。
2013年,牛津大学的一项研究表明,未来20年,美国47%的工作岗位可能会被人工智能取代,今年已经是2023年了,未来十年内还会有岗位被持续取代。
容易被ChatGpt代替的岗位
那么,什么样的工作容易被人工智能或ChatGpt替代?一般认为以下三类工作容易被替代。
第一类
运营小编、律师助理、媒体人、法律咨询师、市场分析师、家庭教师等这类注重信息收集、分析、加工的职业。
人工智能在海量信息存储、处理和分析上有着天然优势。
第二类
会计、财务顾问、交易员等这类处理大量数据的工作。
人工智能在数据处理上具有更高的效率。
第三类
公司客服、心里咨询师、电话推销员等这类语言交互工作。
人工智能没有感情,不会疲劳,更适合这类固定场景对话,事实上,当前智能客服已经在市场上被大量使用。
创造新机遇
面对如此严峻的现实,网友不禁要问了,我们的“饭碗”还保得住吗?答案显而易见:保的住,也保不住。
这不取决于你的工作岗位是什么,而取决于你的工作内容是什么。
尽管ChatGpt火爆全网,震惊世人,被誉为“划时代技术、人类科技又一个奇点”。谷歌、微软、苹果、百度、阿里、京东等互联网大厂也纷纷布局自己的AI项目,规划自己的“ChatGpt”蓝图,阵仗之大,气势恢宏。
但是,ChatGpt本质上仍然是一个工具,而不是一个类人智慧体。这种本质的区别决定工具本身不会自发创造价值,只有被人使用后才能创造价值,这点很重要。
举个例子:对于小麦收割而言,全自动大型收割机就是一个划时代的高级小麦收割工具。一套全自动大型收割机可以轻松完成几十人、上百人的收割工作,毫无疑问,它减少了人工收割的需求,但是它并没有消灭小麦收割这份工作。
第一,它创造了新的岗位。一套全自动收割机仍然需要很多人参与才能工作,如:驾驶员、维修人员、生产工人等。
第二,它无法满足所有场景的收割任务。受限于地形,丘陵、梯田等这类特殊地形的小麦收割任务,仍然需要人工收割。
ChatGpt的局限
ChatGpt就是一个人工智能领域的“全自动大型收割机”,它能替代一部人人的工作,也会创造出新的岗位。
ChatGpt展示出了较高的对话天赋,能根据人的对话不断学习、优化自己,具有不断“进化”能力,这点较于之前的对话模型有长足的进步。随着越来越多的人和它对话,帮助它学习进步,在肉眼可见的未来,人工智能客服会进一步普及。
但是,和当前所有的智能客服一样,它依旧无法处理更复杂的问题对话。我们还是需要人来处理一些特殊的、复杂的场景,比如贵宾客户、特殊事故等。
因为现阶段的人工智能于人类大脑相比,智慧程度依旧相距甚远。面对开放的、充满不确定性的现实世界,人工智能宛如“人工智障”。
就拿ChatGpt最擅长的聊天功能来说吧,对于语意的理解上仍然有巨大的缺陷。如:“老王的媳妇人不错,我该不该出手,是要出什么手?”“生死由命富贵在天,是要干还是要放弃?”“你应该替他着想,是尊重他,给他自由,还是关注他,及时劝阻他?”等等。这些话在不同的场景,由不同人说出来,所表达的意思会截然相反。
正如一千个读者就有一千个哈姆雷特一样。不同的经历、心境、价值观、身份和文化等,都影响着我们对同一个信息具体意思的理解,这是一个ChatGpt所不能够应对、处理和理解的。
在天然丢失掉语境、语气、语速、语调这类对语意表达至关重要的信息后,ChatGpt要想正确理解所有语意将毫无可能。get不到这些,ChatGpt就无法聊更有思想深度的话题,就宛如一个不谙世事的小孩,可以聊天,但是不会深入聊天,也注定ChatGpt这个现象级的事物会慢慢淡出大部分人的视野。
要解决这个问题,我们需要千千万万个“ChatGpt”,和我们共同生活、经历、学习、成长,形成和我们相似的价值体系。然而,这些以当前计算机算力是无法满足和实现的。只有量子计算这类带来算力飞跃提升的技术实现后,我们才具备人工智能小型化、大规模普及的前提,而这个前提乐观估计还需要二十年甚至更多。
把握工具
工具的使用门槛会阻碍工具的普及,越高级的工具驾驭门槛越高。这个门槛可以是学习成本、操作复杂度、自控能力、信息表达能力等。
比如:
-
Excle有很强大的功能,但是很多同事依旧只会使用基础的数据存储;
-
搜索引擎功能强大,但是很多人都不知道如何使用搜索引擎能理解的方式表达自己的问题,所以通常搜到的东西驴唇不对马嘴,在浏览一堆无效信息后,大骂一句:FUCK后关闭了网页。
网络课程方便高效,想学什么学什么,想听那段听那段。知识就是财富,面对互联网海量的财富,有些人勤奋、刻苦,修炼成技术大牛,有些人熬夜、刷剧,养成了200斤的大胖子。我们有多少人是抱着学习的目的打开电脑,然后游戏、可乐、爆米花。
这些就是高级工具的使用门槛,越高级的工具对人的要求越高。很多人喜欢用初级的工具,因为它们简单易上手、对人的要求少:
-
给你根木棍,3岁以上的小孩就能驾驭;
-
给你一本书,你只有看或者不看的选择,不会面临其他诱惑;
-
给你一台电脑,可做的事情几何倍数的增加。
面对这些诱惑,如何心静如水持之以恒,决定了你是否能够驾驭高级工具。现实是,大多数人都不具备这种能力或者这种能力较弱。所以,我们普通人读书时,要去图书馆、要营造良好的学习氛围,要关闭手机,远离电脑。
这其实并不可耻,面对诱惑能心如止水本就是对圣人才有的要求,有时我们能拿起木棒,就已经比很多人优秀了。
复杂信息的鉴真能力,使得大多数人无法有效使用ChatGpt这类高级工具。ChatGpt有着让人耳目一新的信息收集和内容生成功能确,如完成一个报表,解决一道数学题,搜集某厂商最近五年的收入数据等。这些功能确实很好用,很诱人。但是,如果这些信息不保证正确,对你还有多少价值?
之前听到一个笑话:一个应聘者说他的特长就是计算速度特别快,面试官问他:49乘以39等于多少?应聘者想都没想回答:89!面试官白了他一眼说:你这也差太多了。应聘者说:你就说快不快吧?面试官说:快,但是没用。
如果不能保证信息正确,再便捷、强大的信息收集和加工能力都是鸡肋。ChatGpt也是如此,现在很多人已经发现ChatGpt的回答有时违背基本的常识。比如:有人问它:“出淤泥而不染,濯清莲而不妖”出自哪里,它说《红楼梦》。这也是当今人工智能的一大弱点,无法保证信息的准确性。
而我们要在工作中使用它,势必要对它返回的信息进行鉴真。而信息鉴真能力所需要的的分析思维能力,以及所消耗的脑力是大部分人所不具备、不愿去做的。
如何使用ChatGpt
尽快如此,能够拥抱新工具,我们才能走的更高、更远。俗话说站在巨人的肩膀上才能看到更高,面对新工具,与其处于被替代的恐惧中,不如了解并使用它、借助它,完成你所做的基础工作、低级任务,节约时间和精力用于更需要分析、思考的工作和任务上。
就拿ChatGpt、搜索引擎来说,我们在使用这些工具解决问题前,应优先搞清楚我们的问题到底是什么,将问题拆解成若干小的具体的任务。将其中的信息收集、问题案例等信息收集和初步加工工作交给这些工具完成。通过正向反向信息收集、同类信息类别、多渠道信息比对、原始信息溯源等方式交叉对得到的信息进行鉴真。
然后基于这些信息,通过自己的方法论加工处理,生成更高级的内容、成果。
就拿ChatGpt是否能替代我们这个问题来说:
-
我们首先要找到ChatGpt的原始出处,了解发布者对ChatGpt的介绍以及发布ChatGpt的初衷等信息。
-
然后,搜索ChatGpt的正面信息和负面(反向)信息,了解正向评价都是什么,负面评价又有那些。对比找出矛盾点,根据矛盾点搜索相关解释。
-
这样,我们就会全面的了解到ChatGpt是什么以及它能完成那些事情,存在那些问题。
了解到这些,我们就能轻易发现,ChatGpt以及它的衍生品后续会慢慢替代低质量的工作内容,如简单的信息收集整理,处理规则简单明确的工作。相关工作的人如果不提高自己的工作技能和质量,势必会被替代。
总结
时代在进步,技术在发展,桑海沧田的故事时刻都在发生。忽视这种变化,享受当下的安逸,就要坦然接受潜在的危机。放不下心中不甘,那就立刻行动,迈出脚步。文末,借用一个历史名场面形容下我们当下的处境吧。
卢比孔河的对岸是权利的盛宴,还是致命的陷阱,对于凯撒而言已经不重要。骰子已经掷下,唯有前行,方能始终。于历史不同的是,他有的选择,而我们普通人只会被时代裹挟着跨过卢比孔河。
最后: 下方这份完整的软件测试视频学习教程已经整理上传完成,朋友们如果需要可以自行免费领取【保证100%免费】
这些资料,对于【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴上万个测试工程师们走过最艰难的路程,希望也能帮助到你!

以上是关于ChatGPT能代替Oracle DBA吗?用Oracle OCP(1z0-083)的真题测试一下。的主要内容,如果未能解决你的问题,请参考以下文章