Pix2Pix
Posted zhiyong_will
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Pix2Pix相关的知识,希望对你有一定的参考价值。
1. 概述
很多的图像处理问题可以转换成图像到图像(Image-to-Image)的转换,即将一个输入图像翻译成另外一个对应的图像。通常直接学习这种转换,需要事先定义好损失函数,然而对于不同的转换任务,需要设计的损失函数也不尽相同。得益于生成对抗网络GAN的提出,尤其是条件生成对抗网络cGAN[1](conditional GAN),可以直接学习这种映射关系,同时不需要人工定义该映射的损失函数,可以通过自动的学习得到。基于cGAN的基本原理,Pix2Pix[2]提出了一种图像转图像的通用框架。Pix2Pix网络不仅能够学习到从输入图像到输出图像的映射,还能学习到用于训练该映射的损失函数。
2. 算法原理
2.1. Pix2Pix的原理
与GAN,cGAN的结构一致,在Pix2Pix中包括两个部分,即生成器 G G G和判别器 D D D,对于cGAN的结构,可以由下图表示:
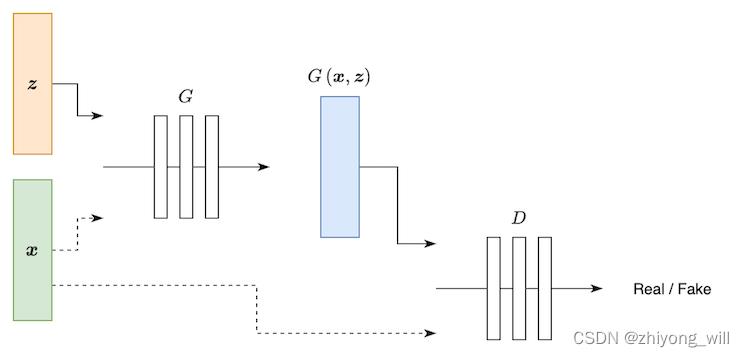
其中, z \\boldsymbolz z为随机噪音, x \\boldsymbolx x为条件变量,对于基本的cGAN,将随机噪音 z \\boldsymbolz z和随机变量 x \\boldsymbolx x两者concat后输入到生成器 G G G中,得到生成结果 G ( x , z ) G\\left ( \\boldsymbolx,\\boldsymbolz \\right ) G(x,z);将生成的结果 G ( x , z ) G\\left ( \\boldsymbolx,\\boldsymbolz \\right ) G(x,z)或者真实数据 y \\boldsymboly y与随机变量 x \\boldsymbolx x两者concat后输入到判别器 D D D中,判断该输入是来自真实的,还是生成的。而Pix2Pix的结构如下图所示:
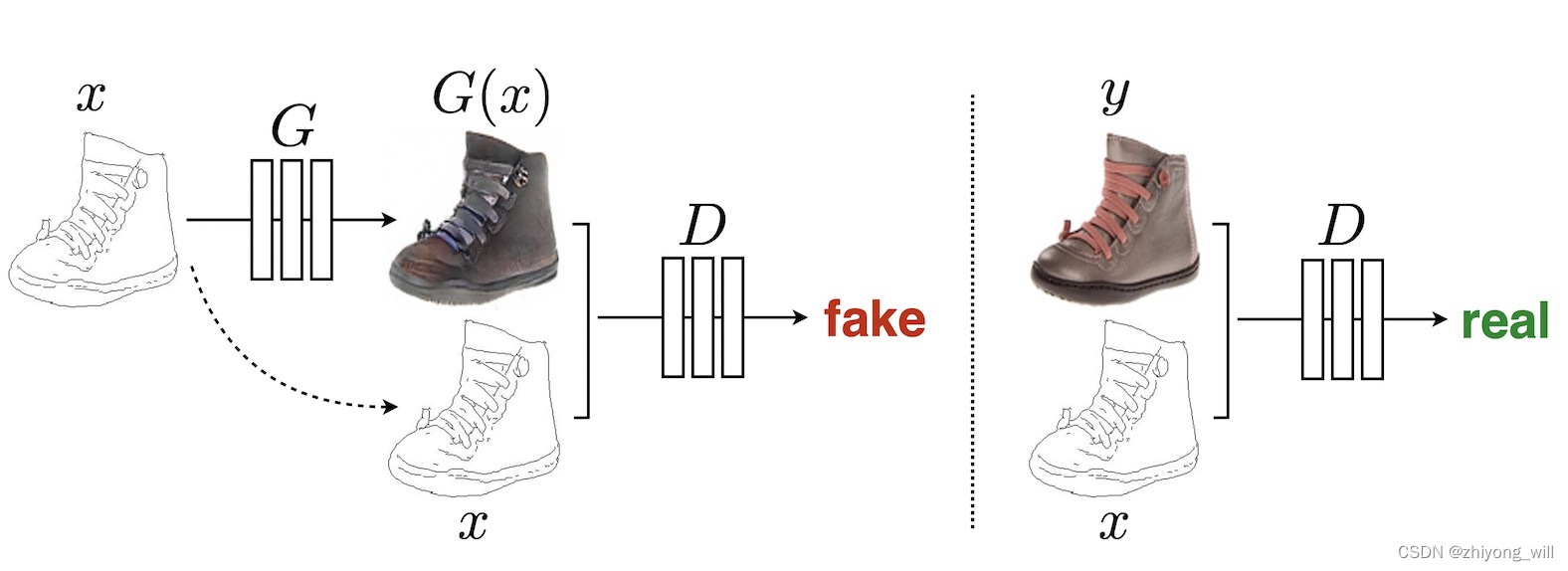
其中生成器 G G G将输入的轮廓图 x \\boldsymbolx x映射成图片 G ( x ) G\\left ( \\boldsymbolx \\right ) G(x),判别器 D D D在轮廓图 x \\boldsymbolx x的条件下,对于生成的图片 G ( x ) G\\left ( \\boldsymbolx \\right ) G(x)和真实图片 y \\boldsymboly y判断是否是真实图片。与cGAN相比,有四点不一致:
| 差异 | cGAN | Pix2Pix |
|---|---|---|
| 生成器 G G G的输入 | concat( z \\boldsymbolz z, x \\boldsymbolx x) | x \\boldsymbolx x |
| 生成器 G G G | MLP | U-Net |
| 判别器 G G G的输入 | concat( G ( x , z ) G\\left ( \\boldsymbolx,\\boldsymbolz \\right ) G(x,z), x \\boldsymbolx x) | concat( G ( x ) G\\left ( \\boldsymbolx \\right ) G(x), x \\boldsymbolx x) |
| 判别器 D D D | MLP | PatchGAN |
对于cGAN,其目标函数为:
L c G A N ( G , D ) = E x , y [ l o g D ( x , y ) ] + E x , z [ l o g ( 1 − D ( x , G ( x , z ) ) ) ] L_cGAN\\left ( G,D \\right )=\\mathbbE_\\boldsymbolx,\\boldsymboly\\left [ log\\; D\\left ( \\boldsymbolx,\\boldsymboly \\right ) \\right ]+\\mathbbE_\\boldsymbolx,\\boldsymbolz\\left [ log\\; \\left ( 1-D\\left ( \\boldsymbolx,G\\left ( \\boldsymbolx,\\boldsymbolz \\right ) \\right ) \\right ) \\right ] LcGAN(G,D)=Ex,y[logD(x,y)]+Ex,z[log(1−D(x,G(x,z)))]
最优的生成器 G ∗ G^\\ast G∗为:
G ∗ = a r g m i n G m a x D L c G A N ( G , D ) G^\\ast=argmin_Gmax_DL_cGAN\\left ( G,D \\right ) G∗=argminGmaxDLcGAN(G,D)
Pix2Pix在cGAN目标函数的基础上,增加了 L 1 L_1 L1正则:
L L 1 ( G ) = E x , y , z [ ∥ y − G ( x , z ) ∥ 1 ] L_L_1\\left ( G \\right )=\\mathbbE_\\boldsymbolx,\\boldsymboly,\\boldsymbolz\\left [ \\left \\| \\boldsymboly-G\\left ( \\boldsymbolx,\\boldsymbolz \\right ) \\right \\|_1 \\right ] LL1(G)=Ex,y,z[∥y−G(x,z)∥1]
最终,最优的生成器 G ∗ G^\\ast G∗为:
G ∗ = a r g m i n G m a x D L c G A N ( G , D ) + λ L L 1 ( G ) G^\\ast=arg\\; \\undersetGmin\\; \\undersetDmaxL_cGAN\\left ( G,D \\right )+\\lambda L_L_1\\left ( G \\right ) G∗=argGminDmaxLcGAN(G,D)+λLL1(G)
在Pix2Pix中,设计了专门的生成器 G G G和判别器 D D D。
2.2. 生成器U-Net
在Pix2Pix中的生成器 G G G采用了U-Net结构,U-Net[3]是2015年提出用于处理生物医学图像分割的卷积网络,U-Net的网络结构如下图所示:
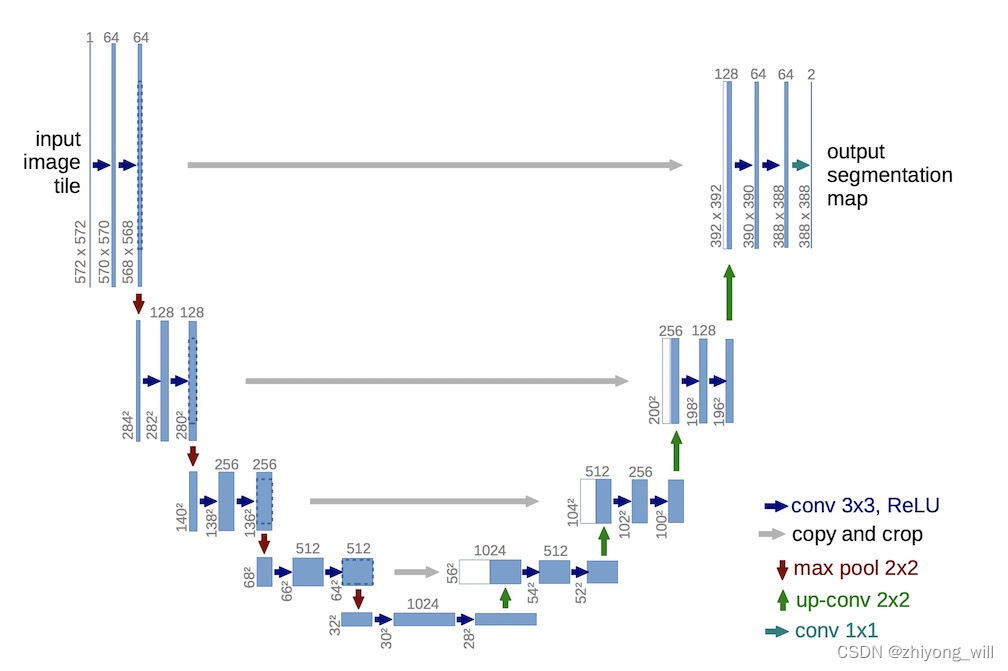
如上图,U-Net网络是一个对称的结构,因为形似英文字母“U”所以也被称为U-Net。在上图中,蓝色和白色的框表示的是 feature map,蓝色箭头表示的是 3 × 3 3\\times 3 3×3的卷积,用于特征提取,灰色箭头表示的是skip-connection,用于特征融合,红色箭头表示的是pooling,用于降低维度,绿色箭头表示的是上采样upsample,用于恢复维度,青色箭头表示的是 1 × 1 1\\times 1 1×1的卷积,用于输出结果。
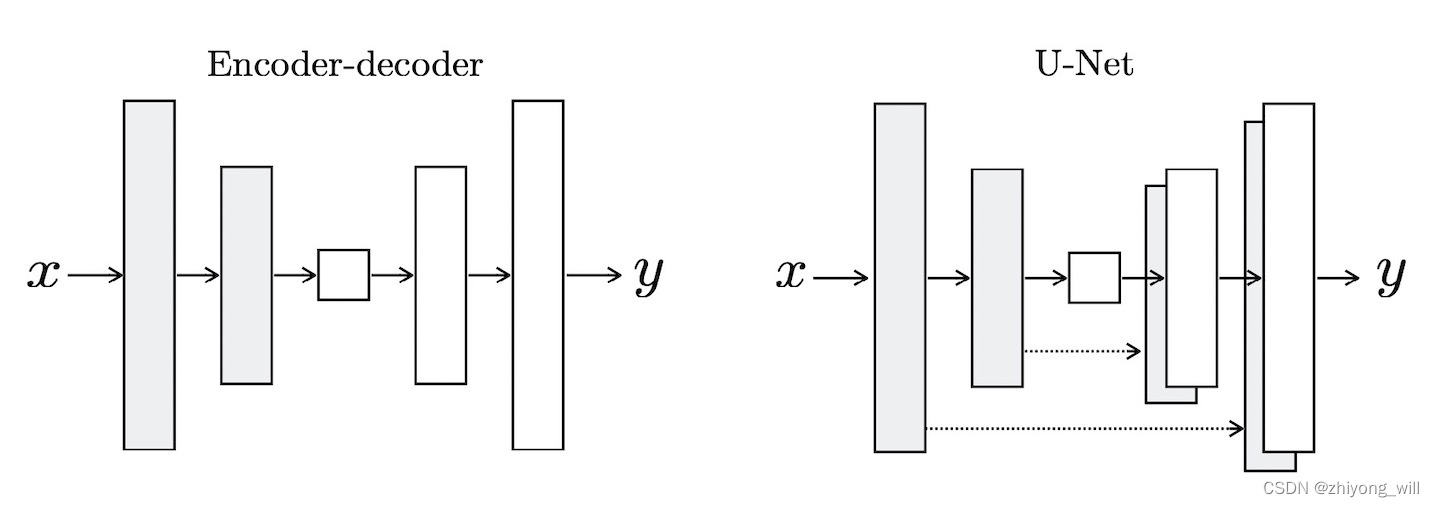
U-Net网络是一个典型的Encoder-Decoder结构,与一般的Encoder-Decoder结构不同的是在Encoder和Decoder之间增加了skip connection。其中Encoder是由卷积操作和下采样操作组成,用于特征提取;Decoder是由卷积操作和upsampling操作组成。其与encoder-decoder架构的关系如下图所示:
2.3. 判别器PatchGAN
判别器PatchGAN的思路也比较直接,对比原先一个CNN模型对整个图片进行卷积和pooling的操作,在PatchGAN中,模型对每一个 N × N N\\times N N×N的patch进行操作,最终将所有的patch块的结果做平均,作为最终的判别器 D D D的输出。
3. 总结
Pix2Pix借鉴cGAN的基本原理,并对其中的损失函数,生成器 G G G,判别器 D D D分别做了优化,从而实现了图像到图像的转换。
参考文献
[1] Mirza M, Osindero S. Conditional generative adversarial nets[J]. arXiv preprint arXiv:1411.1784, 2014.
[2] Isola, Phillip, Jun-Yan Zhu, Tinghui Zhou, and Alexei A. Efros. “Image-to-image translation with conditional adversarial networks.” In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 1125-1134. 2017.
[3] Ronneberger O , Fischer P , Brox T . U-Net: Convolutional Networks for Biomedical Image Segmentation[J]. Springer International Publishing, 2015.
[4] Pix2Pix图图转换网络原理分析与pytorch实现
[5] U-Net原理分析与代码解读
以上是关于Pix2Pix的主要内容,如果未能解决你的问题,请参考以下文章
手把手写深度学习(10):用Pix2Pix GANs实现sketch-to-image跨模态任务(理论基础)
pix2pix与CycleGAN的网络结构(by_xiaojian)