大数据技术Flink开发环境准备和API代码案例
Posted 陆海潘江小C
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据技术Flink开发环境准备和API代码案例相关的知识,希望对你有一定的参考价值。
Flink开发环境搭建和API基础学习
1、Flink简介
看到下面这只可爱的松鼠,显然它不仅是一直普通的松鼠,它还是Flink的项目logo,我们都知道计算机领域很多应用和项目都会使用一只动物作为代表。先来看看这只小动物的意义!

在德语中,Flink 一词表示快速和灵巧,项目采用一只松鼠的彩色图案作为 logo与之呼应,因为柏林的松鼠有一种迷人的红棕色,而 Flink 的松鼠 logo 拥有可爱的尾巴,尾巴的颜色与 Apache 软件基金会的 logo 颜色相呼应,也就是说,这是一只 Apache 风格的松鼠。

对于不熟悉大数据相关的,可以不了解Flink是做什么用的,所以接下来认识一下!
Apache Flink 是一个框架和分布式处理引擎,用于对无界和有界数据流进行有
状态计算。Flink 被设计在所有常见的集群环境中运行,以内存执行速度和任意规模来执行计算。
看到这里,可以猜测出Flink的功能和使用场景:(1)数据处理引擎。(2)分布式架构。(3)计算速度快,适用大规模数据。
有界和无界数据流是什么呢?
这里先认识一下流处理的概念:
流处理是无界、实时的, 无需针对整个数据集执行操作,而是对通过系统传输的每个数据项执行操作,一般用于实时统计。
看完之后,就知道数据流是何物了。而有界和无界在Flink中的区分就是数据的存在形式:离线数据是有界限的流,实时数据是无界限的流。
以流式处理的好处就是取得更低的延迟。
Flink的架构分为多层的API,包括底层的ProcessFunction,中间的DataStream API和顶层的Analytics API,通常使用中间的API比较多,用户可以自定义数据处理方式,也是最丰富和表达能力最好的一层。另外,最高级层就是Flink SQL,直接使用SQL表达式来交互,不过这个模块并不完善。

2、maven工程环境准备
现在使用IDEA创建maven工程,为后面代码编写做准备。


项目创建好之后,准备编程环境,Flink支持Java和Scala编程,scala在这里常用,需要在IDEA中下载插件支持。

这样IDEA就支持scala文件,可以自动识别scala和创建文件。
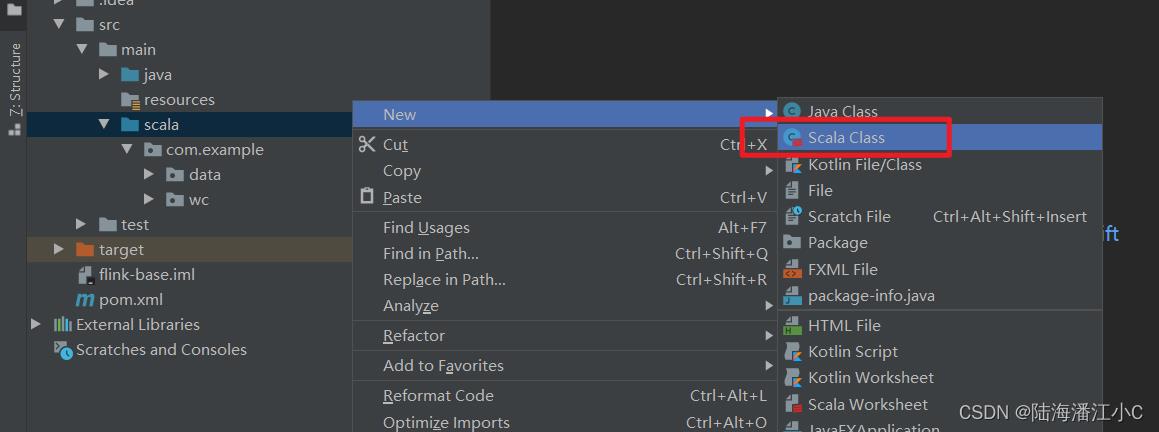
然后可以创建一个test.scala文件试试,一般IDEA会告诉你需要按照Scala SDK,直接点击按照即可,就不需要自己去下载安装包按照,其他按照SDK方法可以参考:Scala SDK安装方法。

自动识别到没有Scala环境,我们就Create一个。


完成之后可以看到SDK的包。

3、Flink流处理API

3.1 Environment
创建一个执行环境,表示当前执行程序的上下文。 如果程序是独立调用的,则
此方法返回本地执行环境;如果从命令行客户端调用程序以提交到集群,则此方法
返回此集群的执行环境,也就是说,getExecutionEnvironment 会根据查询运行的方式决定返回什么样的运行环境,是最常用的一种创建执行环境的方式。
val env = ExecutionEnvironment.getExecutionEnvironment //创建执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
3.2 Source
表示数据的来源,可以来自一个集合、文件、消息队列kafka等,还可以自定义数据源。
- 集合
import org.apache.flink.api.scala._
case class dataFromSet(id:String,timestamp: Long,temperature:Double)
object Sensor
def main(args: Array[String]): Unit =
val env = ExecutionEnvironment.getExecutionEnvironment
val stream1 = env.fromCollection(List(
dataFromSet("sensor_1", 1547718199, 35.80018327300259),
dataFromSet("sensor_2", 1547718201, 15.402984393403084),
dataFromSet("sensor_3", 1547718202, 6.720945201171228)
))
stream1.print("stream1:").setParallelism(1)
env.execute()

- 文件
val stream2 = env.readTextFile("D:\\\\data\\\\test1.txt")
- 以 kafka 消息队列
import java.util.Properties
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer011
object dataFromKafka
val env = StreamExecutionEnvironment.getExecutionEnvironment
val properties = new Properties()
properties.getProperty("bootstrap.servers", "localhost:9092")
properties.setProperty("group.id", "consumer-group")
properties.setProperty("key.deserializer","org.apache.kafka.common.serialization.StringDeserializer")
properties.setProperty("value.deserializer","org.apache.kafka.common.serialization.StringDeserializer")
properties.setProperty("auto.offset.reset", "latest")
val stream3 = env.addSource(new FlinkKafkaConsumer011[String]("sensor", new
SimpleStringSchema(), properties))
pom.xml引入依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka-0.11_2.11</artifactId>
<version>1.7.2</version>
</dependency>
- 自定义数据源
import org.apache.flink.streaming.api.functions.source.SourceFunction
import scala.util.Random
class MySource extends SourceFunction[dataFromSet]
var running = true
override def run(sourceContext: SourceFunction.SourceContext[dataFromSet]): Unit =
val rand = new Random() //随机数生成器
var currTemp = 1.to(10).map(i => ("sensor_" + i, 65 + rand.nextGaussian() * 20))
while (running)
currTemp = currTemp.map(t => (t._1, t._2 + rand.nextGaussian())) //更新值
val currTime = System.currentTimeMillis()
currTemp.foreach(t => sourceContext.collect(dataFromSet(t._1, currTime, t._2)))
Thread.sleep(100)
override def cancel(): Unit =
running = false
Flink的API还有许多,比如转换算子Transform、sink,也是更加深入的内容,这一篇属于基础,先不涉及太多,接下来看看实际的例子!
4、代码案例:统计单词(wordCount)
pom.xml添加Flink、scala相关依赖包。
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_2.11</artifactId>
<version>1.7.2</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.11</artifactId>
<version>1.7.2</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka-0.11_2.11</artifactId>
<version>1.7.2</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin><!-- 用于将 Scala 代码编译成 class 文件 -->
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.4.6</version>
<executions>
<execution>
<goals>
<goal>testCompile</goal><!-- 声明绑定到 maven 的 compile 阶段 -->
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
准备一个测试文件。
Once upon a time . there was a young farmer . On a hot summer day , he was working on his farm where the soil had been shined dry . It made the farmer feel hard to plant . Suddenly , he saw a rabbit which was running fast bump into a big tree . Then the rabbit died . The young farmer picked it up happily and thought . ' I'm lucky today . It costs me nothing to gain this fat rabbit . So I can eat meat this evening . I would rather be lucky like this than work on the farm without any harvest . '
编写代码。
import org.apache.flink.api.scala._ //AggregateDataSet, DataSet, ExecutionEnvironment
object wordCount
def main(args: Array[String]): Unit =
val env = ExecutionEnvironment.getExecutionEnvironment //创建执行环境
val inputPath = "D:\\\\data\\\\test1.txt"
val inputDS: DataSet[String] = env.readTextFile(inputPath)
val wordCountDS: AggregateDataSet[(String, Int)] = inputDS.flatMap(_.split(" ")).map((_, 1)).groupBy(0).sum(1)
wordCountDS.print()
可以看到,一行代码实现了文件中单词的统计,通过flatMap算子以及简单聚合的方法完成。
结果如下:

到这里,学习到基本的Flink,算是入门,动手尝试可以发现细节问题,收获更多!下篇将再深入探索Flink的内容。
欢迎“一键三连”哦,点赞加关注,收藏不迷路,我们下篇见!(⊙ᗜ⊙)
公众号同步更新哦,习惯阅读公众号的伙伴们可以关注下面我的公众号呀!
本篇内容首发我的CSDN博客:https://csdn-czh.blog.csdn.net/article/details/125125337
代码已同步Github:https://github.com/CharZeus/flink-base
以上是关于大数据技术Flink开发环境准备和API代码案例的主要内容,如果未能解决你的问题,请参考以下文章