大语言模型的最新研究方向综述
Posted 邓大帅
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大语言模型的最新研究方向综述相关的知识,希望对你有一定的参考价值。
在自然语言处理( Natural Language Processing, NLP)领域,其最新代表之作ChatGPT凭借卓越的多轮对话和内容生成能力,正掀起新一轮人工智能研究、商用及创业热潮。最近在研究这一话题的过程中,关注到了大语言模型的最新研究,大致有如下几个板块:
- 参数规模和数据规模的探索
- 缩放法则 (Scaling Laws)
- Compute-Optimal :在计算总量不变的情况下,模型训练的效果在参数量和训练数据量当中有个最优平衡点
- Open and Efficient :参数的潜力可以通过更多 Token 训练进一步激发出来。故此可推测,百亿模型的潜力仍有待深入挖掘,尤其在算力资源受限的情况下,存在性价比更高的优化空间。
- 数据规模存在瓶颈 :开放数据即将耗尽。高质量的语言数据按照目前的发展速度,预计 2026 年可能就要耗尽;低质量的语言数据(如日常聊天等)到 2025 年就耗尽;多模态的数据(比如视觉图像)到 2060 年要耗尽。
- 通用大模型的预训练数据集研究
- 通用预训练之对数据多样性的分析:在通用预训练过程中,不同类型的文本代表不同的能力。一部分是训练专业领域的知识,另一部分是训练一些带有情感的讲故事和创造性文艺创作的能力。对话文本虽然规模不大,但是它对提升对话能力非常有帮助。除此之外,还有训练 COT 能力的代码、数学题等,这些数据规模参差不齐,但多样性的数据对提升语言大模型的综合性能起到非常重要的作用。
- 多语种和能力迁移:大规模单语种(英语)预训练中,即使混入的不足 0.1% 其他语种,也会让模型拥有显著的跨语种能力。语言之间存在某种共性,且底层的知识和认知能力是跨语言的,因此混合训练可以起到一定的增强作用。
- 选择最合适的训练数据:正确的训练数据对提升某些能力有重要效果,“对症下药”很关键。例如代码训练显著增强大模型的常识推理能力,且仅使用有限的代码训练量就 能取得比 fine-turned T5 模型明显得多的效果提升。
- 探索预训练的数据过滤和提纯方法:
- 传统的文本分类技术,将高质量的文本作为正面的样本集合,一部分如大量带有互联网上的垃圾广告或者低质量评论等数据做负面样本。标注以后送到分类器里分类,再把高质量的文本提取出来。这是一种常规方法,但严重依赖文本分类、数据标注等,费时费力。
- 基于重要性采样的数据提纯方法。我们在目标样本集里人为的挑出一些我们认可的高质量的数据,对这个高质量的数据做一个 KL reduction,并且做相应分布计算。得出的目标样本的集合越接近,重要性越高,这种方式相对更容易提纯出优质语料用来做模型训练。
- 垂直领域适应预训练
- 探索路线一:自适应预训练。先大规模通用语料预训练,再用小规模领域语料预训练。
- 有两种不同的处理方法:领域自适应的预训练,叫 “DAPT”,DAPT 后在领域任务上相比通用模型效果提升,但是 DAPT 后的领域模型在其它领域上效果比通用模型效果差。 任务自适应预训练,它是在任务的数据集进行训练,叫 “TAPT”。TAPT 相比通用模型也更好,DAPT +TAPT 效果最佳 。
- 预微调:多任务的数据集对它进行 Pre-Finetuning,不同的任务集合越多,最终得到的预微调的模型效果就越好。
- 能力对比:小规模领域语料预训练后的大模型在自身领域内相比通用大模型增强,而在通用生成上表现与通用大模型相当。这是我们值得未来探索的。
- 探索路线二:效果分析。直接进行大规模领域语料预训练工作。
- 路线二是一个性价比非常高的方案,它用到的参数规模并不大,但在垂直领域的效果不错。同时,垂直领域大模型所用资源会比通用大模型少很多,并且和超大规模模型在垂直领域的效果是接近的,这种方式也给我们开启了一些尝试的空间。
- 知识增强:知识增强是专业领域的知识增强,可以较好的探索路线二时提升它的专业模型训练效果。应用了知识增强技术的领域大模型在领域任务上的效果, 好于领域小模型和通用大模型。所以这可能是一条值得去探索的中间道路,是一种垂直领域比大模型要略小一点,但比小模型要大的中间态的模型。
- 探索路线三:语料按比例混合,同时预训练。通用语料比例混合领域语料同时预训练。
- 探索路线一:自适应预训练。先大规模通用语料预训练,再用小规模领域语料预训练。
- 微调技术探索
- 增量微调:为了降低大模型的微调成本,同时能够更高效地把一些专业领域的知识引入进来。结果显示,delta tunig 和 fine tuning 之间的差距并非不可逾越,这证明了参数有效自适应的大规模应用的潜力。
- 多任务提示/指令微调:指令微调的目标是提升语言模型在多任务中的零样本推理能力。微调后的语言模型具有很强的零任务概括能力。
- COT(Chain-of-Thought)微调:将文本 (questions + prompt) 输入给大模型,用大模型输出含有思维链且正确的文本作为 label 。再用上述数据组成的数据对(Reasoning samples),直接对小模型进行微调。使小语言模型获得思维链能力。
- 提示工程prompt和垂直优化
- 提示工程( Prompt Engineering ):在垂直领域创新工程方面,我们的大思路是让模型完成垂直领域指定任务后,在 prompt 当中提出明确的要求,这样能够把垂直领域的专业任务变成模型期望的输出。未来在复杂的垂直领域任务可能需要极为丰富的 prompt 信息,包括各类事实、数据、要求等,并存在层层递进的多步骤任务,因此值得探索产品化方案来生成 prompt。提示工程的两种思路:
- 产品化思路:请垂直领域的专家,针对每项垂直任务,来设计用于生成 prompt 的产品,由专家编写大量不同的 prompt,评估或输出好的 prompt 后,进行片段切分,形成相应的产品。
- 自动化的思路:通过借过外部工具,或通过自动化的流程方法和训练方式,对 Prompt 进行自动优化。有两种不同的技术路线,一种叫 APE 的技术,一种叫 DSP 的技术,它们基本思想都是让大语言模型加入到Prompt 过程当中。另外,我们可以训练一个小的 LLM,它能够对 Prompt 进行有效提示,未来都可以在很多垂直领域里得到创新和应用。
- 提示工程( Prompt Engineering ):在垂直领域创新工程方面,我们的大思路是让模型完成垂直领域指定任务后,在 prompt 当中提出明确的要求,这样能够把垂直领域的专业任务变成模型期望的输出。未来在复杂的垂直领域任务可能需要极为丰富的 prompt 信息,包括各类事实、数据、要求等,并存在层层递进的多步骤任务,因此值得探索产品化方案来生成 prompt。提示工程的两种思路:
- 模型训练加速思路
在我们工业界的模型加速大致有两块思路,一是分布式并行,二是显存优化工作。- 分布式并行的工作。有 4 种常见技术:
- 数据并行(Data Parallelism):在不同的 CPU 上存放神经网络的副本,用更大的 batch size 来训练模型,来提高并行能力。
- 模型并行(Tensor Parallelism):解决模型在一个 GPU 上放不下的问题。
- 流水线并行(Pipeline Parallelism):多个 GPU 之间高效利用它的资源。
- 混合并行(Hybrid Parallelism):这些并行工作能够更好地充分利用 GPU 的并行运算能力,来提升模型迭代加速的速度。
- 显存优化。显存优化方案,像混合精度训练、降低深度学习训练中间激活带来的显存占用、能够降低模型加载到显存当中的资源占用,以及我们通过去除冗余的参数,引入 CPU 和内存等等方式,能够解决显存容量不够导致的模型运算慢或者大模型跑不动的问题。
- 分布式并行的工作。有 4 种常见技术:
- 模型功能的垂直效能增强:大语言模型存在很多缺陷,如存在事实性错误以及关键数据错误、垂直领域可能存在复杂的推理任务等。基于此,我们也在尝试一些不同的思路来做,比如在推理能力方面,我们也在尝试把复杂任务分解为多个简单任务,并且引入其他模型解决;在工具方面,有一些 ALM 的输出中包含特定的 token,激活去调用规则;在行为方面,使用一些工具对虚拟和现实世界进行影响。
- 利用 CoT 增强模型复杂推理能力 :我们对原有的模型通过 CoT 做个增强训练,能有效提升它的 Few-Shot 或者 Zero-Shot 的能力。通过 CoT 可以显著增强模型在 GSM8K 数据集上的准确率。
- 使用其他模型:例如当计算机做一个长文档的规划协作生成的内容,我们让相应的其他模型做一个生成后,引入分类模型,判断生成段落的上下文和相关性,把其他的模型的结果串连在当前的模型当中,能够进行迭代和顺序的循环调用,这样就能够突破现有当前大语言模型在特别长的文本当中生成的短板,能够提升它的写作效能。
- 使用垂直知识库:小模型如果用外部语料库、专用语料库的模式,在有些任务上可以和大模型相媲美。而且应用场景广泛,实际落地中也探索了语言模型和知识图谱的交互。
- 使用搜索引擎:搜索引擎在传统意义上知识严重受限于语料库的实现,所以如果我们使用特定 token 激活或提示的方式生成查询语言,去请求搜索引擎的结果,并融合到当前模型的训练和输出当中,是可以很好的来弥补语料库更新不及时导致的很多信息滞后等问题。尤其是基于搜索引擎提供事实性的文档,使用外部搜索引擎来补充相关的语料资源,可以增强回答问题的可解释性,和用户的习惯对齐。
- 内容转换:在涉及数学领域的运算,今天的语言模型因为没有实质理解数学运算背后的含义,所以往往这个结果会做错。因此,我们可以利用 CoT 将复杂问题分解为若干个简单问题并生成可执行代码,然后利用代码解释器获得最终结果以辅助语言模型解决复杂推理问题。
CMU预训练模型最新综述:自然语言处理新范式—预训练Prompt和预测
©PaperWeekly 原创 · 作者 | 王馨月
学校 | 四川大学本科生
研究方向 | 自然语言处理

概要
本文针对自然语言处理的新范式——我们称之为“prompt-based 学习”,进行了综述与组织。

论文标题:
Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing
Pengfei Liu, Weizhe Yuan, Jinlan Fu, Zhengbao Jiang, Hiroaki Hayashi, Graham Neubig
论文链接:
https://arxiv.org/abs/2107.13586
区别于传统的监督学习中训练模型接受输入 x 并将输出 y 预测为 P(y|x),Prompt-based 学习基于直接对文本概率进行建模的语言模型。为了使用这些模型执行预测任务,使用模板将原始输入 x 修改为具有一些未填充槽的文本字符串 prompt x',然后使用语言模型对未填充信息进行概率填充以获得最终字符串 x ,从中可以导出最终输出 y。
这个框架强大且有吸引力的原因有很多:它允许语言模型在大量原始文本上进行预训练,并且通过定义一个新的 prompting 函数,模型能够执行少样本甚至零样本学习,可以适应很少或没有标记数据的新场景。
http://pretrain.nlpedia.ai/


引言
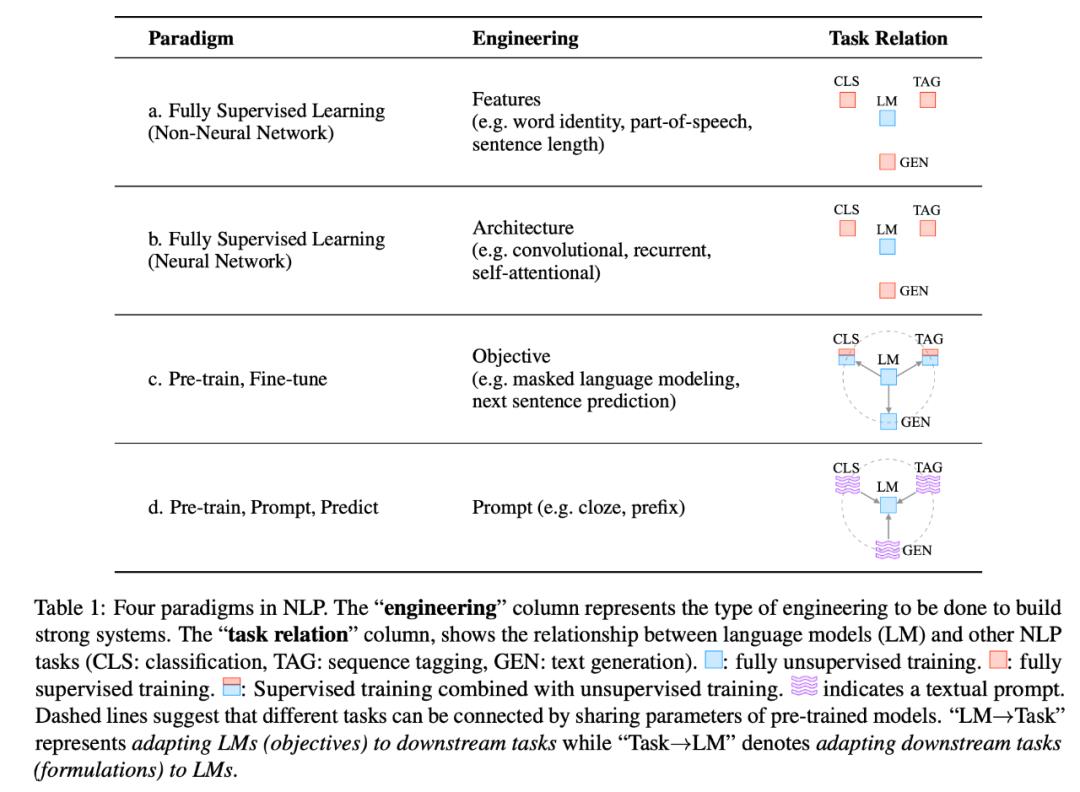
NLP 的两次巨变
第一次巨变是“pre-train and fine-tune” 范式,第二次巨变则是目前的 “pre-train, prompt, and predict”。如图,是 NLP 中的四种范式。
Prompting 的正式描述
-
prompt 添加:通过 将输入文本转化为一个 prompt -
回答搜索:找到能将 LM 分数最大化的得分最高的文本 -
回答mapping:通过得分最高的回答 ,得到得分最高的输出
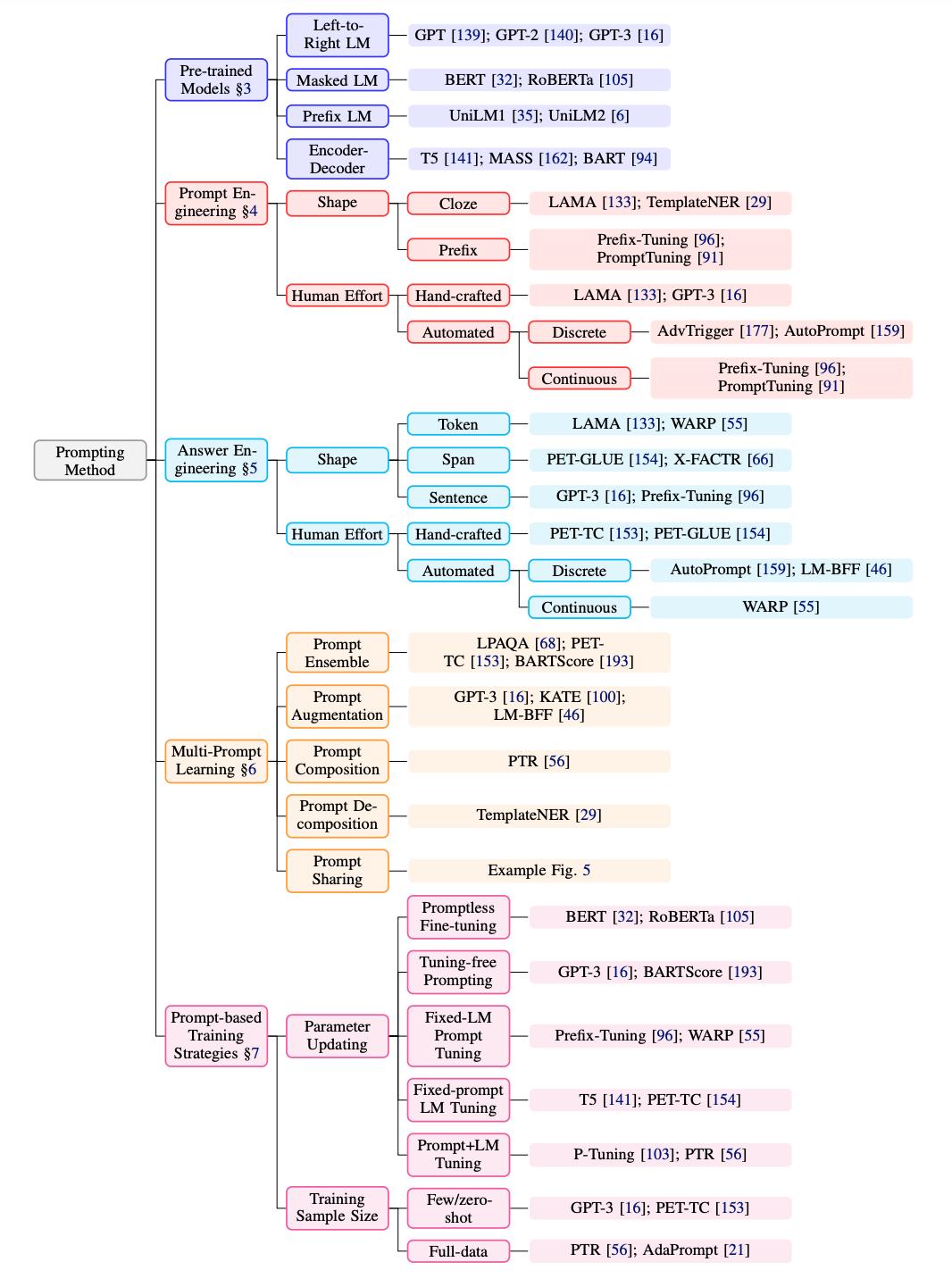
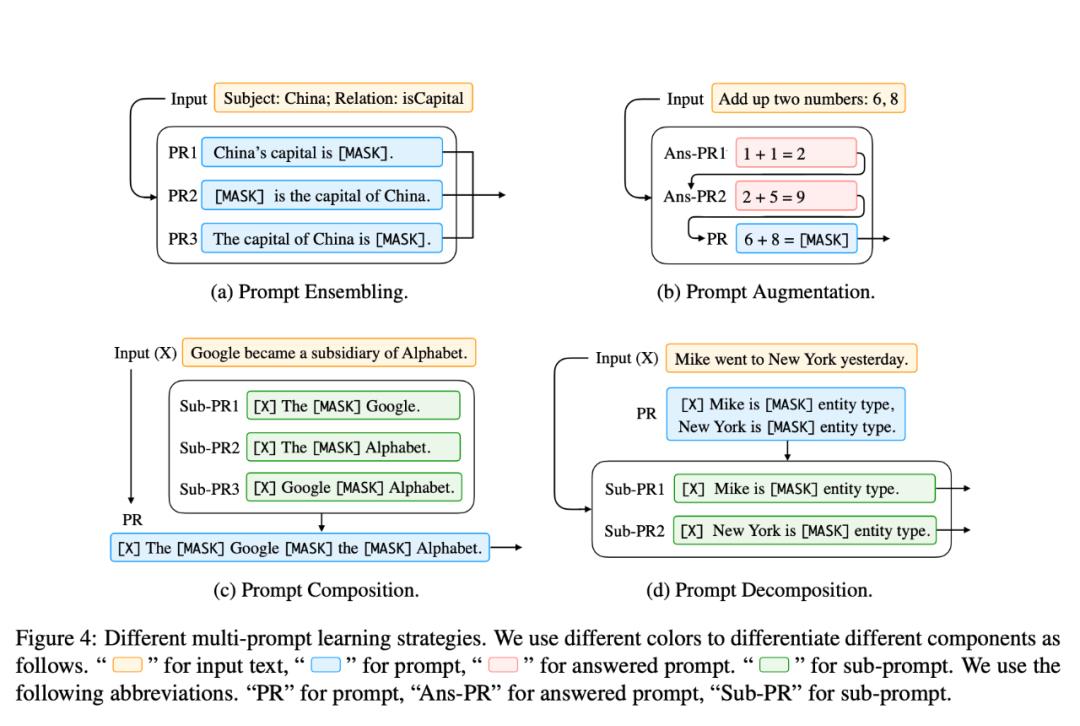
如图所示,是 Prompt 方法的一些术语和符号表示。

Prompting 设计过程中的注意事项
有了基本的数学公式后,还需要了解一些基本设计注意事项:
-
预训练模型选择:有多种预训练 LM 可用于计算 。对于 Prompt 方法在效用维度存在差异。 -
Prompt 工程:鉴于 prompt 指定了任务,选择合适的 prompt 不仅对准确性有很大影响,而且对模型首先执行的任务也有很大影响; -
回答工程:根据任务的不同,我们可能希望设计不同的 Z,可能与映射函数一起设计; -
扩展范式:如上所述,上述等式仅代表已被提议用于执行此类 prompt 的各种基础框架中最简单的。还有一些扩展这种基本范式以进一步提高结果或适用性的方法; -
基于 prompt 的训练策略:有训练参数的方法,包括 prompt 和 LM。

总结
在本文中,作者总结并分析了统计自然语言处理技术发展中的几个范式,并认为 Prompt-based 学习是一种很有前途的新范式,它可能代表着我们看待 NLP 方式的另一个重大变化。
作者在原文中列出了详细的表格、实例甚至 timeline 以帮助读者更加直观地了解这一新范式,非常值得阅读原文。
特别鸣谢
感谢 TCCI 天桥脑科学研究院对于 PaperWeekly 的支持。TCCI 关注大脑探知、大脑功能和大脑健康。
更多阅读

#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
以上是关于大语言模型的最新研究方向综述的主要内容,如果未能解决你的问题,请参考以下文章