Linux 内核裁剪框架初探
Posted 半吊子全栈工匠
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Linux 内核裁剪框架初探相关的知识,希望对你有一定的参考价值。
大约是在2000年的时候,老码农还很年轻,当时希望将Linux 作为手机的操作系统, 于是才有了进行内核裁剪的想法并辅助实践,效果尚好,已经能在PDA上执行手机的功能了。一晃20多年过去了,Linux 已经有了太大的变化,内核裁剪的技术和方式也有了较大的不同。
Linux 的内核裁剪是为了减少目标应用中不需要的内核代码,在安全性和高性能(快速启动时间和减少内存占用)方面有着显著的好处。但是,现有的内核裁剪技术有其局限性,有没有内核裁剪的框架化方法呢?

1. 关于内核裁剪
近年来,Linux操作系统在复杂性和规模上都在增长。然而,一个应用程序通常只需要一部分 OS 功能,众多的应用需求导致了Linux内核的膨胀。操作系统的内核膨胀同样导致了安全性隐患、启动时间变长和内存使用的增加。
随着服务化和微服务的流行,进一步提出了对内核裁剪的需求。在这些场景中,虚拟机运行小型应用程序,每个应用程序往往是“微型”的,内核占用较小,一些虚拟化技术要为目标应用程序提供最简单的 Linux 内核。
鉴于操作系统的复杂性,通过手工挑选内核特性来裁剪内核有些不切实际。例如,Linux 有超过14,000+个配置选项(截至 v4.14) ,每年都会引入数百个新选项。内核配置器(例如 KConfig)只提供用于选择配置选项的用户界面。鉴于糟糕的可用性和文档的不完整性,用户很难选择最小且实用的内核配置。
现有的内核裁剪技术一般遵循三个步骤:
运行目标应用程序的工作负载并跟踪在应用程序运行期间执行的内核代码;
分析跟踪并确定目标应用程序所需的内核代码,
组装一个只包含应用程序所需代码的内核裁剪。
配置驱动的是内核裁剪的一般方法,大多数现有的工具使用配置驱动技术,因为它们是为数不多的可以产生稳定内核的技术之一。配置驱动的内核重载根据功能特性减少了内核代码,配置选项对应于内核的功能,裁剪后的内核只包含用于支持目标应用程序工作负载的功能。
然而,尽管内核裁剪技术在安全性和性能方面非常吸引人,但在实践中并没有得到广泛采用。这并不是因为缺乏需求,实际上,许多云供应商手工编写 Linux 内核来减少代码,但一般不如内核裁剪技术有效。
2. 现有内核裁剪技术的限制
现有内核裁剪技术有五个主要的局限性。
在引导阶段不可见。现有技术只能在内核引导后启动,依赖于 ftrace,因此无法观察在引导阶段加载了哪些内核代码。如果内核中缺少关键模块,内核通常无法启动,而大量的内核功能特性只能通过观察引导阶段来捕获。此外,关于性能和安全性同样只在引导时加载(例如,用于多核支持的 CONFIGSCHEDMC 和 CONFIGSECURITYNETWORK) ,导致了性能和安全性降低。
缺乏对应用程序部署的快速支持。使用现有的工具,面向内核裁剪来部署一个新的应用程序需要完成跟踪、分析和组装这三个步骤。这个过程非常耗时,有可能需要几个小时甚至几天,阻碍了应用部署的敏捷性。
粒度较粗。使用ftrace 只能在函数级跟踪内核代码,粒度太粗,无法跟踪影响函数内代码的配置选项。
覆盖不完全。因为使用动态跟踪,所以需要应用程序工作负载来驱动内核的代码执行,以最大限度地扩大覆盖范围。然而,基准测试覆盖是具有挑战性的,而且,如果应用程序有在跟踪期间没有观察到的内核代码,那么裁剪后的内核可能会在运行时崩溃。
没有区分执行依赖,可能存在冗余。即使实际上可能并不需要执行的代码,也可能包含在了内核功能特性中,例如,可能初始化了第二个文件系统。
前三个限制是可以克服的,可以通过改进设计和工具加以解决,而后两个限制是在所难免,需要在具体的技术之外作出努力。
3. Linux 的内核配置
3.1配置选项
内核配置由一组配置选项组成。一个内核模块可以有多个选项,每个选项都控制哪些代码将包含在最终的内核二进制文件中。
配置选项控制内核代码的不同粒度,例如由 C 预处理器实现的语句和函数,以及基于 Makefile 实现的对象文件。C 预处理器根据 #ifdef/#ifndef 选择代码块,配置选项用作宏定义,以确定是否在编译后的内核中包含这样条件的代码块,可以是语句粒度或者函数粒度。Makefile 用于确定是否在编译后的内核中包含某些对象文件,例如, CONFIG_CACHEFILES 就是 Makefile 中的配置选项。
语句级配置选项不能通过现有内核裁剪工具所使用的函数级跟踪来识别。事实上,Linux 4.14 中30%左右 的 C 预处理器是语句级选项。
随着内核代码和功能特性的快速增长,内核中的配置选项数量也在迅速增加,以 Linux内核3.0以上版本都有1万多个配置选项。
3.2. 配置语言
Linux内核使用KConfig 配置语言来指示编译器在编译后的内核中包含哪些代码,允许定义配置选项以及它们之间的依赖关系。
KConfig 中配置选项的值可能是 bool、 tristate 或 constant。bool 意味着代码要么被静态编译成内核二进制文件,要么被排除在外,而 tristate 允许代码被编译成一个可载入核心模组,即一个可以在运行时加载的独立对象。constant可以为内核代码变量提供字符串或数值。一个选项可以依赖于另一个选项,KConfig 使用了一个递归过程,通过递归选择和取消依赖项。最终的内核配置具有有效的依赖关系,但可能与用户输入不同。
3.3. 配置模板
Linux 内核附带了许多手工制作的配置模板。但是,由于配置模板的硬编码特性并且需要人工干预,它们不能适应不同的硬件平台,也不了解应用程序的需求。例如,由 tinyconfig 构建的内核不能在标准硬件上启动,更不用说支持其他应用了。有些工具将 localmodconfig 视为最小化的配置,但是,localmodconfig 与静态配置模板具有相同的局限性,它不会启动控制语句级或函数级 C 预处理器的配置选项,也不会处理可加载的内核模块。
kvmconfig 和 xenconfig 模板是为在 KVM 和 Xen 上运行的内核而定制的。它们提供例如底层虚拟化和硬件环境的领域知识。
3.4. 云中的 Linux 内核配置
Linux 是云服务中占主导地位的操作系统内核,云供应商都在一定程度上放弃了普通的 Linux 内核。云厂商的定制通常是通过直接删除可加载的内核模块来完成的,手工修剪内核模块二进制文件的问题是可能会违反依赖关系。重要的是,基于应用程序需求可以进一步裁剪内核。例如,Amazon FireCracker 内核是一个专门用于函数即服务的微型虚拟机,使用 HTTPD 作为目标应用程序,在保证功能和性能提升的同时,使内核裁剪实现了更大程度的最小化。
4. 内核裁剪的思考
针对局限一,是否可以使用来自 QEMU 的指令级跟踪来实现引导阶段的可见性呢?这样,就可以跟踪内核代码并将其映射到内核配置选项。既然引导阶段对于生成可引导内核至关重要,使用 hypervisor 提供的跟踪特性来获得端到端的可观察性并生成稳定的内核。
针对局限二,根据在NLP深度学习中的经验,可以使用离线和在线结合的方法,给定一组目标应用程序,可以直接离线生成的App 配置,再和基线配置组合成完整的内核配置,从而生成一个裁剪后的内核。这种可组合性能够通过重用应用配置和以前构建的文件(例如内核模块)来增量地构建新内核。如果目标应用程序的配置已知,就可以在几十秒内完成内核裁剪。
针对局限三,使用指令级跟踪可以解决控制函数内部功能特性的内核配置选项,指令级跟踪的开销对于运行测试套件和性能基准来说是可以接受的。
针对局限四,使用基于动态跟踪的一个基本限制是测试套件和基准的不完善,许多开源应用程序测试套件的代码覆盖率较低。组合不同的工作负载来驱动应用程序可以在一定程度上减轻这种限制。
针对局限五,通过删除在基线内核中执行但在实际部署运行时不需要的内核模块,可以使用特定于领域的信息进一步加载内核。以 Xen 和 KVM 为例,可以基于 xenconfig 和 kvmconfig 配置模板进一步减少内核大小。面向应用程序的内核裁剪可以进一步减少内核大小甚至广泛地定制的内核代码。
5 内核裁剪框架初探
内核裁剪框架的原理没有变,仍然是跟踪目标应用工作负载的内核占用情况,以确定所需的内核选项。
5.1 内核裁剪框架的核心特性
内核裁剪框架大概可以具备以下特性:
端到端的可见性。利用虚拟机监控程序的可见性来实现端到端的观察,可以跟踪内核引导阶段和应用程序工作负载,可以尝试在QEMU 的基础上建造Linux内核的裁剪框架。
可组合性。一个核心思想是通过将内核配置划分为若干组配置集,使内核配置可以组合,用于在给定的部署环境上引导内核,也可以用于目标应用程序所需的配置选项。配置集分为两种:基线配置和应用配置。基线配置不一定是在特定硬件上引导所需的最小配置集,而是在引导阶段跟踪的一组配置选项。基线配置可以与一个或多个应用配置组合在一起,以生成最终的内核配置。
可重用性。基线配置和应用配置都可以存储在数据库中,并且只要部署环境和应用程序的二进制文件不变就可以重用。这种可重用性避免了重复跟踪工作负载的运行,使得配置集的创建成为一次性的工作。
支持快速应用部署。给定一个部署环境和目标应用程序,内核裁剪框架可以有效地检索基线配置和 应用配置,并将它们组合成所需的内核配置,然后使用生成的配置构建废弃的内核。
细粒度配置跟踪,基于程序计数器的跟踪来识别基于低级代码模式的配置选项。
5.2 内核裁剪框架的体系结构
内核裁剪框架应该同时具备离/在线系统,体系结构如下图所示:
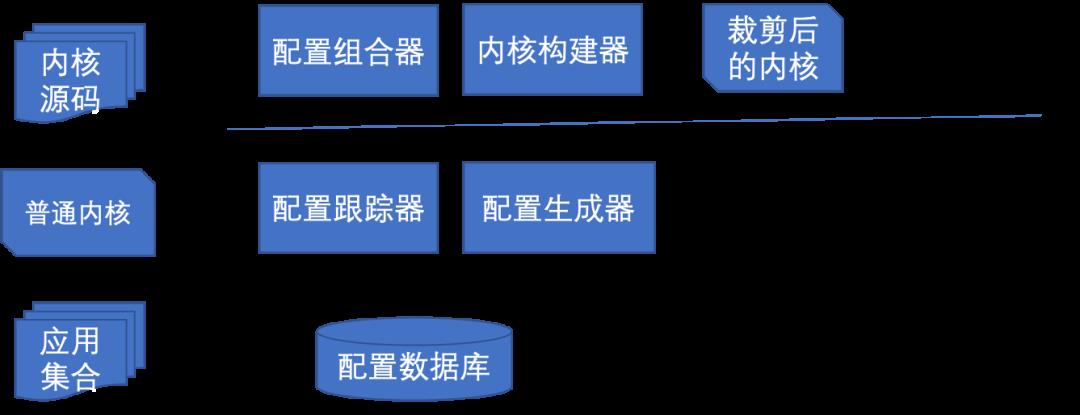
通过离线系统, 配置跟踪器用于跟踪部署环境和应用程序所需的配置选项,并记录下来。配置生成器将这些选项处理成基线配置和应用配置选项,并将它们存储在配置数据库中。
通过在线系统,配置组合器使用基线配置和应用配置来生成目标内核配置,然后,内核构建器生成裁剪后的Linux内核.
5.3 内核裁剪框架的实现可行性
配置跟踪
内核裁剪框架的配置跟踪器在目标应用程序驱动的内核执行期间跟踪配置选项,使用 PC 寄存器捕获正在执行的指令的地址。为了确保被跟踪的 PC 属于目标应用程序,而不是其他进程(例如,后台服务) ,可以使用了一个定制的 init 脚本,该脚本不启动任何其他应用程序,只挂载文件系统/tmp、/proc 和/sys ,启用网络接口(lo 和 eth0) ,最后在内核引导后直接启动应用程序。
同时,可能需要禁用内核位址空间配置随机载入 ,以便能够正确地将地址映射到源代码,但在裁剪后的内核中仍然可以使用。然后,将 PC 映射到源代码语句。可加载的内核模块需要额外的处理,可以使用/proc/module 获取每个加载的内核模块的起始地址,将这些 PC 映射到内核模块二进制中的语句。另一种方法是利用 localmodconfig,但是,localmodconfig 只提供模块粒度级别的信息。
最后,将语句归属于配置。对于基于 C 预处理器的模式 ,分析 C 源文件以提取预处理器指令,然后检查这些指令中的语句是否被执行。对于基于 Makefile 的模式 ,确定是否应该在对象文件的粒度上选择配置选项。例如,如果使用了任何相应的文件(bind.o、 achefiles.o 或 daemon.o) ,则需要选择 CONFIG_CACHEFILES。
配置生成
基线配置和应用配置是在离线系统中生成的。如何判断启动阶段结束呢?可以使用 mmap 将一个空的存根函数映射到一个预定义地址段,上述的初始化脚本在运行目标应用程序之前调用调用存根函数,因此,可能根据 PC 跟踪中的预定义地址来识别引导阶段的结束。
内核裁剪框架从应用程序中获取配置选项,并过滤掉在引导阶段观察到的与硬件相关的选项。这些硬件特性是根据它们在内核源代码中的位置定义的。不排除这样的可能性,即与硬件相关的选项只能在应用程序执行期间观察到,例如,它根据需要加载新的设备驱动程序。
配置组装
将基线配置与一个或多个应用配置组合在一起,可以以生成用于构建内核的最终配置。首先,将所有 配置选项并入一个初始配置,然后使用SAT求解器解决它们之间的依赖关系。尝试将配置依赖性建模为一个布尔可满足性问题,有效配置是指满足配置选项之间所有指定依赖性的配置。因为 KConfig 并不确保包含所有选定的选项,而是取消选择未满足的依赖项,所以才要基于 SAT 求解器对内核配置进行建模。
内核构建
使用于Linux的KBuild基于组装后的配置选项构建裁剪内核,利用现代make的增量构建可以优化构建时间,也可以缓存以前的构建结果(例如,目标文件和内核模块) ,以避免冗余的编译和链接。当发生配置更改时,只有对配置选项进行更改的模块重新构建,而其他文件可以重用。
6. 小结
由于操作系统内核的不稳定性、时效性较差、完整性问题以及需要人工干预等原因,Linux内核裁剪技术没有得到广泛的应用。了解了现有技术的局限性,尝试提出一个Linux内核裁剪框架,或许可以解决这些问题。
【关联阅读】
 暑期编程PK赛
暑期编程PK赛
 得CSDN机械键盘等精美礼品!
得CSDN机械键盘等精美礼品!
以上是关于Linux 内核裁剪框架初探的主要内容,如果未能解决你的问题,请参考以下文章