使用Tesseract和OpenCV构建自动收据扫描仪
Posted 程序媛一枚~
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了使用Tesseract和OpenCV构建自动收据扫描仪相关的知识,希望对你有一定的参考价值。
使用Tesseract和OpenCV构建自动收据扫描仪
这篇博客将介绍如何使用Tesseract和OpenCV构建自动收据扫描仪。将使用OpenCV构建系统的实际图像处理组件,包括:
- 检测图像中的收据(边缘检测、轮廓检测、基于弧长和近似的轮廓滤波)
- 找到收据的四个角点
- 应用透视变换获得收据的自顶向下鸟瞰视图
- 使用Tesseract逐行OCR收据
- 查看如何选择正确的Tesseract页面分割模式(PSM Page Segmentation Mode)以获得更好的结果的真实应用程序
最重要的是通过Tesseract使用–psm 4,逐行从收据中提取每个项目,包括项目名称和该特定项目的成本。
正常ocr收据的限制是需要:收据和背景之间的充分对比,收据的所有四个角在图像中可见,有任何一个不成立将无法找到收据并ocr。
1. 效果图
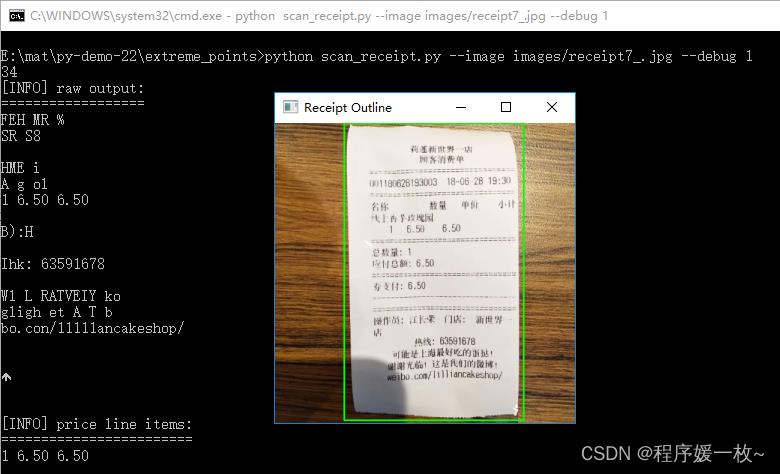
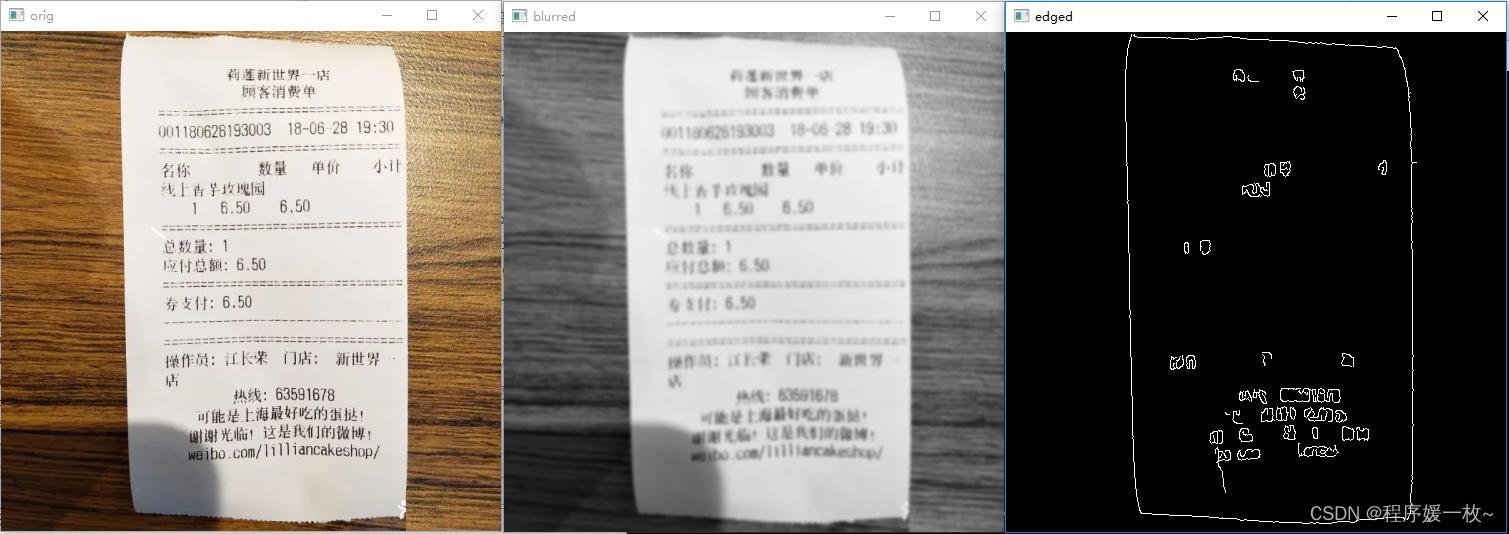
过程图1——原始图 VS 高斯平滑图 VS 边缘图如下:
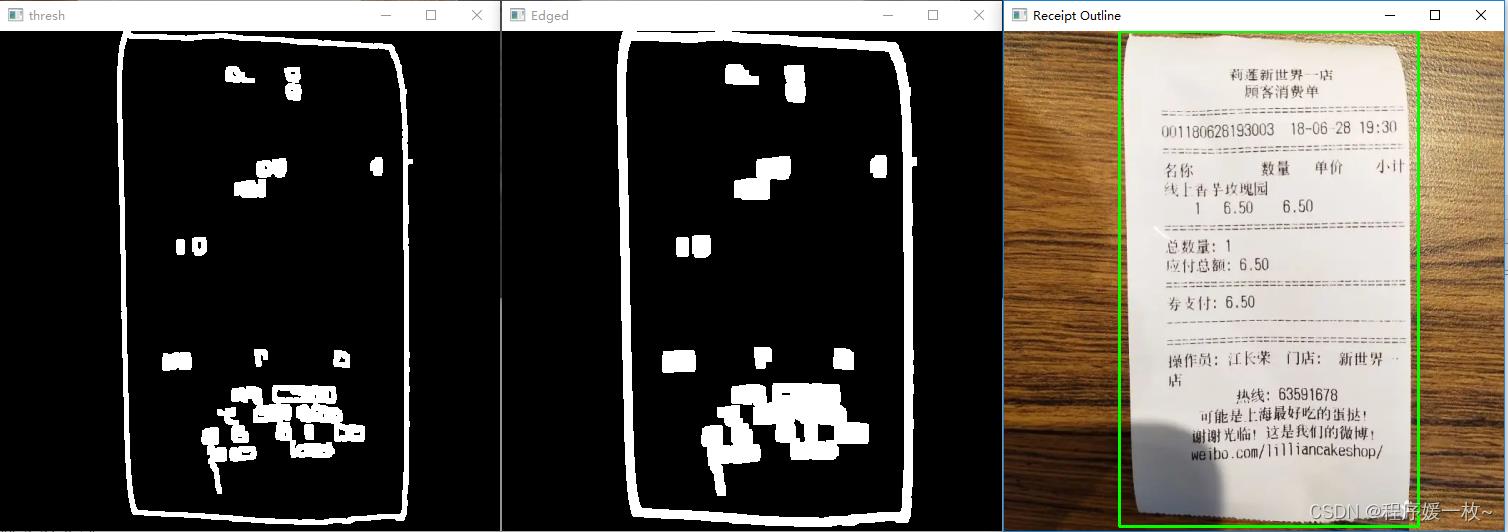
过程图2——阈值化图 VS 腐蚀膨胀后边缘图 VS 收据外绘制轮廓图如下:
原始图下绘制收据外轮廓线 及 ocr效果如下:
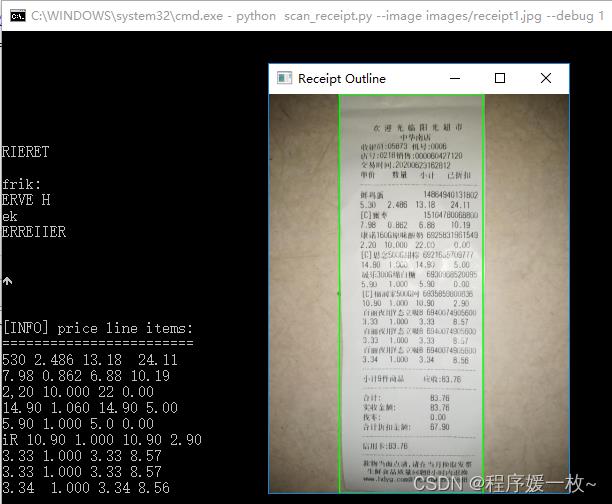
原始图2如下:

识别商品及价格2如下:
输出中还有一堆其他“噪音”,包括商店的名称、地址、电话号码等。如何解析这些信息,只留下商品及其价格?答案是使用正则表达式。在具有类似于价格的数值的行上进行过滤。
2.原理
pip install opencv-contrib-python
3. 源码
# 使用Python,OpenCV实现收据扫描仪
# USAGE
# python scan_receipt.py --image images/receipt1.jpg
# python scan_receipt.py --image images/receipt7_.jpg --debug 1
# 导入必要的包
import argparse
import re # 正则表达式
import cv2
import imutils
import numpy as np
import pytesseract
from imutils.perspective import four_point_transform
# 构建命令行参数及解析
# --image 收据图片
# --debug 一个整数值,用于指示是否要通过管道显示调试图像,包括边缘检测、接收检测等的输出。
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=False, default="images/receipt1.jpg",
help="path to input receipt image")
ap.add_argument("-d", "--debug", type=int, default=-1,
help="whether or not we are visualizing each step of the pipeline")
args = vars(ap.parse_args())
# 从磁盘加载图像,计算旧图像与新图像的比率
orig = cv2.imread(args["image"])
image = orig.copy()
image = imutils.resize(image, width=500)
cv2.imshow("orig", image)
ratio = orig.shape[1] / float(image.shape[1])
# 转换图像为灰度图
# 将图像转换为灰度,使用5x5高斯核模糊图像(以减少噪声),然后使用Canny边缘检测器应用边缘检测来执行边缘检测。
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
blurred = cv2.GaussianBlur(gray, (7, 7), 0)
cv2.imshow("blurred", blurred)
# cv2.waitKey(0)
edged = cv2.Canny(blurred, 70, 230)
cv2.imshow("edged", edged)
cv2.waitKey(0)
thresh = cv2.threshold(blurred, 200, 255, cv2.THRESH_BINARY_INV)[1]
# 图像中还存在一些噪点(即小斑点),可通过执行一系列腐蚀和扩张来对其进行清理:
# 应用一系列腐蚀、膨胀来消除小的噪点
thresh = cv2.erode(thresh, None, iterations=2)
edged = cv2.dilate(edged, None, iterations=2)
cv2.imshow("thresh", edged)
cv2.waitKey(0)
edged = cv2.erode(edged, None, iterations=2)
edged = cv2.dilate(edged, None, iterations=4)
# 检查是否展示边缘检测结果
if args["debug"] > 0:
cv2.imshow("Input", image)
cv2.imshow("Edged", edged)
cv2.waitKey(0)
# 寻找边缘图中的轮廓,然后对轮廓面积降序排列
cnts = cv2.findContours(edged.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
cnts = imutils.grab_contours(cnts)
cnts = sorted(cnts, key=cv2.contourArea, reverse=True)
print(len(cnts))
# 初始化轮廓与收据边缘线对应
receiptCnt = None
# # res = image.copy()
# # 遍历轮廓
# for c in cnts:
# res = image.copy()
# # 通过减少点的数量来近似轮廓,从而简化形状
# peri = cv2.arcLength(c, True)
# approx = cv2.approxPolyDP(c, 0.03 * peri, True)
# color = np.random.randint(0, high=256, size=(3,)).tolist()
# cv2.drawContours(res, [c], -1, color, 2)
# cv2.imshow("contours", res)
# # cv2.drawContours(res, [c], -1, (0, 255, 255), 2)
# cv2.waitKey(0)
# # 遍历轮廓
# for i, c in enumerate(cnts):
# # 通过减少点的数量来近似轮廓,从而简化形状
# peri = cv2.arcLength(c, True)
# approx = cv2.approxPolyDP(c, 0.02 * peri, True)
# print(i, len(approx), str(cv2.contourArea(c)))
#
# # 如果近似轮廓有4个点,则已找到了收据的轮廓
# if len(approx) == 4:
# receiptCnt = approx
# break
#
cnt = max(cnts, key=cv2.contourArea)
rect = cv2.minAreaRect(cnt)
box = cv2.boxPoints(rect)
box = np.int0(box)
# box = [[150, 0], [150, 853], [456, 853], [456, 0]] # receipt1.jpg用到
box = np.array(box)
receiptCnt = box
# 如果没找到轮廓,则抛出异常
if receiptCnt is None:
raise Exception(("Could not find receipt outline. "
"Try debugging your edge detection and contour steps."))
# 检查是否调试状态,绘制收据轮廓并显示到屏幕上
if args["debug"] > 0:
output = image.copy()
cv2.drawContours(output, [receiptCnt], -1, (0, 255, 0), 2)
cv2.imshow("Receipt Outline", imutils.resize(output,width=300))
cv2.waitKey(0)
# 应用4点透视变换以获取鸟瞰图
# 将变换应用于更高分辨率的原始图像-为什么?首先图像变量已经应用了边缘检测和轮廓处理。使用透视变换图像,然后进行OCR,不会产生正确的结果;
receipt = four_point_transform(orig, receiptCnt.reshape(4, 2) * ratio)
# 展示转换后的图像
cv2.imshow("Receipt Transform", imutils.resize(receipt, width=500))
cv2.waitKey(0)
# 通过假设列数据,将OCR应用于收据图像,确保文本跨行连接*(此外,对于自己的图像进行额外处理以进行清理图像,包括大小调整、阈值设置等
options = "--psm 4"
text = pytesseract.image_to_string(
image=cv2.cvtColor(receipt, cv2.COLOR_BGR2RGB),
# lang='chi_sim',# 识别中文,字母,数字
config=options)
# 展示OCR进程的原始输出使用
# --psm 4可以逐行OCR收据。每行将包括项目名称和项目价格。
print("[INFO] raw output:")
print("==================")
print(text)
print("\\n")
# Tesseract不知道收据上的物品是什么,而只知道杂货店的名称、地址、电话号码以及你通常在收据上找到的所有其他信息。
# 这就提出了一个问题——如何解析出不需要的信息,只剩下商品名称和价格?答案是利用正则表达式
# 定义正则表达式,匹配每一行的价格
pricePattern = r'([0-9]+\\.[0-9]+)'
# 显示包含价格的条目
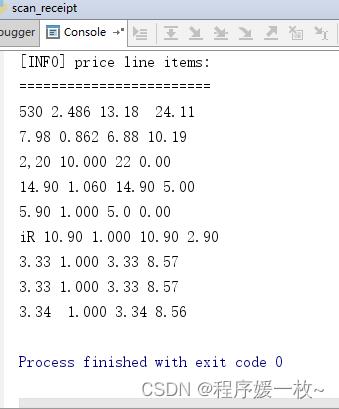
print("[INFO] price line items:")
print("========================")
# 从OCR收据的文本中逐行进行正则匹配
for row in text.split("\\n"):
# 检查是否匹配当前行
if re.search(pricePattern, row) is not None:
print(row)
cv2.waitKey(0)
cv2.destroyAllWindows()
参考
- https://pyimagesearch.com/2021/10/27/automatically-ocring-receipts-and-scans/
- https://realpython.com/regex-python/
以上是关于使用Tesseract和OpenCV构建自动收据扫描仪的主要内容,如果未能解决你的问题,请参考以下文章