深入解读 Flink CDC 增量快照框架
Posted 学而知之@
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深入解读 Flink CDC 增量快照框架相关的知识,希望对你有一定的参考价值。
导读:随着大数据的迅猛发展,企业越来越重视数据的价值,数据采集工具也在不断改进,实时采集工具也在由长链路向短链路发展,今天和大家分享一下 Flink CDC 技术。在国内不断内卷的大环境下,技术更新迭代的速度也令人瞠目结舌,一个技术生态的形成也在各种场景的催生和验证下得到了快速的发展,相信Flink CDC会快速的成为主流架构。
今天的介绍会围绕下面四点展开:
Flink CDC 简介
Flink CDC 增量快照算法
Flink CDC 增量快照框架
社区发展规划
01
Flink CDC 简介
首先整体介绍一下 Flink CDC 技术。
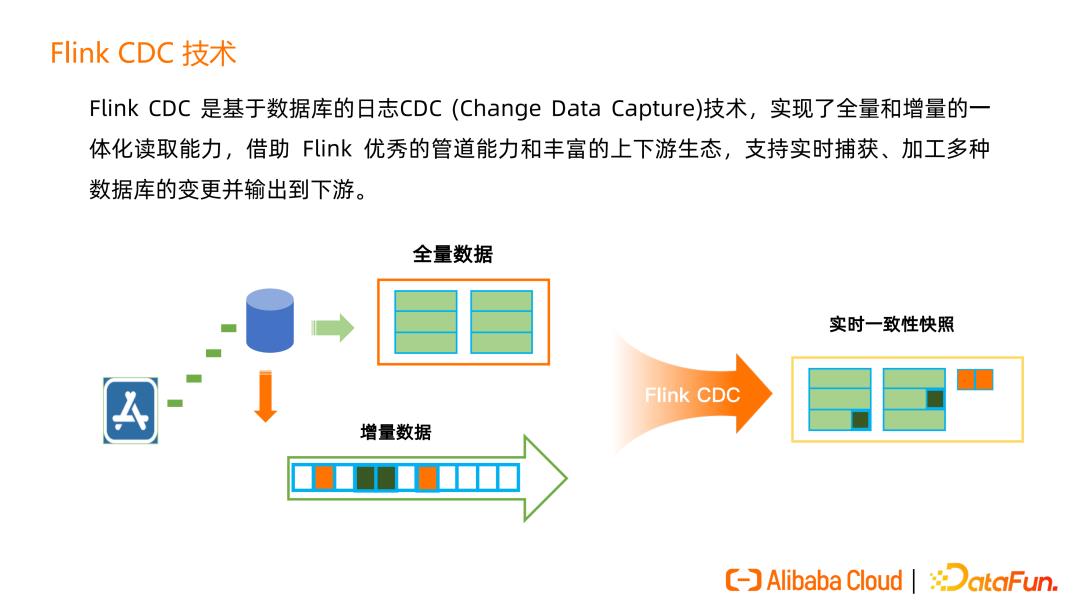
Flink CDC 是基于数据库的日志 CDC(ChangeDataCapture)技术,实现了全量和增量的一体化读取能力。全量就是经常说的历史数据,增量就是实时的数据,不断的在写入。通过 Flink CDC,用户在Flink中看到这张表就是该表的最新一个一致性快照。这个过程中,不用去处理全量跟增量数据之间的衔接和合并,这就是 Flink CDC 的全增量一体化读取能力。
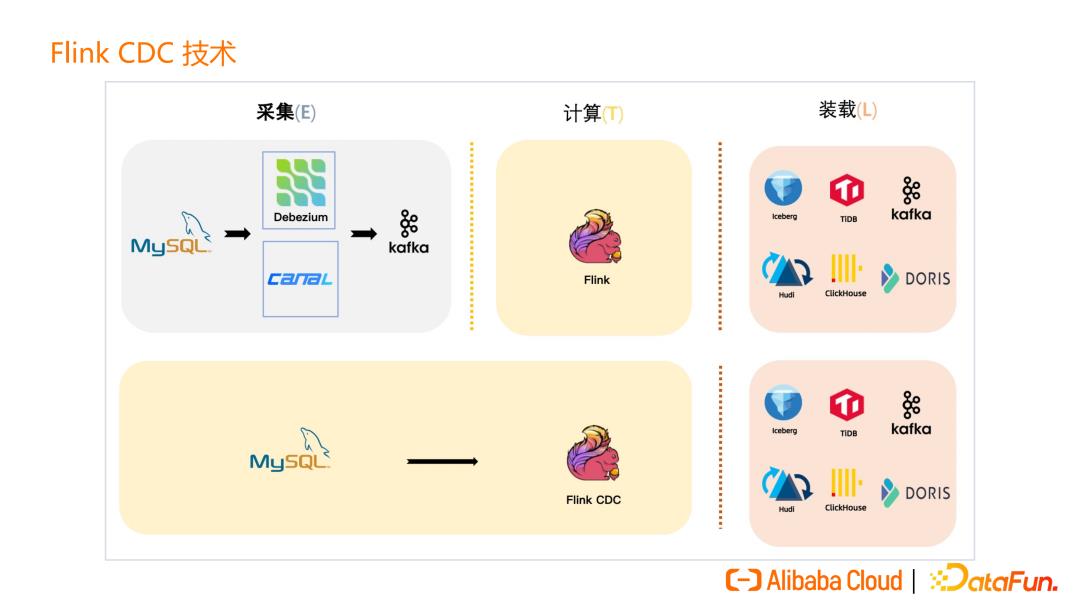
有了 Flink CDC 技术,我们一些传统的 ETL 分析链路可以大大简化。
在传统的采集方式下,首先需要借助 Canal、Debezium 等技术把实时变更的日志写入到 Kafka 等消息队列,然后通过 Flink 等计算引擎读取最新数据与历史数据进行合并从而获得完整的数据,然后再写入下游。
在引入 Flink CDC 技术后,数据链路可以大大缩短,Flink CDC 可以直接读取上游数据,借助 Flink 优秀的管道能力和生态来完成之前的数据采集、计算和写入。
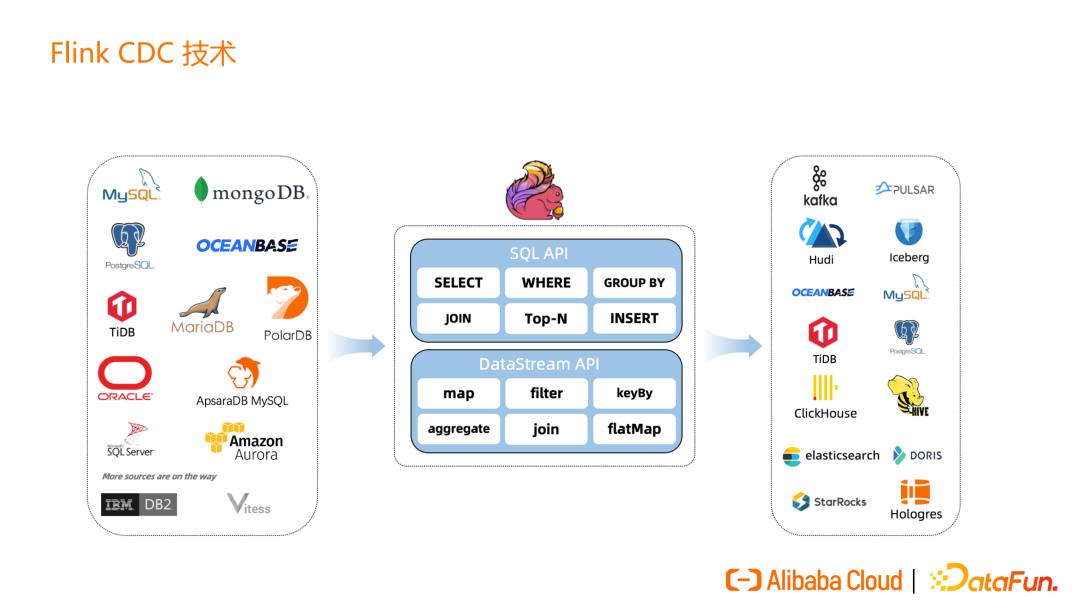
在 Flink CDC 现有生态中,接入端中主流的数据库基本都支持,在处理过程中支持SQL API 和 DataStreamAPI 两种方式的处理,SQLAPI 处理的优势是操作简单,用户门槛低,DataStreamAPI 的优势是可扩展能力强,可以通过自定义开发实现一些定制功能。
02
Flink CDC 增量快照算法
1. Flink CDC1.0 痛点

在 Flink CDC 1.0 中有三大痛点,第一个是一致性通过加锁保证,对业务不友好;第二个是不支持水平扩展,在全量读取阶段只能单并发,如果表特别大,那么耗时就会很长;第三个是全量读取阶段不支持 checkpoint,如果读取失败,则只能从开始再次读取,耗时也会很长。
2. Flink CDC1.0 锁分析

Flink CDC 1.0 实现中,底层封装了 Debezium,读取数据的时候就分为两个阶段,第一个是全量读取阶段,第二个是增量读取阶段。在全量读取阶段和增量阶段衔接时是通过加锁来保证数据一致性。
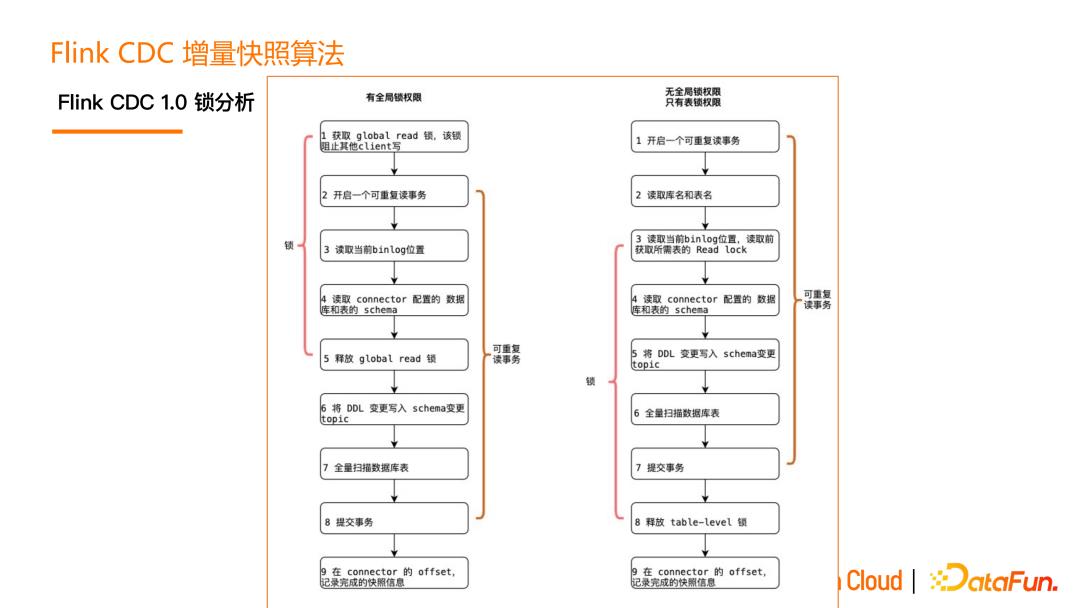
读取 mysql 的加锁流程如上图所示,对于不同的数据库,权限也不同,有的是全局锁,有的是表锁,且它们的流程也不相同。

但加锁是非常危险的操作,以 MySQL 的加锁为例,MySQL 的加锁时间是不确定的,在某些极端情况下,会把数据库 hang住,影响数据库上承载的线上业务。
3. Flink CDC2.0 锁设计目标

Flink CDC 2.0 的设计主要是为了解决 Flink CDC 1.0 的痛点问题,即全量读取阶段使用无锁读取,支持高并发的水平扩展,可断点续传解决失败重做问题。
4. Flink CDC2.0 设计方案

Flink CDC 2.0 主要是借鉴 DBLog 算法的一个变种同时结合 FLIP-27 Source 实现。
5. DBLog 算法原理
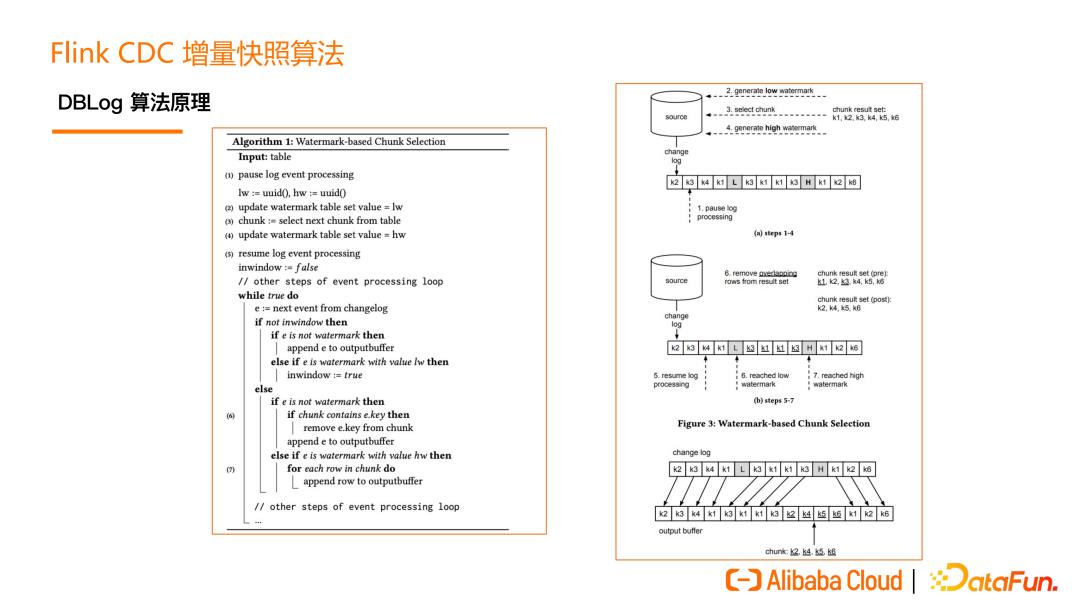
DBLog 这个算法的原理分成两个部分,第一部分是分 chunk,第二部分是读 chunk。分 chunk 就是把一张表分为多个 chunk(桶/片)。我可以把这些 chunk 分发给不同的并发的 task 去做。例如:有 reader1 和 reader2,不同的 reader 负责读不同的 chunk。其实只要保证每个 reader 读的那个 chunk 是完整的,也能跟最新的 Binlog 能够匹配在一起就可以了。在读 chunk 的过程中,会同时读属于这个 chunk的历史数据,也会读这个 chunk 期间发生的 Binlog 事件,然后来做一个 normalize。
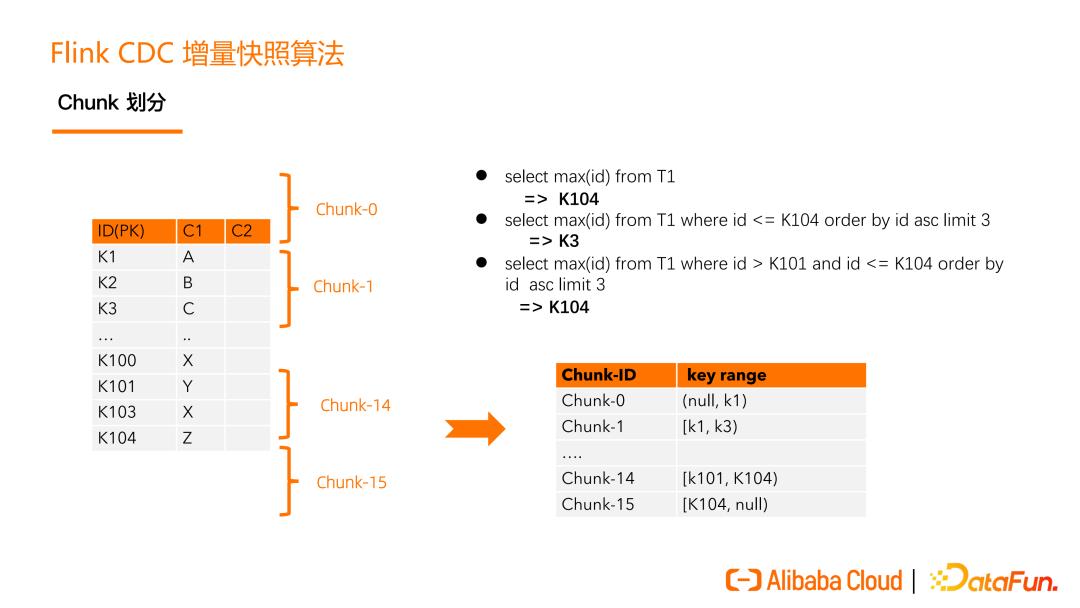
首先是 chunk 的划分。一张表,它的 ID 字段是主键 PK。通过 query 能够知道最大的 PK 也能知道最小的 PK。然后根据最大最小的 PK 设定一个步长,那么就能把这个表分成一些 chunk。每个 chunk 是一个左闭右开的区间,这样可以实现 chunk 的无缝衔接。第一个 chunk 和最后一个 chunk 最后一个字段,是一个正无穷和负无穷的表示, 即所有小于 k1 的 key 由第一个 chunk 去读,所有大于 K104 的 key 由最后一个chunk去读。

chunk 的读取,首先有一个 open 打点的过程,还有一个 close 打点的过程。例如,读属于这个 chunk1 的所有数据时,橘色的 K1 到 K7 是这些全量数据。橘黄色里面有下划线的数据,是在读期间这些 Binlog 在做改变。比如 K2 就是一条 update,从 100 变成 108,K3 是一条 delete。K2 后面又变成 119。还有 K5 也是一个update。在 K2、K3、K5 做标记,说明它们已经不是最新的数据了,需要从 Binlog 里面读出来,做一个 merge 获取最新的数据, 最后读出来的就是在 close 位点时刻的最新数据。最后的效果就是,将 update 最新的数据最终输出,将 delete 的数据如 K3 不输出。所以在 chunk1 读完的时候,输出的数据是 K0、K2、K4、K5、K6、K7 这些数据,这些数据也是在 close 位点时数据库中该 chunk 的数据。
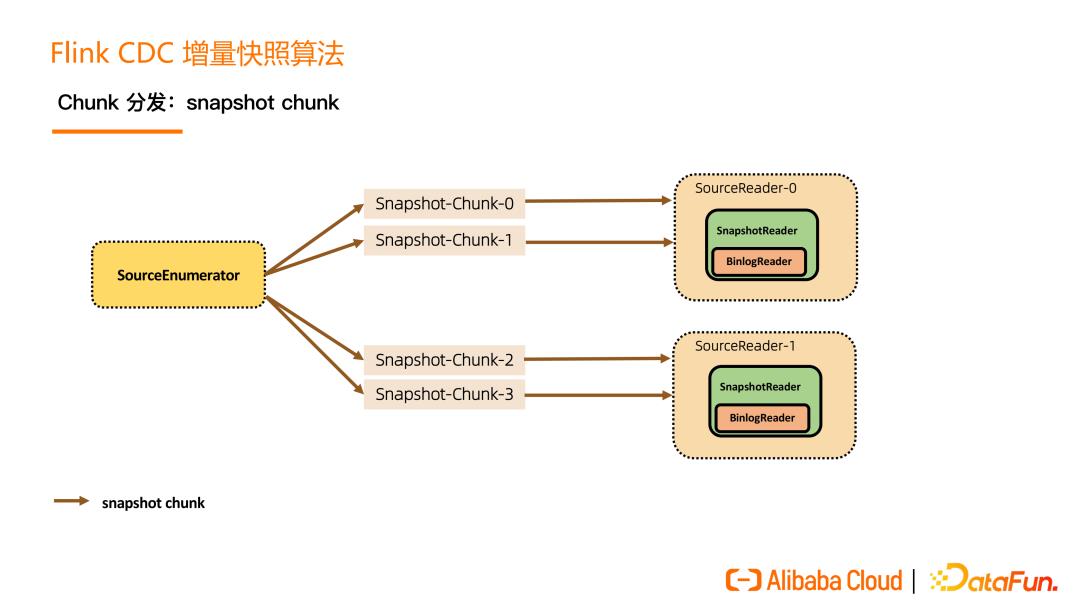
接下来是 chunk 的分发。一张表切成了 N 个 chunk 后,SourceEnumerator 会将这些 chunk 分给一些 SourceReader 并行地读取,并行读是用户可以配置的,这就是水平扩展能力。
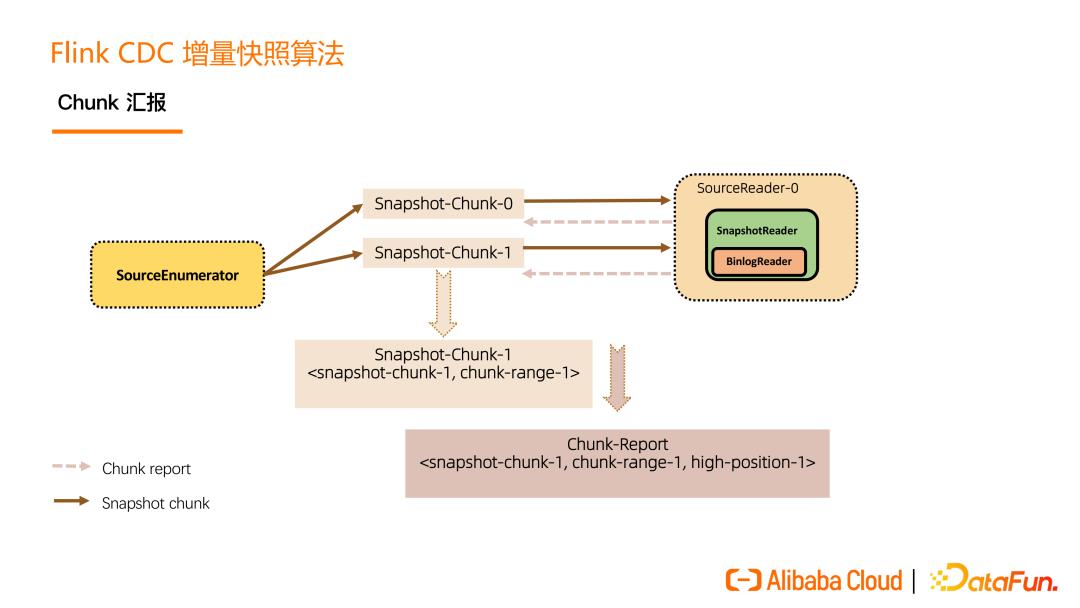
每一个 Snapshot chunk 读完了之后有一个信息汇报过程,这个汇报非常关键,包含该 chunk 的基本信息和该 chunk 是在什么位点读完的(即 close 位点)。在进入 Binlog 读取阶段之后, 在 close 位点之后且属于这个 chunk 的 binlog 数据,是要需要继续读取的,从而来保证数据的完整性。
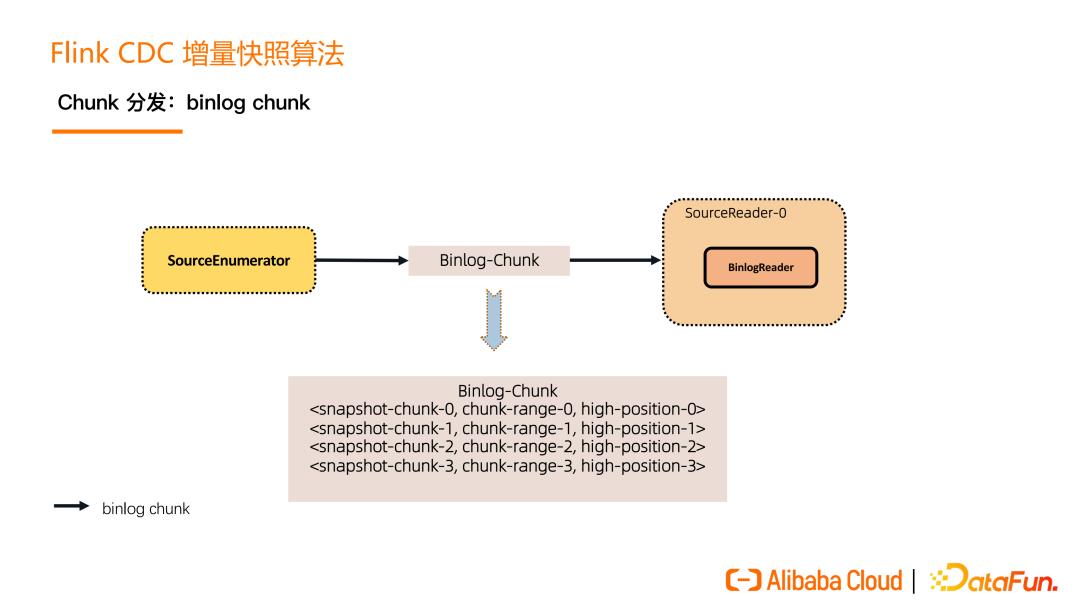
在所有的 Snapshot chunk 读完之后会发一个特殊的 Binlog chunk,该 chunk 里包含刚刚所有 Snapshot chunk 的汇报信息。Binlog Reader 会根据所有的 Snapshot chunk 汇报信息按照各自的位点进行跳读,跳读完后再进入一个纯粹的 binlog 读取。跳读就是需要考虑各个 snapshot chunk 读完全量时的 close 位点进行过滤,避免重复数据,纯 binlog 读就是在跳读完成后只要是属于目标表的 changelog 都读取。

Flink CDC 增量快照算法流程为,首先,一张表按 key 分成一个个 chunk,Binlog在不断地写,全量阶段由 SourceReader 去读,进入增量阶段后,SourceReader 中会启一个 BinlogReader 来读增量的部分。全量阶段只会有 insert only 的数据,增量阶段才会有 update、delete 数据。SourceReader 中具体去负责读 chunk 的 reader 会根据收到的分片类型,决定启动 SnapshotReader 还是 BinlogReader。

Flink CDC 增量快照算法的核心价值包括:
第一,实现了并行读取,水平扩展的能力,即使十亿百亿的大表,只要资源够,那么水平扩展就能够提升效率;
第二,实现 Dblog 算法的变动,它能够做到在保证一致性的情况下,实现无锁切换;
第三,基于 Flink 的 state 和 checkpoint 机制,它实现了断点续传。比如 task 1 失败了,不影响其它正在读的task,只需要把 task 1 负责的那几个 chunk 进行重读;
第四,全增量一体化,全增量自动切换。
03
Flink CDC 增量快照框架
Flink CDC 的增量快照读取算法早期只在 MySQL CDC 上支持,为了其他 CDC Connector 也能够轻松地接入,获得无锁读取,并发读取,断点续传等高级能力。在 2.2 版本中,我们推出了增量快照框架,把一些复用的、可以沉淀的代码抽象了出来,把一些面向数据源的特有的实现进行抽象。
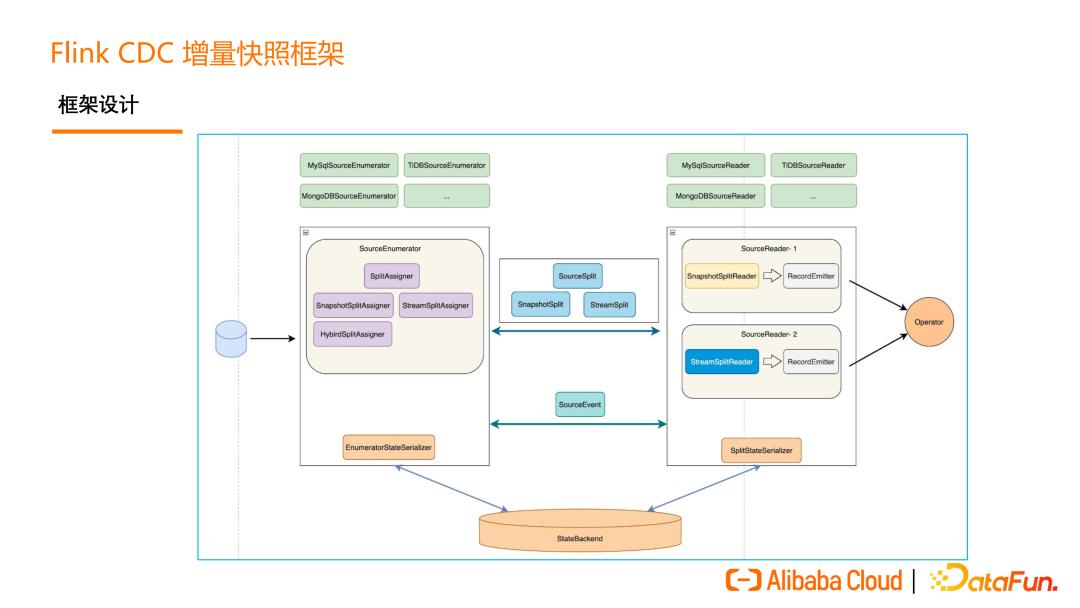
Flink CDC 增量快照框架的架构如上图所示。
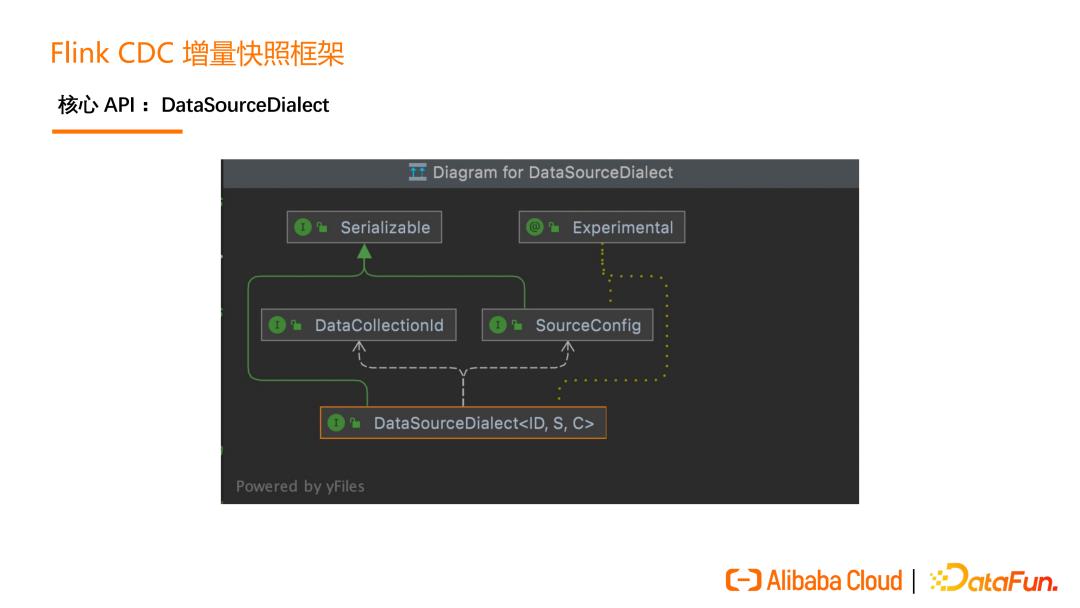
增量快照框架的设计围绕一个核心的 API 展开,这个核心的 API 就是DataSourceDialect(数据源方言),这个方言关心的就是面向某个数据源特有的,在接入全增量框架时需要实现的方法。
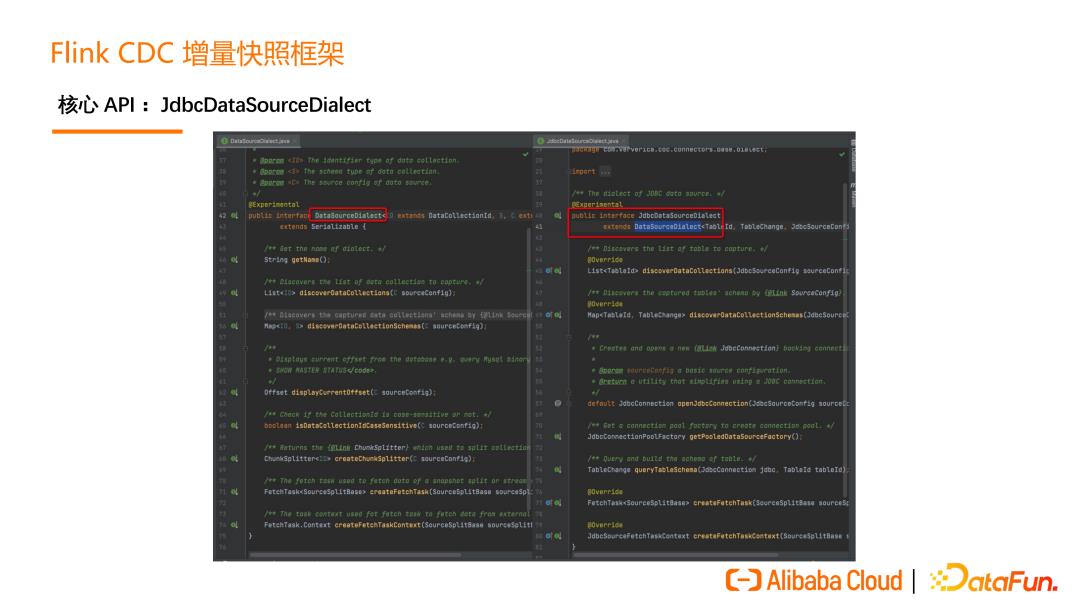
对于 JDBC 数据源,我们还提供了 JdbcDataSourceDialect 这个 API,可以让JDBC 数据源以更低的成本接入这个框架。
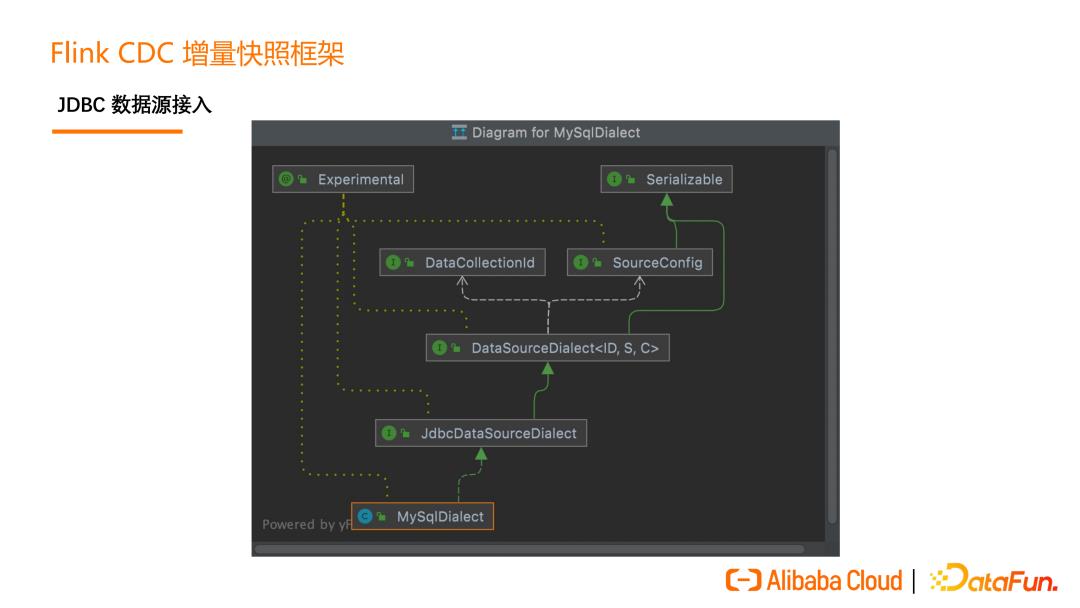
如上图所示,如果用户要实现 MySQL 接入的增量快照框架,只需要实现MySQLDialect 即可。

目前社区已经有多个 Connector 正在对接到增量快照框架上,大家可以关注社区 PR 了解更多详情。
04
社区发展规划
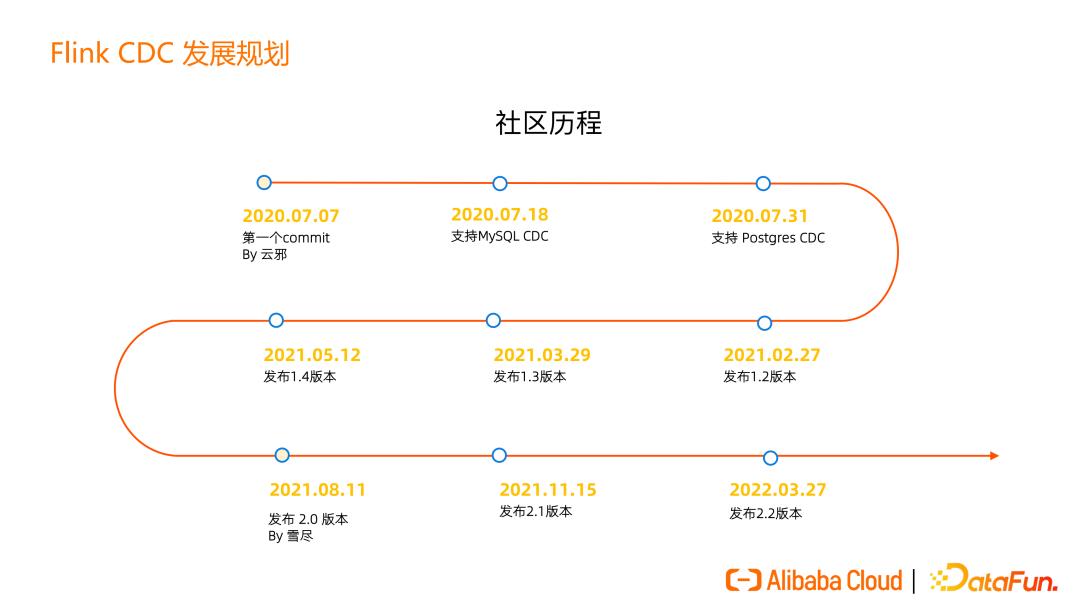
Flink CDC 的增量快照算法和框架的产生都离不开开源社区的全体贡献者,最后来介绍一下社区的发展和对未来的一些规划。首先来看一下过去两年中,我们发布的一些版本:
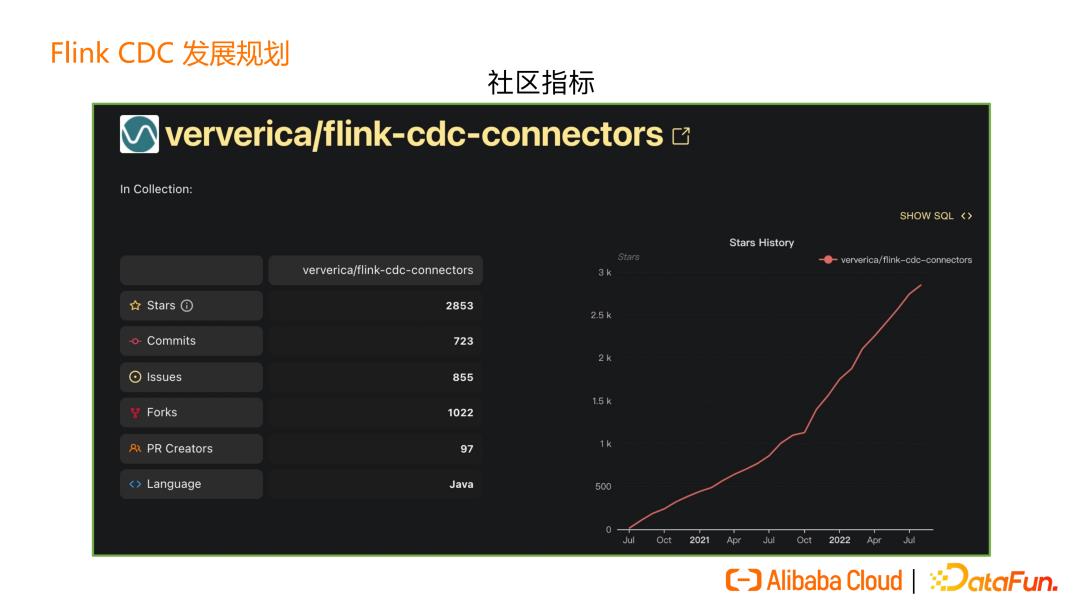
社区指标表明我们正在高速速发展的,特别是 2.0 版本发布之后,用户增长上了一个新的台阶。

Flink CDC 的社群目前也有非常多小伙伴加入,开源社群已经超过 6000 开发者,社群里大家可以自由地讨论开源和技术。
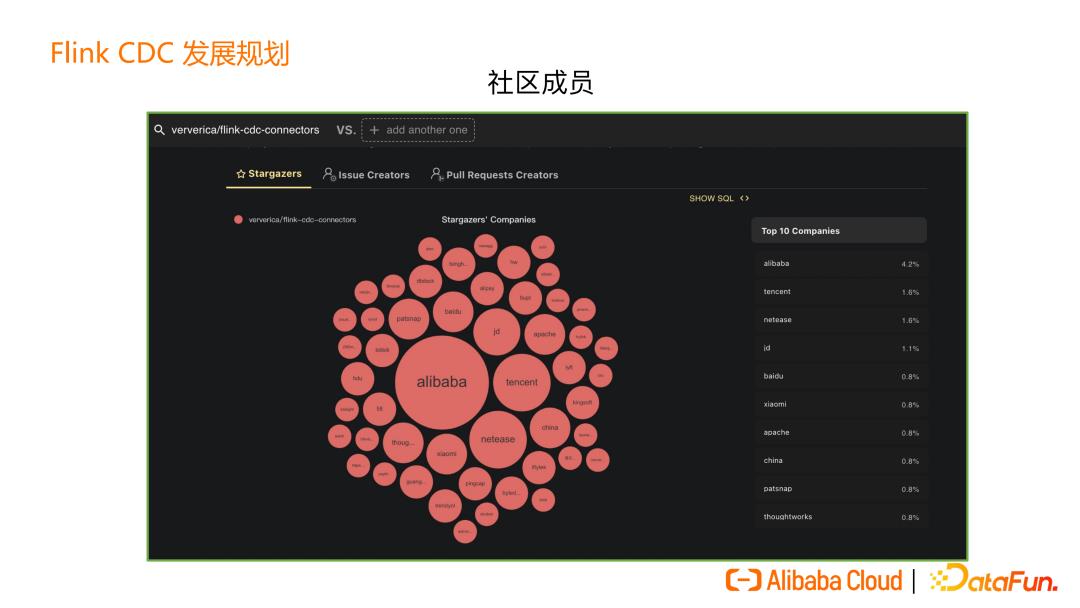
最近也统计了来自不同公司的关注者,如上图所示,可以发现其中不乏国内外头部互联网企业的身影。

整个社区在未来的规划主要围绕在框架推广,生态集成,易用性三大方面。
05
问答环节
Q1:表的分割数量怎么确定?步长怎么确定?如果全量数据比较大的时候,同时又在同时又变更频繁,把增量 merge 到全量这个效率和结束时间怎么保证?
A1:第一,表的那个分割数量怎么确定?默认每个分片大概是 8096,就是根据这个数量来的。这里面具体分的话其实是有两种分片的方式。第一种,分片如果说你表示自增并且是均匀的,我们直接取一个 min 跟 max,就你可以通过一个简单的数学计算确定这个分片数量。还有一种就是表的分片是不均匀的,比如说它的 ID 是个 UUID 这个时候我们就是通过 query 来查,就是通过数据库查询这个分片的边界。当然的话在社区也做了很多优化,就是说他会 lazy 地去查,因为一些 query 会比较耗时,支持一边查查询确定分片,一边读取已经确定的分片内容。
那第二个问题就是说把增量 merge 到全量的这个效率跟结束时间怎么保证。其实的话读一个全量数据一个 Snapshot chunk 的时候之间发生的那个 Binlog 我们是有过优化的。如果是说那个 Binlog 的位点没有前进,或者说前进的时候这张表没有做改变,那么我不会去读这个增量。那如果说有读,那个增量其实应该就很少一部分这些都是在内存里面做了一个 upsert 或者说叫 normalize 整个过程的话这个是非常快的,并且这个的话是可以并发做的。比如说我们大的作业我搞个一千个并发在这个地方读一千个并发,或者说上几百个并发在这个地方读,效率跟这个时间跟这个并发相关。
Q2:增量 log 有很多,单个 reader 的压力很大,也是可以并行读取增量 log 吗?
A2:目前的设计是只支持单个 reader 的,可以把增量阶段的那个资源给它开大一些。这个设计的初衷出发点是在大部分的数据源上游的这个日志写的时候,它其实只有一个 binlog 文件,它全局是单文件的,理论上你写的话比读的开销是要大的,就是一般来读的那个开销,如果说不是一些网络或者说是资源不够,那个读是要比写要快的。
今天的分享就到这里,谢谢大家。
🧐 分享、点赞、在看,给个3连击呗!👇
以上是关于深入解读 Flink CDC 增量快照框架的主要内容,如果未能解决你的问题,请参考以下文章