无标题
Posted Alluxio
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了无标题相关的知识,希望对你有一定的参考价值。
概要速览
PrestoDB的Aria项目曾于2020年发布过一组实验性功能,用来提高对表(通过Hive连接器连接并以ORC格式存储数据)的扫描性能。
在本文中,我们将在基于Docker的PrestoDB测试环境中对这些新功能进行基础性的测试。[1]
Presto
Presto 是一款能够大规模并行处理 (MPP) 的SQL执行引擎。执行引擎与数据存储是分离的,该项目包含大量插件(又称为连接器,connector),它们为Presto引擎提供查询的数据。数据存储中的数据被读取后,交由Presto执行查询操作,比如数据连接(joining)和聚合(aggregation)。这种数据存储和执行分离的架构允许单个Presto实例查询多个数据源,从而提供了非常强大的联合查询层。
Presto有许多可用的连接器,社区也会定期提供用以访问数据存储的新型连接器。
Hive 连接器
Hive 连接器一般被视为Presto的标准连接器。我们通常用它连接到 Hive Metastore,以此来获取Metastore 中定义的表的元数据信息。数据通常存储在 HDFS 或 S3中,而Metastore提供有关文件存储位置和格式的信息;最常用的是ORC格式,但也支持 Avro 和 Parquet等其他格式。Hive 连接器允许 Presto 引擎并行地将数据从HDFS/S3扫描到引擎中来执行查询。ORC格式是一种非常标准且常见的数据存储格式,能提供很好的压缩比和性能。
两个用于执行查询的核心服务
Presto有两个用于执行查询的核心服务:一个负责查询解析和任务调度等职责的Coordinator,以及多个负责并行执行查询的Worker。理论上,Coordinator也可以充当Worker的角色,但在生产环境中不会这么操作。鉴于我们在这里测试的是Presto,为方便起见,我们只使用一个节点,既作为 Coordinator 也作为 Worker。[2]
我们将使用单个Docker容器来进行本次Presto的测试。请点击查看部署文档,文档的末尾处有如何实现单节点 Presto部署的示例。
下面来介绍Presto是如何执行一条查询语句的:
首先,Presto coordinator先对查询语句进行解析,从而制定出一个执行计划(下文会提供示例展示)。计划制定完成之后就会被分成几个阶段(或片段),每个阶段将执行一系列操作,即引擎用来执行查询的特定函数。执行计划通常从连接器扫描数据开始,然后执行一系列操作,如数据过滤、部分聚合以及在Presto worker节点之间交换数据来执行数据连接和最终的数据聚合等。所有这些阶段被分成多个分片(split),即Presto中的并行执行单元。Worker 并行执行可配置数量的分片,从而获得所需的结果。引擎中的所有数据都保存在内存中(前提是不超过集群的容量阈值)。
Hive连接器(以及所有其他连接器)负责将输入数据集拆分为多个分片,供 Presto 并行读取。作为一项优化措施,Presto 引擎将告知连接器查询中使用的谓词(predicate)以及选定的列(column)——称为谓词下推 (predicate pushdown),这使得连接器能够在把数据提供给Presto引擎之前过滤掉不必要的数据,这也是本文的重点所在。
为了演示谓词下推,我们来看一个基本查询——统计某个数据表内符合条件的行数。我们的查询示例是基于基准测试数据集TPC-H的lineitem数据表进行的。TPC-H的lineitem表中大约有6亿行记录,它们的shipdate字段取值介于1992和1998之间。下面的查询语句是针对lineitem数据表的设置条件过滤谓词,筛选出shipdate字段为1992年的数据行。我们先在不启用Aria增强会话属性的情况下,通过运行 EXPLAIN 命令来观察一下查询计划:
presto:tpch> EXPLAIN (TYPE DISTRIBUTED) SELECT COUNT(shipdate) FROM lineitem WHERE shipdate BETWEEN DATE '1992-01-01' AND DATE '1992-12-31';
Fragment 0 [SINGLE]
Output layout: [count]
Output partitioning: SINGLE []
Stage Execution Strategy: UNGROUPED_EXECUTION
- Output[_col0] => [count:bigint]
_col0 := count
- Aggregate(FINAL) => [count:bigint]
count := ""presto.default.count""((count_4))
- LocalExchange[SINGLE] () => [count_4:bigint]
- RemoteSource[1] => [count_4:bigint]
Fragment 1 [SOURCE]
Output layout: [count_4]
Output partitioning: SINGLE []
Stage Execution Strategy: UNGROUPED_EXECUTION
- Aggregate(PARTIAL) => [count_4:bigint]
count_4 := ""presto.default.count""((shipdate))
-ScanFilter[table = TableHandle connectorId='hive', connectorHandle='HiveTableHandleschemaName=tpch, tableName=lineitem, analyzePartitionValues=Optional.empty', layout='Optional[tpch.lineitemdomains=shipdate=[ [[1992-01-01, 1992-12-31]] ]]', grouped = false, filterPredicate = shipdate BETWEEN (DATE 1992-01-01) AND (DATE 1992-12-31)] => [shipdate:date]
Estimates: rows: 600037902 (2.79GB), cpu: 3000189510.00, memory: 0.00, network: 0.00/rows: ? (?), cpu: 6000379020.00, memory: 0.00, network: 0.00
LAYOUT: tpch.lineitemdomains=shipdate=[ [[1992-01-01, 1992-12-31]] ]
shipdate := shipdate:date:10:REGULAR
查询计划按自下而上顺序来阅读,从 Fragment 1 开始,并行扫描 lineitem 表,使用谓词对shipdate列进行过滤,然后对每个分片执行部分聚合,并将该部分结果交换到下一阶段 Fragment 0 来执行最终的聚合,之后再将结果发送到客户端,查询计划流程参见下图:(图中靠近底部的水平线标示出哪些代码在 Hive 连接器中执行,哪些代码在 Presto 引擎中执行。)
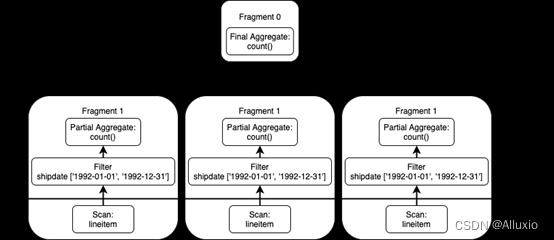
现在我们来执行这个查询!
presto:tpch> SELECT COUNT(shipdate) FROM lineitem WHERE shipdate BETWEEN DATE '1992-01-01' AND DATE '1992-12-31';
_col0
----------
76036301
(1 row)
Query 20200609_154258_00019_ug2v4, FINISHED, 1 node
Splits: 367 total, 367 done (100.00%)
0:09 [600M rows, 928MB] [63.2M rows/s, 97.7MB/s]
我们看到,lineitem 表包含7600多万行shipdate列取值为1992年的记录。执行这个查询大约花费了9 秒,总共处理了 6 亿行数据。
现在我们来激活会话属性 pushdown_subfields_enabled 和hive.pushdown_filter_enabled,以启用 Aria 功能,下面我们来看一下查询计划发生了怎样的变化:
presto:tpch> SET SESSION pushdown_subfields_enabled=true;
SET SESSION
presto:tpch> SET SESSION hive.pushdown_filter_enabled=true;
SET SESSION
presto:tpch> EXPLAIN (TYPE DISTRIBUTED) SELECT COUNT(shipdate) FROM lineitem WHERE shipdate BETWEEN DATE '1992-01-01' AND DATE '1992-12-31';
Fragment 0 [SINGLE]
Output layout: [count]
Output partitioning: SINGLE []
Stage Execution Strategy: UNGROUPED_EXECUTION
- Output[_col0] => [count:bigint]
_col0 := count
- Aggregate(FINAL) => [count:bigint]
count := ""presto.default.count""((count_4))
- LocalExchange[SINGLE] () => [count_4:bigint]
- RemoteSource[1] => [count_4:bigint]
Fragment 1 [SOURCE]
Output layout: [count_4]
Output partitioning: SINGLE []
Stage Execution Strategy: UNGROUPED_EXECUTION
- Aggregate(PARTIAL) => [count_4:bigint]
count_4 := ""presto.default.count""((shipdate))
- TableScan[TableHandle connectorId='hive', connectorHandle='HiveTableHandleschemaName=tpch, tableName=lineitem, analyzePartitionValues=Optional.empty', layout='Optional[tpch.lineitemdomains=shipdate=[ [[1992-01-01, 1992-12-31]] ]]', grouped = false] => [shipdate:date]
Estimates: rows: 540034112 (2.51GB), cpu: 2700170559.00, memory: 0.00, network: 0.00
LAYOUT: tpch.lineitemdomains=shipdate=[ [[1992-01-01, 1992-12-31]] ]
shipdate := shipdate:date:10:REGULAR
:: [[1992-01-01, 1992-12-31]]
注意:查询计划的主要变化位于底部,即TableScan 操作中包含了shipdate 列。连接器已经接收到shipdate列上的谓词条件——取值介于1992-01-01 和 1992-12-31之间。如下图所示,该谓词被下推到连接器,免去了查询引擎过滤这些数据的必要性。
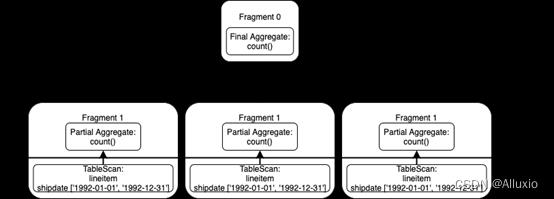
我们再一次运行这个查询!
presto:tpch> SELECT COUNT(shipdate) FROM lineitem WHERE shipdate BETWEEN DATE '1992-01-01' AND DATE '1992-12-31';
_col0
----------
76036301
(1 row)
Query 20200609_154413_00023_ug2v4, FINISHED, 1 node
Splits: 367 total, 367 done (100.00%)
0:05 [76M rows, 928MB] [15.5M rows/s, 189MB/s]
运行查询后,我们得到了相同的结果,但查询时间几乎缩短了一半,更重要的是,查询只扫描了7600万行!连接器已经将谓词应用于shipdate 列,而不是让引擎来处理谓词,因此节省了CPU周期,继而加快了查询速度。针对不同的查询和数据集情况可能有所不同,但如果是通过Hive连接器查询ORC文件的场景,该方案绝对值得一试。
文章作者:Adam Shook 原文于2020年6月15日发表在作者的个人博客上:http://datacatessen.com
参考
[1]如需了解有关Aria项目功能的更多信息,可查看文章底部 https://engineering.fb.com/2019/06/10/data-infrastructure/aria-presto/
[2]如需了解安装等详细信息,可查看文章底部文档 https://prestodb.io/docs/current/
以上是关于无标题的主要内容,如果未能解决你的问题,请参考以下文章