AI遮天传 ML-无监督学习
Posted 老师我作业忘带了
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了AI遮天传 ML-无监督学习相关的知识,希望对你有一定的参考价值。
一、无监督学习介绍
机器学习算法分类(不同角度):
- 贪婪 vs. 懒惰
- 参数化 vs. 非参数化
- 有监督 vs. 无监督 vs. 半监督
- ......
什么是无监督学习?(unsupervised learning)
解释 1
- 有监督:涉及人力(human label)的介入
- 无监督:不牵扯人力(是否要通过人来给一些label分辨属于哪些类别)
解释 2
- 给定一系列数据: x1 , x2 , . . . , xN
- 有监督:期望的输出同样给出 y1 , y2 , . . . , yN
- 无监督:没有期望输出
解释 3
- 有监督:学习的知识关注条件分布 P(Y|X)
- X = 样例(用其特征来表示), Y = 类别
- 无监督:学习的知识关注联合分布 P(X),
- X: X1 , X2, …, Xn
- 半监督学习:通过一些(少量)有标注的数据和很多无标注的数据学习条件分布 P(Y|X)
对于监督学习:

我们通过多个样例<xi,yi>来训练模型,对于一个需要预测的样例xn+1,我们通过训练完的模型对其进行预测,得到yn+1,(x一般很复杂,有多种特征值,y一般比较简单,比如是某分类)如:
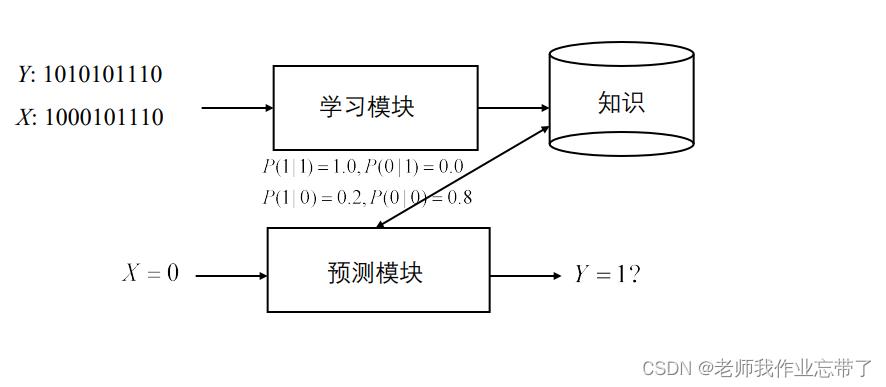
对于无监督学习
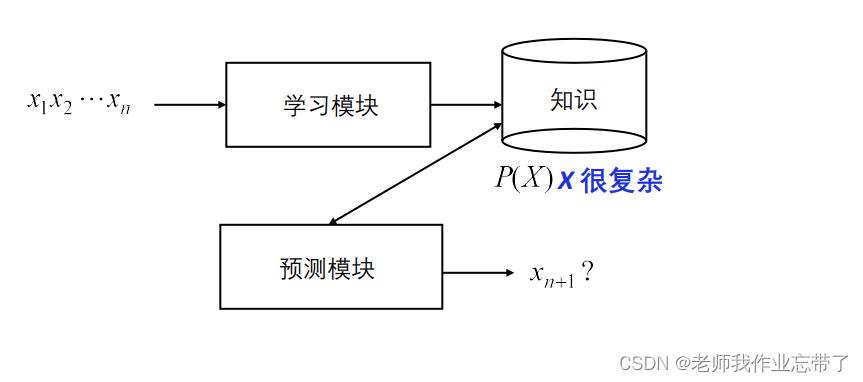
对于给的一组x1...xn,我们一般会预测下一个xn+1是什么样,或者x1...xn它们是一个什么样的结构组成的。
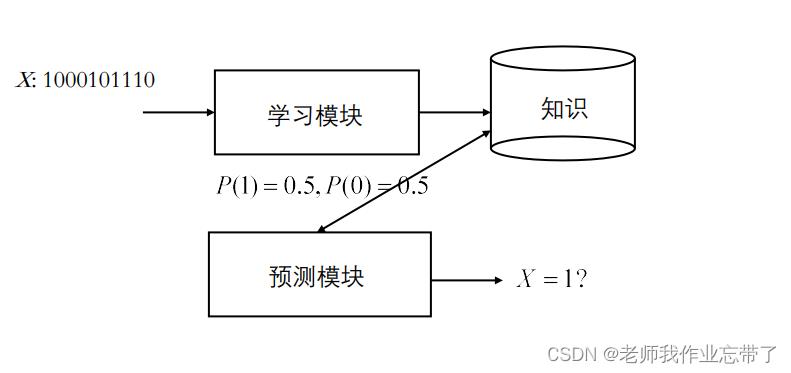
对于半监督学习
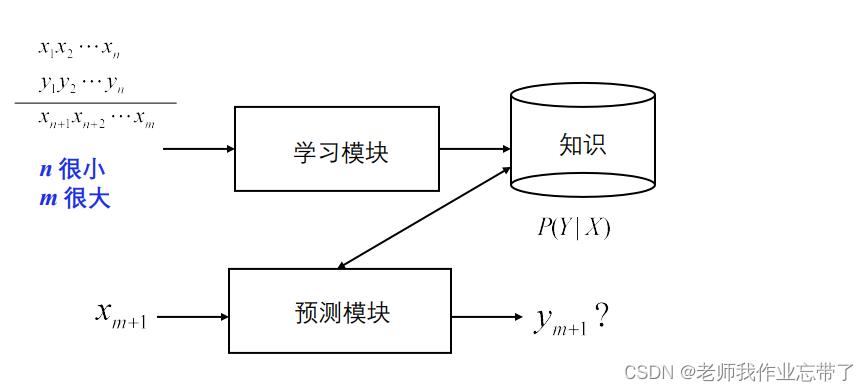
有一堆数据(1,2...n...m),有一些是由标注的,还有一些是没有y的(m>>n),对于有标注的那部分,我们还是以监督学习的方法的到模型去预测输入的样例。我们用100个数据去学习10000个数据,我们可以看对于那些没有标注(y)的,哪些与有标注的相类似(如果不使用基于实例的学习方法的话)。
无标注数据的结构
无监督学习中最重要的就是学到无标注数据的结构
- 构建模型找到输入的合理表示
- 可以用来做决策、预测未知数据、将输入高效迁移到其他学习器等
- 发现数据的结构
- 一篇学术论文包含题目、摘要......
- 半结构化网页中蕴含结构化信息
- 图片中的像素不是随机生成的
- 不同的用户兴趣组
对于一张图片,我们随即交换像素点和RGB后:

而实际上它是这样一张图片:

这里的结构信息就是什么样的像素RGB它们是在一起的。此外还涉及一些语义信息,比如我们在图片中可以看到有树,草地,天空,这些经过分割后,下一步才会做一些理解,比如右下角是一朵向日葵,阳光,中间的两个分开的房子...
ps:一个有趣的小问题:如果我们不知道它是一棵树,那怎么把它分割成一棵树了呢?如果没有办法把它分割出来,又怎么能知道它是一棵树呢?

我们可以用无标注数据干什么
- 数据聚类
- 在没有预先定义的类别时将数据分为不同的组(cluster/class)
- 降维
- 减少所需要考虑的变量数量(去掉较小的特征值。比如SVD矩阵分解方法。)
- 离群点检测
- 识别机器学习系统在训练中未发现的新数据/信号 Identification of new or unknown data or signal that a Machine Learning system is not aware of during training
- 刻画数据密度
二、聚类介绍
什么是聚类?
- 将相似的对象归入同一个“类”
- “Birds of a feather flock together. ” “物以类聚,人以群分”
- 发现数据的结构
- 使得同一个类中的对象互相之间关联更强
- 同一个类中的对象相似
- 不同类中的对象有明显差异
- 核心问题:相似度定义(距离)
- 簇/类内(intra-cluster)相似度
- 簇/类间(inter-cluster)相似度
什么样的聚类好?
通常,我们认为类内距离小,类间距离大的聚类更好。
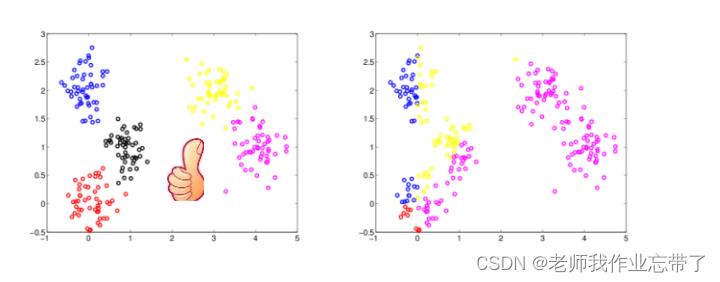
聚类类型
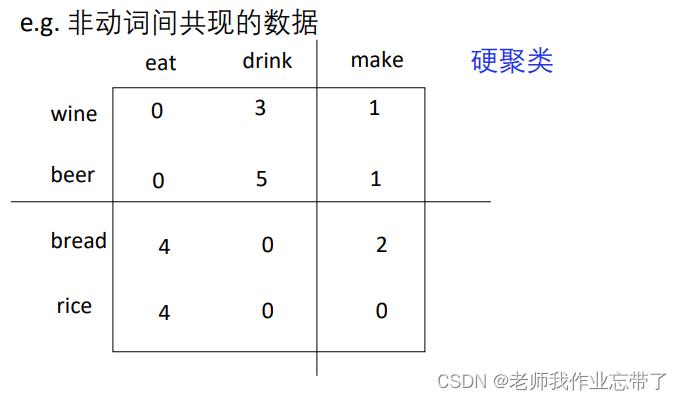
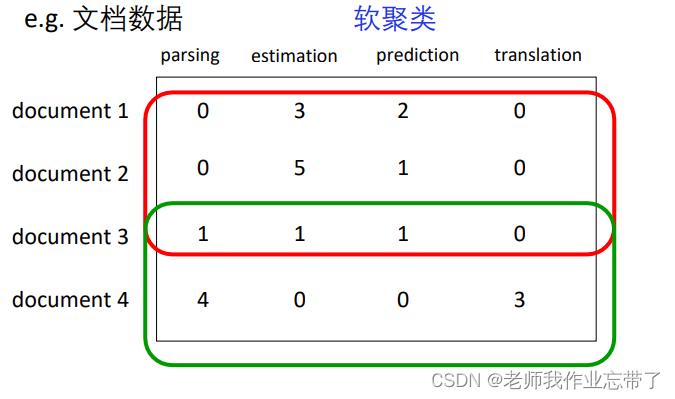
软聚类(soft clustering) vs. 硬聚类(hard clustering)
- 软:同一个对象可以属于不同类
- 硬:同一个对象只能属于一个类(用的比较多)
如:
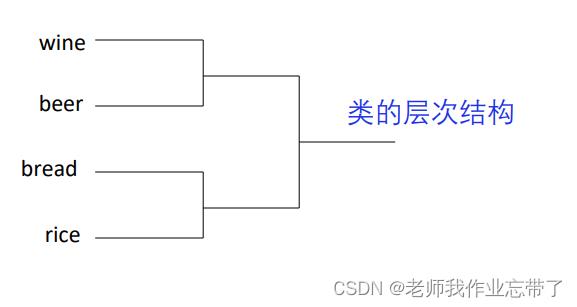
层次聚类 vs. 非层次聚类
- 层次:一个所有类间的层次结构(tree)
- 非层次: 平的,只有一层
如:
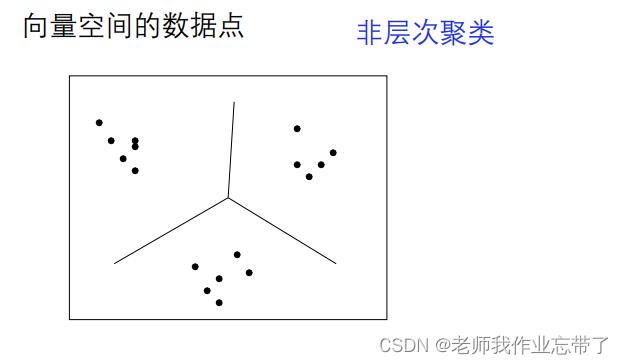
聚类的应用
- 生物学
- 将同源序列分组到基因家族中
- 基因数据的相似度往往在聚类中被用于预测种群结构
- 图像处理 e.g. 自动相册
- 经济 – 尤其是市场商务智能
- 找到不同的顾客群体,e.g. 保险
- WWW
- 文档/事件 聚类,e.g. 每周新闻摘要
- WEB日志分析,e.g. 找到相似的用户
- ……
数据聚类需要什么?
- 无标注数据
- 对象间的 距离 或 相似度度量
- (可选)类间的距离或相似度度量
- 聚类算法
- 层次聚类
- K-means、K-mediods
- ……
数据
- 向量 x ∈ D1 × D2 · · · × DN
- 类型
- 实数值 Real: D=R
- 二值 Binary: D = v1 ,v2 e.g., Female, Male
- 非数值 Nominal: D = v1 ,v2 ,...,vM e.g., Mon, Tue, Wed, Thu, Fri, Sat, Sun
- 有序值 Ordinal: D = R or D = v1 ,v2 ,...,vM
- 用于顺序非常重要的场景 e.g., 排名
相似度度量
- 相似度 =
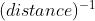 ps:反比 也不一定就是倒数
ps:反比 也不一定就是倒数 - 实数值数据
- 内积
- 余弦相似度
- 基于核
- …
- 回顾基于实例学习中的距离度量
- Minkowski 距离
- Manhattan 距离、Euclidean 距离、Chebyshev 距离
- ……
- Minkowski 距离
- 非数值
- E.g. "Boston", "LA", "Pittsburgh"
- 或 “男” , “女",
- 或 “弥散”, “球形”, “螺旋”, “风车"
- 二值
-
- 用对应的语义属性
- E.g. Sim(Boston, LA) = a*dist(Boston, LA)-1 ,
- Sim(Boston, LA) = a*(|size(Boston) - size(LA)|) / Max(size(cities))
- 用相似度矩阵
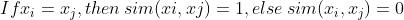
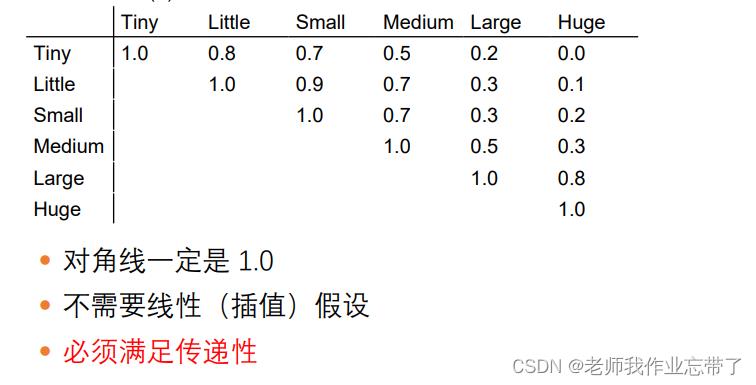
- 有序值
- E.g. “小” , “中”, “大”, “特大"
- 归一化成 [0,1] 间的实数值:
- max(v)=1, min(v)=0, 其他进行插值
- E.g. “小”=0, “中"=0.33, etc.
- 然后就可以使用实数值变量的相似度度量
- 可以用相似度矩阵
三、层次聚类
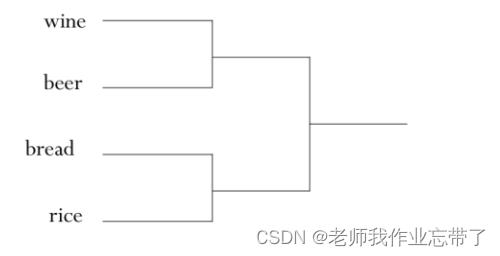
- 层次地构建一个类,比如一个由不同类组成的树状结构
- 父节点所涵盖的点被分割为兄弟类
- 以不同的粒度解释数据
凝聚式层次聚类算法(Agglomerative, bottom-up)
- 通过迭代过程得到嵌套式聚类结构
- 算法:(以文档聚类为例)
- 计算文档之间的相似系数
- 把n个文档中的每一个分配给自己构成一个簇
- 把最相似的两个簇类ci和cj合并成一个
- 用新构成的簇类代替原来的两个簇
- 重新计算其他簇与新生成簇之间的相似性
- 重复上述过程,直到只剩下k个簇(k可以等于1)
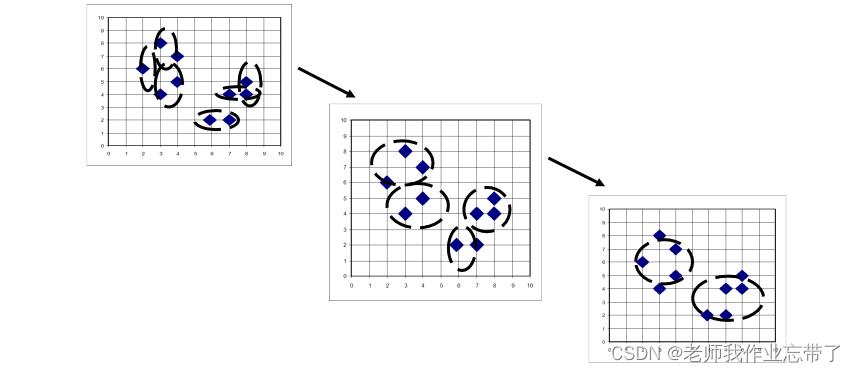
类相似度

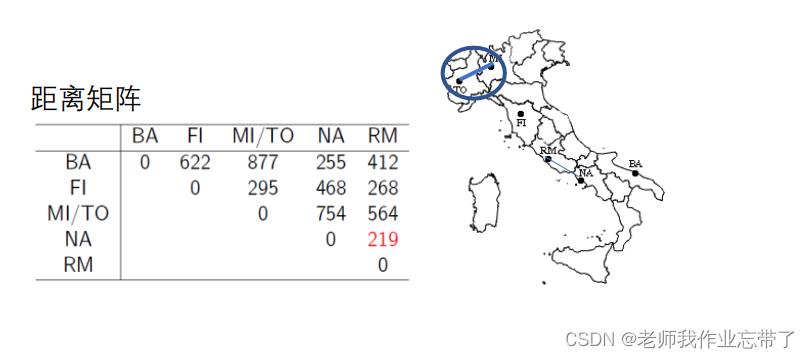
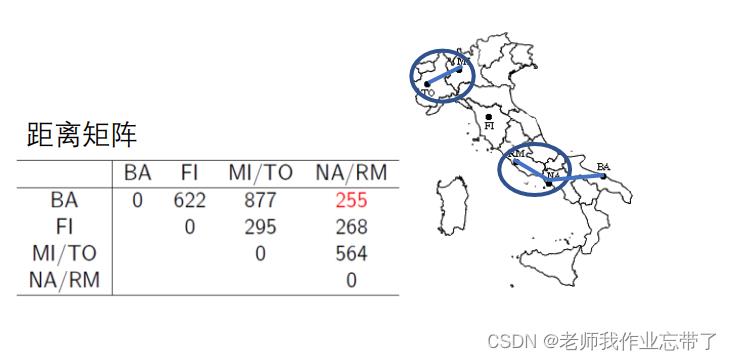
实例:意大利城市的层次聚类

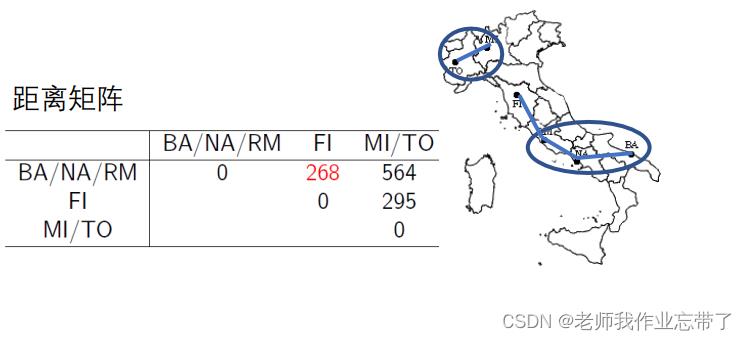
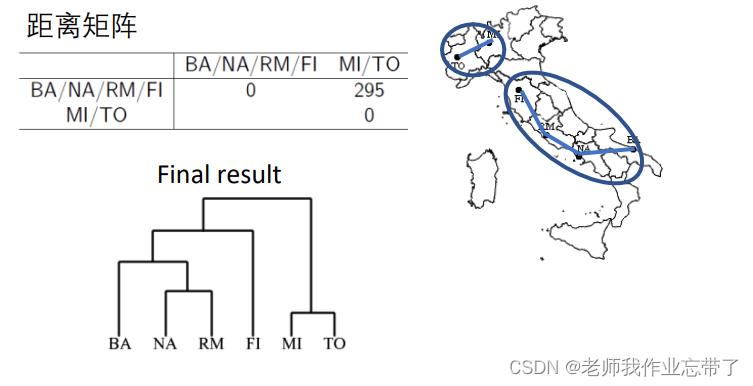
分裂式层次聚类(Divisive, top-down)
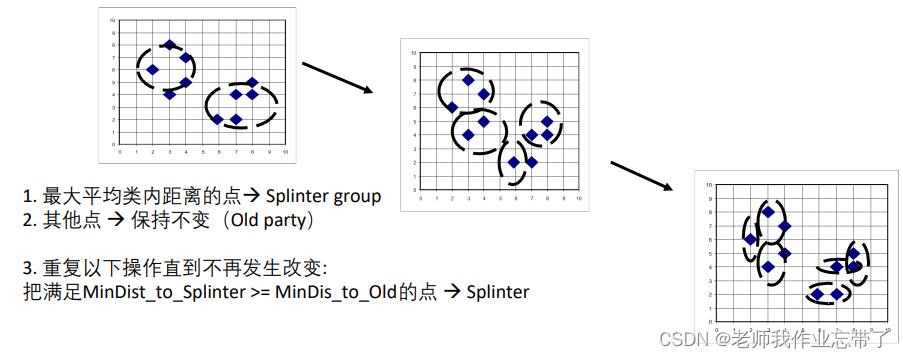
根据一个类中最大的间隔进行分裂
- 最大平均类内距离的点:Splinter group
- 其他点 :保持不变(Old party)
- 重复以下操作直到不再发生改变: 把满足MinDist_to_Splinter >= MinDis_to_Old的点:Splinter
分裂式层次聚类vs. 凝聚式层次聚类

层次聚类的相关讨论
优点
- 可以从不同粒度观察数据,十分灵活
- 可以方便适应各种形式的相似度定义
- 因此适用于各种属性类型
缺点
- 停止条件不确定
- 计算开销大、很难应用到大的数据集上
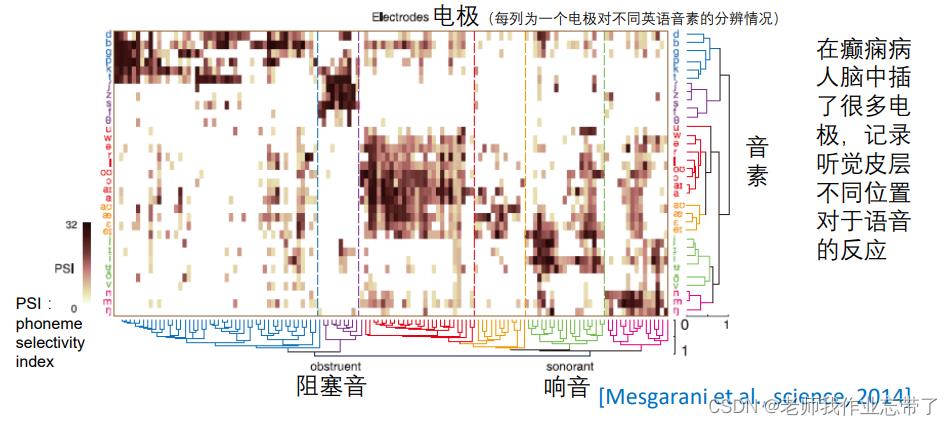
神经科学数据分析中的应用
四、K-means 聚类
算法:
- 给定一个类分配方案C,确定每个类的均值向量:g1,...,gk。
- 给定K个均值向量的集合g1,...,gk,把每个对象分配给距离均值最近的类。
- 重复上述过程直到评价函数不发生变化。
不保证找到最优解
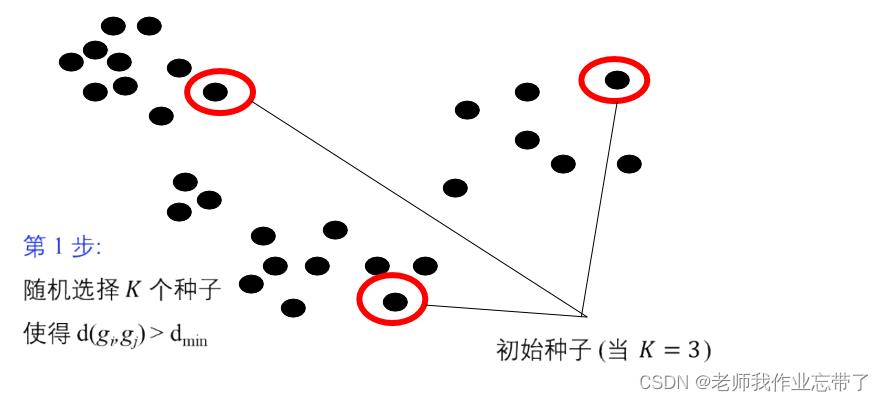
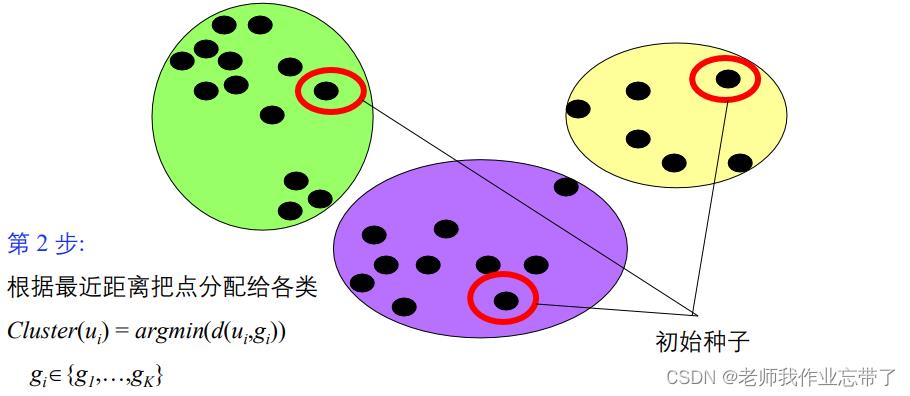
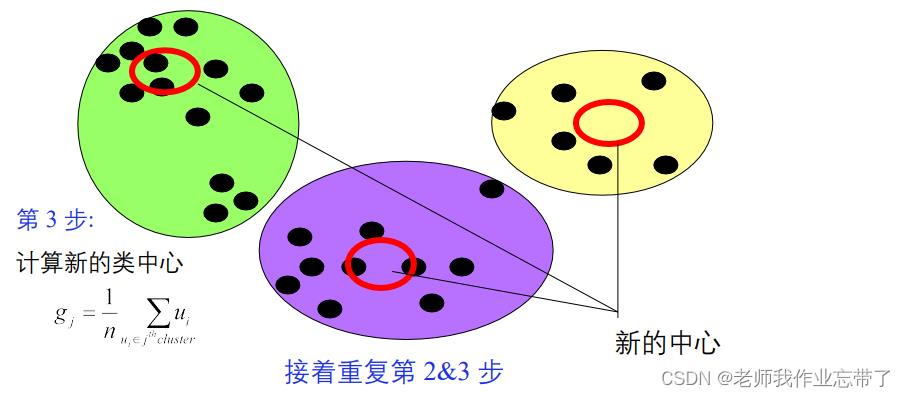
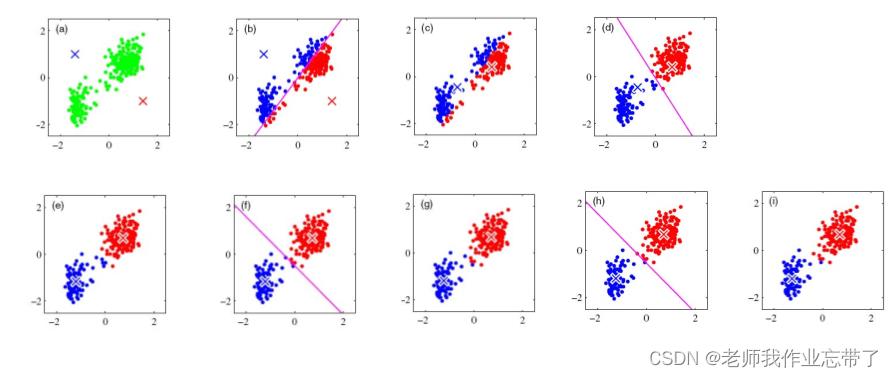
算法的收敛性



K-means 算法特性小结
模型: 向量空间模型
策略: 最小化类内对象的欧式距离
算法: 迭代
硬聚类
非层次
K-means 算法举例
应用举例:不仅仅是聚类 —— 图像压缩
数据:所有像素
特征:RGB值

每个像素根据所属类的中心对应的 R,G,B 值进行重画
K-means讨论:如何确定“k”?
- 问题驱动
- 通常问题本身会设定一个需要的 K 值
- 只有满足下列条件之一时,可以是 ”数据驱动” 的
- 数据不稀疏
- 度量的维度没有明显噪音
- 如果 K 值没有给定
- 计算类间不相似度 Wk (与类间相似度相反) (或者检验类内相似度) —— 与 K 相关的函数
- 一般来说, K 值增加,Wk 值降低
方法1:
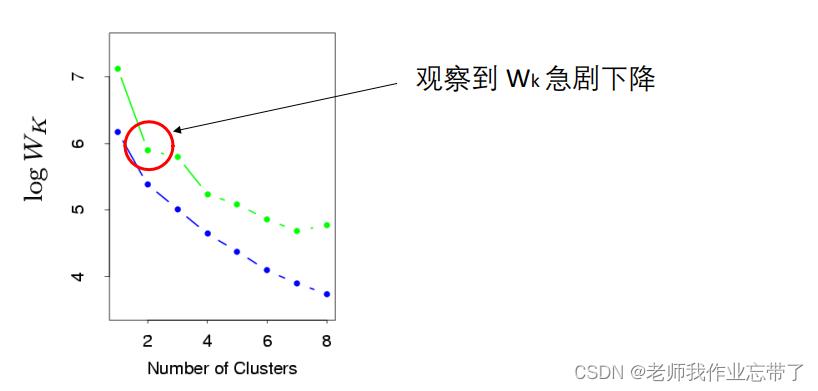
方法2 :

K-means :更多讨论
- 当数据呈几个紧凑且互相分离的云状时效果很好
- 对于非凸边界的类或类大小非常不一致的情况也适用
- 对噪声和离群点非常敏感
五、K- medoids
用 medoid – 用最靠近类中心的对象作为类的参考点 而不是用类的均值
基本策略:
- 找到 n 对象中的 k 个类,随机确定每个类的代表对象
- 迭代:
- 其他所有对象根据距离最近的类中心进行类的分配
- 计算使得cost最小的类中心
- 重复直到不再发生变化
- 代价函数:类内对象与类中心的平均不相似度
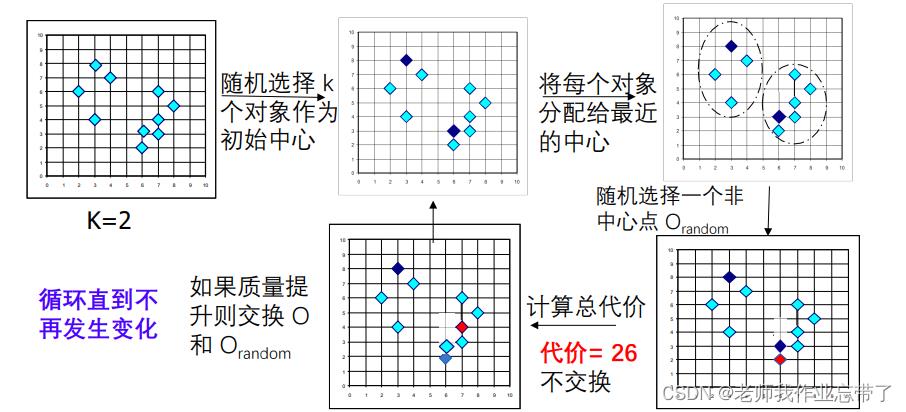
K- medoids改进算法:PAM(Partitioning Around Medoids)
基本策略:
- 找到 n 对象中的 k 个类,随机确定每个类的代表对象
- 迭代:
- 其他所有对象根据距离最近的类中心进行类的分配
- 随机用一个非中心对象替换类中心
- 类的质量提高则保留替换
类的质量
代价函数:类内对象与类中心的平均不相似度
如总代价为20
K-Medoids讨论
优点:
- 当存在噪音和孤立点时, K-medoids 比 K-means 更鲁棒
- 如果能够迭代所有情况,那么最终得到的划分一定是最优的划分,即聚类 结果最好
缺点:
- K-medoids 对于小数据集工作得很好, 但不能很好地用于大数据集
- 计算中心的步骤时间复杂度是O(n^2),运行速度较慢
基于大样本的改进算法:CLARA(Clustering LARge Applications)
基本策略:当面对大样本量时:
- 每次随机选取样本量中的一小部分进行PAM聚类
- 将剩余样本按照最小中心距离进行归类
- 在各次重复抽样聚类的结果中,选取误差最小,即中 心点代换代价最小的结果作为最终结果
无监督学习总结
有监督 v.s. 无监督学习
聚类
- 数据及相似度度量
层次聚类
- 凝聚式 (从下到上)
- 分裂式 (从上到下)
K-means 聚类
K-medoids 聚类(及其变种与改进:PAM,CLARA)
以上是关于AI遮天传 ML-无监督学习的主要内容,如果未能解决你的问题,请参考以下文章