Keras深度学习实战(13)——目标检测基础详解
Posted 盼小辉丶
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Keras深度学习实战(13)——目标检测基础详解相关的知识,希望对你有一定的参考价值。
Keras深度学习实战(13)——目标检测基础详解
0. 前言
在《深度卷积神经网络》和《迁移学习》的相关博文中,我们已经学习了如何使用深度卷积神经网络来进行图像分类任务。尽管图像分类用途广泛,但在现实世界中,我们还会遇到需要在图像中定位目标的应用场景。例如,在无人驾驶中,我们不仅需要检测是否有行人出现在视野内,而且还必须检测出行人离汽车有多远。在本节中,我们将介绍检测图像中目标对象的各种基础技术,为之后实现目标检测 (Object Detection) 模型奠定基础。
1. 目标检测概念
目标检测 (Object Detection) 的目的是找出图像中所有感兴趣的目标(对象),并确定这些目标的类别和位置,是计算机视觉领域的核心问题之一。随着自动驾驶汽车、人脸检测和智能视频监控等应用的兴起,人们愈加重视更加快速、准确的目标检测系统。这些系统不仅需要对图像中的对象进行识别和分类,还需要通过在目标对象周围绘制适当的矩形框来定位图像中的每一个目标。目标检测的输出比图像分类更加复杂,可以通过下图明显看出两者之间的差别:

在系列博文中,我们已经了解了图像分类 (Classification) 任务,即判断图像中目标对象的类别,定位 (Location) 任务则是在图片中的对象周围绘制一个边界框,而检测图片中的所有目标对象的类别和位置就是对象检测 (Detection) 任务。
2. 创建自定义目标检测数据集
通过以上介绍,我们已经知道目标检测 (object detection) 的输出是目标的边界框,其中边界框用于定位图像中的目标对象。要构建算法检测图像中目标周围的边界框,就必须首先创建输入-输出映射,其中输入是图像,而输出是给定图像中目标周围的边界框。
当我们检测到边界框时,我们需要检测图像周围边界框左上角的像素位置,以及边界框的相应宽度和高度。要训练能够输出边界框的模型,我们需要训练集图像以及训练数据集图像中所有对象的相应边界框坐标和类别标签。
在本节中,我们将介绍如何创建训练数据集的方法,其中将图像作为输入,并将相应的边界框存储在XML文件中。我们将学习使用labelImg包来标注边界框和相应目标对象的类。最为通用的方法是使用 pip 进行安装,与其它第三方库安装方法相同:
$ pip3 install labelImg
除了使用 pip 安装外,在不同操作系统中也有其它不同的方式使用 labelimg 包标注图像中对象的边界框,不同操作系统的安装教程可以参考官方网页,本节我们进行简要介绍。
2.1 windows
通过官方链接下载 labelImg 的可执行文件,解压后打开 labelImg.exe 程序,其界面如下图所示:

在 data 文件夹的 predefined_classes.txt 文件包含了图像中所有可能的标签,我们需要确保每个类别都占据单独一行,如下所示:
单击 “Open” 打开图像,然后单击 “Create RectBox” 为图像绘制边界框。绘制边界框完成后,将弹出为目标对象选择的类别窗口,为标记的对象选择所属类别,如下所示:
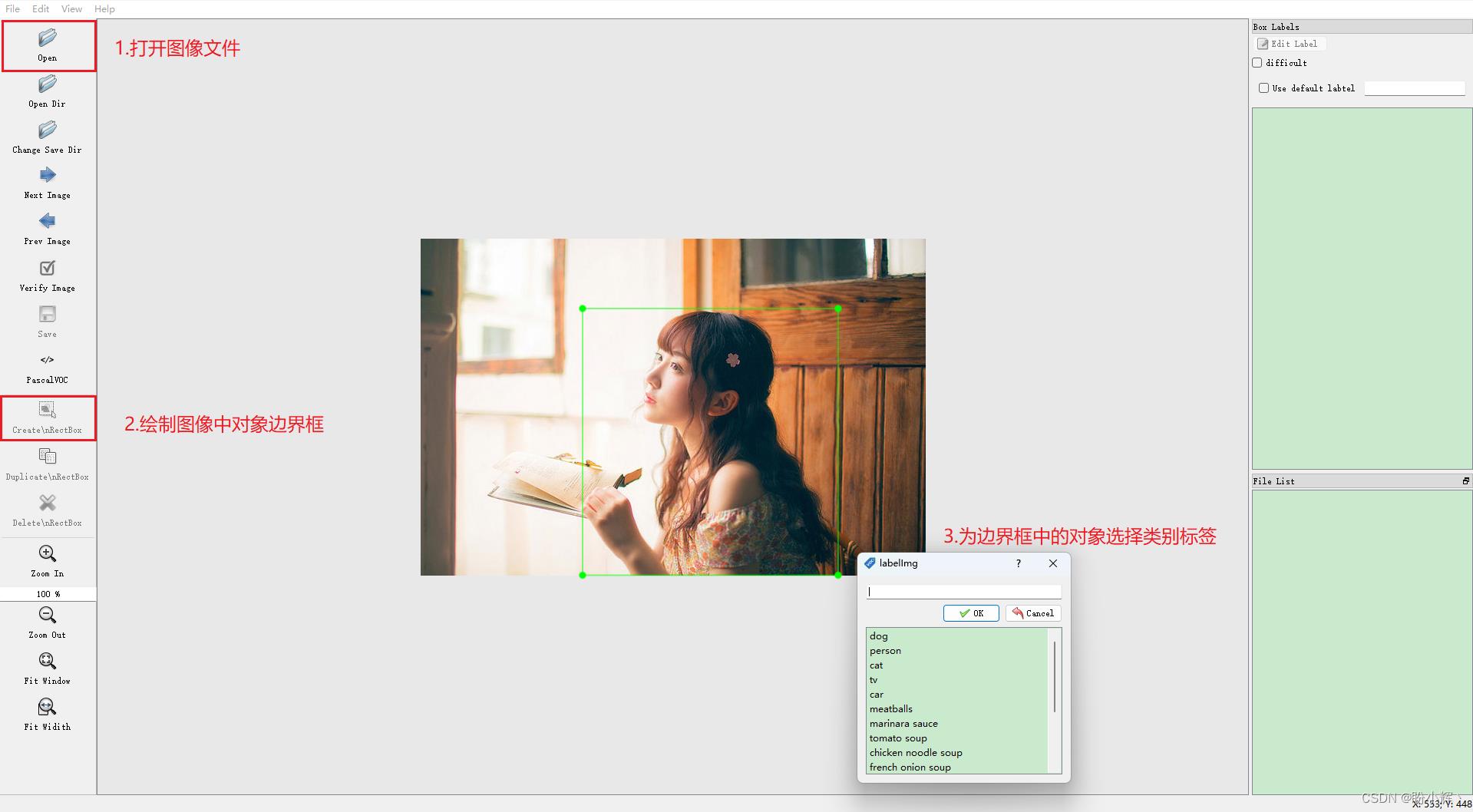
单击 Ok 完成此对象的标注,标注图中所有对象后,单击 Save 并保存 XML 文件:

保存完成后,可以检查 XML 文件。绘制矩形边界框后,XML 文件的内容如下所示:

在上图中,可以看到,bndbox 包含图像中对象相对应的 x 和 y 坐标的最小值和最大值的坐标,即边界框左上角和右下角坐标。此外,我们可以通过 name 提取到边界框中对象相对应的类别标签。
2.2 Ubuntu
在 Ubuntu 中,可以通过运行以下命令来使用 labelimg 包:
$ sudo apt-get install pyqt5-dev-tools
$ sudo pip3 install -r requirements/requirements-linux-python3.txt
$ make qt5py3
$ python3 labelImg.py
可以在 GitHub 链接中找到脚本 labelImg.py。执行上述命令后,接下来使用 labelimg 包标注目标对象边界框和类别的用法与 Windows 中相同。
2.3 MacOS
在 macOS 中,可以通过执行以下命令来使用 labelimg 包:
$ brew install qt
$ brew install libxml2
$ make qt5py3
$ python3 labelImg.py
可以在 GitHub 链接中找到脚本 labelImg.py。执行了以上命令之后,接下来使用 labelimg 包标注目标对象边界框和类别的用法与 Windows 中相同。
3. 使用选择性搜索在图像内生成候选区域
3.1 候选区域
候选区域 (Region proposal) 也称区域提议,要了解什么是候选区域,我们首先需要了解什么是区域,在目标检测上下文中,区域是整个图像的一部分,且该部分中的像素值非常相似。而候选区域是整个图像中较小的部分,且该部分包含特定目标对象的可能性较高。候选区域对于目标定位非常重要,因为我们需要从图像中提取候选对象,而对象位于这些区域之中的几率很高。接下来,我们将通过研究为图像内的人物生成边界框来学习如何生成候选区域。
3.2 选择性搜索
选择性搜索是在对象检测中常用的区域提议算法,它的运行速度很快,且具有很高的召回率。它首先将图片划分成很多小区域,然后基于颜色、纹理、大小和形状相似度合并这些小区域得到较大的尺寸区域。候选区域可以使用一个名为 selectivesearch 的 Python 库生成。
selectivesearch 库中的选择性搜索通过使用 Felzenszwalb 和 Huttenlocher 的基于图的分割方法,基于像素的强度对图像进行分割,生成数千个候选区域。然后,选择性搜索算法将这些分割后的区域作为初始输入,迭代执行以下步骤:
- 将分割后的区域相对应的所有边界框添加到候选区域列表中
- 根据相似度将相邻的小区域分组
- 在每次迭代中,将形成较大的区域并将其添加到候选区域列表中。因此,我们采用自下而上的方法创建了从较小区域到较大区域的候选区域
- 选择性搜索使用基于颜色,纹理,大小和形状的四个相似性度量来合并生成候选区域
候选区域有助于识别图像中可能感兴趣的对象。因此,我们可以将定位操作转换为分类操作,将每个区域分类为是否包含感兴趣的目标对象。
3.3 使用选择性搜索生成候选区域
在本节中,我们利用选择性搜索提取图像中的候选区域。
首先,像安装其他第三方库一样安装 selectivesearch:
pip install selectivesearch
导入相关的库,并加载图像:
import matplotlib.pyplot as plt
import cv2
import selectivesearch
img = cv2.imread('4.png')
提取候选区域:
img_lbl, regions = selectivesearch.selective_search(img, scale=100, min_size=2500)
参数 min_size 用于限制候选区域的大小,此处限制其至少应为 2500 像素,参数 scale 设置有效的观察范围,较大的 scale 会导致偏向于生成较大区域。
检查最终获取的候选区域数,并将区域大小大于 2500 像素的所有区域存储到候选项元组 candidates 中:
print(len(regions))
candidates = set()
for r in regions:
if r['rect'] in candidates:
continue
# 排除小于2500像素的区域
if r['size'] < 2500:
continue
x, y, w, h = r['rect']
candidates.add(r['rect'])
利用 candidates 绘制结果图像:
import matplotlib.patches as mpatches
fig, ax = plt.subplots(ncols=1, nrows=1, figsize=(6, 6))
ax.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
for x, y, w, h in candidates:
rect = mpatches.Rectangle(
(x, y), w, h, fill=False, edgecolor='red', linewidth=1)
ax.add_patch(rect)
plt.show()
绘制的结果图像如下所示,可以看出,我们从图像中提取了多个区域:

4. 交并比 (Intersection over Union, IoU)
4.1 目标检测模型性能评估标准
为了了解所提取候选区域的准确性,我们使用了一个名为“交并比” (Intersection over Union, IoU) 的度量,IoU 计算方式如下所示:

在上图中,蓝色框是标注的目标边界框,红色框是候选区域。计算候选区域的交并比为候选框和标注框的交集与候选框与标注框的并集的比。接下来,我们详细介绍并实现 IoU 的计算过程。
4.2 IoU 计算过程
根据以上 IoU 定义,编写 IoU 计算函数,如以下代码所示:
from copy import deepcopy
import numpy as np
import cv2
import matplotlib.pyplot as plt
import selectivesearch
def calc_iou(candidate, current_y, img_shape):
boxA = deepcopy(candidate)
boxB = deepcopy(current_y)
img1 = np.zeros(img_shape)
img1[int(boxA[1]):int(boxA[3]), int(boxA[0]):int(boxA[2])] = 1
img2 = np.zeros(img_shape)
img2[int(boxB[1]):int(boxB[3]), int(boxB[0]):int(boxB[2])] = 1
iou = np.sum(img1*img2) / (np.sum(img1) + np.sum(img2) - np.sum(img1*img2))
return iou
在函数中,我们将候选目标边界框,实际目标边界框和图像尺寸作为输入,首先初始化了两个形状与图像尺寸相同的零值数组,并用值 1 覆盖候选目标区域和实际目标区域内的值。最后,我们计算了候选目标区域与实际目标区域的交并比。
4.3 计算图像中候选区域和实际区域交并比
导入需要计算的图像:
img = cv2.imread('4.png')
绘制图像并观察目标对象的实际位置,从图中可以看出,目标人物在 x 轴上大约从左下角 x=300 开始到 x=590,在 y 轴上,其大约从 y=50 开始到 y=500。因此,对象的实际位置是 (50, 50, 290, 500),使用的格式为 (xmin, ymin, xmax, ymax):
plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
plt.show()

提取候选区域,方法与在第 3 小节中介绍的相同:
img_lbl, regions = selectivesearch.selective_search(img, scale=100, min_size=2500)
print(len(regions))
candidates = set()
for r in regions:
if r['rect'] in candidates:
continue
# 排除小于2500像素的区域
if r['size'] < 2500:
continue
x, y, w, h = r['rect']
candidates.add(r['rect'])
从 selectivesearch 方法提取的区域的格式为 (xmin, ymin, width, height)。因此,在计算区域的 IoU 之前,应确保候选区域的位置和实际标记区域具有相同的格式,即 (xmin, ymin, xmax, ymax)。
将 IoU 计算函数应用于加载的图像,该函数将实际对象区域和候选区域作为输入:
regions = list(candidates)
actual_bb = [300, 10, 590, 390]
iou = []
for i in range(len(regions)):
candidate = list(regions[i])
candidate[3] += candidate[1]
candidate[2] += candidate[0]
iou.append(calc_iou(candidate, actual_bb, img.shape))
确定与实际对象区域重叠度最高的候选区域:
index = np.argmax(iou)
# 打印相关信息
print(index)
print(iou[index])
我们在此加载的图像中,候选区域中交并比最高的区域索引为 4,其值为 0.8862138765666049,区域坐标为 (305, 29, 294, 370),格式为 (xmin, ymin, width, height)。
最后,我们在图像中绘制实际边界框和候选边界框,我们必须将实际边界框的 (xmin, ymin, xmax, ymax) 格式转换为 (xmin, ymin, width, height):
max_region = list(regions[index])
actual_bb[2] -= actual_bb[0]
actual_bb[3] -= actual_bb[1]
添加具有最高 IoU 的候选边界框与真实边界框:
max_candidate_actual = [max_region, actual_bb]
最后,遍历前面的列表,并使用矩形框绘制图像中对象的实际区域和候选区域,其中实际区域使用红色表示,候选框使用蓝色表示:
import matplotlib.patches as mpatches
fig, ax = plt.subplots(ncols=1, nrows=1, figsize=(6, 6))
ax.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
for i,(x, y, w, h) in enumerate(max_candidate_actual):
if(i==0):
rect = mpatches.Rectangle(
(x, y), w, h, fill=False, edgecolor='blue', linewidth=2)
ax.add_patch(rect)
else:
rect = mpatches.Rectangle(
(x, y), w, h, fill=False, edgecolor='red', linewidth=2)
ax.add_patch(rect)
plt.show()
经过以上步骤,我们就可以利用图像中对象的实际位置来计算每个候选区域的 IoU,并可以获取具有最高 IoU 的候选区域,来定位图像中目标位置。

小结
目标检测一直是计算机视觉领域最具有挑战性的问题之一,同时也是具有广泛应用场景的任务之一。本节中,首先介绍了目标检测的基本概念,然后介绍了如何制作用于训练目标检测模型的数据集,最后讲解了如何生成候选区域和常用于目标检测模型性能评估的指标。通过介绍目标检测中的相关技术,为接下来实现目标检测算法奠定基础。
系列链接
Keras深度学习实战(1)——神经网络基础与模型训练过程详解
Keras深度学习实战(2)——使用Keras构建神经网络
Keras深度学习实战(3)——神经网络性能优化技术
Keras深度学习实战(4)——深度学习中常用激活函数和损失函数详解
Keras深度学习实战(5)——批归一化详解
Keras深度学习实战(6)——深度学习过拟合问题及解决方法
Keras深度学习实战(7)——卷积神经网络详解与实现
Keras深度学习实战(8)——使用数据增强提高神经网络性能
Keras深度学习实战(9)——卷积神经网络的局限性
Keras深度学习实战(10)——迁移学习
Keras深度学习实战(11)——可视化神经网络中间层输出
Keras深度学习实战(12)——面部特征点检测
以上是关于Keras深度学习实战(13)——目标检测基础详解的主要内容,如果未能解决你的问题,请参考以下文章