Java链表详解--通俗易懂(超详细,含源码)
Posted 噜噜噜噜鲁先生
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java链表详解--通俗易懂(超详细,含源码)相关的知识,希望对你有一定的参考价值。
目录
方法二:头插法public void addFirst(int data)
方法三:尾插法public void addLast(int data)
4.查找是否包含关键字key是否在单链表当中:public boolean contains(int key)
6.任意位置插入,第一个数据节点为0号下标:public boolean addIndex(int index,int data)
7.删除第一次出现关键字为key的节点:public void remove(int key)
8.删除所有值为key的节点:public void removeAllKey(int key)
概念
链表(linked list):是一种物理存储结构上非连续存储结构,数据元素的逻辑顺序是通过链表中的引用链接次序实现的.
链表由一系列结点(链表中每一个元素称为结点)组成,结点可以在运行时动态生成。每个结点包括两个部分:一个是存储数据元素的数据域,另一个是存储下一个结点地址的指针域。 相比于线性表顺序结构,操作复杂。由于不必须按顺序存储,链表在插入的时候可以达到O(1)的复杂度,比另一种线性表顺序表快得多,但是查找一个节点或者访问特定编号的节点则需要O(n)的时间,而线性表和顺序表相应的时间复杂度分别是O(logn)和O(1)。
链表的分类
- 单向链表,双向链表
- 带头链表,不带头链表
- 循环的,非循环的
排列组合后一共有
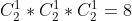
即一共8种链表,其中单向、不带头、非循环以及双向、不带头、非循环的链表最为重要,也是本文主要介绍的链表类型。
链表的结构
对于链表的结构,可以用如下这个图来模拟。
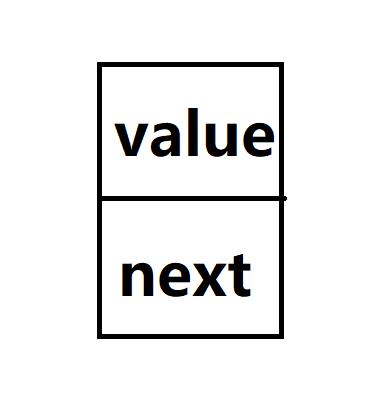
图中所示的为链表的一个节点,value是这个节点的所存储的数据值,next为下一节点的地址。
下面是一个5个节点的链表。
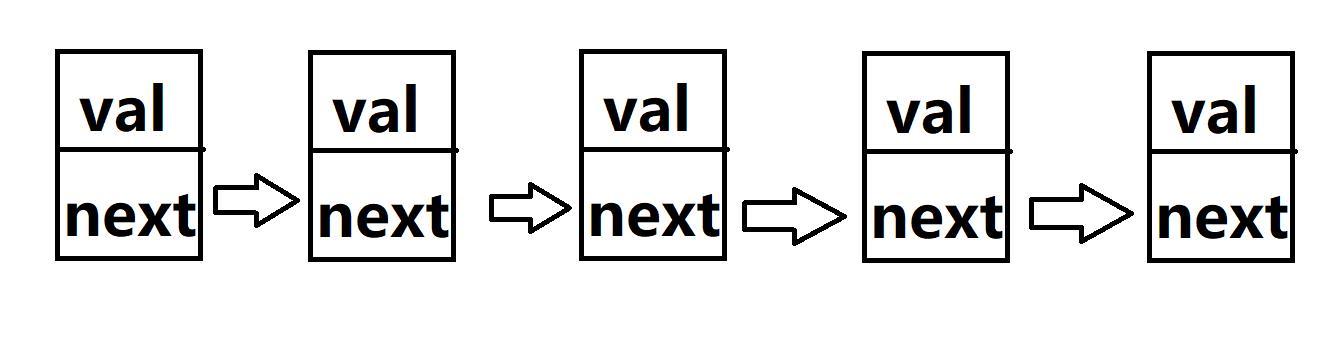
接下来,我们来实现这样的链表的增删查改:
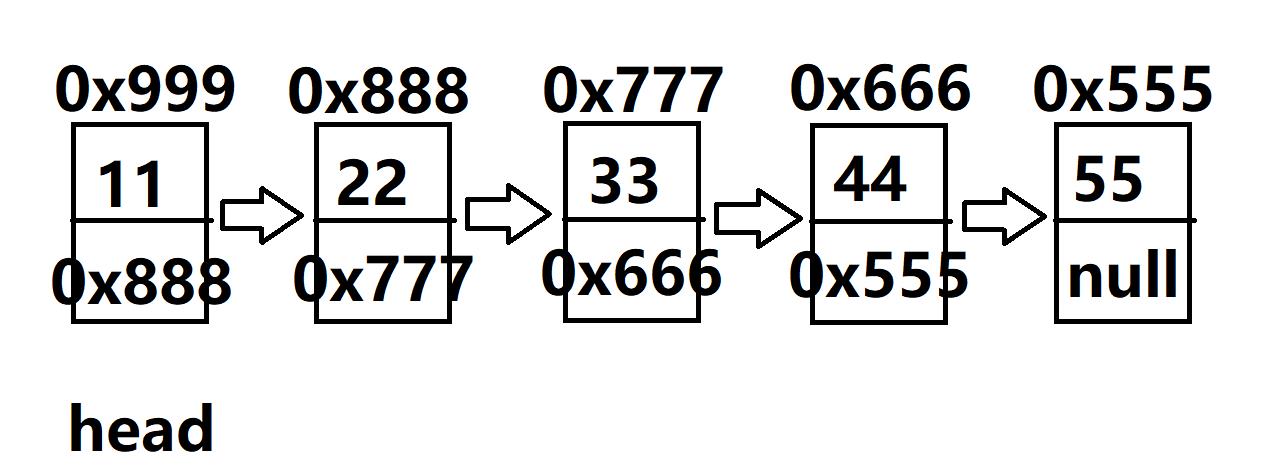
第一个节点,地址假设是0x999,存储的数据是11,next存储的是下一个节点的地址(假设是0x888)
第二个节点,地址假设是0x888,存储的数据是22,next存储的是下一个节点的地址(假设是0x777)
第三个节点,地址假设是0x777,存储的数据是33,next存储的是下一个节点的地址(假设是0x666)
第四个节点,地址假设是0x666,存储的数据是44,next存储的是下一个节点的地址(假设是0x555)
第五个节点,地址假设是0x555,存储的数据是55,由于没有后续节点,next存储的是空指针null
定义一个head,存储头节点(第一个节点)的地址(假设为0x999)。
代码实现链表
1.创建节点类
节点由val域(数据域),以及next域(指针域)组成,对于next域,其是引用类型,存放下一个节点的地址,故
用public ListNode next来创建next。
同时设置构造函数,方便对val进行初始化。
//ListNode代表一个节点
class ListNode
public int val;
public ListNode next;
//构造函数
public ListNode(int a)
this.val = a;
2.创建链表
-
方法一:枚举法(略简单,略low)
public class MyLinkedList
public ListNode head;//链表的头
public void creatList()
ListNode listNode1 = new ListNode(11);
ListNode listNode2 = new ListNode(22);
ListNode listNode3 = new ListNode(33);
ListNode listNode4 = new ListNode(44);
ListNode listNode5 = new ListNode(55);
this.head = listNode1;
listNode1.next = listNode2;
listNode2.next = listNode3;
listNode3.next = listNode4;
listNode4.next = listNode5;
直接进行val的赋值以及对next的初始化。
注意:不用对最后一个节点的next进行赋值,因为next是引用类型,不赋值则默认为null。
-
方法二:头插法public void addFirst(int data)
头插法是指在链表的头节点的位置插入一个新节点,定义一个node表示该节点,然后就是对node的next进行赋值,用node.next = this.head即可完成(注意:head应指向新节点)
代码实现
public void addFirst(int data)
ListNode node = new ListNode(data);
node.next = this.head;
this.head = node;
-
方法三:尾插法public void addLast(int data)
尾插法是指在链表的尾节点的位置插入一个新节点,定义一个node表示该节点,然后就是对原来最后一个节点的next进行赋值,先将head移动至原来最后一个节点,用head.next = node进行赋值(注意,如果链表不为空,需要定义cur来代替head)
代码实现
public void addLast(int data)
ListNode node = new ListNode(data);
if(this.head == null)
this.head = node;
else
ListNode cur = this.head;
while(cur.next != null)
cur = cur.next;
cur.next = node;
3.打印链表:public void display()
认识了链表的结构,我们可以知道,节点与节点之间通过next产生联系。并且我们已将创建了head,即头节点的地址,通过head的移动来实现链表的打印。
注意:为了使head一直存在且有意义,我们在display()函数中定义一个cur:ListNode cur = this.head;来替代head。
对于head的移动,可用head = head.next来实现。
代码实现:
public void display()
ListNode cur = this.head;
while(cur != null)
System.out.print(cur.val+" ");
cur = cur.next;
System.out.println();
4.查找是否包含关键字key是否在单链表当中:public boolean contains(int key)
查找key,可以利用head移动,实现对于key的查找(注意:同样要定义一个cur来代替head)
代码实现
public boolean contains(int key)
ListNode cur = this.head;
while(cur != null)
if(cur.val == key)
return true;
cur = cur.next;
return false;
5.得到单链表的长度:public int Size()
定义计数器count = 0,通过head的移动来判断链表长度(注意:同样要定义一个cur来代替head)
代码实现
public int Size()
int count = 0;
ListNode cur = this.head;
while(cur != null)
count++;
cur = cur.next;
return count;
6.任意位置插入,第一个数据节点为0号下标:public boolean addIndex(int index,int data)
比如,我们把一个值为1314,地址是0x520(设为node引用)的节点,即val域值为1314,next域为null,地址是520,将该节点插入至3号位置,
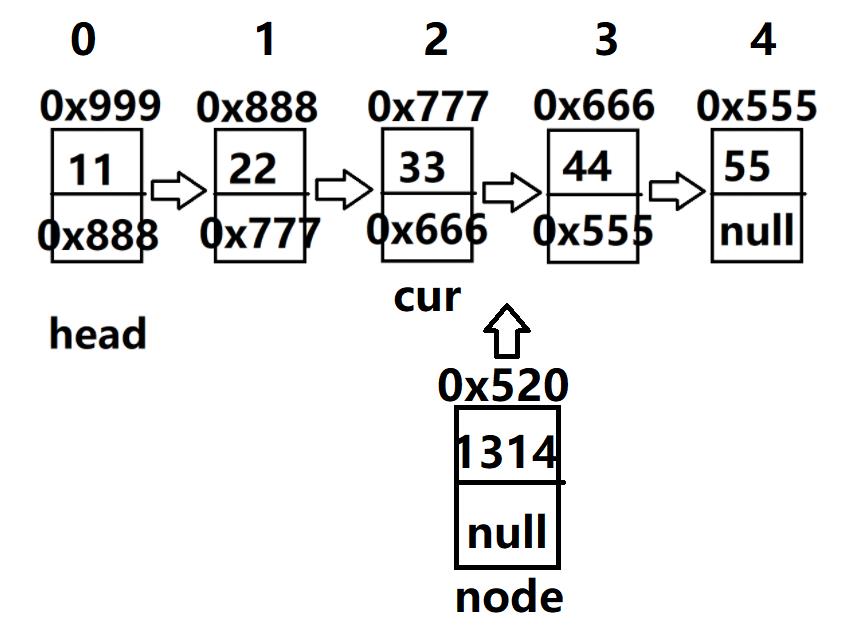
经过分析,需要将head先移至2号位置(注意:用cur代替head,防止head丢失),然后
node.next = cur.next使该节点的next域改为下一节点的地址,再cur.next = node.next使前一节点
的next域改为该节点的地址。
public void addIndex(int index,int data)
if(index < 0 ||index > Size()) //对index位置的合法性进行判断
return;
if(index == 0) //相当于头插法
addFirst(data);
return;
if(index = Size()) //相当于尾插法
addLast(data);
return;
ListNode cur = findIndex(index);//找到index位置前一位置的地址
ListNode node = new ListNode(data);//初始化node
node.next = cur.next;
cur.next = node;
7.删除第一次出现关键字为key的节点:public void remove(int key)
对于删除第一次出现的key值的节点,若不是头节点,我们只需将key值对应的节点的前一节点的next的域改为key值对应的节点的next域即可。
对于头节点,直接head = head.next即可。
对于key值对应的节点的前一节点,我们可以写一个函数来找到它,方便后续的代码书写。
//找到key的前驱(前一节点)
public ListNode searchPrev(int key)
ListNode cur = this.head;
while(cur.next != null)
if(cur.next.val == key)
return cur;
cur = cur.next;
return null;
//删除第一次出现关键字为key的节点
public void remove(int key)
if(this.head == null)
return;
if(this.head.val == key)
this.head = this.head.next;
return;
ListNode cur = searchPrev(key);
if(cur == null)
return; //没有要删除的节点
ListNode del = cur.next;//定义要删除的节点
cur.next = del.next;
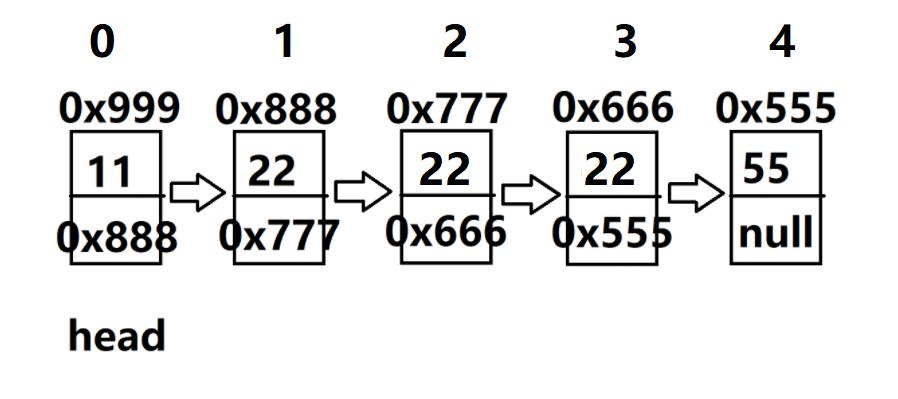
8.删除所有值为key的节点:public void removeAllKey(int key)
若要删除所有值为key的节点,其实我们只需多次调用上面所写的remove函数即可完成,但是,
若要达到面试难度,那么要求就是遍历一遍链表,删除所有值为key的节点。
情况一:key连续,如下(1,2,3节点)
情况二:key不连续,如下(1,3节点)
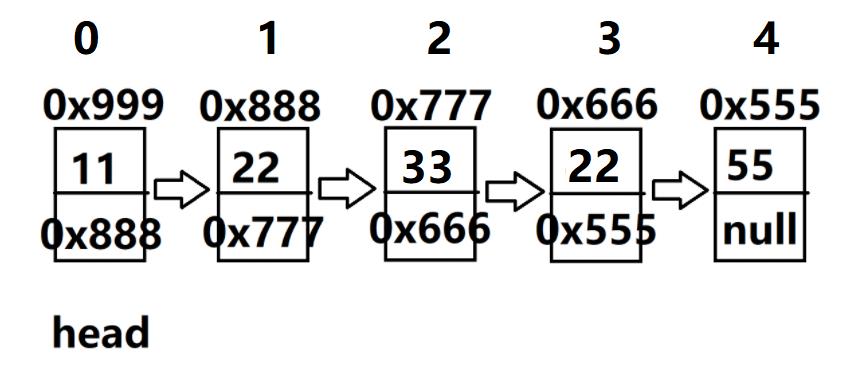
代码实现:
public ListNode removeAllKey(int key)
if(this.head = null)
return null;
ListNode prev = this.head;
ListNode cur = this.head.next;
while(cur != null)
if(cur.val == key)
prev.next = cur.next;
cur = cur.next;
else
prev = cur;
cur = cur.next;
if(this.head.val == key)
this.head = this.head.next;
return this.head;
9.清空链表:public void clear()
1.简单粗暴的方法:将头节点置为空head = null;即可
2.细腻温柔的做法:将每一个节点都置为空
public void clear()
while(this.head != null)
ListNode curNext = this.head.next;
this.head.next = null;
this.head = curNext;
源码
import java.util.List;
//ListNode代表一个节点
class ListNode
public int val;
public ListNode next;
//构造函数
public ListNode(int a)
this.val = a;
public class MyLinkedList
public ListNode head;//链表的头
public void creatList()
ListNode listNode1 = new ListNode(11);
ListNode listNode2 = new ListNode(22);
ListNode listNode3 = new ListNode(33);
ListNode listNode4 = new ListNode(44);
ListNode listNode5 = new ListNode(55);
this.head = listNode1;
listNode1.next = listNode2;
listNode2.next = listNode3;
listNode3.next = listNode4;
listNode4.next = listNode5;
//头插法
public void addFirst(int data)
ListNode node = new ListNode(data);
node.next = this.head;
this.head = node;
/*if(this.head == null)
this.head = node;
else
node.next = this.head;
this.head = node;
*/
//尾插法
public void addLast(int data)
ListNode node = new ListNode(data);
if (this.head == null)
this.head = node;
else
ListNode cur = this.head;
while (cur.next != null)
cur = cur.next;
cur.next = node;
//打印顺序表
public void display()
ListNode cur = this.head;
while (cur != null)
System.out.print(cur.val + " ");
cur = cur.next;
System.out.println();
//查找是否包含关键字key是否在单链表当中
public boolean contains(int key)
ListNode cur = this.head;
while (cur != null)
if (cur.val == key)
return true;
cur = cur.next;
return false;
//得到单链表的长度
public int Size()
int count = 0;
ListNode cur = this.head;
while (cur != null)
count++;
cur = cur.next;
return count;
//找到index位置的前一位置的地址
public ListNode findIndex(int index)
ListNode cur = head.next;
while (index - 1 != 0)
cur = cur.next;
index--;
return cur;
//任意位置插入,第一个数据节点为0号下标
public void addIndex(int index, int data)
if (index < 0 || index > Size())
return;
if (index == 0) //相当于头插法
addFirst(data);
return;
if (index == Size()) //相当于尾插法
addLast(data);
return;
ListNode cur = findIndex(index);//找到index位置前一位置的地址
ListNode node = new ListNode(data);//初始化node
node.next = cur.next;
cur.next = node;
//找到key的前驱(前一节点)
public ListNode searchPrev(int key)
ListNode cur = this.head;
while (cur.next != null)
if (cur.next.val == key)
return cur;
cur = cur.next;
return null;
//删除第一次出现关键字为key的节点
public void remove(int key)
if (this.head == null)
return;
if (this.head.val == key)
this.head = this.head.next;
return;
ListNode cur = searchPrev(key);
if (cur == null)
return; //没有要删除的节点
ListNode del = cur.next;//定义要删除的节点
cur.next = del.next;
//删除所有值为key的节点
public ListNode removeAllKey(int key)
if (this.head = null)
return null;
ListNode prev = this.head;
ListNode cur = this.head.next;
while (cur != null)
if (cur.val == key)
prev.next = cur.next;
cur = cur.next;
else
prev = cur;
cur = cur.next;
if (this.head.val == key)
this.head = this.head.next;
return this.head;
//清空链表
public void clear()
while (this.head != null)
ListNode curNext = this.head.next;
this.head.next = null;
this.head = curNext;
c语言指针用法及实际应用详解,通俗易懂超详细!
大家好,我是无际。
今天给大家来讲解一下指针。
我会由浅到深,最后结合实际应用讲解,让大家学会指针的同时,知道大佬们都用指针来干嘛!
长文预警!全文大约5200多字,学指针看这篇文章就够了!
很多人跟我刚学习c语言一样,都害怕指针。
我也是后面做了一些物联网网关才知道,指针是c语言的灵魂这句话真正含义。
没有指针,很多功能实现起来确实很不方便,比如做不到真正的模块化编程。
Ok,废话不多说,下面正式进入主题。
一、通过这篇文章你能掌握以下知识:
- 指针的相关概念
- 掌握指针与数组之间的关系
- 掌握指针指向的指针
- 掌握如何使用指针变量做函数参数
- 掌握如何使用指针函数
- 掌握如何使用数组指针函数
那么这篇文章对应有视频教程,如果不喜欢看文章的可以去看视频,教程在小破站可以搜无际单片机编程找到,也可以找我们拿。
二、指针的作用:
指针是C语言中一个比较重要的东西,有人说指针是C语言的灵魂这句话说的一点也没错。
正确灵活地运用它,可以有效地表达一些复杂的数据结构,比如系统地动态分配内存、消息机制、任务调度、灵活矩阵定时等等。
掌握指针可以使你的程序更加简洁、紧凑、高效。
那么在单片机领域,如果是做稍微大一点的项目,需要把每个功能做成模块化,硬件驱动层和应用层分别独立运行。
即使更换单片机型号也不用修改应用层程序,即移植性非常强,这些都离不开指针。
甚至没指针会很难实现,即使实现代码的可移植性也很差。
三、指针的概念
前面讲了指针的作用,这里再强调一点,指针是一把双刃剑。
用好了能十分灵活而且提高程序的效率,但是如果使用不当,则会出现程序”死机”等致命问题。
而这些问题往往是由于错误地使用指针而造成的,最常见的就是内存溢出错误,指针指向未知地址。
1.地址与指针
指针是一个比较抽象地概念,如果想真正了解指针,那么要先从数据是如何存储的说起,我们通过一个图来看一下数据在内存里存储的情况。

在这个图中,都是以16进制显示。
红色标注的0x00000400代表地址内存地址,绿色37,30代表数据,而橙色标注的00 01代表地址递增量,即代表0x00000400和0x00000401,每个地址存储1个字节数据。
那么我们把这个图看作是数据在内存里的存储形式,0x00000400这个内存地址存储着数据37,0x00000401这个内存地址存储着数据30。
当我们在程序里定义一个字节的变量,那么在编译器编译时就会给这个变量分配一个这样的内存地址来存储。
假设我们定义以下变量
unsigned char a;
a = 0x37;
对应这个图就是,编译器在编译时会为变量a分配一个字节的内存空间并把0x37这个数据存储进去,并将变量名a改成地址0x00000400,以便CPU的访问。
通过这个地址就能找到变量a数据的存储位置,而这个地址0x00000400其实就是指针,通过这个指针可以访问变量a的数据。
2.指针变量
通过上面讲解我们明白了通过地址能访问内存的数据,这个地址啊就是指针。
那么指针和指针变量呢是不一样的概念,大家一定要记住了。
指针是概念、指针变量是这个概念的具体应用之一,我们先来看一下C语言里怎么定义指针变量。
指针变量定义的一般形式:
变量类型 *变量名
unsigned char *p;
通过这种语法,我们就能够定义一个指针变量p。
指针变量赋值
指针和指针变量是两个概念,指针变量跟普通变量一样,在使用前一定要定义和赋值(指向地址)。
给指针变量赋的值和普通变量不同,给指针变量赋值只能赋地址,而不能赋予其他任何值,否则会引起错误。
那么怎么获取普通变量的地址呢,在C语言里可以使用”&”来获取普通变量的地址,一般用以下格式来表示:
&变量名
那么通过&变量名取得变量地址后就可以赋值给指针变量。
举例:
unsigned char a;
unsigned char *p
int main()
{
p = &a;
}
这个代码里,我们定义了一个变量a, 定义了一个指针变量p。
我们通过运算符&把变量a的内存地址赋值给变量p,所以p指向了变量a的内存存储地址。
上面说了指针变量赋值的问题,那么怎么获取和改变指针变量指向那个内存地址的数据呢? 我们可以通过:
*指针变量 = 数值
如:*p = 10;
这样的操作可以改变指针变量指向那个内存地址的数据。
通过:
a = *p;
来获取指针变量指向那个内存地址的数据。
下面我们通过一个代码实验来举例。

这里我们定义了变量a和指针变量p,然后a的值初始化为10。
把a的地址赋值给指针变量p,接着我们输出a的地址是0x60ff33。
由于前面我们把a的地址赋值给了指针变量p,所以p指向的地址也是0x60ff33。
那么我们再来看一下,指针变量的在内存里的存储地址是0x60ff2c。
所以大家这里要注意了,我们定义指针变量时,即便指针变量是指向地址用的,但是编译器也会分配一块内存地址来存储指针变量。
我们接着来看下变量a的输出值。
a=10, *p是获取指针指向内存地址的数据,所以也是10。
下面就是通过指针变量来改变变量a的值,因为指针变量p指向的是变量a的地址,所以改变指针变量p指向内存地址的数据就可以改变变量a的值。
那么通过这么原理,我们是不是不用指针变量,也不用a等于多少来改变a的值呢? 当然可以!
我们看下面通过内存地址改变变量a的值,我们前面知道a的地址是0x60ff33,那我们可以直接写0x60ff33=12来改变变量a的值。
当然这里要注意,编译器编译时并不知道0x60ff33是什么东西,所以要把这个整形地址转换成指针类型。
最后通过*+地址语法改变这个地址里面的数据。
我们看输出结果,可以发现a的值已经成功被改成了12。
其实通过指针变量改变某个内存地址的数据就是这个原理,但是指针变量好处可以任意起名字。
也不用像这样先把变量a的地址读出来,然后通过地址去改变它的值,用起来就很方便,所以通过指针变量来替代了这种做法。
四、数组与指针
一般系统或编译器会分配连续地址的内存来存储数组里的元素,如果把数组地址赋值给指针变量,那么就可以通过指针变量来引用数组,读写数组里的元素了。我们来做个实验:

从这个代码来看,定义了一个数组buff并初始化为1,2,3,4,5。
定义了2个指针变量p1和p1,分别指向buff, &buff[0]。
buff默认的是数组下标为0元素的存储地址。
所以这里buff和&buff[0]是同一个内存地址,只是写法不一样。
我们从输出结果可以看的出来,数组和指针变量的地址都是一样的,所以大家用这几种写法都是可以的。
那么我们来看下输出结果,都是1,说明操作是对的。
指针自加自减运算
指针变量除了可以用来获取内存地址的值以外,还可以用来进行加减运算。
但是这个加减呢跟普通变量加减不一样,普通变量加减的是数值,而指针变量加减的是地址,我们来通过代码来讲解下。

同样这里定义了数组buff并初始化为1,2,3,4,5。
我们把指针变量p1指向数组第一个元素的地址,即0x402000。
然后我们直接看p1++的操作,p1++后我们看到p=0x402001,所以指针变量的加减等运算是指向地址的运算。
其他减法乘除法也是基于地址的运算。
二维数组与指针
通过一维数组与指针的讲解,相信大家已经掌握。
那么二维数组与指针的操作也是一样的, 二维数组和一维数组一样,都是分配连续的地址来存储的数据的。
我们还是通过一个例子来实践一下:

首先我们定义了一个二维数组buff和指针变量p1。
p1指向二维数组的[0][0]这个元素地址,这个就是为这个数组分配时的首地址。
然后打印二维数组里每个元素的地址和值,接着打印指针变量地址和值,这些就是指针和二维数组的用法,比较简单,这些代码大家可以去做下实验。
五、指向指针的指针
一个指针变量指向整型变量或者字符型变量,当然也可以指向指针变量,这种指针变量用于指向指针类型变量时,就称为指向指针的变量,也叫双重指针。
定义方法:
数据类型 **指针变量名;
例如:unsigned char **p;
这个含义就是定义一个指向指针的指针变量p,它指向另一个指针变量,我们通过代码来说明一下会更好理解一点。
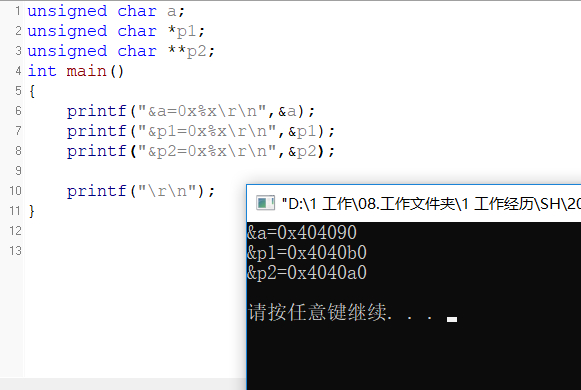
我们定义一个变量a, 定义一个指针变量p1,定义一个双重指针变量p2,然后打印这3个变量的内存地址。
编译器在编译的时候呢,也会为指针变量和双重指针变量分配一个存储空间。
虽然指针变量是指向别的内存地址的,但是变量本身还是需要一个地址空间来存储的。
指针容易把人搞晕的就是,指针变量本身的存储地址和指向的地址分不清楚,这个是两个概念,大家要记住了。
下面我们通过实验来看下双重指针怎么用:

这里我们定义了变量a并初始化值为10,指针变量p1,双重指针变量p2。
我们把p1指向变量a,p2指向变量p1的存储地址,这里要注意,不是p1指针指向的地址。
然后我们打印看下结果,可以看到a的地址是0x404090。
指针变量p1的存储地址通过&运算符获得即0x4040b0,p1指向a的地址,所以p1也等于0x404090。
所以指针变量分为存储地址和指向地址,这两个是不一样的概念。
而p2是双重指针,p2指向p1的存储地址0x4040b0,通过*p2获得0x4040b0这个地址里指向的地址0x404090,即p1指向的地址或变量a的地址。
再通过**p2来获取0x404090地址里的值,得到10。
这里还有一个问题需要注意,”*”这个运算符是从右到左进行运算的。
所以,**p2就是*(*p2),先取指向地址,再取指向地址里面存储的值。
一般在单片机程序中,尽量少使用这种指向指针的指针,防止出现Bug的时候非常难排查,目前我就在队列中使用过。
六、指针变量作为函数形参
一般我们都是以字符型、整型、数组等作为函数的形参带入。
除此以外,指针变量也可以作为形参使用,而且用的非常多,主要目的是为了改变指针指向地址的值,专业术语是通过形参改变实参的值。
我们直接写个代码来举个例子:

这个代码中,我们定义一个SetValue函数,并且形参为指针变量p1。
我们调用SetValue时把&a的地址赋值给形参指针变量p1。
当我们通过*p1=5后就能把p1指向地址的值改成5,所以a的值也从1变成了5。
这个就是指针变量作为函数形参的一种作用。
实际当中使用功能当然不会这么简单。
比如说我们常用的memset库函数,他的原型就是:
Void *memset(void *s, int ch, size_t n);
这个函数的作用是给某个数组或者结构体初始化用的。
那么这个函数就使用了无指定数据类型的指针变量s,这样我们就可以很轻易的把实现某些功能的代码封装起来,使用者不用关心功能代码的实现,只需要了解函数怎么用即可。
这样的话代码很简洁紧凑,移植性也好,这是把指针作为形参的一种作用,不过这些都只是冰山一角,在后面的学习当中,你会慢慢发现指针的魅力和强大。
七、函数指针
如果在程序中定义了一个函数,那么在编译时系统就会为这个函数代码分配一段存储空间,这段存储空间的首地址称为这个函数的地址。
而且函数名表示的就是这个地址。
既然是地址我们就可以定义一个指针变量来存放,这个指针变量就叫作函数指针变量,简称函数指针。
在这个章节我们大家只要学会怎么定义和使用就行了,后面章节课程我们无际单片机编程会教大家函数指针的一些实际应用。
我们学东西主要还是看能运用在哪里是吧?
后面我会教大家如何用这些知识点让我们的程序写的更好,更加系统的教程可以到公号【无际单片机编程】拿到。
那么这个函数指针怎么定义呢?我们定义函数指针的格式如下:
函数返回值类型 (* 指针变量名) (函数参数列表);

这样就定义了一个函数指针变量func, 该函数指针返回值为unsigned char类型,然后有2个形参,分别是unsigned char类型。
那么我们定义了这个函数指针变量以后要怎么使用呢?我们写个代码来解析一下。
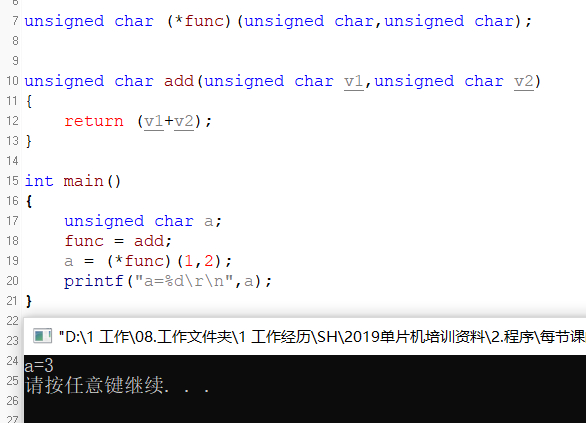
我们看下这个代码,首先我们定义一个函数指针func,再定义一个加法函数add,函数返回值为形参1+形参2的值。
然后我们把func指向加法函数add,因为函数名称就是函数首地址,所以我们直接func=add就可以实现func指向add了。
接着(*func)(1,2)代表执行func函数指针指向的函数,所以结果等于3。
函数指针func的返回参数和形参不一定要和函数add定义成一样,func也可以不设置返回值或者形参,但是一般不建议这样做,避免引起一些不必要的错误。
那么这里呢其实还有一个知识点要和大家说一下,我们先来写一段代码:

这段代码调用函数指针的时候没有使用(*func)(1,2),这种用法也是可以的,执行的效果是一样,那么到底有什么区别呢?
其实这个是编译器实现的问题,我们不用去纠结这种对我们没有意义的东西,除非你想去做编译器。
大家只要记住函数指针是这样用的就行了。
后期应用时再把它们多练几遍,以后做产品都用上,那么基本就熟了,而且产品的程序架构也更好了。
七、函数指针数组
像字符型,整形都是可以单独定义,也可以定义成数组,同样函数指针也可以定义成数组,同样,这里我们不讲那么多理论上的概念,直接记住怎么定义,怎么使用、用在哪里就行了。
函数指针数组定义格式如下:
函数返回值类型 (* 指针变量名[数组大小]) (函数参数列表);
我们用程序表示如下:

这样就定义了一个可以指向3个函数的函数指针数组。
定义了以后,我们函数指针需要赋值,赋值的意思就是让它们指向函数首地址,一般初始化的方式有两种。

这是第一种,定义函数指针数组的时候直接初始化。

这是第二种,先定义然后再初始化,这里我们主要是要记住它们这两种的写法就行了。
函数指针数组赋值以后通过以下代码来执行。
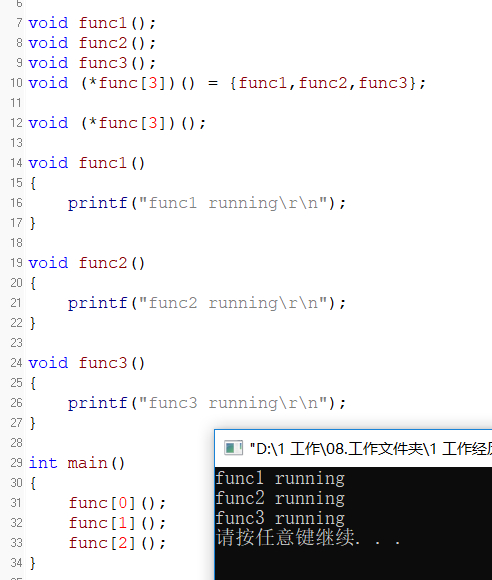
我们可以看到直接写func[0]();就可以执行函数指针数值指向的函数了。
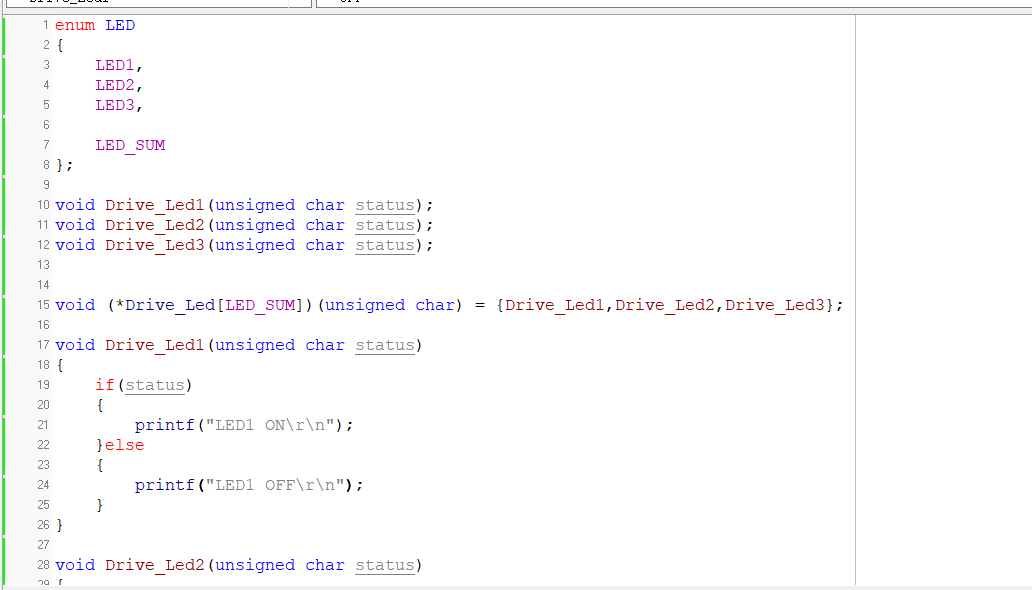
那么这种函数指针数组到底有什么用呢?
其实真正产品应用中函数指针数组是非常有用的。
我举一个例子,写控制5个LED灯亮的函数,如果用传统方式,流程是先要判断控制哪个LED,然后再控制指定GPIO口高低电平。
而函数指针只要一条语句,这就是所谓的代码的简洁、紧凑的特点,代码简洁紧凑以后自然也能节约cpu和内存的资源。
下面是演示代码:

Ok,终于码完了,这篇文章整整写了几天,各位看官给我来个三连鼓励吧,爱你们哟!
以上是关于Java链表详解--通俗易懂(超详细,含源码)的主要内容,如果未能解决你的问题,请参考以下文章