yolov5 优化系列:修改损失函数
Posted weixin_50862344
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了yolov5 优化系列:修改损失函数相关的知识,希望对你有一定的参考价值。
1.使用 Focal loss
在util/loss.py中,computeloss类用于计算损失函数
# Focal loss
g = h['fl_gamma'] # focal loss gamma
if g > 0:
BCEcls, BCEobj = FocalLoss(BCEcls, g), FocalLoss(BCEobj, g)
其中这一段就是开启Focal loss的关键!!!
parser.add_argument('--hyp', type=str, default=ROOT / 'data/hyps/hyp.scratch-low.yaml', help='hyperparameters path')
使用的data/hyps/hyp.scratch-low.yaml为参数配置文件,进去修改fl_gamma即可

fl_gamma实际上就是公式中红色椭圆的部分
看看代码更易于理解:
def forward(self, pred, true):
loss = self.loss_fcn(pred, true)
# p_t = torch.exp(-loss)
# loss *= self.alpha * (1.000001 - p_t) ** self.gamma # non-zero power for gradient stability
# TF implementation https://github.com/tensorflow/addons/blob/v0.7.1/tensorflow_addons/losses/focal_loss.py
pred_prob = torch.sigmoid(pred) # prob from logits
p_t = true * pred_prob + (1 - true) * (1 - pred_prob)
alpha_factor = true * self.alpha + (1 - true) * (1 - self.alpha)
modulating_factor = (1.0 - p_t) ** self.gamma
loss *= alpha_factor * modulating_factor
if self.reduction == 'mean':
return loss.mean()
elif self.reduction == 'sum':
return loss.sum()
else: # 'none'
return loss
调参上的技巧

1.1 增加alpha
focalloss其实是两个参数,一个参数就是我们前述的fl_gamma,同样的道理我们也可以增加fl_alpha来调节alpha参数
(1)进入参数配置文件

增加
fl_alpha: 0.95 # my focal loss alpha:nagetive example rate
(2)然后回到核心代码那里替换这一段
# Focal loss
g = h['fl_gamma'] # focal loss gamma
if g > 0:
a=h['fl_alpha']
BCEcls, BCEobj = FocalLoss(BCEcls, g), FocalLoss(BCEobj, g)
# ————————————————使用Varifocal Loss损失函数———————————————————————————————————
#BCEcls, BCEobj = VFLoss(BCEcls, g,a), VFLoss(BCEobj, g,a)
# print(BCEcls)
# print
# ————————————————使用Varifocal Loss损失函数———————————————————————————————————
Varifocal 和foacl loss二选一,另一个注释掉就行
(2)使用Varifocal Loss
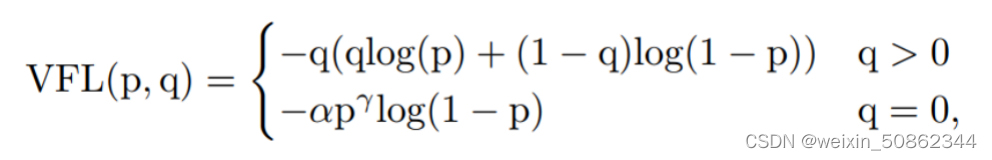
p输入为前景类的预测概率;q为ground-truth
class VFLoss(nn.Module):
def __init__(self, loss_fcn, gamma=1.5, alpha=0.25):
super(VFLoss, self).__init__()
# 传递 nn.BCEWithLogitsLoss() 损失函数 must be nn.BCEWithLogitsLoss()
self.loss_fcn = loss_fcn #
self.gamma = gamma
self.alpha = alpha
self.reduction = loss_fcn.reduction
self.loss_fcn.reduction = 'mean' # required to apply VFL to each element
def forward(self, pred, true):
loss = self.loss_fcn(pred, true)
pred_prob = torch.sigmoid(pred) # prob from logits
#p
focal_weight = true * (true > 0.0).float() + self.alpha * (pred_prob - true).abs().pow(self.gamma) * (
true <= 0.0).float()
loss *= focal_weight
if self.reduction == 'mean':
return loss.mean()
elif self.reduction == 'sum':
return loss.sum()
else:
return loss
true:q,即为ground-truth
(pred_prob - true):p,即前景类的预测概率
直接使用代码会报这个错
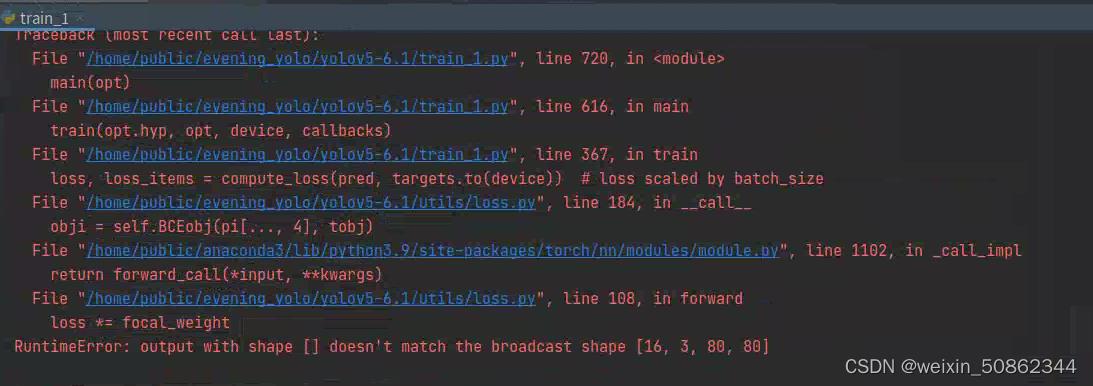
后面self.loss_fcn.reduction = 'mean'修改为self.loss_fcn.reduction = 'none'就没问题了
Focal loss和Varifocal Loss始终是不如原先的效果,可能很大一部分是参数问题
芒果改进YOLOv5系列:首发使用最新Wise-IoU损失函数,具有动态聚焦机制的边界框回归损失,YOLO涨点神器,超越CIoU, SIoU性能,提出了BBR的基于注意力的损失WIoU函数
以上是关于yolov5 优化系列:修改损失函数的主要内容,如果未能解决你的问题,请参考以下文章