python 开发 -- 17字符编码
Posted FikL-09-19
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python 开发 -- 17字符编码相关的知识,希望对你有一定的参考价值。
文章目录
引入
1.什么是字符编码
- 就是文字符号与数字的对应表
- 一个字符对应着一个数字
文字符号>>-------编码----------->>数字
文字符号<<-------解码-----------<<数字
2.为何要研究字符编码
- 为了解决乱码问题
- 因为存取都用一张字符编码表
3.储备知识
- 计算机三大核心硬件
- 应用程序任何操作硬件的请求都需要向操作系统发起系统调用, 然后又操作系统去操作硬件
1. CPU
2. 内存
3. 硬盘
ps : 计算机三大核心硬件
- 文本编辑器读取文件的流程
1. 首先是启动文本编辑器
2. 文本编辑器发送系统调用,操作系统将"a.txt"的内容读入内存
3. 文本编辑器会将刚刚读入内存的内容画到屏幕上,并没有语法结构 #不同点
- Python解释器执行文件的流程
1. 首先得启动 "Python解释器"
2. 解释器发送系统调用,操作系统将"a.py"的内容读入内存,此时内容全为普通字符,没有任何语法意义
3. 解释器开始逐行执行内存中的"a.py"内容,并开始识别语法 #不同点
一.字符编码的发展历程
1.一家独大 : ACSLL
- ACSLL : 只能识别英文字符
- 使用 " 8 " 个 “bit” 对应一个英文字符
🦜现代计算机起源于美国,所以最先考虑仅仅是让计算机识别英文字符,于是诞生了ASCII表
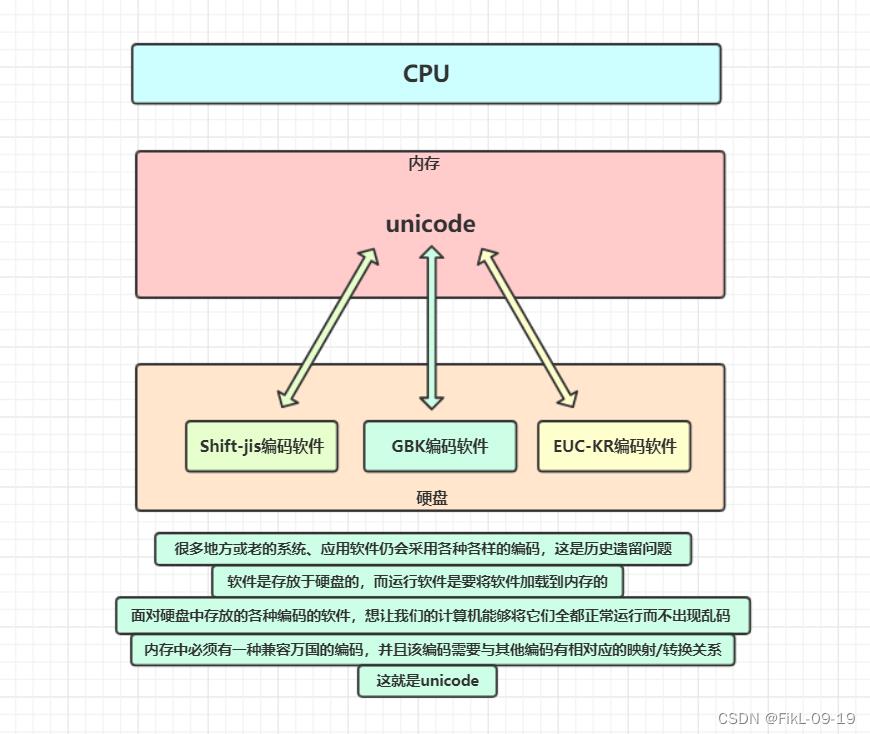
2.天下大乱 : ACSLL, GBK, Shift-jis, Euc-KR …
- GBK : 能识别中文和英文
- 使用 " 16 " 个 “bit” (2Bytes) 对应一个字符
🦜为了能让计算机能识别自己国家的语言字符, 各个国家都开始定制属于自己的字符编码
"Shift-jis" : 能识别日本字符和英文字符
"Euc-KR" : 能识别韩国字符和英文字符
.......
🦜如果一个文件在中国电脑上使用"GBK"字符格式创建的, 那么就无法在别的国家电脑上运行,会出现乱码,各个国家质检的字符编码无法兼容
3.归于统一 : unicode
- unicode : 能识别万国语言
- 使用 " 16 " 个 “bit” (2Bytes) 对应一个字符
- 一些生僻字可能使用 “4Bytes”(了解)
🦜这时候乱码问题消失了,所有的文档我们都使用但是新问题出现了,如果我们的文档通篇都是英文,你用"unicode"会比"ascll"耗费多一倍的空间,在存储和传输上十分的低效
🦜本着节约的精神,又出现了把Unicode编码转化为“可变长编码”的"UTF-8"编码
🦜常用的英文字母被编码成"1"个字节,汉字通常是"3"个字节,只有很生僻的字符才会被编码成"4-6"个字节
🦜如果你要传输的文本包含大量英文字符,用"UTF-8"编码就能节省空间:
4.UTF-8 的由来
- 前面已经谈到: 如果我们的文档通篇都是英文,你用**"unicode"会比"ascll"耗费多一倍的空间,在存储和传输上十分的低效**
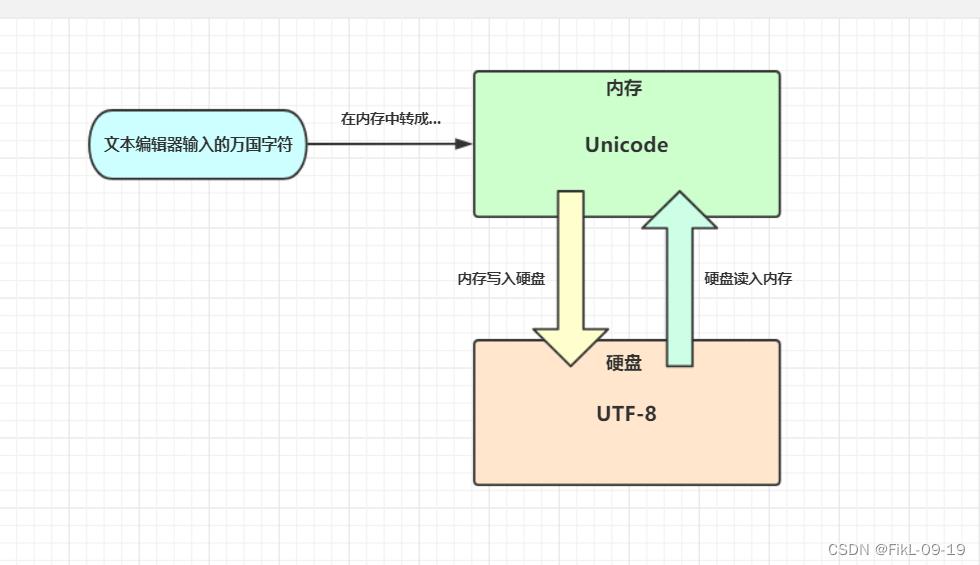
- 所以将内存中的unicode二进制写入硬盘或者基于网络传输时必须将其转换成一种精简的格式,这种格式即utf-8 : (全称Unicode Transformation Format,即unicode的转换格式)
- utf-8:采用8位二进制数(1Bytes)对应一个英文字符,采用24位二进制数(3Bytes)对应一个中文字符
5.为何不在内存中直接使用 UTF-8 ?
- unicode更像是一个过渡版本,我们新开发的软件或文件存入硬盘都采用utf-8格式
- 等过去几十年,所有老编码的文件都淘汰掉之后,会出现一个令人开心的场景
- 即硬盘里放的都是utf-8格式,此时unicode便可以退出历史舞台,内存里也改用utf-8
二.编码与解码
- **编码:**由字符转换成内存中的unicode 或 由其他编码转换成内存中的unicode
字符------------->>"unicode"格式的二进制(内存)------------->>"utf-8"格式的二进制(硬盘)
- **解码:**由内存中的unicode转换成字符 或 由内存中的unicode转换成其他编码
字符<<-------------"unicode"格式的二进制(内存)<<--------------"utf-8"格式的二进制(硬盘)
- **注意:**unicode 是存在内存当中
三.总结
1.字符编码对应字符关系:
- **ASCII:**只采用1个字节对应一个英文字符
- **GBK:**采用1个字节对应一个英文字符,采用2个字节对应一个中文字符。
- **unicode:**采用2个字节对应一个字符,生僻字采用4个字节、8个字节。(注意:无论是英文还是中文,都是采用2个字符)
- **utf-8:**采用1个字节对应一个英文字符,采用3个字节对应一个中文字符。
2.目前内存使用的编码: unicode
-
unicode兼容万国码,与万国字符都有对应关系。
-
unicode
有2个作用:
- 1、兼容万国字符
- 2、有着万国字符编码表对应关系(这是它目前过度阶段存在的主要作用)
3.目前硬盘中使用的编码
- utf-8、
- GBK、
- Shift-JIS
- 等等…
4.内存固定使用 unicode 无法改变,我们可以改变的是存入硬盘采用的格式
- 英文+汉字(文本编辑器) ---->> unicode(内存) ----->>GBK(硬盘)
- 英文+日文(文本编辑器) ----->> unicode(内存) ----->>Shift-JIS(硬盘)
- 万国字符(文本编辑器) ----->> unicode(内存) ----->>utf-8(硬盘)
ps : 字符编码之间不可以进行转换, 例如:GBK不能转成ASCII,因为这两种字符表的对应关系不一样, 但是字符编码之间可以使用unicode作为中间介质,进行读写操作
四.示例
1.使用 GBK 存,再使用 Shift-jis 读
-
写入
-
读取,日文乱码
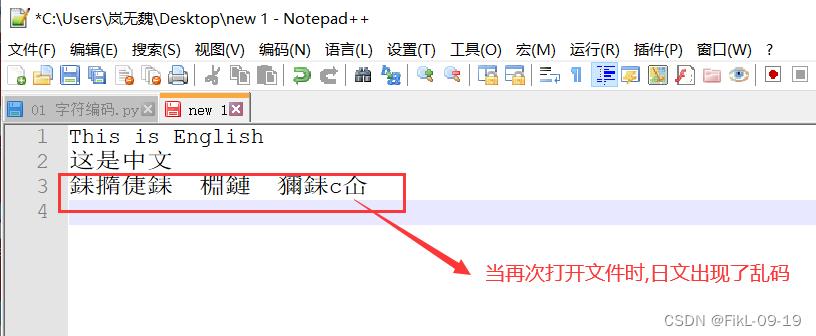
2.使用 UTF-8 存, 使用 其他编码读取
- 写入
- 读取,出现乱码
3.文件写入和读取乱码问题总结
- 保证存的时候不乱:
- 致命性: 在写入文件的时候, 字符与硬盘的字符编码格式不一致, 文件内容直接损坏,数据也就不存在了
- **解决:**在由内存写入硬盘时,你的是 GBK 字符编码的硬盘, 那就必须存入中文 , 其他语言就使用其他语言所对应的字符编码硬盘去存
- 保证读的时候不乱:
- **致命性:**取乱了并不一定致命,你当初用什么格式存的,那么你就用什么格式取就可以
- **解决:**在由硬盘读入内存时,文件用什么编码格式存入硬盘的,就应该用什么编码格式读入内存。
五.Python2 终端打印字符串
1.Python2 中字符串类型
- str类型:
x='上' - unicode类型:
x=u'上' - python2中默认ASCII码
- 加小 u **在python2中是把这个字符串强制转换成**unicode编码
# python2
x = "明明"
print (x) #因为这个是gdk格式,所以会报错,需要加个u
x = u"明明"
print (x) # 正常打印 mm
# python3
x = "明明"
print (x) #默认字符都是utf-8,所以不会报错,正常打印 mm
2.Python3 只有字符串类型
- python3中字符串前面帮我们默认加了小u,我们加不加都是一样,并不影响使用
3.解决 Python2 乱码问题
- 指定文件头:
#unicoding:[字符编码], 字符编码需要与文件存的编码格式一样 - 在字符串前面加小u:
x=u"上"
4.解决 Python3 乱码问题
-
指定文件头:
#unicoding:[字符编码], 字符编码需要与文件存的编码格式一样 -
python3中字符串前面帮我们默认加了小u,我们加不加都是一样,并不影响使用
3.解决 Python2 乱码问题
- 指定文件头:
#unicoding:[字符编码], 字符编码需要与文件存的编码格式一样 - 在字符串前面加小u:
x=u"上"
4.解决 Python3 乱码问题
- 指定文件头:
#unicoding:[字符编码], 字符编码需要与文件存的编码格式一样
ps : 字符编码只适合用文本文件。并不支持图片,视频等格式
以上是关于python 开发 -- 17字符编码的主要内容,如果未能解决你的问题,请参考以下文章