Python使用jieba库分词并去除标点符号
Posted Alexabc3000
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python使用jieba库分词并去除标点符号相关的知识,希望对你有一定的参考价值。
相对于英文文本,中文文本挖掘面临的首要问题就是分词,因为中文的词之间没有空格。在Python中可以使用jieba库来进行中文分词。
但是在中文中,标点符号出现的频率也是很高的,在使用jieba库对带有标点符号的汉语句子进行分词时,标点符号出现在分词结果中时,对于后续的文本数据挖掘是一个不利的因素。
本文介绍一段去除标点符号的Python代码。并在Anaconda3的Jupyter Notebook中展现代码的运行结果。
下面的代码,定义一段带有标点符号的文本,并使用jieba库进行分词。代码如下:
import jieba
text = "她说:“我爱死你了!”"
cutwords = list(jieba.cut(text))
cutwords运行结果如下图所示:

上图中,分词结果列表中有标点符号冒号、逗号、感叹号、左双引号、右双引号等。
使用下面这段代码即可从分词结果中去除标点符号。代码如下:
import jieba
import pandas as pd
text = "她说:“我爱死你了!”"
cutwords = list(jieba.cut(text))
cutwords = pd.Series(cutwords)[pd.Series(cutwords).apply(len)>0] #去除长度为0的词
stopwords=[':','“','!','”']
cutwords = cutwords[~cutwords.isin(stopwords)]
cutwords上面这段代码主要使用了pandas库中的函数,还定义了停用词列表stopwords,将想要去除的标点符号添加到该列表中。运行结果如下图所示:
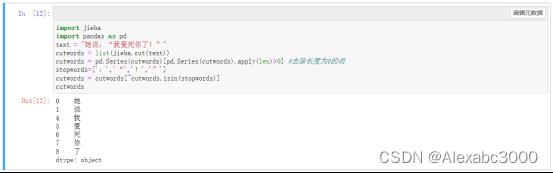
由程序运行结果可以看出,达到了目的,即去除了分词结果中的标点符号。
相关参考资料:
- Python手动安装Jieba库(Win11). https://www.toutiao.com/article/7162528424102789635/?log_from=20632270c7786_1668424596605 .
- 在Anaconda3使用Jupyter Notebook的简单例子. https://www.toutiao.com/article/7160267285184119333/?log_from=5da6ca35b0bd3_1668424881002 .
- Python在机器学习中的应用. 余本国, 孙玉林著. 中国水利水电出版社[北京], 2019年6月第一版.
Python 中的 jieba 库
jieba库
一、 简介
1、 是什么
(1)jieba是优秀的中文分词第三方库
- 中文文本需要通过分词获得单个的词语
- jieba是优秀的中文分词第三方库,需要额外安装
- jieba库提供三种分词模式,最简单只需掌握一个函数
(2)jieba分词的原理
- jieba分词依靠中文词库
- 利用一个中文词库,确定汉字之间的关联概率
- 汉字间概率大的组成词组,形成分词结果
- 除了分词,用户还可以添加自定义的词组
2、 安装
pip install jieba
导入
import jieba
官方文档【https://github.com/fxsjy/jieba】
二、 基本使用
1、 三种模式
精确模式:
-
就是把一段文本精确地切分成若干个中文单词,若干个中文单词之间经过组合,就精确地还原之前的文本。其中不存在冗余单词
-
str = "你好呀,我叫李华!多多关照!" print(jieba.lcut(str))
全模式:
-
将一段文本中所有可能的词语都扫描出来,可能有一段文本,它可以切分成不同的模式,或者有不同的角度来切分变成不同的词语,在全模式下,jieba库会将各种不同的组合都挖掘出来。分词后的信息组合起来会有冗余,不再是原来的文本
-
str = "你好呀,我叫李华!多多关照!" print(jieba.lcut(str, cut_all=True))
搜索引擎模式:
-
在精确模式的基础上,对发现的那些长的词语,我们会对它再次切分,进而适合搜索引擎对短词语的索引和搜索。也有冗余
-
str = "你好呀,我叫李华!多多关照!" print(jieba.lcut_for_search(str))
2、 使用语法
2.1 对词组的基本操作
-
添加
-
str = "你好呀,我叫李华!多多关照!" jieba.add_word("你") print(jieba.lcut(str))
-
-
删除
-
str = "你好呀,我叫李华!多多关照!" jieba.del_word("李华") print(jieba.lcut(str))
-
-
加载自定义词典
-
str = "你好呀,我叫李华!多多关照!" jieba.load_userdict("./dict.txt") # 文件编码必须为 utf-8 print(jieba.lcut(str))
-
-
调整词出现的频率
-
str = "你好呀,我叫李华!多多关照!" jieba.suggest_freq(("李", "华"), True) print(jieba.lcut(str))
-
2.2 关键字提取
TFIDF算法
import jieba.analyse # 导包
jieba.analyse.extract_tags(sentence, topK=20, withWeight=False,
allowPOS=())
jieba.analyse.TFIDF(idf_path=None) # 创建一个新的 TFIDF 实例,idf_path是指指定 IDF 频率文件的路径
参数:
- sentence:要提取的文本
- topK:返回多少个具有最高TF/IDF权重的关键字。默认值为 20
- withWeight:是否返回关键字的TF/IDF权重。默认为假
- allowPOS:过滤包含POS(词性)的单词。空无过滤,可以选择
[\'ns\', \'n\', \'vn\', \'v\',\'nr\']
TextRank算法
jieba.analyse.textrank(sentence, topK=20, withWeight=False, allowPOS=(\'ns\', \'n\', \'vn\', \'v\')) # 有默认词性
jieba.analyse.TextRank() # 新建自定义 TextRank 实例
2.3 词性标注
jieba.posseg.POSTokenizer(tokenizer=None)
新建自定义分词器,tokenizer 参数可指定内部使用的 jieba.Tokenizer 分词器
jieba.posseg.dt 为默认词性标注分词器
import jieba.posseg
str = "你好呀,我叫李华!多多关照!"
pt = jieba.posseg.POSTokenizer()
print(pt.lcut(str)) # 得到 pair键值对,使用遍历取值
# print(jieba.posseg.cut(str)) # 作用一样
for i, k in ps.lcut(str):
print(i, k)
2.4 返回词语在原文的起止位置
jieba.tokenize(arg, mode=None)
mode有搜索模式(search)和默认模式(default)
import jieba
str = "你好呀,我叫李华!多多关照!"
g = jieba.tokenize(str, mode="search") # 生成器
for i in g:
print(i)
本文来自博客园,作者:A-L-Kun,转载请注明原文链接:https://www.cnblogs.com/liuzhongkun/p/16056345.html
以上是关于Python使用jieba库分词并去除标点符号的主要内容,如果未能解决你的问题,请参考以下文章