编程“盲”逆袭架构师之后的独白
Posted Javaesandyou
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了编程“盲”逆袭架构师之后的独白相关的知识,希望对你有一定的参考价值。
初生
知识改变命运,技术改变世界。当然,世界对我来说,是件很遥远的东西,哪怕身在其中。选择Java,不是想改变世界,只是兴趣爱好与生活使然。

记得当初自学html、CSS后(JS与其说不会,不如说根本不知道有这么个玩意儿),做出来的前端页面,大家都知道——只能看,不能摸。
那时不是自己不知道页面上的功能,而是不知道怎么学,也不知道后台这玩意儿姓编程。
不过很恼火的事情就是,我居然找到工作了,而且还是3.5K。
现在想想,我的天呐,太神奇啦!!!当然我是个自知之明的人,记得当初找到工作后,还是把上天和祖宗都感谢了一遍。
执念
当然,对编程的热情没有被打击,而是进一步激发了这个容易掉发的兴趣爱好,不过这个过程比较逼屈,因为没有这方面的亲人朋友,转来转去,居然找了3年,才知道这玩意儿姓---编程。
当明白编程后,到度娘那里一通询问,才知道有许多孪生兄妹,至此,才弄明白编程中的Java。
之后就找了家培训机构,0基础培训了6个月。
培训结束后,自己找了份工作,工资4.9K。
当然面试也撞过墙了,之后幸运之神再次降临,找了家物联网公司,工资9K。

进入这家公司后,才知道当初从培训机构出来撞墙是多么的应该。当然,在这家物联网公司,我并没有吃过苦,相反很感激这家物联网公司。
柳暗花明
由于不忙,自己也想学好Java。但是不知道怎么进阶,所以又开始度娘,最后好像是在今日头条,遇见哪位马士兵大美女,把我拉进QQ群,听了两节公开课,直接联系马士兵美女老师,转接连老师,就加入了马士兵VIP大家庭,总结一句话:师从马士兵,未来已定。

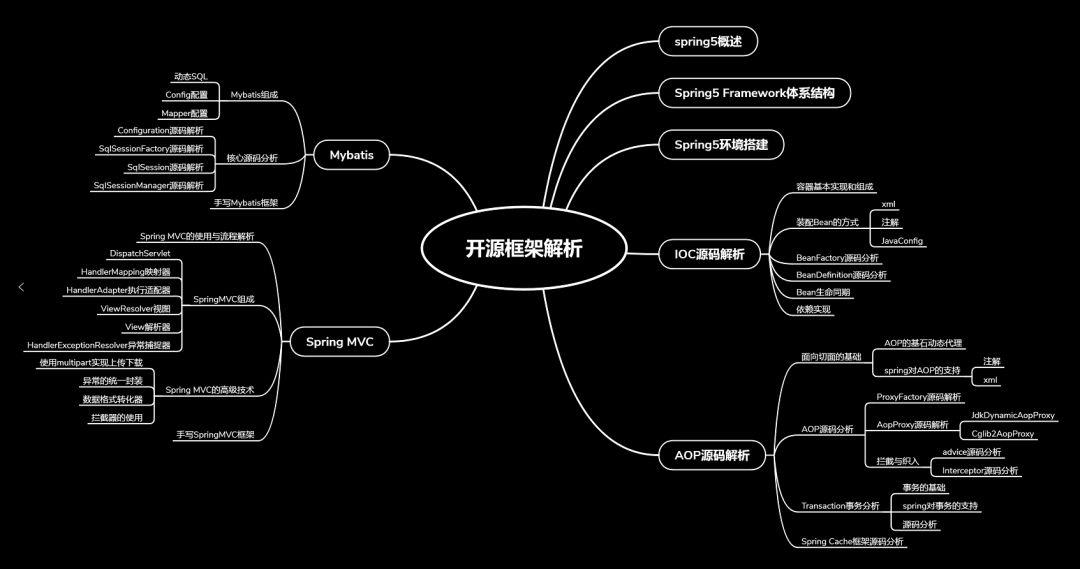
马士兵课堂几大风景:
一、班主任全是美女,水灵灵的那种(告诉你个秘密:Java老师说,有同学把班主任小姐姐搞到手的先例,单身的,这个是重点);
二、Java老师的头发呀,发迹线啦,理发师都做不到那么自然,他们最喜欢13号,估计师娘们认为13号是男的(哈哈!!!开玩笑);
三、授课的方式方法,自己去体会。

这里说自己师从马士兵前后一个习惯的变化,能不能领会精神看你自己啦。
首先声明:我英文很LOW,这样说都有点对不起LOW这三个字母,因为我连Hello都写错。
进入马士兵VIP之前,自己有个习惯(当然也是没有办法的事儿),除了能看Java API6中文文档外,其他的Java方法都是询问度娘,这个就是之前跟傻子似的天真的自己;
进入马士兵VIP,通过自己的勤奋好学,这里夸奖下自己,因为Java的路上逼屈的太多,学完了第一期VIP课程,终于走到了架构师。
(例子:我们公司外包的系统,在外包公司交付前1个星期,由于用户量大了,服务器挂了,而且还是. net写的,公司的领导那个一筹莫展的样子啊,我主动提建议,分两步做的,先增服务器,用集群解决眼前问题,然后再做分布式,把硬件与软件系统拆分)
通过马士兵课堂VIP课程的系统学习,结合公司项目实战,对课程中除JDK外,所有系列的基础和进阶部分,掌握的满不错的。
对所有系列的高级部分,很欠缺,说实话VIP课程的所有高级系列的确有难度,因为高级部分,除了课堂本身的代码外,高级部分的知识点是触类旁通的,老师的案例只是演示知识点中比较经典的。
这样说吧,里面的老师全是来自中国互联网排名前五的公司中的大佬,除了老师经验外,还精通硬件和软件开发,什么手写Tomcat、spring、mybatis等等之类框架,就跟你写个业务功能一样。马士兵课堂拥有这些过硬的资源并没有放松为同学服务的精神,当然比起13号,我更喜欢马士兵课堂的班主任老师,有机会自己去体验吧!!!
从马士兵VIP课堂出来,对过去从Java一路走来的自己,心里充满了欣慰,同时也对马士兵课堂充满了感激。
目标
在以后的Java生涯中,会分三个方向:第一个方向是进公司发展,第二个是自己想创业(这个每个人都应该会有),第三个方向是再进马士兵MCA后端架构VIP进修一下。

首先,在第一个方向上,不会去一线互联网公司,只会找中小企业,如果只能打工的话,国有系统的企业优先考虑;其次会在合适的时间,试试再次创业。
在技术上,现在到2021年底,结合公司的项目,把马士兵VIP课程系列技术的基础和进阶部分,由熟练到精通。(最如人愿的,但是这个少部分技术可能有难度)
对高级部分能做到熟练就好了,高级部分的知识,说直接点,能熟练课堂经典案例就不错了,暂时就别谈触类旁通,完全领会了。2021后,这个高级部分也是后面重点专研的部分,对高级部分,要去专研深的话,要满足第一个方向。
————END————
- 点赞(编辑不易,感谢您的支持)
- ...
- 转发(分享知识,传播快乐)
- ...
- 关注(每天更新Java开发技术)
- ...
送书啦搬砖工逆袭Java架构师 8Elasticsearch详解(建议收藏)
往期精彩回顾
【搬砖工逆袭Java架构师 1】MySql基础知识总结(2021版)
【搬砖工逆袭Java架构师 2】MySql基础知识总结(SQL优化篇)
【搬砖工逆袭Java架构师 3】Linux基础知识总结(2021版)
【搬砖工逆袭Java架构师 4】Redis基础知识总结(2021版)
【搬砖工逆袭Java架构师 5】阿里Sentinel知识体系总结(2021版)
粉丝专属福利:包邮送书3本,《Java核心技术及面试指南》
🍅 获取方式:
1、评论区评论:获取点赞最多者,获取一本;
2、微信群抽奖:采取微信群发红包的形式,手气最佳者获取一本;
3、2021年9月31日 20:00进行抽奖,并在第一时间公布中奖结果;
【注意】想加入微信群聊,可以扫描主页左侧二维码、私信与我、加本人微信guo_rui_
目录
一、Elasticsearch简介
Elasticsearch是一个分布式、RESTful风格的搜索和数据分析引擎,能够解决不断涌现出的各种用例。作为Elastic Stack的核心,它集中存储您的数据,帮助您发现意料之中以及意料之外的情况。
The Elastic Stack包括Elasticsearch、Kibana、Beats和Logstash,也称为ELK Stack。
能够安全可靠地获取任何来源、任何格式的数据,然后实时地对数据进行搜索、分析和可视化。
Elasticsearch简称ES,ES是一个开源的高扩展的分布式全文搜索引擎,是整个Elastic Stack技术栈的核心,它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别的数据。
PB是数据存储容量的单位,它等于2的50次方个字节,或者在数值上大约等于1000TB。
二、下载与安装
1、Elasticsearch官网下载地址
Download Elasticsearch Free | Get Started Now | Elastic | Elastic
2、下载成功
3、双击elasticsearch.bat启动
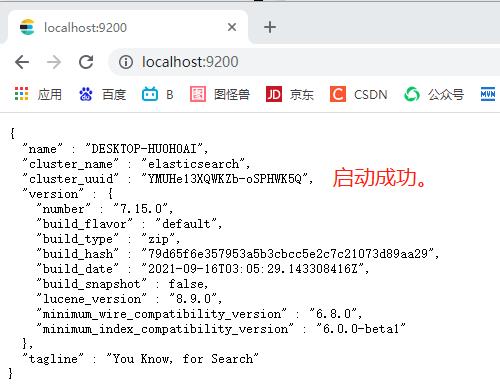
4、启动成功
三、数据格式
Elasticsearch是面向文档型数据库,一条数据在这里就是一个文档。为了方便大家理解,我们将Elasticsearch里存储文档数据和关系型数据库Mysql存储数据的概念进行一个类比:
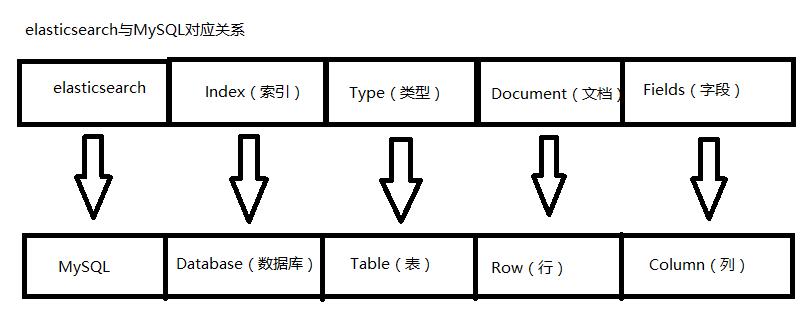
ES里的Index可以看做一个库,而Types相当于表,Documents则相当于表的行。
Elasticsearch7.X中,Type的概念已经被删除了。
四、索引
1、创建索引
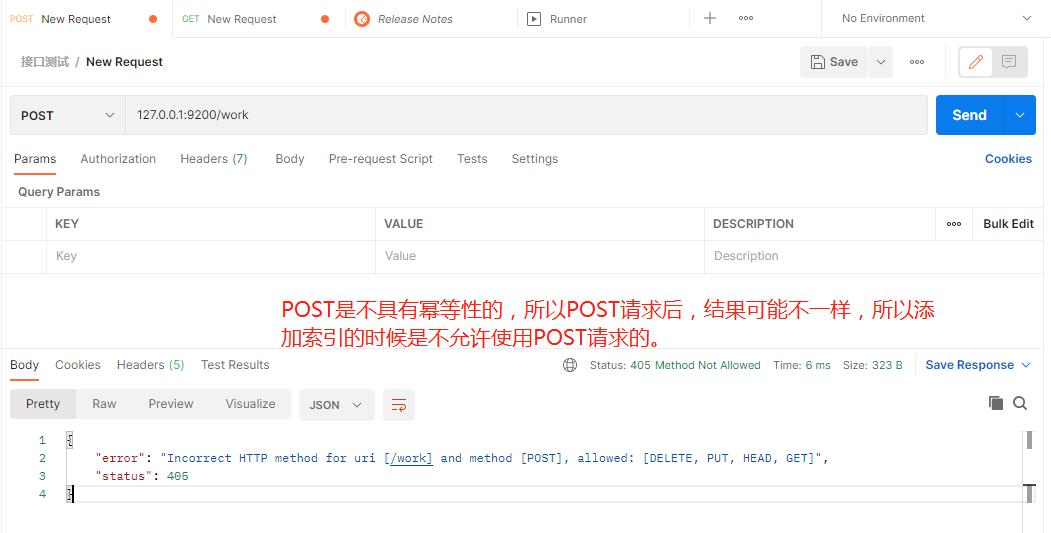
在postman中,向ES服务器发送PUT请求:127.0.0.1:9200/work
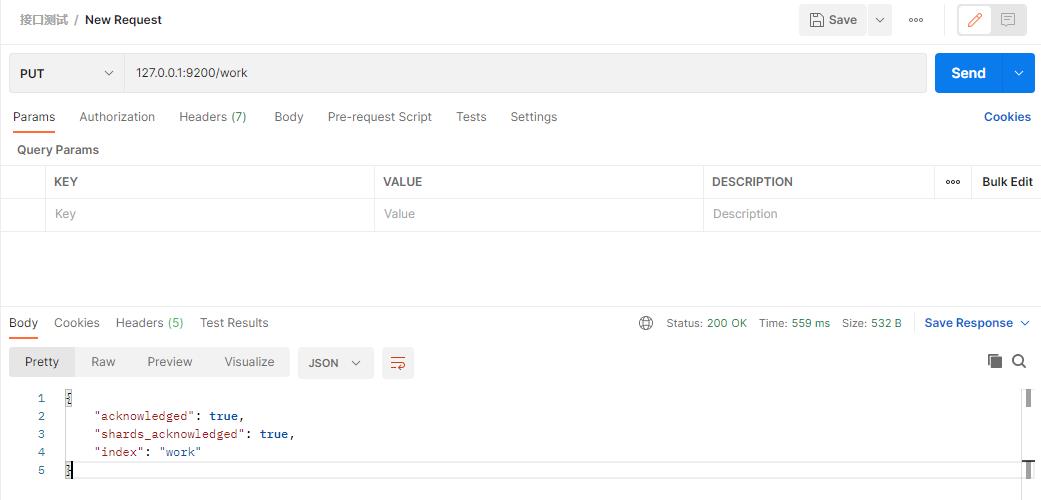
由于PUT请求具有幂等性,每次PUT请求创建的结果都是一样的,再次请求时,由于ES中已经存在名为work的索引了,所以会创建失败。
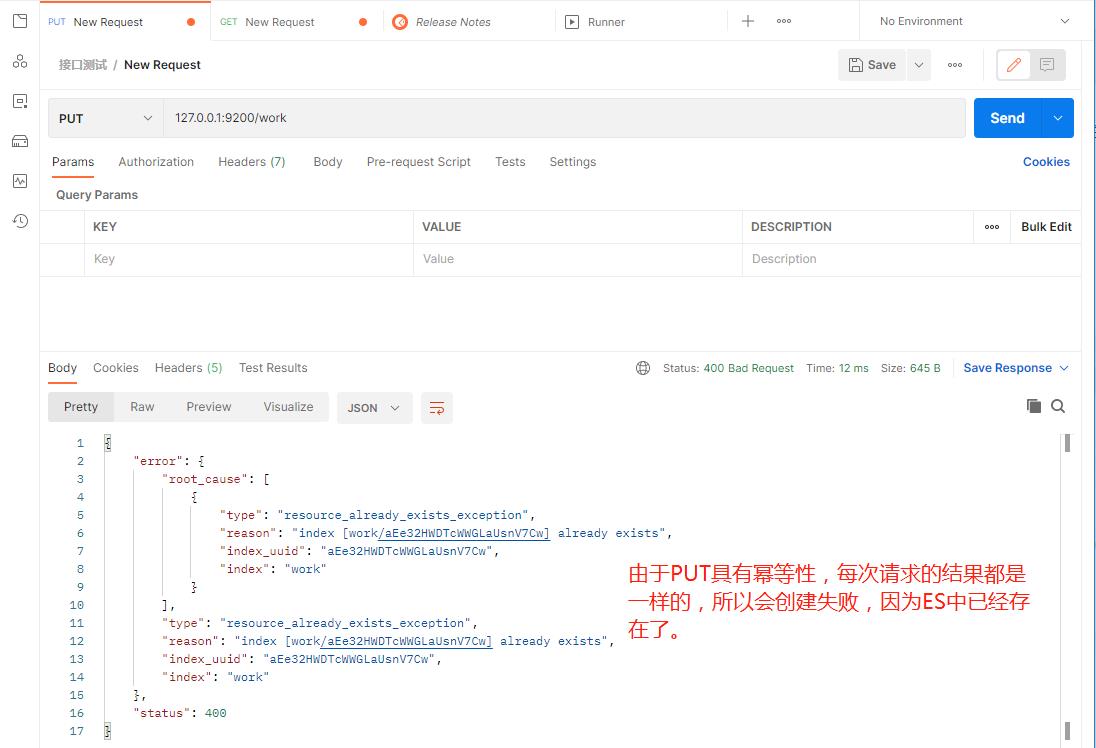
POST是不具有幂等性的,所以POST请求后,结果可能不一样,所以添加索引的时候是不允许使用POST请求的。
什么是幂等性?
在编程中一个幂等操作的特点是其任意多次执行所产生的影响均与一次执行的影响相同。幂等函数,或幂等方法,是指可以使用相同参数重复执行,并能获得相同结果的函数。这些函数不会影响系统状态,也不用担心重复执行会对系统造成改变。
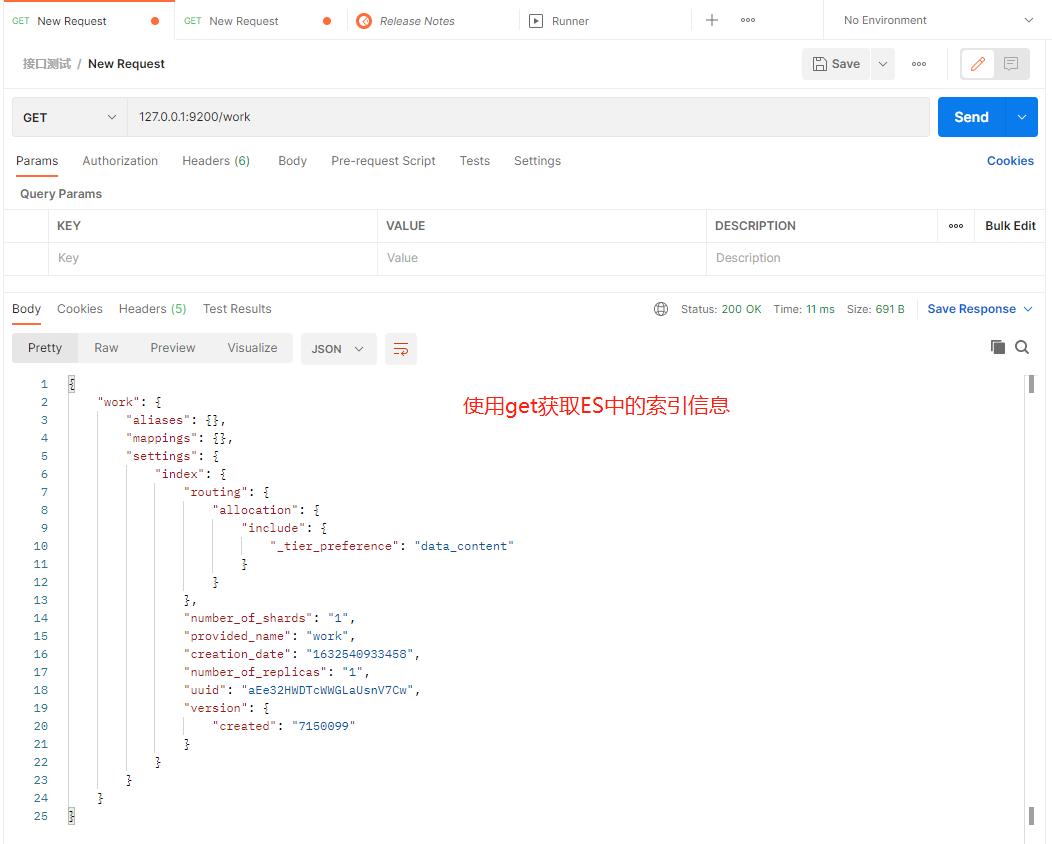
2、查询索引
(1)通过GET请求可以获取单一索引
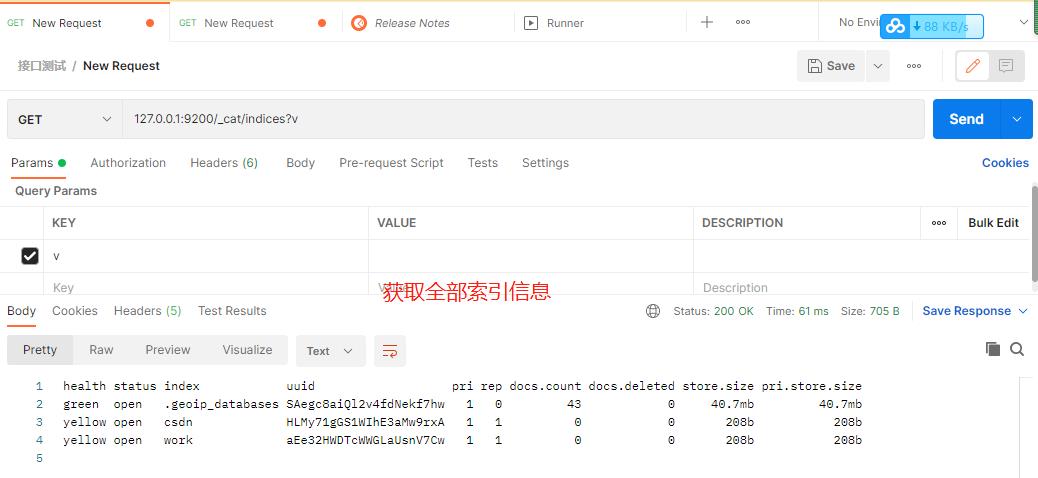
(2)获取全部索引信息
127.0.0.1:9200/_cat/indices?v
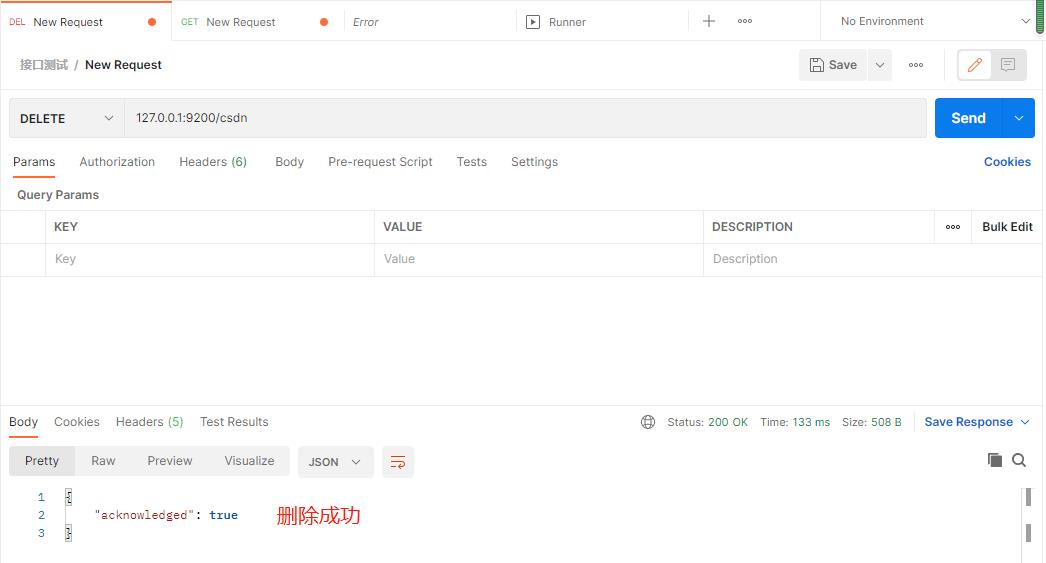
3、删除索引
五、文档
1、创建文档
ES中的文档相当于MySQL中的表数据,数据格式为JSON格式。
由于文档生成时会自动创建一个唯一性标识,因为POST不是幂等性的,PUT是幂等性的,所以这里只能用POST。
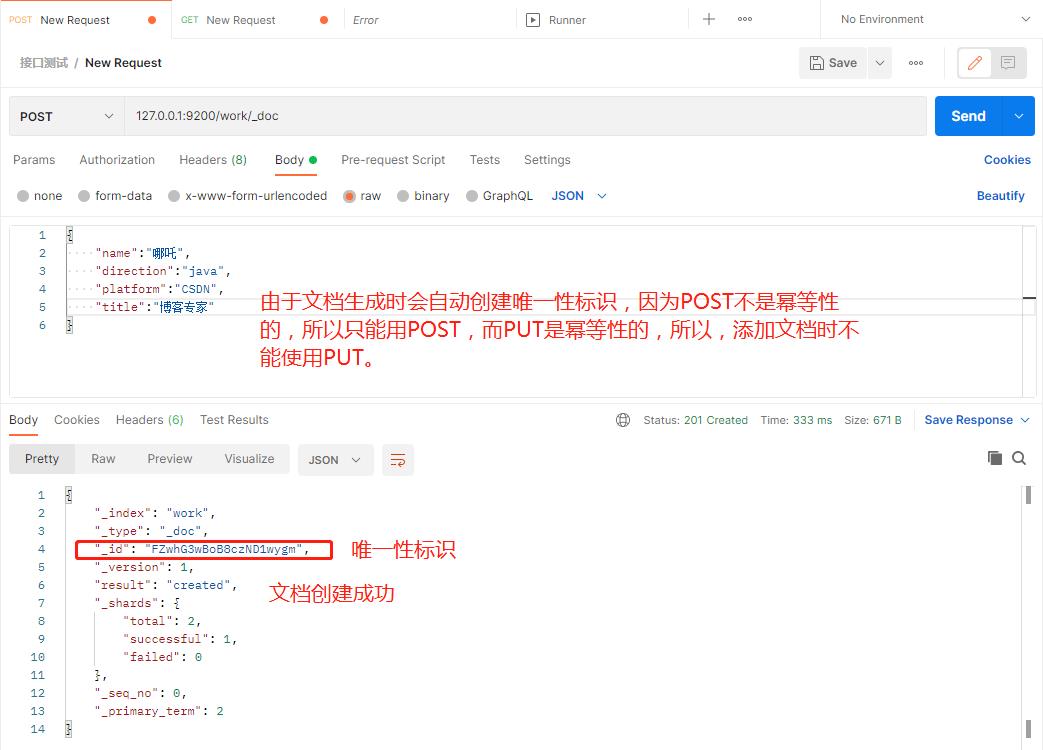
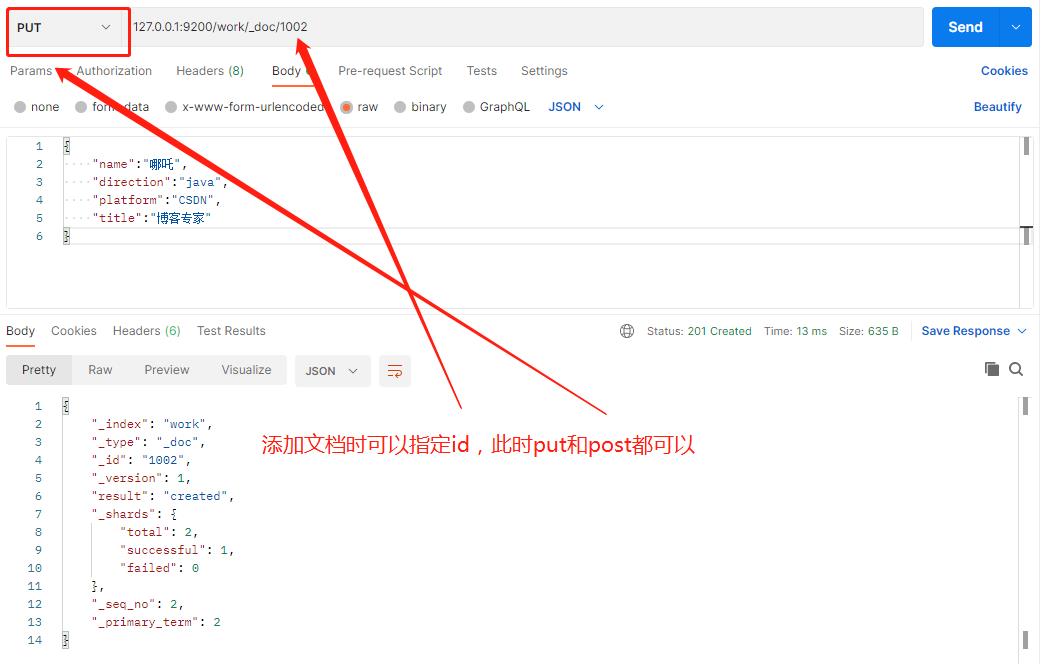
可以指定id
2、查询文档
(1)根据id查询

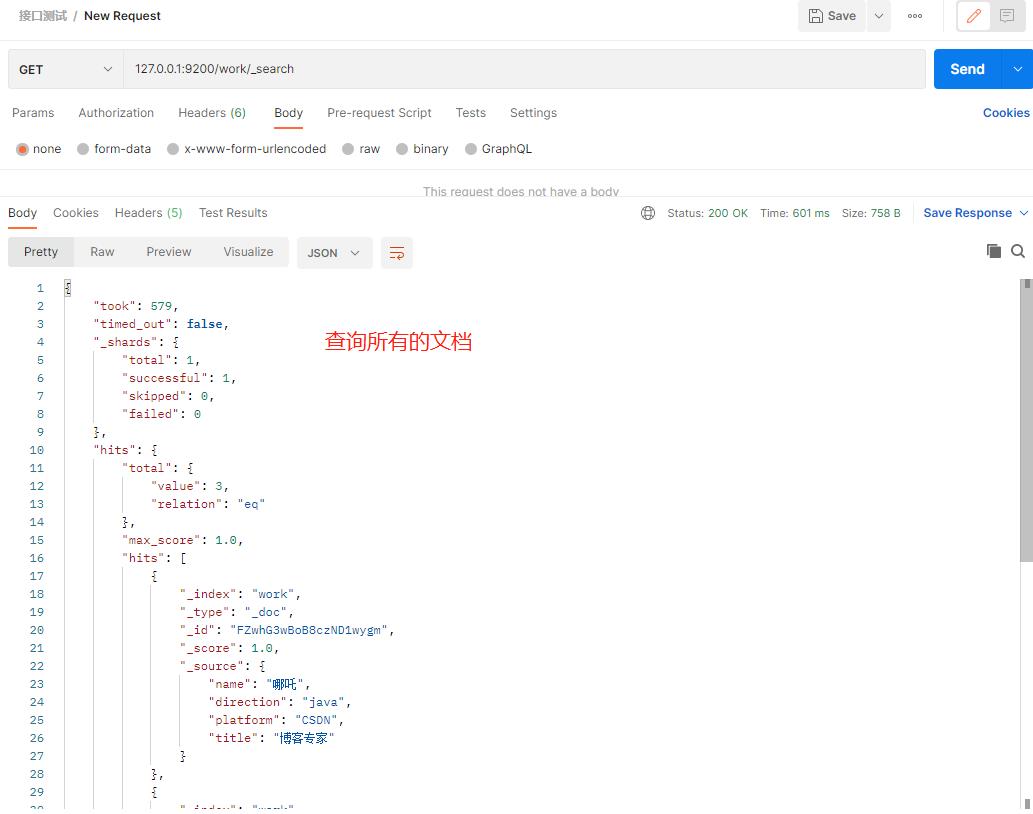
(2)查询所有文档
127.0.0.1:9200/work/_search
3、更改文档内容
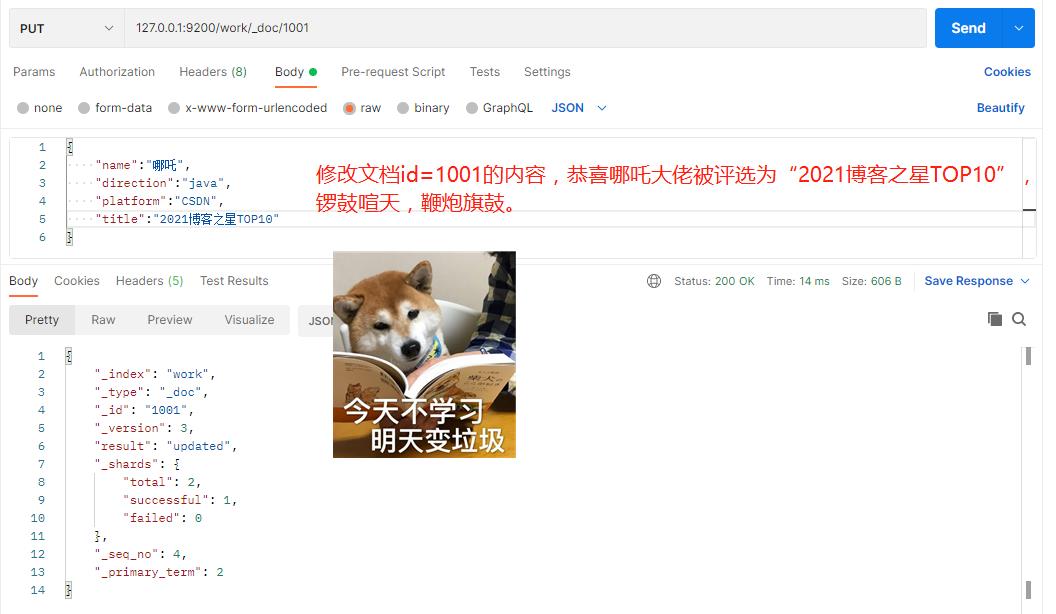
(1)修改文档id=1001的内容,恭喜哪吒大佬被评选为“2021博客之星TOP10”,锣鼓喧天,鞭炮旗鼓。
(2)局部更新
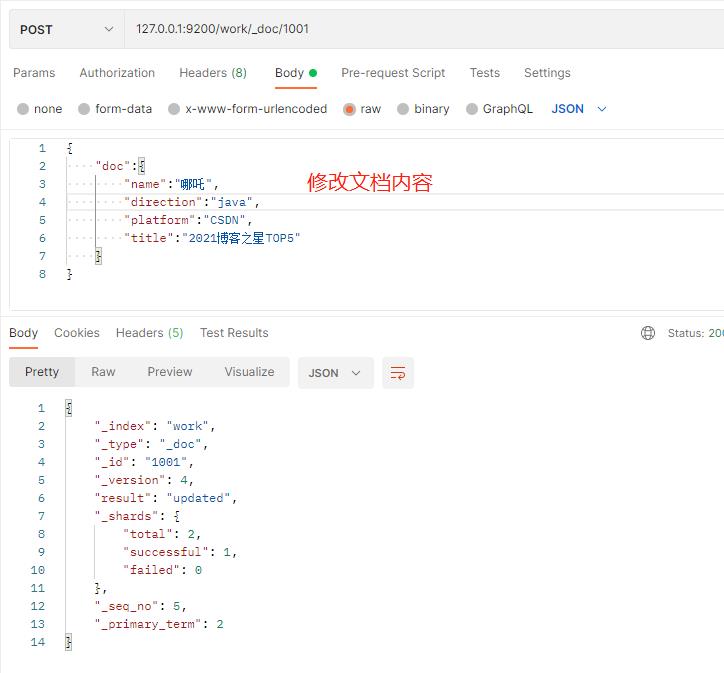
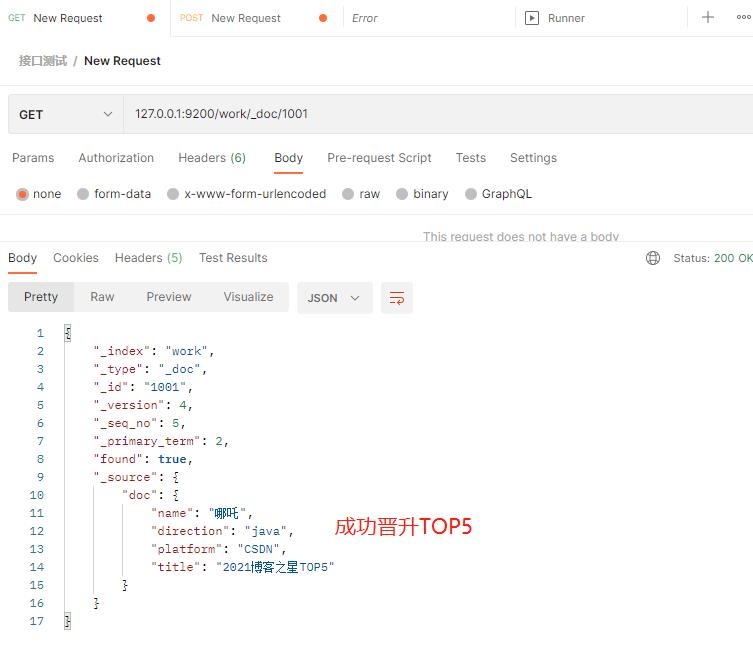
(3)局部更新成功,恭喜哪吒成功晋升TOP5。
六、复杂查询
1、指定条件查询
(1)查询name为哪吒的索引(通过请求路径:127.0.0.1:9200/work/_search?q=name:哪吒)
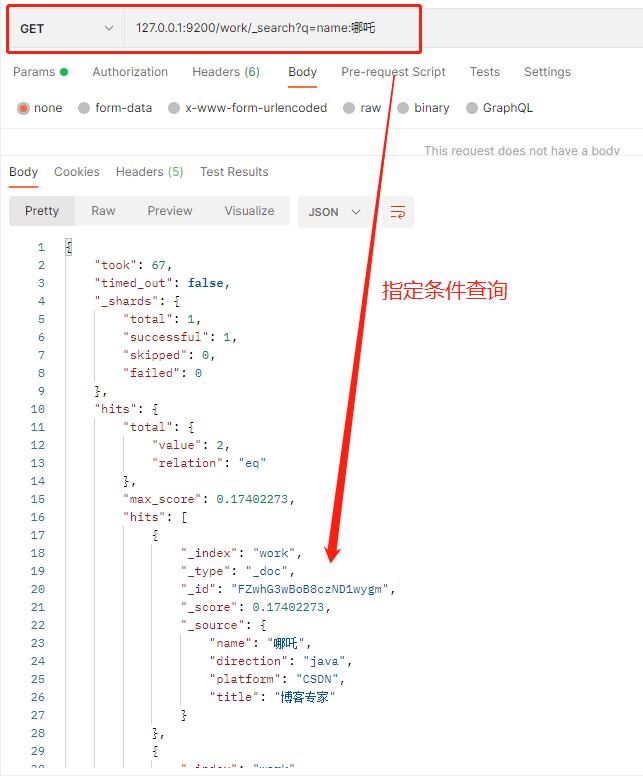
注意:满篇全是截图也不好看,以下就不截图了,望谅解。
(2)请求体查询
get请求:127.0.0.1:9200/work/_search
请求体:
{
"query":{
"match":{
"name":"哪吒"
}
}
}(3)分页查询
get请求:127.0.0.1:9200/work/_search
请求体:
{
"query":{
"match_all":{
}
} ,
"from":0,
"size":2
}(4)只获取指定字段 and 根据id排序
{
"query":{
"match_all":{
}
} ,
"from":0,
"size":2,
"_source":["title"],
"sort":{
"_id":"desc"
}
}2、多条件查询
must表示and匹配
{
"query":{
"bool":{
"must":[
{
"match":{
"name":"哪吒"
}
},{
"match":{
"title":"博客专家"
}
}
]
}
}
}should表示or匹配
{
"query":{
"bool":{
"should":[
{
"match":{
"name":"哪吒"
}
},{
"match":{
"name":"CSDN"
}
}
]
}
}
}范围匹配:工资大于10000
{
"query":{
"bool":{
"should":[
{
"match":{
"name":"哪吒"
}
},{
"match":{
"name":"CSDN"
}
}
],
"filter":{
"range":{
"money":10000
}
}
}
}
}3、部分词汇匹配查询
将每一个值拆解,组成倒排索引,方便进行全文检索。
{
"query":{
"match":{
"name":"哪"
}
}
}完全匹配
{
"query":{
"match_phrase":{
"name":"哪"
}
}
}高亮显示
{
"query":{
"match":{
"name":"哪"
}
},
"highlight":{
"fields":{
"name":{}
}
}
}4、聚合查询
(1)分组查询
{
"aggs":{
"money_group":{
"terms":{
"field":"money"
}
}
},
"size":0
}(2)平均值查询
{
"aggs":{
"money_avg":{
"avg":{
"field":"money"
}
}
},
"size":0
}七、代码实例
1、引入pom
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.2.1.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.guor</groupId>
<artifactId>es</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>es</name>
<description>Demo project for Spring Boot</description>
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>7.8.0</version>
</dependency>
<!-- elasticsearch的客户端 -->
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.8.0</version>
<exclusions>
<exclusion>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client</artifactId>
<version>7.8.0</version>
</dependency>
<!-- elasticsearch依赖2.x的log4j -->
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version>2.8.2</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.8.2</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.9.9</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<!-- junit单元测试 -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
2、添加索引
package com.guor.es.test;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.client.indices.CreateIndexRequest;
import org.elasticsearch.client.indices.CreateIndexResponse;
public class ESTest {
public static void main(String[] args) throws Exception{
//创建es客户端
RestHighLevelClient esClient = new RestHighLevelClient(
RestClient.builder(new HttpHost("localhost",9200,"http"))
);
//创建索引
CreateIndexRequest request = new CreateIndexRequest("student");
CreateIndexResponse createIndexResponse = esClient.indices().create(request, RequestOptions.DEFAULT);
boolean acknowledged = createIndexResponse.isAcknowledged();
System.out.println("创建索引:"+acknowledged);
// 关闭es客户端
esClient.close();
}
}
3、运行出错
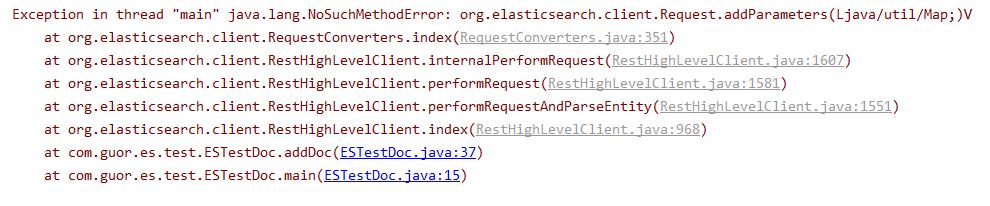
解决方法:
将pom中
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.8.0</version>
</dependency>替换为:
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.8.0</version>
<exclusions>
<exclusion>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client</artifactId>
<version>7.8.0</version>
</dependency>4、查询索引
package com.guor.es.test;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.client.indices.CreateIndexRequest;
import org.elasticsearch.client.indices.CreateIndexResponse;
import org.elasticsearch.client.indices.GetIndexRequest;
import org.elasticsearch.client.indices.GetIndexResponse;
public class ESTest {
public static void main(String[] args) throws Exception{
//创建es客户端
RestHighLevelClient esClient = new RestHighLevelClient(
RestClient.builder(new HttpHost("localhost",9200,"http"))
);
//创建索引
GetIndexRequest request = new GetIndexRequest("student");
GetIndexResponse getIndexResponse = esClient.indices().get(request, RequestOptions.DEFAULT);
//响应状态
System.out.println(getIndexResponse.getAliases());
System.out.println(getIndexResponse.getMappings());
System.out.println(getIndexResponse.getSettings());
// 关闭es客户端
esClient.close();
}
}
5、插入文档
package com.guor.es.test;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.apache.http.HttpHost;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.client.indices.GetIndexRequest;
import org.elasticsearch.client.indices.GetIndexResponse;
import org.elasticsearch.common.xcontent.XContentType;
public class ESTestDoc {
public static void main(String[] args) throws Exception{
addDoc();
}
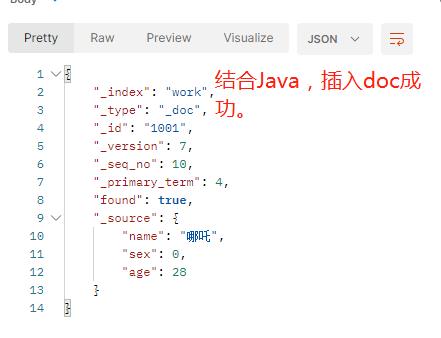
private static void addDoc() throws Exception{
//创建es客户端
RestHighLevelClient esClient = new RestHighLevelClient(
RestClient.builder(new HttpHost("localhost",9200,"http"))
);
IndexRequest request = new IndexRequest();
request.index("work").id("1001");
Work work = new Work();
work.setName("哪吒");
work.setAge(28);
work.setSex(0);
ObjectMapper mapper = new ObjectMapper();
String workJson = mapper.writeValueAsString(work);
IndexRequest response = request.source(workJson, XContentType.JSON);
System.out.println(response.getShouldStoreResult());
esClient.index(request, RequestOptions.DEFAULT);
// 关闭es客户端
esClient.close();
}
}
6、批量插入文档
private static void addBatchDoc() throws Exception{
//创建es客户端
RestHighLevelClient esClient = new RestHighLevelClient(
RestClient.builder(new HttpHost("localhost",9200,"http"))
);
BulkRequest request = new BulkRequest();
request.add(new IndexRequest().index("work").id("1001").source(XContentType.JSON, "name", "csdn哪吒"));
request.add(new IndexRequest().index("work").id("1002").source(XContentType.JSON, "name", "csdn哪吒1"));
request.add(new IndexRequest().index("work").id("1003").source(XContentType.JSON, "name", "csdn哪吒2"));
BulkResponse response = esClient.bulk(request, RequestOptions.DEFAULT);
System.out.println(response.getTook());
System.out.println(response.getItems());
// 关闭es客户端
esClient.close();
}7、根据条件查询文档中全部数据
/**
* 查询索引中全部数据
*/
private static void getDoc() throws Exception{
//创建es客户端
RestHighLevelClient esClient = new RestHighLevelClient(
RestClient.builder(new HttpHost("localhost",9200,"http"))
);
//查询索引中全部数据
SearchRequest request = new SearchRequest();
request.indices("work");
//构造查询条件,匹配所有
SearchSourceBuilder query = new SearchSourceBuilder().query(QueryBuilders.matchAllQuery());
request.source(query);
//查询文档
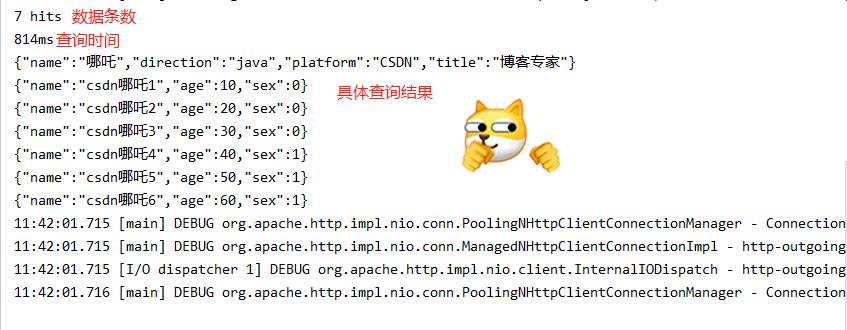
SearchResponse response = esClient.search(request, RequestOptions.DEFAULT);
//查询的结果
SearchHits hits = response.getHits();
//查询条数
System.out.println(hits.getTotalHits());
//查询时间
System.out.println(response.getTook());
//查询的具体数据
for (SearchHit hit : hits){
System.out.println(hit.getSourceAsString());
}
// 关闭es客户端
esClient.close();
}控制台输出
8、按条件查询
SearchSourceBuilder query = new SearchSourceBuilder().
query(QueryBuilders.termQuery("name","csdn哪吒"));9、分页查询
//构造查询条件,分页查询
SearchSourceBuilder builder = new SearchSourceBuilder().query(QueryBuilders.matchAllQuery());
//起始页
builder.from(0);
//每页数据量
builder.size(2);
request.source(builder);
10、按年龄排序
//按照年龄排序
SearchSourceBuilder builder = new SearchSourceBuilder().query(QueryBuilders.matchAllQuery());
builder.sort("age", SortOrder.DESC);
request.source(builder);控制台输出 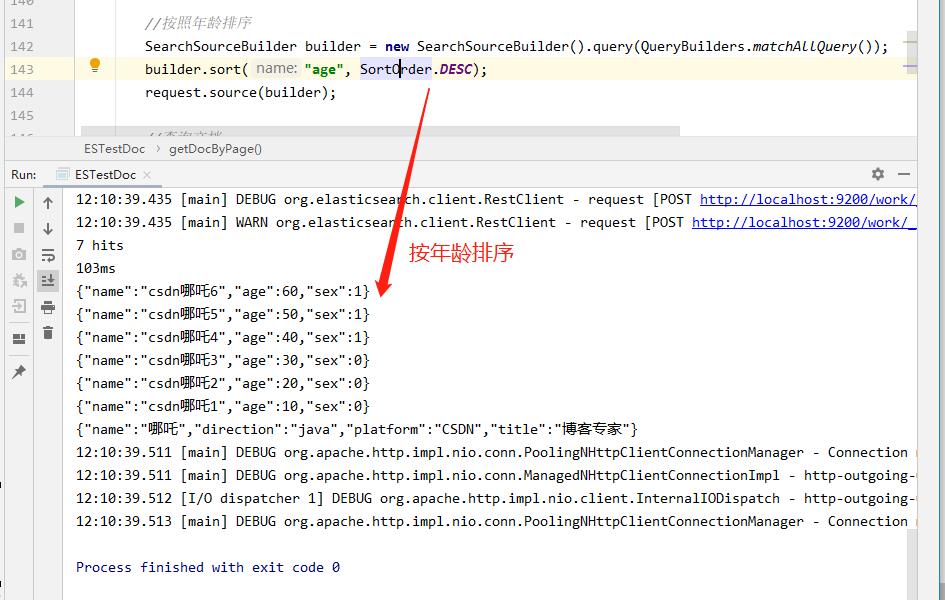
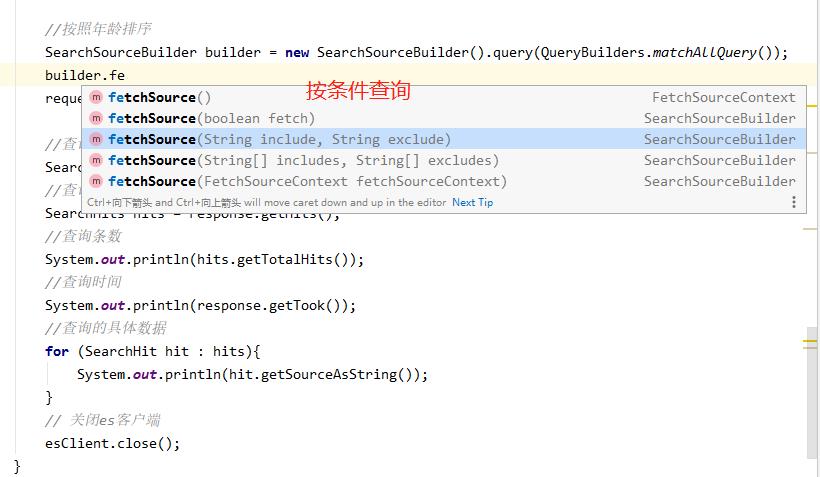
11、按条件查询
12、组合条件查询
13、模糊查询
//差一个字符也能匹配
SearchSourceBuilder builder = new SearchSourceBuilder();
FuzzyQueryBuilder fuzziness = QueryBuilders.
fuzzyQuery("name", "哪吒").fuzziness(Fuzziness.ONE);
builder.query(fuzziness);
request.source(builder);14、聚合查询
送书啦!!!
【图书简介】
(1)全面:本书作者团队阵容强大,既有架构师、培训师,又有面试官,分别从自身经验出发讲解工作中遇到的痛点。
(2) 实用:本书将相关知识的系统整合,符合现在Java的主流应用,拒绝全面不实用;本书知识点主要围绕技术升级和面试技巧展开,让你在升级专业知识的同时更能顺利通过面试。
(3) 丰富:本书附带Java Core常用知识点的视频和面试题,并且内容会不断更新。
【内容简介】
Java是编程世界备受欢迎的语言,虽然Java技术在运用中已趋成熟,但招聘市场的Java开发人才却仍然供不应求。《Java核心技术及面试指南》一书,从Java核心技术的开发和面试指南的解析两个方面展开,包括基本语法中常用技术点的精讲、集合类与常用的数据结构分析、异常处理与IO操作、多线程与并发编程、虚拟机内存优化技巧等内容,同时教会读者如何通过简历和面试找到好工作。本书既适合在公司中从事Java编程和开发工作的人员学习,也适合作为大中专职业院校毕业生的学习用书,特别有助于想要加强专业技术提高工作效率、通过简历和面试找到好工作的人群。
【作者简介】
金华,上海张江信息技术专修学院副院长,上海师范大学兼职教授,软件与信息技术讲师,长期从事软件与信息技术职业技能培训与职业规划工作。
胡书敏,资深架构师,《Java Web轻量级开发面试教程》图书的作者。
周国华,国内著名大学计算机应用专业毕业,超过十年Java开发经验,毕业后赴日本担任丰田、本田、电装等大型企业.NET及Java架构设计,5年多Java领域的职业能力培训经验。
吴倍敏,国内著名财经类大学毕业,多年财税及ERP系统开发经验,毕业后在多家会计师事务所从事内部管理及系统架构设计。
京东自营购买链接:
https://item.jd.com/12421187.html
当当自营购买链接:
http://product.dangdang.com/25336667.html

以上是关于编程“盲”逆袭架构师之后的独白的主要内容,如果未能解决你的问题,请参考以下文章