时序数据库 InfluxDB 2.2 初探
Posted sp42a
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了时序数据库 InfluxDB 2.2 初探相关的知识,希望对你有一定的参考价值。
时序数据库是什么?这里就不科普了,敬请百度一下。时序数据是写多读少的场景。
InfluxDB 用 Go 语言写,开源,应该还不错。但缺点是:单机版是免费开源的,集群版本是要收费的。
安装
分别下载数据库 Server 和命令行工具 CLI,两个独立的程序。安装后之后,执行 influx 启动 Server,注意暴露 8086 默认端口。
influx
这是临时启动的,我们改为守护进程执行的,
nohup ./influx &
然后对 Server 进行相应的配置,有 WebUI 的界面,访问其 8086 Web 服务即可,如下图所示。
设置初始用户,都是必填项。

初始化成功。
Java 客户端调用
我们的应用程序乃 Java,于是搞一下:
<dependency>
<groupId>com.influxdb</groupId>
<artifactId>influxdb-client-java</artifactId>
<version>6.1.0</version>
</dependency>
Measurement
摘抄网友的:
在关系数据库中,我们都是在表 table中查询数据,按照惯性思维的理解,也会把 influxdb 的 measurement 理解成表,然后查询的时候自然的会带上
_measurement,然而实际查询中这个仅仅作为 influxdb 的查询条件,其实是一个可有可无的条件,即使没有依然能正确查询。但是在进行入写的时候是必须要 measurement 的。从这里也可以看出,influxdb 的 measurement 跟关系数据库中的 table 不完全是一个概念,在 influxdb 中 measurement 只是在 bucket 中作为一种分组。influxdb 其实只有一种数据结构,所以 measurement 也是唯一的,measurement 会在写入数据时候自动创建,如果数据不存在了,measurement 也就自然消失了。
简单对比下两者:

写入数据
写入工具可支持:influx 命令行或者 API 客户端,例如我们写 Java 的就是官方提供 Java-client。写入方式可支持 Line protocol 数据格式或者 Java 实体 Bean,推荐 Java Bean 比较直观。
异步/同步
Java 客户端写入数据可以分为同步写入和异步写入两种。
WriteApiBlocking writeApi = client.getWriteApiBlocking(); // 阻塞,即同步
WriteApi makeWriteApi = client.makeWriteApi(); // 非阻塞,即异步
异步性能更好,达到以下两种情况中的任意一种即可写入一次数据库:
- 定时器 flush 操作,如一秒一次
- 写入数据达到 5000 笔,写入一次,控制这个数量为
batch_size(可调整)
未写入数据之前,数据都积压在 buffer 缓存中。
// 写入,指定精度为 ns 纳秒
writeApi.writeMeasurement(WritePrecision.NS, vo);
浏览数据
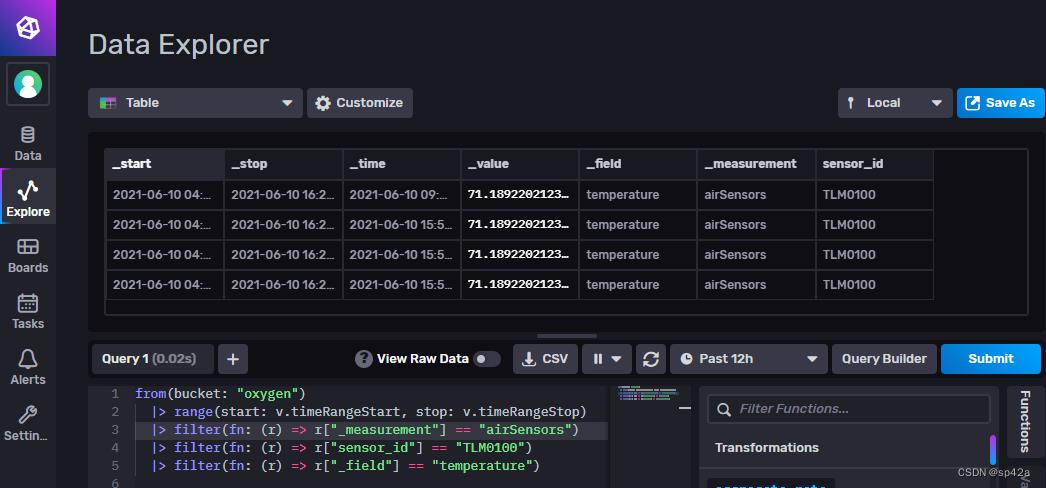
数据库工具我们会想到 NativeCat 之类的,但 influx 的呢?请放心有官方提供的 UI 工具,而且做得很精美,用浏览器访问部署位置,如 http://localhost:8086,点击 Data Explorer 即可浏览。
Flux
Flux(flux: n. 流量;变迁;不稳定;流出; vt. 使熔融;用焊剂处理; vi. 熔化;流出) 是 InfluxDB 2.0 引入的一门查询语言,新版本 v2 抛弃了 v1 的类似 SQL 语法,完全使用自制的查询方式,称为"Flux"。每个 Flux 查询都需要包含以下部分:1.数据源,2时间范围,3数据过滤器。
数据源:bucket 标识数据库的名称
from(bucket:"example-bucket")
时间范围,stop 不是必须的,时间范围可以是具体的时间(UTC 时间)或者时间戳,也可以是相对时间范围,如-1h表示过去1小时内的数据(相对于当前时间),可选单位有 s,m(分钟),h,d,mo(月),y
|> range(start: -1h, stop: -10m)
查询时间序列数据时,Flux 需要一个时间范围。"无界"查询非常占用大量资源,作为一种保护措施,Flux 不会在没有指定范围的情况下查询数据库。
数据过滤器,多个过滤器可以用 and 或 or 连接,或者另起一个 filter
|> filter(fn: (r) =>)
filter 的可选值有:_measurement ,_field ,_value,_time,某个 tag 的名称
生成查询数据(可选)
|> yield()
输出的表一般包含:_start, _stop, _field,_value, _measurement,_time,[tag名称] 字段
每个 flux 语法都以 “from” 开始,其他每个部分都需要以" |> "开头。
关于 Tag Field
开始使用 Flux 时,发现连简单的 SQL where 指定条件查询都做不到,很是失望!问了很多也不知道,后来看英文文档有 tag 才启发,是没有指定 tag 的缘故。influx 中,区分普通 field 和 tag field,前者不进行索引,于是不能被搜索,后者则可。所以当你要搜索某个字段时,必须指定其为 tag field,如下面的 uavId 字段
/**
* 电池、电压
*/
@Measurement(name = "Power")
public class Power extends InfluxValueObject
@Column(tag = true)
public String uavId;
@Column
public Integer batteryRemaining;
@Column
public Float voltageBattery;
如果建立过多索引,写入、查询性能都会下降。
两种 function
第一种: aggregate function;第二种:selector function。这两类函数最重要的区别就是,aggregate funciton 是通过聚合返回一条数据记录;selector funciton 则是返回一组原始数据。这两类函数有些地方可以混用,有时候又不可以。
类似 SQL 的 OR 或者 IN 查询
- 在 filter 中使用
or连接:|> filter(fn: (r) => r.eq == "1" or r.eq == "2") - 使用
contains函数:在 from 前面定义数组fields = ["1", "2"],然后在 filter 中使用|> filter(fn: (r) => contains(value: r.eq, set: fields))
数据备份
参考:https://www.sunzhongwei.com/influxdb-20-data-backup-recovery-exportimport?from=bottom
以上是关于时序数据库 InfluxDB 2.2 初探的主要内容,如果未能解决你的问题,请参考以下文章
时序数据库连载系列: 时序数据库一哥InfluxDB之存储机制解析