头歌:Python开发技术—面向对象程序设计3 详细注释(第1关:工资结算系统+第2关:设计LFU缓存类)
Posted MSY~学习日记分享
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了头歌:Python开发技术—面向对象程序设计3 详细注释(第1关:工资结算系统+第2关:设计LFU缓存类)相关的知识,希望对你有一定的参考价值。

目录
第1关:工资结算系统
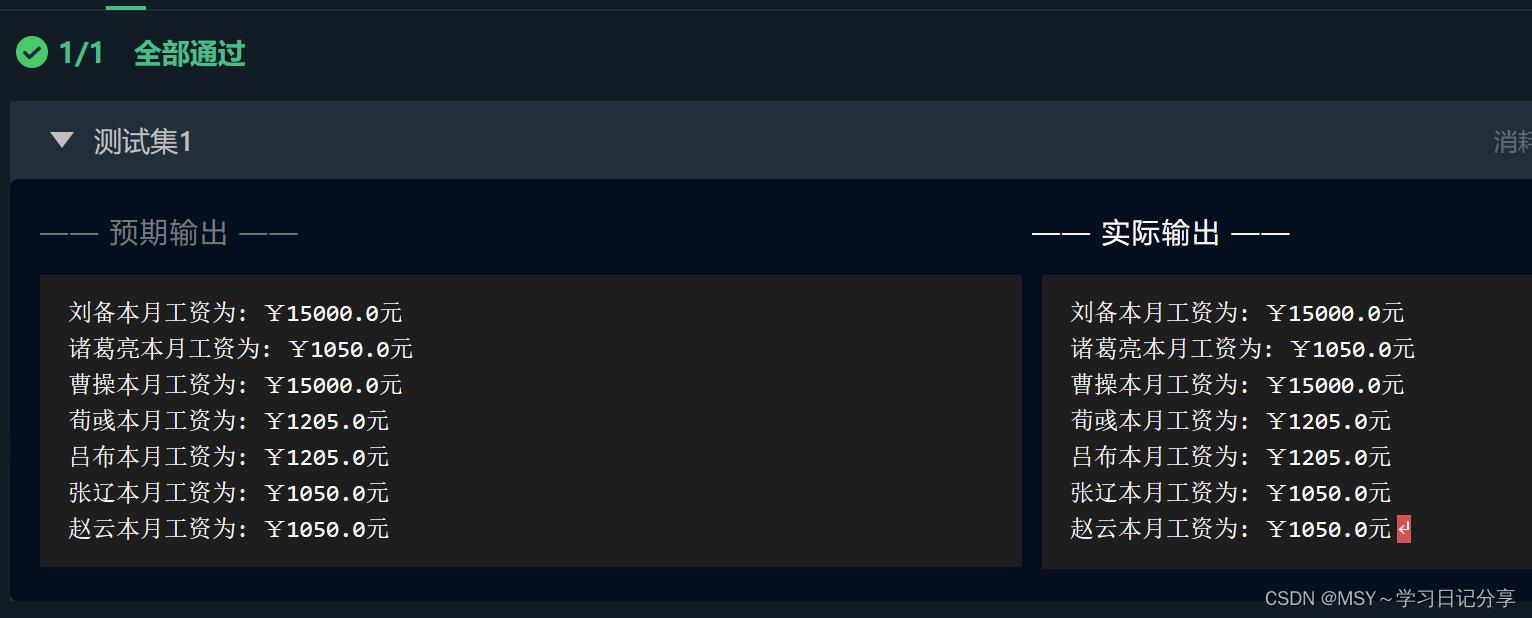
# Molly
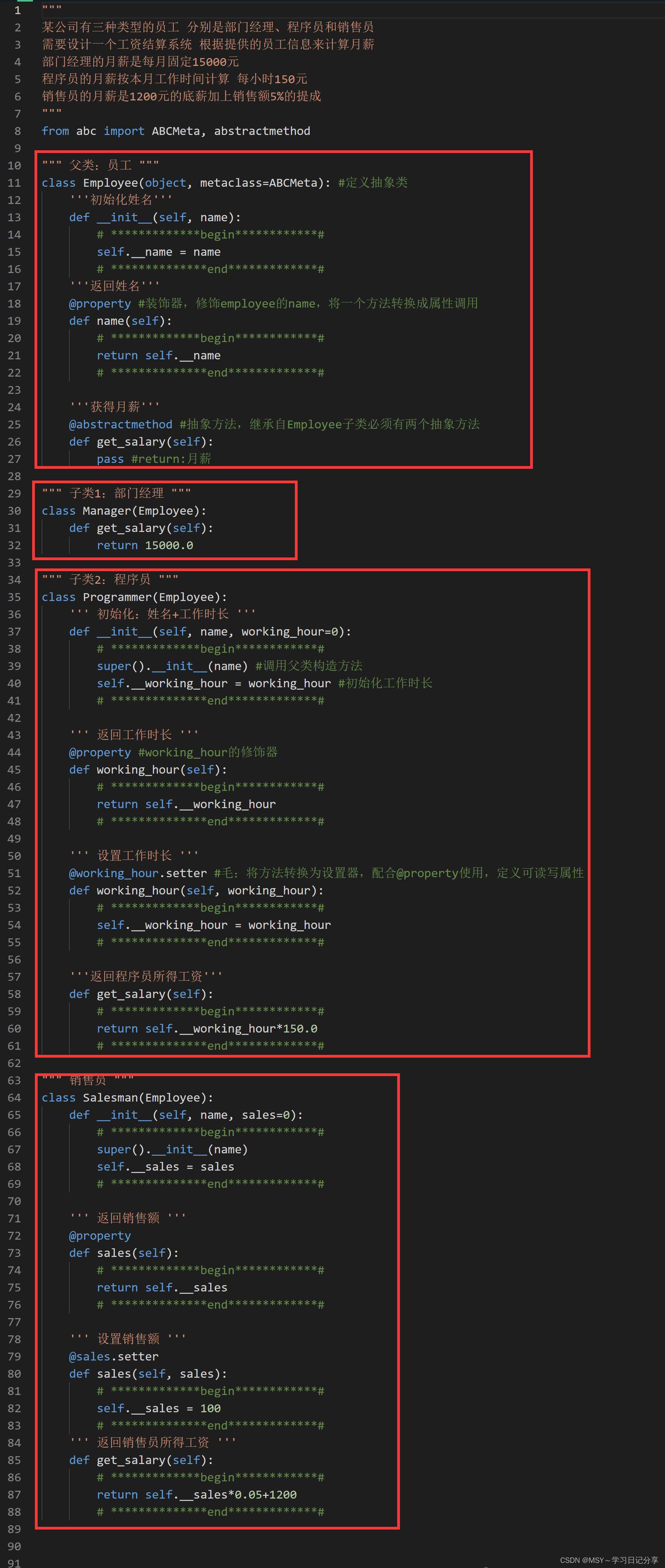
"""
某公司有三种类型的员工 分别是部门经理、程序员和销售员
需要设计一个工资结算系统 根据提供的员工信息来计算月薪
部门经理的月薪是每月固定15000元
程序员的月薪按本月工作时间计算 每小时150元
销售员的月薪是1200元的底薪加上销售额5%的提成
"""
from abc import ABCMeta, abstractmethod
class Employee(object, metaclass=ABCMeta):
"""员工"""
def __init__(self, name):
"""
初始化方法
:param name: 姓名
"""
# 请在此处添加代码 #
# *************begin************#
self.__name = name
# **************end*************#
@property
def name(self):
'''返回姓名'''
# 请在此处添加代码 #
# *************begin************#
return self.__name
# **************end*************#
@abstractmethod
def get_salary(self):
"""
获得月薪
:return: 月薪
"""
pass
class Manager(Employee):
"""部门经理"""
def get_salary(self):
return 15000.0
class Programmer(Employee):
"""程序员"""
def __init__(self, name, working_hour=0):
"""
初始化方法
:param name: 姓名
:param working_hour:工作时长
"""
# 请在此处添加代码 #
# *************begin************#
super().__init__(name)
self.__working_hour = working_hour
# **************end*************#
@property
def working_hour(self):
'''返回工作时长'''
# 请在此处添加代码 #
# *************begin************#
return self.__working_hour
# **************end*************#
@working_hour.setter
def working_hour(self, working_hour):
'''
设置工作时长
:param working_hour:工作时长
'''
# 请在此处添加代码 #
# *************begin************#
self.__working_hour = working_hour
# **************end*************#
def get_salary(self):
'''返回程序员所得工资'''
# 请在此处添加代码 #
# *************begin************#
return self.__working_hour*150.0
# **************end*************#
class Salesman(Employee):
"""销售员"""
def __init__(self, name, sales=0):
"""
初始化方法
:param name: 姓名
:param sales:销售额
"""
# 请在此处添加代码 #
# *************begin************#
super().__init__(name)#内置函数:调用父类方法,方便子类继承
self.__sales = sales
# **************end*************#
@property
def sales(self):
'''返回销售额'''
# 请在此处添加代码 #
# *************begin************#
return self.__sales
# **************end*************#
@sales.setter
def sales(self, sales):
'''
设置销售额
:param sales:销售额
'''
# 请在此处添加代码 #
# *************begin************#
self.__sales = 100 #销售额的默认值为100
# **************end*************#
def get_salary(self):
'''返回销售员所得工资'''
# 请在此处添加代码 #
# *************begin************#
return self.__sales*0.05+1200
# **************end*************#本题学习思考笔记:
1. @property作用:
@property是Python中的一个装饰器,用于将一个类方法转换成属性调用。它的作用是让方法的调用者可以像调用属性一样来调用这个方法,从而简化代码的编写和阅读。 在上述代码中,我们可以看到@property被用来装饰Employee的name、Programmer的working_hour和Salesman的sales方法。这样,我们就可以通过直接调用这些方法来获取对应的属性值,而不需要使用()来调用方法。例如,我们可以通过以下方式直接获取员工的姓名和工作时长:代码更加简洁易读#方法1:有修饰符 @property p = Programmer('Jerry', 160) print(p.name) # 直接调用name方法获取员工姓名 print(p.working_hour) # 直接调用working_hour方法获取员工工作时长 #方法2:没有修饰符,方法 p = Programmer('Jerry', 160) print(p.name()) # 通过方法调用来获取员工姓名 print(p.working_hour()) # 通过方法调用来获取员工工作时长
2. @abstractmethod
@abstractmethod是Python中的一个装饰器,用于标记一个方法为抽象方法。抽象方法是一种不需要具体实现的方法,它只定义了方法的签名(即方法名、参数列表和返回值类型),而没有具体的实现代码。抽象方法通常用于定义一些基础的操作或行为,而这些操作或行为的具体实现则交给子类来完成。 使用@abstractmethod装饰器来定义抽象方法有以下几个作用:
- 强制子类实现抽象方法:被
@abstractmethod装饰的方法必须在子类中被实现,否则子类将无法被实例化。这样可以确保子类实现了基础的操作或行为,从而使得整个应用程序更加稳定可靠。- 明确接口和规范:抽象方法定义了一个类的接口和规范,它告诉其他开发者这个类应该具有哪些基础的操作或行为,从而更加清晰地表达代码的意图。
- 提高代码的可读性和可维护性:抽象方法可以将常见的操作或行为提取出来,从而避免代码的重复,提高代码的可读性和可维护性。 下面是一个使用
@abstractmethod定义抽象方法的示例代码:from abc import ABC, abstractmethod class Shape(ABC): @abstractmethod def area(self): pass @abstractmethod def perimeter(self): pass #定义了一个Shape类,并在其中定义了area和perimeter两个抽象方法。 #这两个方法没有具体的实现代码,只是定义了方法的签名。 #这样,任何继承自Shape的子类都必须实现这两个方法,否则将无法被实例化。
3. @sales.setter
@sales.setter是Python中的一个装饰器,用于将一个方法转换成属性的设置器(setter)。在使用@sales.setter时,需要配合使用@property装饰器,从而定义一个可读写的属性。被@sales.setter装饰的方法将会在属性被重新赋值时自动调用,从而实现对属性的设置和校验。 例如,在下面的代码中,我们定义了一个Salesman类,并使用@property和@sales.setter装饰器定义了一个sales属性:class Salesman(Employee): def __init__(self, name, sales=0): super().__init__(name) self._sales = sales @property def sales(self): return self._sales @sales.setter def sales(self, value): if value < 0: raise ValueError("Sales value must be positive!") self._sales = value 定义了一个私有属性_sales,然后使用@property装饰器将其转换成了一个可读的属性sales。接着,我们使用@sales.setter装饰器定义了一个名为sales的方法,并在其中对属性进行了校验。当我们使用以下方式为sales属性赋值时: s = Salesman('Tom', 10000) s.sales = -1000 由于赋值的值小于0,因此将会引发ValueError异常。这样,我们就可以通过使用@sales.setter装饰器来定义属性的设置器,并对属性进行校验,从而提高代码的可靠性和可维护性。
第2关:设计LFU缓存类
(一) 什么是LFU缓存类呢?
LFU(Least Frequently Used)缓存类是一种缓存算法,用于在缓存中淘汰最不经常使用的缓存项。LFU缓存类维护了一个缓存项列表,每个缓存项都有一个访问计数器,记录该缓存项被访问的次数。当缓存空间不足时,LFU缓存类会淘汰访问计数器最小的缓存项。
LFU缓存类的实现需要维护两个数据结构:
哈希表:用于快速查找缓存项。哈希表的键是缓存项的key,值是缓存项的指针。
最小堆:用于按照访问计数器排序缓存项。最小堆中的每个结点都是一个缓存项,结点的关键字是缓存项的访问计数器。
LFU缓存类的操作包括:
添加缓存项:如果缓存已满,则需要淘汰访问计数器最小的缓存项。
如果存在访问计数器相同的缓存项,则选择最早访问的缓存项进行淘汰。
查找缓存项:在哈希表中快速查找缓存项,并将其访问计数器加1。
LFU缓存类的优点:可以淘汰最不常用的缓存项,避免缓存被占用过多,但实现较为复杂。
(二)双链表如何实现的这个缓存?
双链表的作用是为了实现LRU缓存机制。LRU(Least Recently Used)是一种缓存淘汰算法,它的基本原理是根据数据的历史访问记录来进行淘汰,即淘汰最近最少使用的数据。
在实现LRU缓存机制时,需要维护一个双链表来记录缓存中数据的访问顺序。每当有数据被访问时,就将其移动到链表头部。当缓存空间不足时,就从链表尾部淘汰最近最少使用的数据。双链表在本题中的作用是为了实现LRU缓存机制,确保缓存中的数据按照访问顺序进行存储和淘汰。
关于本题头歌:
在《计算机组成原理》当中,135页也有相关介绍和应用
- 缓存算法广泛存在于各种软件中,其中有一些著名的缓存方法,如LFU替换算法,LFU(Least Frequently Used)算法根据数据的历史访问频率来淘汰数据,其核心思想是“如果数据过去被访问多次,那么将来被访问的频率也更高”。LFU实现方式是这个缓存算法使用一个计数器来记录条目被访问的频率。通过使用LFU缓存算法,最低访问数的条目首先被移除。LFU的每个数据块都有一个引用计数,所有数据块按照引用计数排序,具有相同引用计数的数据块则按照时间排序。
- LFU缓存的实现:LFU(Least Frequently Used)是根据频率维度来选择将要淘汰的元素,即删除访问频率最低的元素 ①先比较频率,选择访问频率最小的元素②如果频率相同,则按时间维度淘汰掉最久远的那个元素。
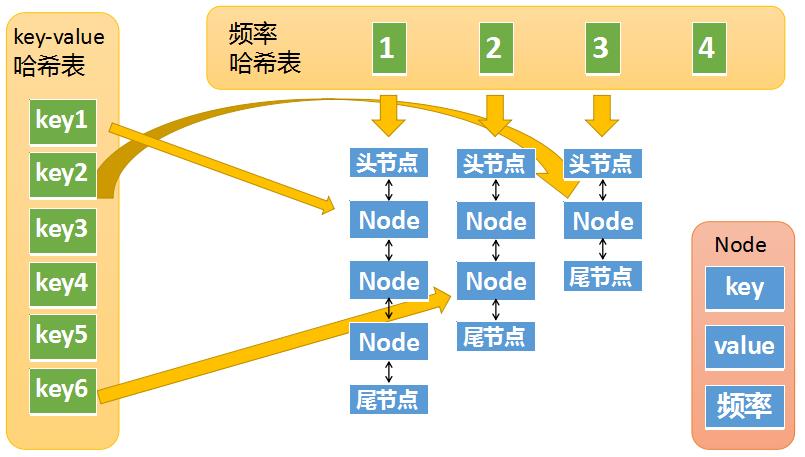
- 因此,LFU可以通过两个哈希表再加上多个双链表来实现:
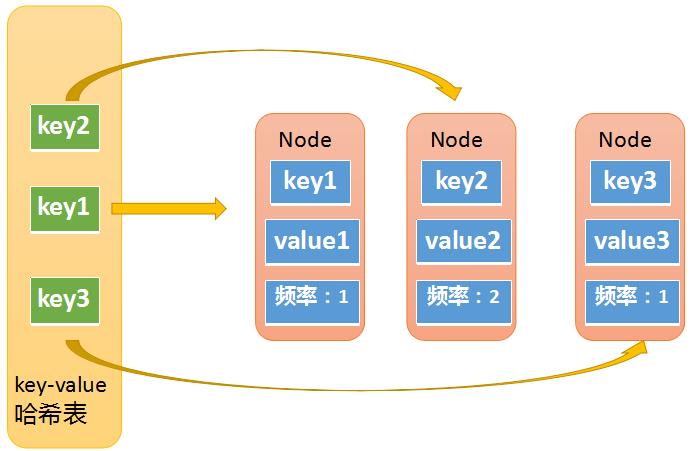
- 第一张哈希表是key-value的哈希表,如下图所示。其中key就是输入的key。value是一个节点对象。这个节点对象Node包含了key,value,以及频率,这个Node又会出现在第二个哈希表的value中。Node中重复包含了key,这是因为某些情况下我们不是通过key-value哈希表拿到Node的,而是通过其他方式获得了Node,之后需要用Node中的key去key-value哈希表中做一些操作,所以Node中包含了一些冗余信息。
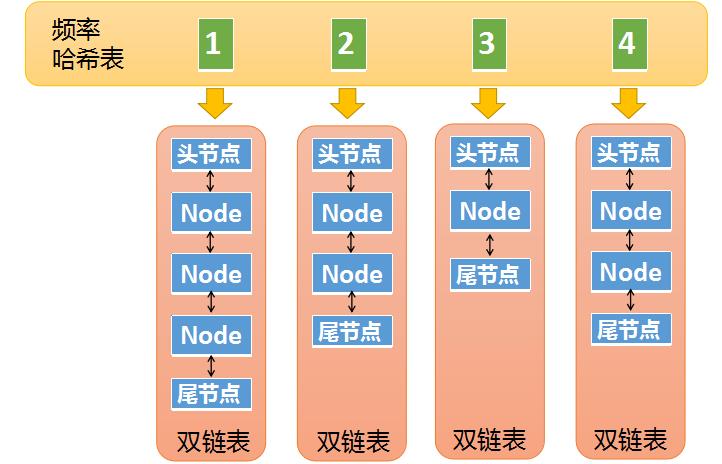
- 第二张哈希表是频率哈希表,如下图所示。这张哈希表中的key是频率,也就是元素被访问的频率(被访问了1次,被访问了两次等),它的value是一个双向链表,图一中的Node对象,在图二中同样存在,图二中的Node其实是双向链表中的一个节点。图一中的Node对象中包含了一个冗余的key,其实它还包含了一个冗余的频率值,因为某些情况下,我们需要通过Node对象中的频率值,去频率哈希表中做查找,所以也需要一个冗余的频率值。
- 因此,我们将两个哈希表整合可以发现,整个完整的LFU cache结构如下图所示。
现在请你完成一个具有put,get功能的LFU Cache类.
- put、get的逻辑如下:


python面向对象编程设计与开发
以上是关于头歌:Python开发技术—面向对象程序设计3 详细注释(第1关:工资结算系统+第2关:设计LFU缓存类)的主要内容,如果未能解决你的问题,请参考以下文章