凯斯西储大学轴承数据介绍及处理
Posted 新池坡南
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了凯斯西储大学轴承数据介绍及处理相关的知识,希望对你有一定的参考价值。
轴承故障诊断一般使用美国凯斯西储大学的数据集进行标准化检测算法的优劣。以下几种实验数据提取和使用方法为我在论文中所看到的。进行以下陈述
一、基于 RA-LSTM 的轴承故障诊断方法
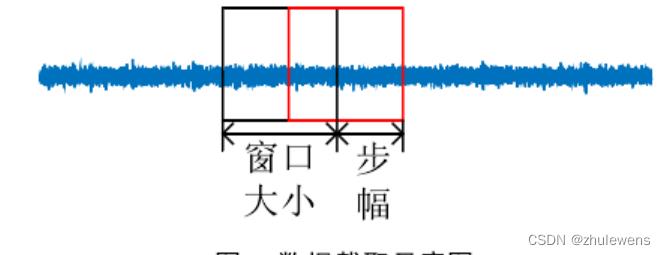
实验数据采用美国凯斯西储大学的SKF型轴承的DE(drive end accelerometer data 驱动端加速度数据)端加速度数据,转速为1730r/min,样本采用频率为48kHz。实验所选轴承单点直径损伤分别为0.007mm、0.014mm、0.021mm的故障,每种故障直径内含有滚动体故障、内圈故障以及外圈故障共三种故障类型。实验数据集由九种故障数据集以及一种正常数据组成,生成数据集的截取方法如图5所示,通过设置一个定值的窗口对数据进行截取,并对窗口按照指定步幅移动,进行下一次截取。将截取后的数据集的70%作为训练集,30%作为测试集。
二、残差网络和注意力机制相结合的滚动轴承故障诊断模型
实验采用凯斯西储大学的滚动轴承振动数据,选用SKF-6205驱动端轴承,其转速为1797r/min,信号采样频率为12kHz,对应有正常(N)、外圈故障(OR)、内圈故障(IR)和滚动体故障(RB)这4种状态,其振动信号如图5所示。图5中N和RB信号有较强的随机性,而IR和OR信号则具备一定的周期性特征,难以直接进行轴承状态的区分。
选择轴承故障的3种损伤尺寸(0.017 78cm、0.035 56cm、0.053 34cm),将轴承状态划分为10种状态标签。同时按照工程实际取5~7转的振动信号,即取每段样本长度为2048点,采用如图6所示的滑动窗重叠采样的方法进行数据增广扩充,将总样本扩充至10的4次方量级。具体数据划分及样本量如下表所示。


三、基于卷积神经网络的轴承故障诊断算法研究
数据集增强:
增强机器学习模型泛化能力最好办法是使用更多的训练样本。数据集增强技术即通过增加训练样本,以达到增强深度网络泛化性能的目的。在计算机视觉领域,数据集增强的方式有图片镜像,旋转,平移,修剪缩放,调整对比度等方法。然而,目前在故障诊断领域,并没有专门提出数据集增强技术,部分诊断算法的训练样本量很少[1,25],这样很容易造成过拟合。对于一维故障诊断信号,由于其特有时序性和周期性,图片的数据集增强技术并不完全适用。
本文提出的数据增强方式是重叠采样,即对于训练样本,从原始信号进行采集训练样本时,每一段信号与其后一段信号之间是有重叠的,采样方式如图 2-6 所示。对于测试样本,采集时没有重叠。假设一段故障诊断信号有 60000 个数据点,每次采集的训练样本长度为 2048,偏移量为 1,那么最多可以制作 57953 个训练样本,可以很好的满足深度神经网络的训练需求。

数据集介绍:
本文的试验数据来自于凯斯西储大学(CWRU)滚动轴承数据中心。CWRU数据集是世界公认的轴承故障诊断标准数据集。截止到 2015 年,仅机械故障诊断领域顶级期刊《Mechanical Systems and Signal Processing》就发表过 41 篇使用CWRU 轴承数据进行故障诊断的文章。在基于深度学习的轴承故障诊断领域,目前被引用数最高的两篇文章[25,26]的试验数据也均来自 CWRU 轴承数据库。当下,轴承故障诊断算法更新较快,为了评价被提出算法的优越性,最客观的方式就是使用第三方标准数据库与当下主流算法比较。因此,本文的所有试验均采用 CWRU
轴承数据。
CWRU 轴承中心数据采集系统如图 2-7 所示。本试验的试验对象为图中的驱动端轴承,被诊断的轴承型号为深沟球轴承 SKF6205,有故障的轴承由电火花加工制作而成,系统的采样频率为 12kHz。被诊断的轴承一共有 3 种缺陷位置,分别是滚动体损伤,外圈损伤与内圈损伤,损伤直径的大小分别为包括 0.007inch, 0.014inch 和 0.021inch,共计 9 种损伤状态。试验中,每次使用 2048 个数据点进行诊断。为了便于训练卷积神经网络,对每段信号𝑥均做归一化处理,归一化处理的公式如式(2-22)所示:

试验一共准备了 4 个数据集,如表 2-3 所示。数据集 A、B 和 C 分别是在负载为 1hp、2hp 和 3hp 下的数据集。每个数据集各包括 6600 个训练样本与 250 个测试样本,其中训练样本采用数据集增强技术,测试样本之间无重叠。数据集 D 是数据集 A、B 和 C 的并集,即包括了 3 种负载状态,一共有 19800 个训练样本与750 个测试样本。

凯斯西储数据集(CWRU)十分类处理与训练代码(Pytorch)
数据预处理(十分类)
文件名:data_10
| Fault location | Loads(hp) | Defect diameters (inches) | Class |
|---|---|---|---|
| Normal | 0/1/2/3 | 0 | 0 |
| Inner race | 0/1/2/3 | 0.007 0.014 0.021 | 1 2 3 |
| Ball | 0/1/2/3 | 0.007 0.014 0.021 | 4 5 6 |
| Outer race | 0/1/2/3 | 0.007 0.014 0.021 | 7 8 9 |
import random
import numpy as np
import scipy.io as scio
from sklearn import preprocessing
def open_data(bath_path,key_num):
#open_data('/Users/apple/Desktop/cwru/12k Drive End Bearing Fault Data/',105)
path = bath_path + str(key_num) + ".mat"
str1 = "X" + "%03d"%key_num + "_DE_time"
data = scio.loadmat(path)
data = data[str1]
return data
def deal_data(data,length,label):
#line:num column:1025
data = np.reshape(data,(-1))
num = len(data)//length
data = data[0:num*length]
data = np.reshape(data,(num,length))
min_max_scaler = preprocessing.MinMaxScaler()
data = min_max_scaler.fit_transform(np.transpose(data,[1,0]))
data = np.transpose(data,[1,0])
label = np.ones((num,1))*label
return np.column_stack((data,label))
def split_data(data,split_rate):
length = len(data)
num1 = int(length*split_rate[0])
num2 = int(length*split_rate[1])
index1 = random.sample(range(num1),num1)
train = data[index1]
data = np.delete(data,index1,axis=0)
index2 = random.sample(range(num2),num2)
valid = data[index2]
test = np.delete(data,index2,axis=0)
return train,valid,test
def load_data(num,length,hp,fault_diameter,split_rate):
#num: number of sample in each data file
#length: each sample
#split_rate: train:valid:test
bath_path1 = 'path of Normal Baseline Data'
bath_path2 = 'path of 12k Drive End Bearing Fault Data/'
data_list = []
file_list = np.array([[105,118,130,106,119,131,107,120,132,108,121,133], #0.007
[169,185,197,170,186,198,171,187,199,172,188,200], #0.014
[209,222,234,210,223,235,211,224,236,212,225,237]]) #0.021
label = 0
#normal data
for i in hp:
normal_data = open_data(bath_path1,97+i)
data = deal_data(normal_data,length,label = label)
data_list.append(data)
#abnormal data
for i in fault_diameter:
for j in hp:
inner_num = file_list[int(i/0.007-1),3*j]
ball_num = file_list[int(i/0.007-1),3*j+1]
outer_num = file_list[int(i/0.007-1),3*j+2]
inner_data = open_data(bath_path2,inner_num)
inner_data = deal_data(inner_data,length,label + 1)
data_list.append(inner_data)
ball_data = open_data(bath_path2,ball_num)
ball_data = deal_data(ball_data,length,label + 4)
data_list.append(ball_data)
outer_data = open_data(bath_path2,outer_num)
outer_data = deal_data(outer_data,length,label + 7)
data_list.append(outer_data)
label = label + 1
#keep each class same number of data
num_list = []
for i in data_list:
num_list.append(len(i))
min_num = min(num_list)
if num > min_num:
print("The number of each class overflow, the maximum number is:%d" %min_num)
min_num = min(num,min_num)
#Divide the train, validation, test sets and shuffle
train = []
valid = []
test = []
for data in data_list:
data = data[0:min_num,:]
a,b,c = split_data(data,split_rate)
train.append(a)
valid.append(b)
test.append(c)
train = np.reshape(train,(-1,length+1))
train = train[random.sample(range(len(train)),len(train))]
train_data = train[:,0:length]
train_label = train[:,length]
onehot_encoder = preprocessing.OneHotEncoder(sparse=False)
train_label = train_label.reshape(len(train_label), 1)
train_label = onehot_encoder.fit_transform(train_label)
valid = np.reshape(valid,(-1,length+1))
valid = valid[random.sample(range(len(valid)),len(valid))]
valid_data = valid[:,0:length]
valid_label = valid[:,length]
valid_label = valid_label.reshape(len(valid_label), 1)
valid_label = onehot_encoder.fit_transform(valid_label)
test = np.reshape(test,(-1,length+1))
test = test[random.sample(range(len(test)),len(test))]
test_data = test[:,0:length]
test_label = test[:,length]
test_label = test_label.reshape(len(test_label), 1)
test_label = onehot_encoder.fit_transform(test_label)
return train_data,train_label,valid_data,valid_label,test_data,test_label
WDCNN训练与测试
from data_10 import load_data
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.data
from torch.utils.data import DataLoader, TensorDataset
import torchvision
from torchvision import datasets, transforms
class Net(nn.Module):
def __init__(self, in_channel=1, out_channel=10):
super(TeacherNet, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv1d(in_channel, 16, kernel_size=64,stride=16,padding=24),
nn.BatchNorm1d(16),
nn.ReLU(inplace=True),
nn.MaxPool1d(kernel_size=2,stride=2)
)
self.layer2 = nn.Sequential(
nn.Conv1d(16, 32, kernel_size=3,padding=1),
nn.BatchNorm1d(32),
nn.ReLU(inplace=True),
nn.MaxPool1d(kernel_size=2, stride=2))
self.layer3 = nn.Sequential(
nn.Conv1d(32, 64, kernel_size=3,padding=1),
nn.BatchNorm1d(64),
nn.ReLU(inplace=True),
nn.MaxPool1d(kernel_size=2, stride=2)
)
self.layer4 = nn.Sequential(
nn.Conv1d(64, 64, kernel_size=3,padding=1),
nn.BatchNorm1d(64),
nn.ReLU(inplace=True),
nn.MaxPool1d(kernel_size=2, stride=2)
)
self.layer5 = nn.Sequential(
nn.Conv1d(64, 64, kernel_size=3),
nn.BatchNorm1d(64),
nn.ReLU(inplace=True),
nn.MaxPool1d(kernel_size=2, stride=2)
)
self.fc=nn.Sequential(
nn.Linear(64, 100),
nn.ReLU(inplace=True),
nn.Linear(100, out_channel)
)
def forward(self, x):
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.layer5(x)
x = x.view(x.size(0), -1)
output = self.fc(x)
return output
def train_Model(model,train_loader,optimizer,epoch):
model.train()
trained_samples = 0
correct = 0
for batch_idx, (data, target) in enumerate(train_loader):
optimizer.zero_grad()
output = model(data)
loss_fn = nn.MSELoss(reduce=True, size_average=True)
loss = loss_fn(output.float(), target.float())
loss.backward(loss.clone().detach())
optimizer.step()
trained_samples += len(data)
print("\\rTrain epoch %d: %d/%d, " %
(epoch, trained_samples, len(train_loader.dataset),), end='')
pred = output.argmax(dim=1, keepdim=True)
real = target.argmax(dim=1, keepdim=True)
correct += pred.eq(real.view_as(pred)).sum().item()
train_acc = correct / len(train_loader.dataset)
print("Train acc: " , train_acc)
def test_Model(model,test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
output = model(data) #logits
print(output)
loss_fn = nn.MSELoss(reduce=True, size_average=False)
test_loss += loss_fn(output.float(), target.float()).item() # sum up batch loss
pred = output.argmax(dim=1, keepdim=True) # get the index of the max log-probability
# print((pred==4).sum())
target = target.argmax(dim=1, keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print('\\nTest: average loss: :.4f, accuracy: / (:.2f%)'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
return test_loss, correct / len(test_loader.dataset)
def main():
epochs = 300
batch_size = 32
torch.manual_seed(0)
train_dataset,train_label,_,_,test_dataset,test_label = load_data(num = 100,length = 1024,hp = [0,1,2,3],fault_diameter = [0.007,0.014,0.021],split_rate = [0.7,0.1,0.2])
train_dataset = torch.tensor(train_dataset)
train_label = torch.tensor(train_label)
test_dataset = torch.tensor(test_dataset)
test_label = torch.tensor(test_label)
train_dataset = train_dataset.unsqueeze(1)
test_dataset = test_dataset.unsqueeze(1)
train_dataset = train_dataset.to(torch.float32)
test_dataset = test_dataset.to(torch.float32)
train_id = TensorDataset(train_dataset, train_label)
test_id = TensorDataset(test_dataset, test_label)
train_loader = DataLoader(dataset=train_id, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(dataset=test_id, batch_size=batch_size, shuffle=False)
model = Net()
optimizer = torch.optim.Adadelta(model.parameters())
model_history = []
for epoch in range(1, epochs + 1):
train_Model(model, train_loader, optimizer, epoch)
loss, acc = test_Model(model, test_loader)
model_history.append((loss, acc))
# torch.save(model.state_dict(), "model.pt")
return model, model_history
model, model_history = main()
以上是关于凯斯西储大学轴承数据介绍及处理的主要内容,如果未能解决你的问题,请参考以下文章