旋转目标检测复现-yolov5-obb
Posted 浪迹天涯@wxy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了旋转目标检测复现-yolov5-obb相关的知识,希望对你有一定的参考价值。
复现源码:
https://github.com/hukaixuan19970627/yolov5_obb
亲测可行
安装流程:
按照https://github.com/hukaixuan19970627/yolov5_obb/blob/master/docs/install.md
确保安装过程不报错,否则影响后续训练
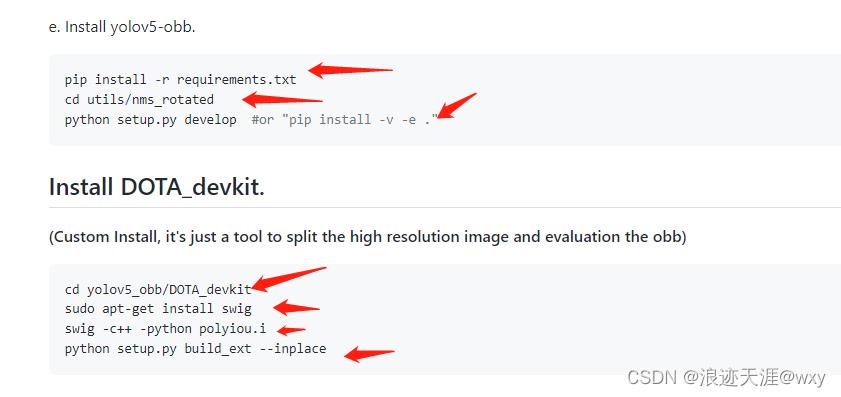
安装成功即可准备数据集
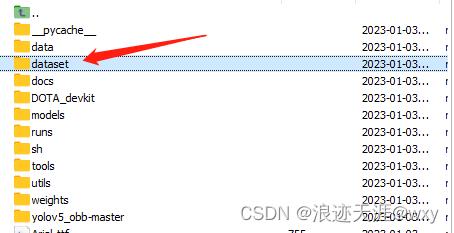

hf_txt存放划分好的训练集、测试集、验证集,里面内容为数据图像文件名,
images存放要训练的图像
labelTxt存放将xml转换后的txt标签文件
hf.py数据集划分;
# -*- coding: utf-8 -*-
import os
import random
trainval_percent = 0.9
train_percent = 0.9
xmlfilepath = 'xml'
txtsavepath = 'images'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open('hf_txt/trainval.txt', 'w')
ftest = open('hf_txt/test.txt', 'w')
ftrain = open('hf_txt/train.txt', 'w')
fval = open('hf_txt/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
xml转txt;
# 文件名称 :roxml_to_dota.py
# 功能描述 :把rolabelimg标注的xml文件转换成dota能识别的xml文件,
# 再转换成dota格式的txt文件
# 把旋转框 cx,cy,w,h,angle,转换成四点坐标x1,y1,x2,y2,x3,y3,x4,y4
import os
import xml.etree.ElementTree as ET
import math
def edit_xml(xml_file,dotaxml_file):
"""
修改xml文件
:param xml_file:xml文件的路径
:return:
"""
tree = ET.parse(xml_file)
objs = tree.findall('object')
for ix, obj in enumerate(objs):
x0 = ET.Element("x0") # 创建节点
y0 = ET.Element("y0")
x1 = ET.Element("x1")
y1 = ET.Element("y1")
x2 = ET.Element("x2")
y2 = ET.Element("y2")
x3 = ET.Element("x3")
y3 = ET.Element("y3")
# obj_type = obj.find('bndbox')
# type = obj_type.text
# print(xml_file)
if (obj.find('robndbox') == None):
obj_bnd = obj.find('bndbox')
obj_xmin = obj_bnd.find('xmin')
obj_ymin = obj_bnd.find('ymin')
obj_xmax = obj_bnd.find('xmax')
obj_ymax = obj_bnd.find('ymax')
xmin = float(obj_xmin.text)
ymin = float(obj_ymin.text)
xmax = float(obj_xmax.text)
ymax = float(obj_ymax.text)
obj_bnd.remove(obj_xmin) # 删除节点
obj_bnd.remove(obj_ymin)
obj_bnd.remove(obj_xmax)
obj_bnd.remove(obj_ymax)
x0.text = str(xmin)
y0.text = str(ymax)
x1.text = str(xmax)
y1.text = str(ymax)
x2.text = str(xmax)
y2.text = str(ymin)
x3.text = str(xmin)
y3.text = str(ymin)
else:
obj_bnd = obj.find('robndbox')
obj_bnd.tag = 'bndbox' # 修改节点名
obj_cx = obj_bnd.find('cx')
obj_cy = obj_bnd.find('cy')
obj_w = obj_bnd.find('w')
obj_h = obj_bnd.find('h')
obj_angle = obj_bnd.find('angle')
cx = float(obj_cx.text)
cy = float(obj_cy.text)
w = float(obj_w.text)
h = float(obj_h.text)
angle = float(obj_angle.text)
obj_bnd.remove(obj_cx) # 删除节点
obj_bnd.remove(obj_cy)
obj_bnd.remove(obj_w)
obj_bnd.remove(obj_h)
obj_bnd.remove(obj_angle)
x0.text, y0.text = rotatePoint(cx, cy, cx - w / 2, cy - h / 2, -angle)
x1.text, y1.text = rotatePoint(cx, cy, cx + w / 2, cy - h / 2, -angle)
x2.text, y2.text = rotatePoint(cx, cy, cx + w / 2, cy + h / 2, -angle)
x3.text, y3.text = rotatePoint(cx, cy, cx - w / 2, cy + h / 2, -angle)
# obj.remove(obj_type) # 删除节点
obj_bnd.append(x0) # 新增节点
obj_bnd.append(y0)
obj_bnd.append(x1)
obj_bnd.append(y1)
obj_bnd.append(x2)
obj_bnd.append(y2)
obj_bnd.append(x3)
obj_bnd.append(y3)
tree.write(dotaxml_file, method='xml', encoding='utf-8') # 更新xml文件
# 转换成四点坐标
def rotatePoint(xc, yc, xp, yp, theta):
xoff = xp - xc;
yoff = yp - yc;
cosTheta = math.cos(theta)
sinTheta = math.sin(theta)
pResx = cosTheta * xoff + sinTheta * yoff
pResy = - sinTheta * xoff + cosTheta * yoff
return str(int(xc + pResx)), str(int(yc + pResy))
def totxt(xml_path,out_path):
# 想要生成的txt文件保存的路径,这里可以自己修改
files = os.listdir(xml_path)
for file in files:
tree = ET.parse(xml_path + os.sep + file)
root = tree.getroot()
name = file.strip('.xml')
output = out_path + name + '.txt'
file = open(output, 'w')
objs = tree.findall('object')
for obj in objs:
cls = obj.find('name').text
box = obj.find('bndbox')
x0 = int(float(box.find('x0').text))
y0 = int(float(box.find('y0').text))
x1 = int(float(box.find('x1').text))
y1 = int(float(box.find('y1').text))
x2 = int(float(box.find('x2').text))
y2 = int(float(box.find('y2').text))
x3 = int(float(box.find('x3').text))
y3 = int(float(box.find('y3').text))
file.write(" 0\\n".format(x0, y0, x1, y1, x2, y2, x3, y3, cls))
file.close()
print(output)
if __name__ == '__main__':
# -----**** 第一步:把xml文件统一转换成旋转框的xml文件 ****-----
roxml_path = "/root/autodl-tmp/yolov5_obb/dataset/dataset_demo/xml/" # 目录下保存的是需要转换的xml文件
dotaxml_path = '/root/autodl-tmp/yolov5_obb/dataset/dataset_demo/1xml/'
out_path = '/root/autodl-tmp/yolov5_obb/dataset/dataset_demo/labelTxt/'
filelist = os.listdir(roxml_path)
for file in filelist:
edit_xml(os.path.join(roxml_path, file), os.path.join(dotaxml_path, file))
# -----**** 第二步:把旋转框xml文件转换成txt格式 ****-----
totxt(dotaxml_path, out_path)
voc_label.py划分训练集,验证集,测试集路径:
# -*- coding: utf-8 -*-
import xml.etree.ElementTree as ET
import os
from os import getcwd
sets = ['train', 'val', 'test']
classes = ["large_car","small_car"]
abs_path = os.getcwd()
wd = getcwd()
for image_set in sets:
if not os.path.exists('labelTxt/'):
os.makedirs('labelTxt/')
image_ids = open('hf_txt/%s.txt' % (image_set)).read().strip().split()
list_file = open('%s.txt' % (image_set), 'w')
for image_id in image_ids:
list_file.write(abs_path + '/images/%s.jpg\\n' % (image_id))
list_file.close()
修改相应数据集访问路劲

# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
#path: ./dataset # dataset root dir
train: dataset/dataset_demo/train.txt #images # train images (relative to 'path')
val: dataset/dataset_demo/val.txt #images # val images (relative to 'path')
#test: dataset_demo/images #images # test images (optional)
# Classes
nc: 2 # number of classes
names: ['large_car','small_car'] # class names
# Download script/URL (optional)
# download: https://ultralytics.com/assets/coco128.zip
最后修改训练文件train.py,修改成对应的文件路径即可
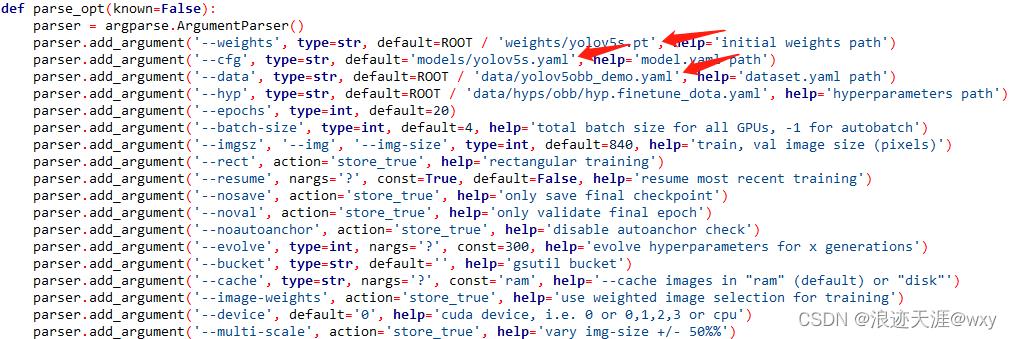
上述都没问题即可训练
python train.py
扩展:部署yolov5-obb:
https://blog.csdn.net/qq_41043389/article/details/127777272
百度飞桨顶会论文复现营目标检测综述笔记
参加了百度飞桨顶会论文复现营第二期,这次是目标检测综述的笔记。
RCNN到Faster RCNN这几种模型讲的实在太多了,直接从FPN开始吧。
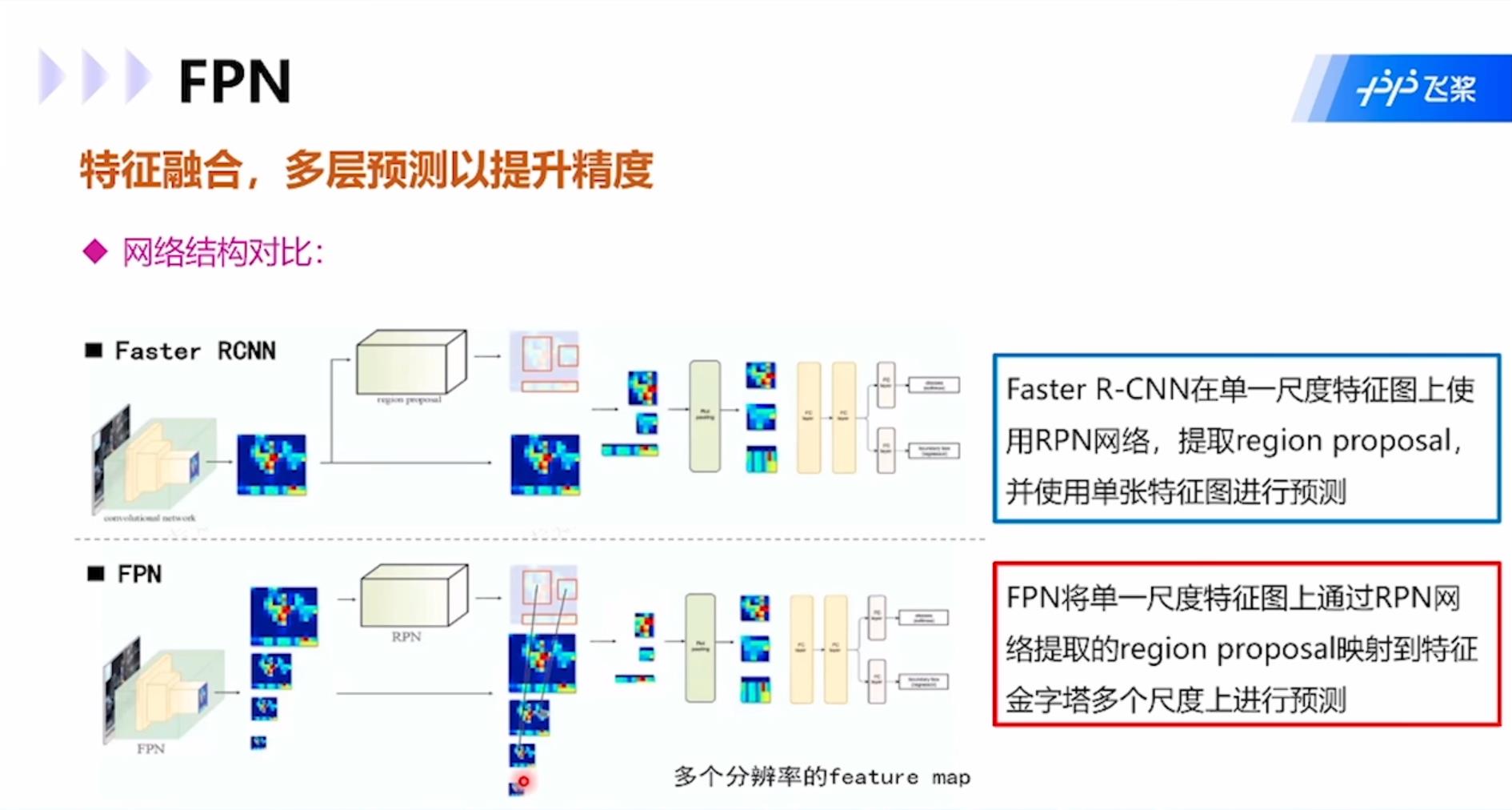
FPN:通过将深层特征与浅层特征相融合,并在多层预测,加强了浅层特征图的语义,特征更加鲁棒,定位更加准确。同时提高了检测精度,尤其对于小目标。模型结构图中蓝框越粗语义信息越多,图像分辨率越小,篮框越细上下文信息更强,图像分辨率越高。
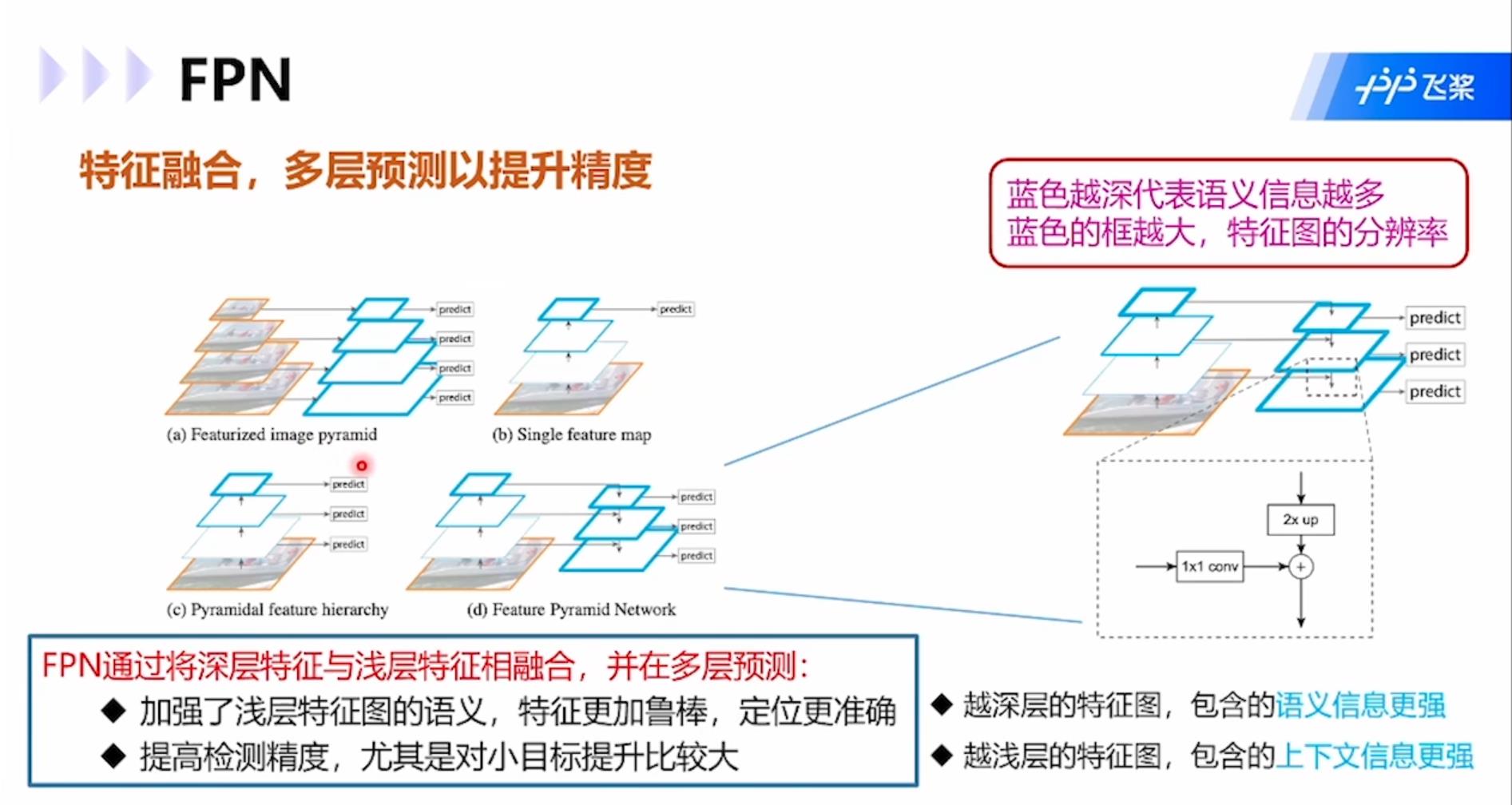
与Faster RCNN相比,FPN将单一尺度特征图上通过RPN网络提取的region proposal映射到特征金字塔多个尺度上进行预测,而Faster RCNN是在单一尺寸特征图上使用RPN网络,提取regional proposal,使用单张特征图进行预测。
YOLO:属于one-stage模型,算法流程是:1.将输入图像划分为S×S个网格;2.每个网格预测B个边界框和这个边界框是物体的概率,具体为4个表示坐标的值xywh和1个置信度Pr(object)*IoU(truth&pred);3.每个网格预测C个类的概率。
每个网格内的预测边界框并不一定必须在网格内,可以横跨多个网格。每个网格还需要投票该网格的类别,然后将边界框和该网格类别合起来就是目标检测的结果。

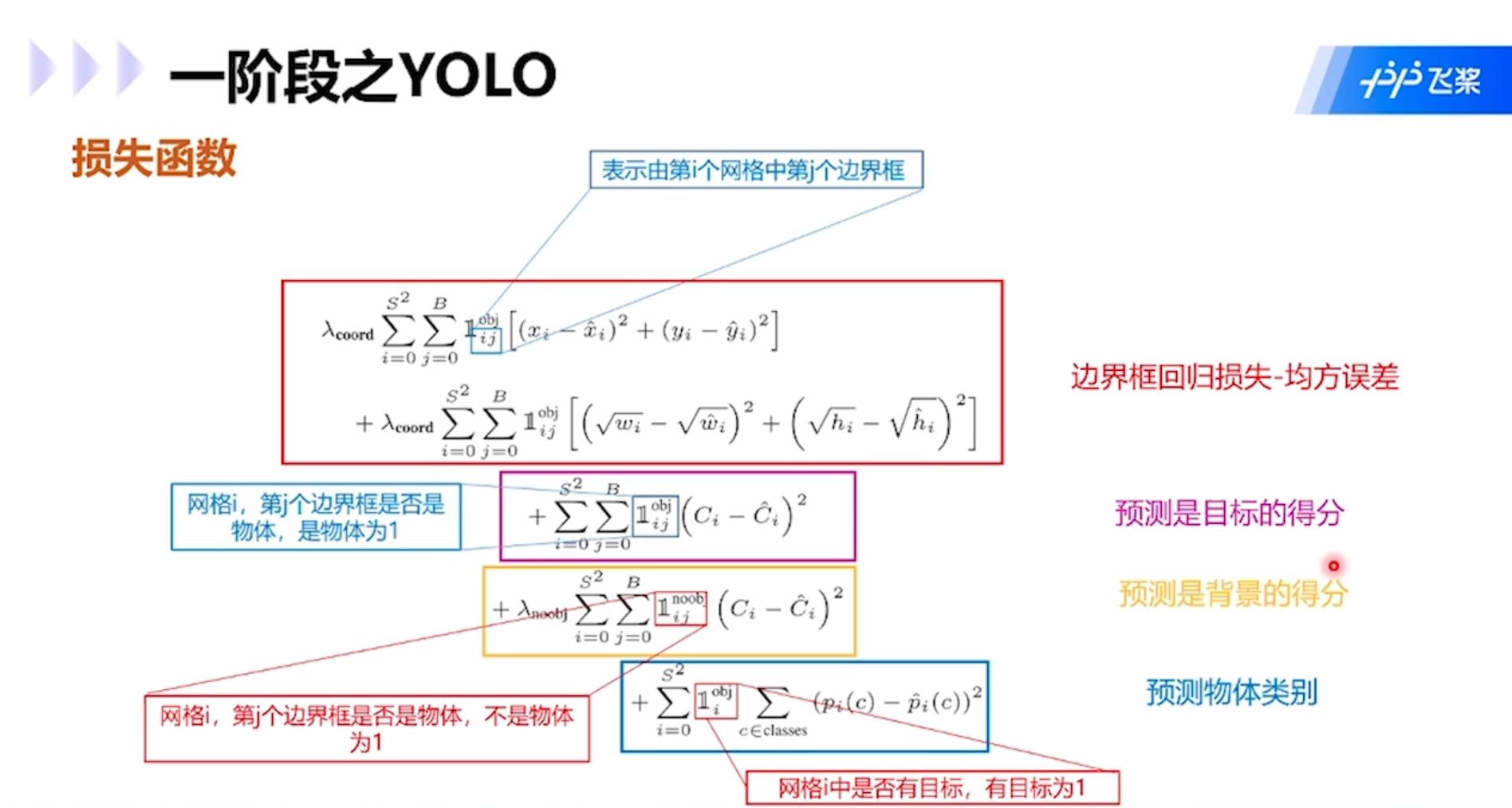
损失函数包括四项:边界框回归损失-均方误差;预测是目标的得分;预测是背景的得分;预测物体类别。
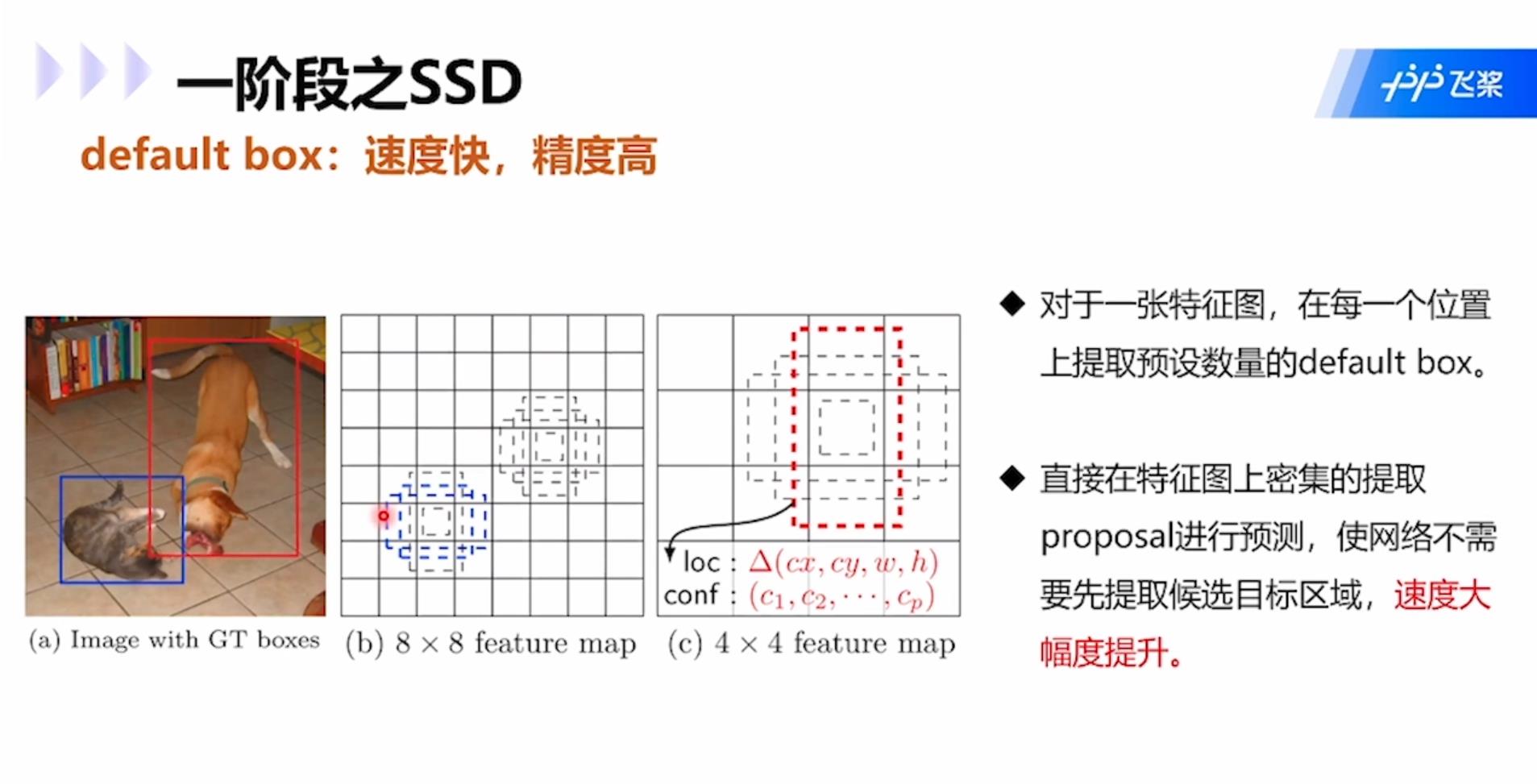
SSD:同属于one-stage模型。对于同一张特征图,在每一个位置上提取预设数量的default box,然后直接在特征图上密集的提取proposal进行预测,使网络不需要先提取候选目标区域,速度大幅提升。
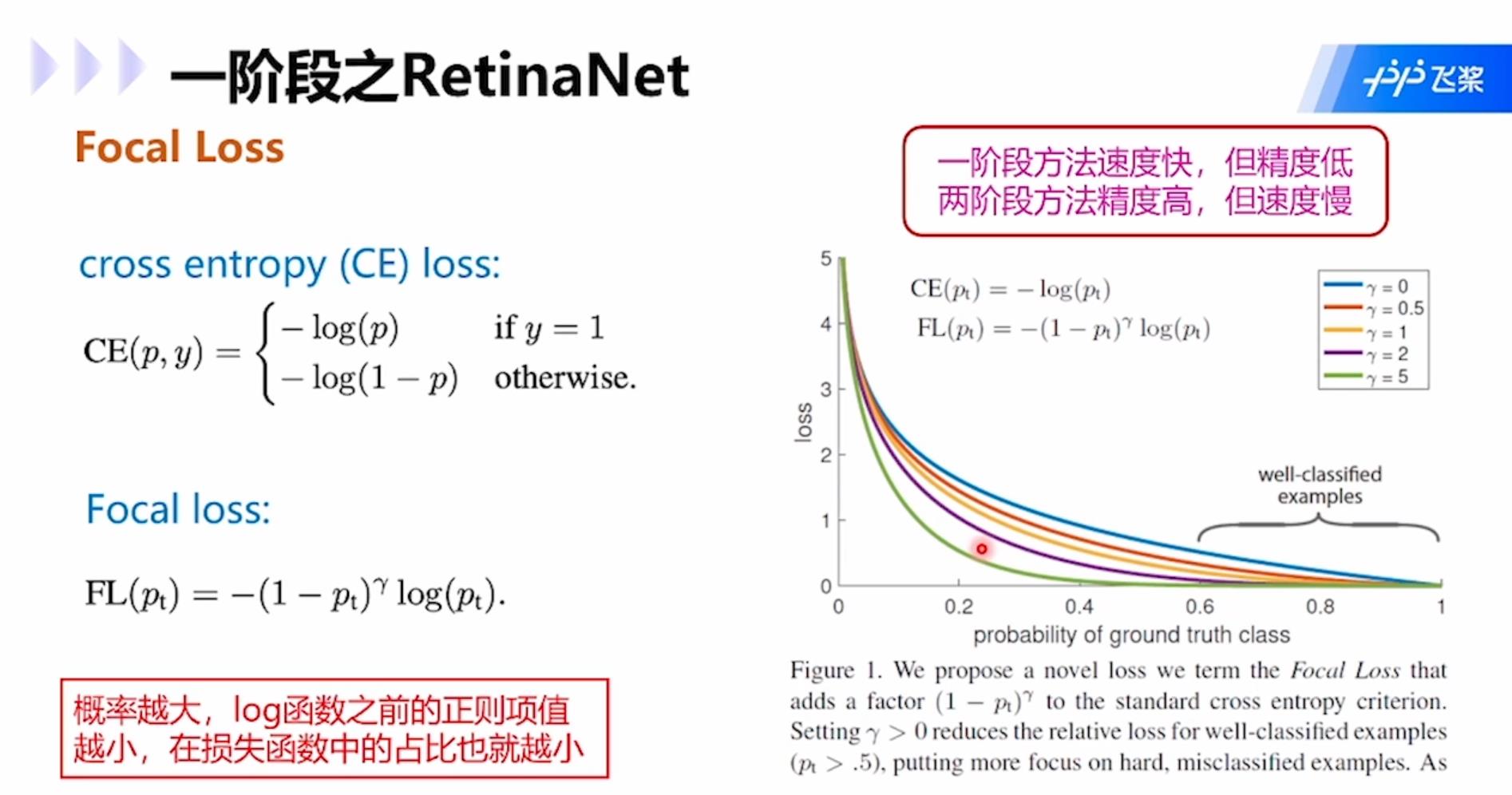
RetinaNet:解决了one-stage模型训练过程中,负样本数量大大超过正样本的问题。类别不平衡是指目标检测算法在早期会生成很多候选区域框,每个框都会生成一个分类类别,然而实际图像中往往只有几个目标,所以大多数候选区域的类别为“背景”,即类别不平衡,是的分类器的训练精度严重受损。
Two-stage模型中,RPN网络可以很大程度减轻类别不平衡问题,使类别极不平衡变为类别较不平衡,然而one-stage方法则会被严重影响精度。改进思路是对损失函数计算进行改进,例如focal loss,适用于各类网络。Focal loss的思路是在交叉熵函数的log前面加上(1-p),这个系数的意思就是1减去属于这个类别的概率,如果属于这个类别的概率比较大,就意味着高置信度被分为这个类别,所以1减去该概率的值就会很小,所以在分类的时候高概率会被分成某个类别的损失值就会比较小,也就是概率越大的类别在损失函数中占比越小,这样网络就会更聚焦在分类概率小的类别中。这样的方法在各类网络中都可以用。
考虑IoU损失的方法IoU-Net:通过非极大值抑制,消除冗余检测框。非极大值抑制NMS是指:1.将同一类的所有检测框按照分类置信度排序;2.将与分类置信度最高的检测框IoU大于一定阈值的检测框删除;3.从未处理的框中,再选出一个分类置信度最高的检测框,重复上述操作。

但是这种方式也会带来分类置信度删除存在问题,例如下图中红色预测框分类置信度高,绿框定位置信度高,如果使用分类置信度进行NMS,那么绿框会被舍弃,显然当前情况下绿框的预测效果要好些。分类置信度和定位准确度不对齐:只依靠分类的置信度来作为NMS中关键依据,可能会导致大量高质量的边界框丢失。

IoU存在的问题包括:1.IoU与常用的损失没有强相关性;2.如果两个对象不重叠,那么IoU为0,并且不会反应两个形状彼此之间的距离;3.IoU无法正确区分两个对象的对齐方式。
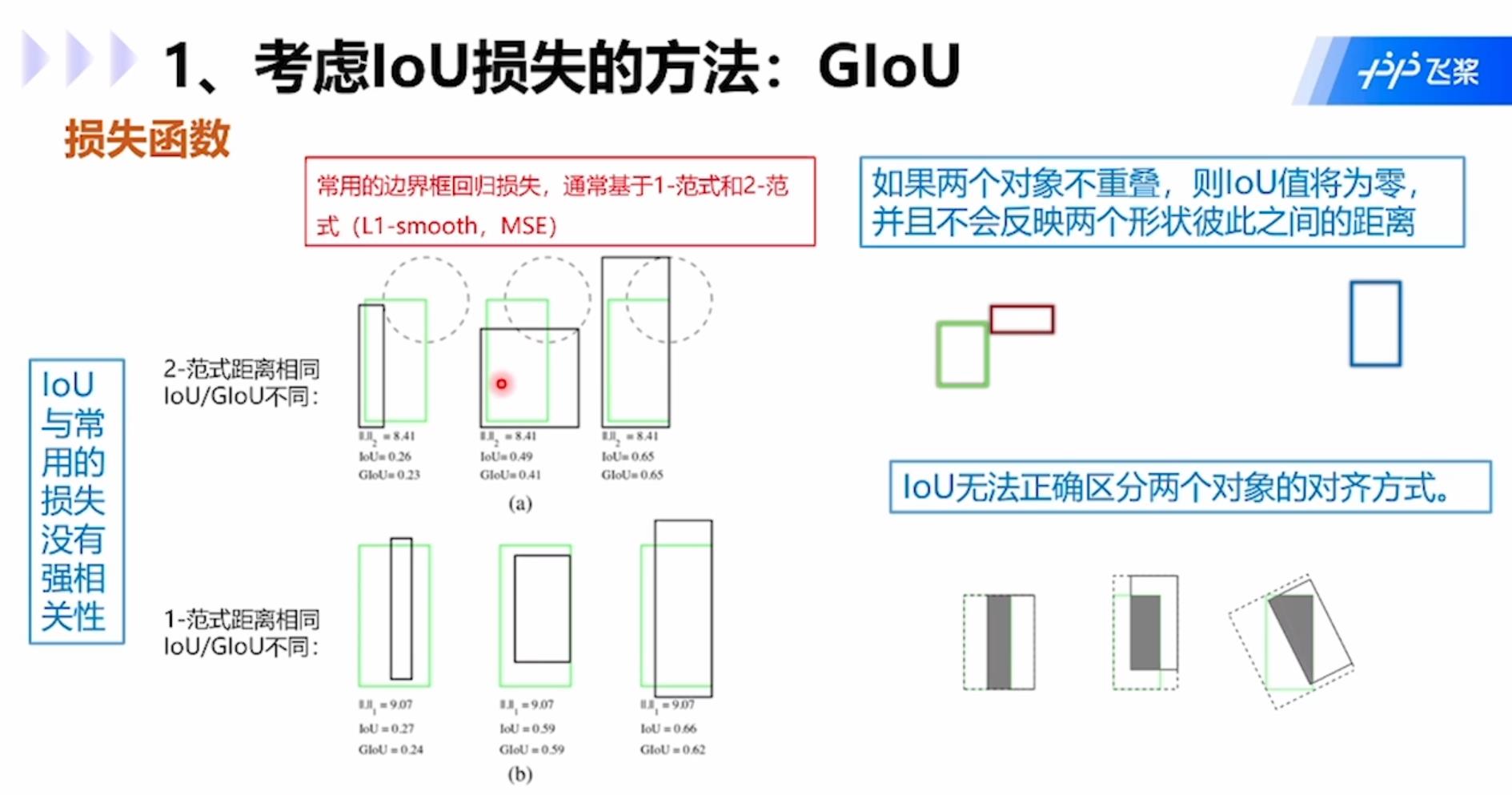
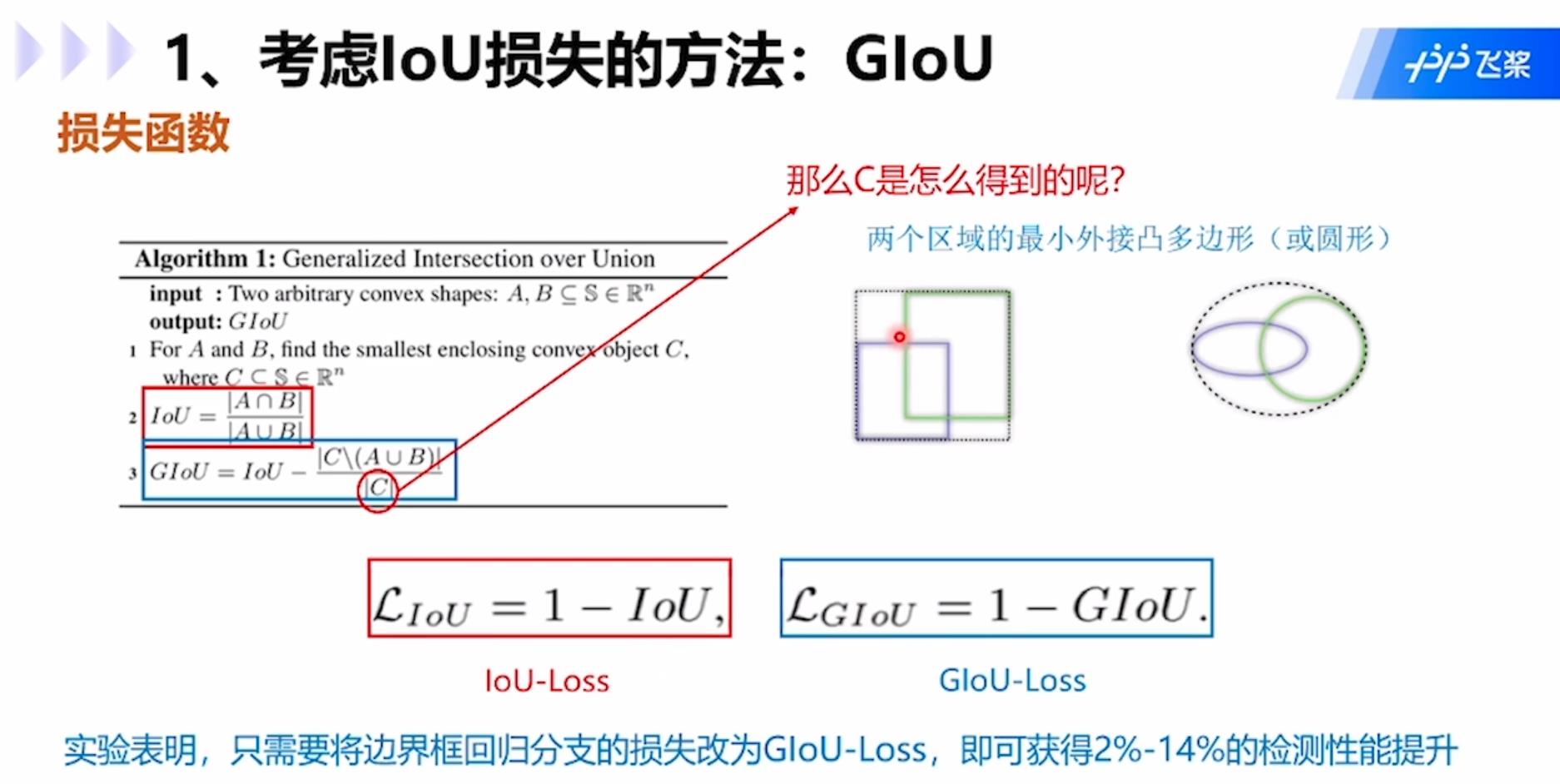
GIoU:GIoU公式中C是两个矩形框的最小外接矩形,就是虚线的大矩形框,公式中分子是外接矩形框去除两个小矩形框A和B后的部分,分母就是C,用IOU减去该值就是GIOU的值。
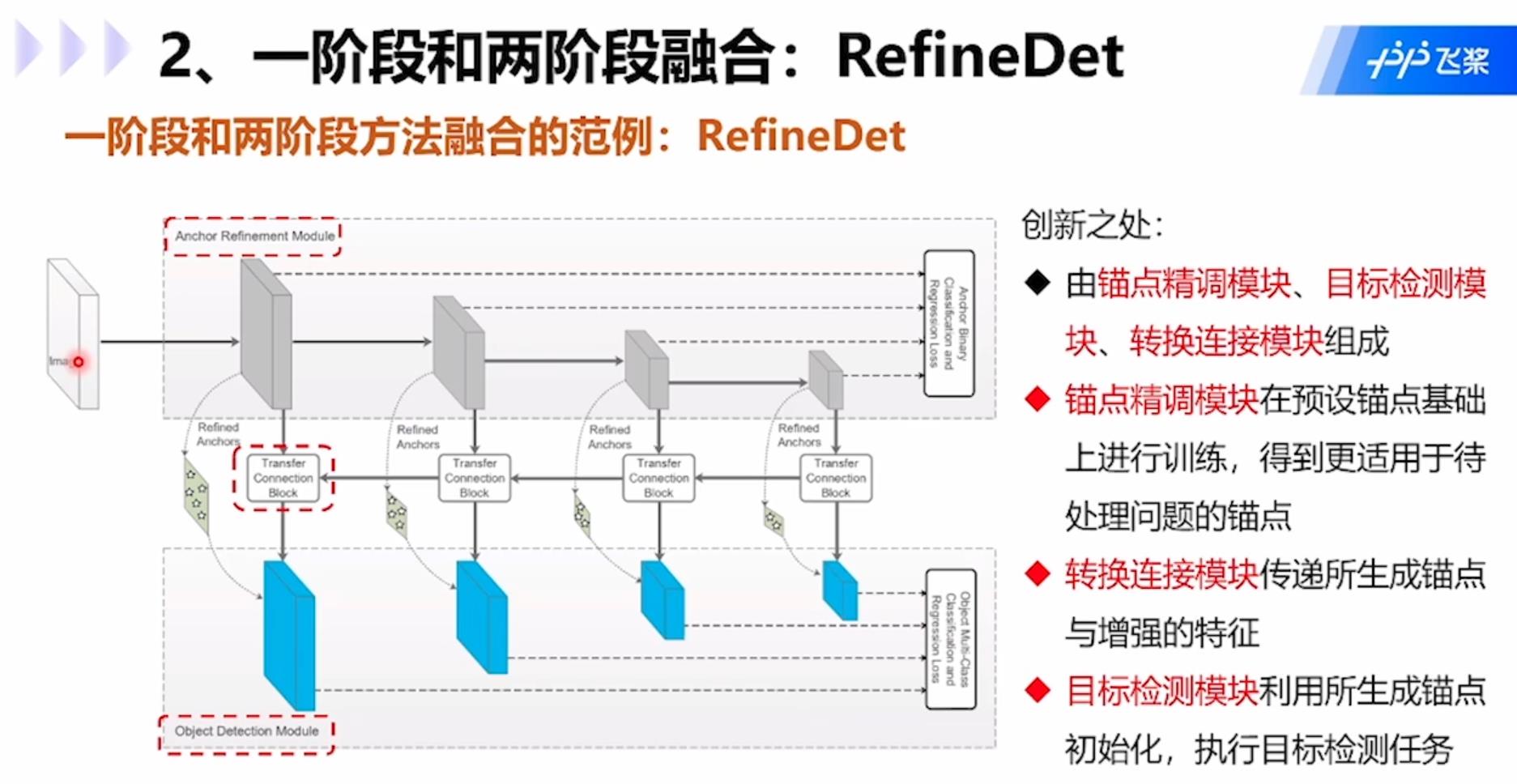
一阶段和两阶段融合的模型RefineDet:创新点在于:1.由锚点精调模块、目标检测模块、转换连接模块组成;2.锚点精调模块在预设锚点基础上进行训练,得到更适用于待处理问题的锚点;3.转换连接模块传递所生成锚点与增强的特征;4.目标检测模块利用所生成锚点初始化,执行目标检测任务。
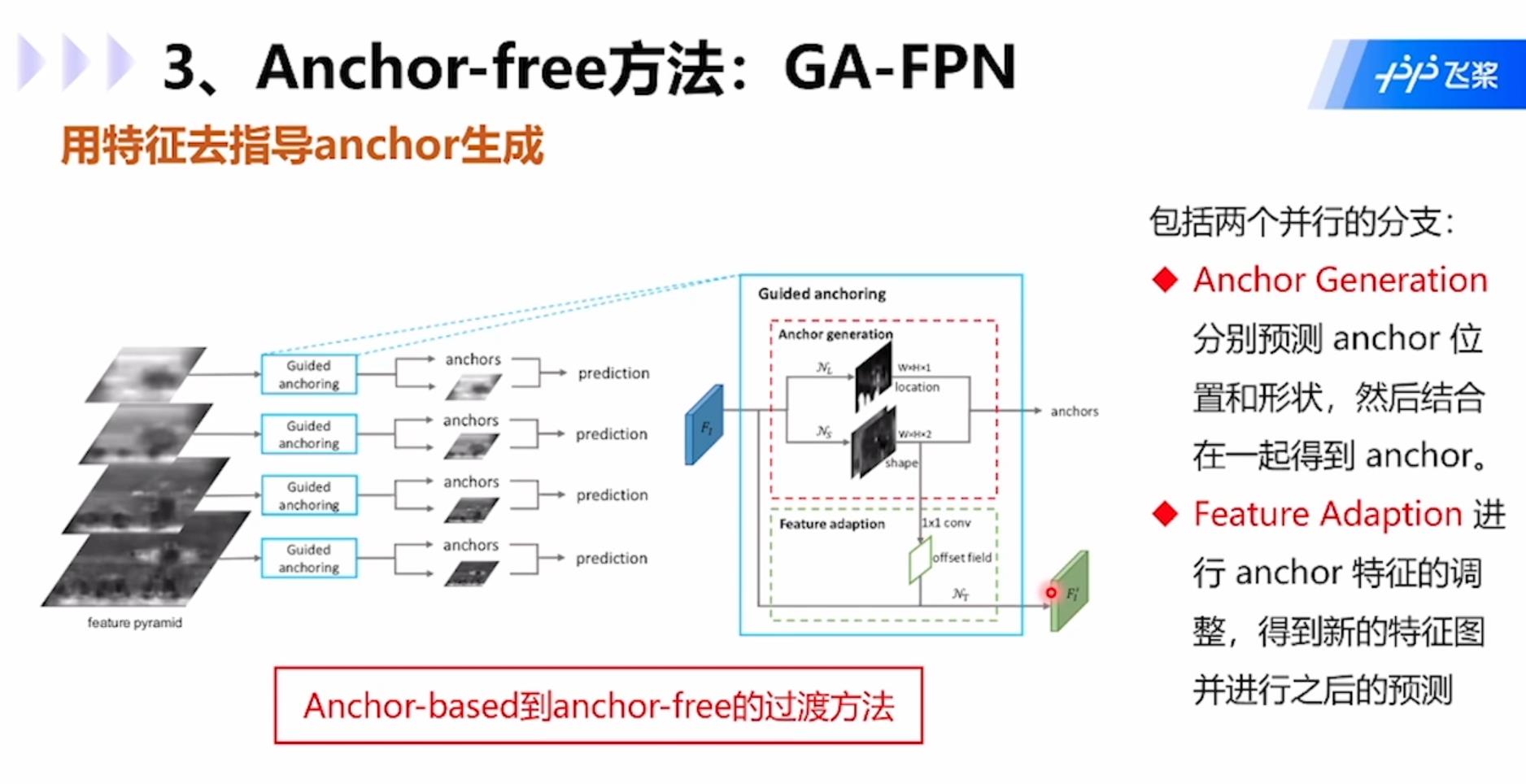
Anchor方法的问题:无需预先设置锚点。必须针对不同问题定义一组固定宽高比的锚点,错误的设计可能会妨碍检测器,影响速度和精度。为了对目标保持足够高的召回率,需要大量锚点,而大多数锚点对应于与目标无关的候选区域。大量的锚点会导致显著的计算成本,尤其是当方法存在候选框分析阶段涉及重型分类器时。这样就需要用到anchor-free方法了。
GA-FPN:使用特种功能去指导anchor的生成。模型包括两个并行的分支:1.Anchor Generation:分别预测anchor位置和形状,然后结合在一起得到anchor;2.Feature Adaption:进行anchor特征的调整,得到新的特征图并进行之后的预测。
CornerNet模型:利用成对角点预测的目标检测模型。利用单个卷积网络将框的左上角和右下角两个点组成一对关键点,进而不需要设计在单阶段检测中大量的anchor boxes,同时引入了corner pooling用于提升角点定位效果。这个模型思想新颖,只需要预测两个关键点的类别即可,只需要做点的拟合,不需要再做anchor。

步骤如下:1.采用hourglass network提取特征,该网络通过串联多个hourglass module组成,每个hourglass module都是先通过一系列的降采样操作缩小输入的大小,然后通过上采样恢复到输入图像的大小;2. hourglass network后会有两个输出分支模块,分别表示左上角点预测分支和右下角点预测分支;3.每个分支模块包含一个corner pooling层和3个输出:heatmap、embeddings和offsets,其中heatmap用啦癌输出预测的角点信息,embeddings用来对预测的corner点做group,找到属于同一个目标的左上角和右下角角点,offsets基于输入图像中的点映射到特征图时的量化误差,对预测框做微调。

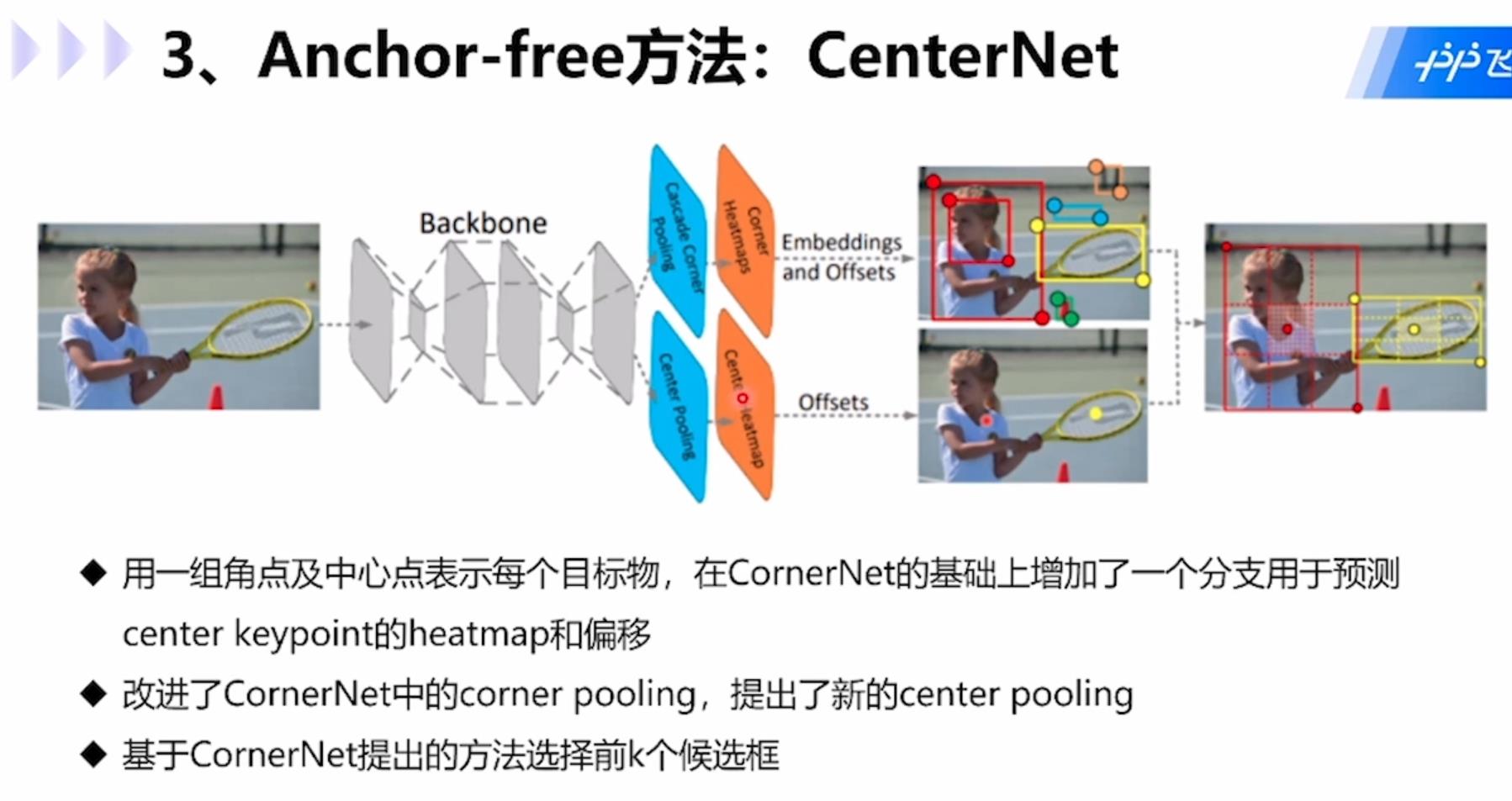
CenterNet模型:用成对角点+中心点预测目标,在CornerNet基础上,CenterNet通过检测每个目标看做是预测一组三个关键点(增加一个关键点来探索proposal中间区域的信息)而不是一对关键点,提供了更多的监督信息,从而提高了准确率和召回率。

具体步骤为:1.用一组角点和中心点表示每个目标,在CornerNet基础上增加一个分支用于预测center keypoint的heatmap和偏移;2.改进了CornerNet中的corner pooling,提出了新的center pooling;3.基于CornerNet提出的方法选择前k个候选框。
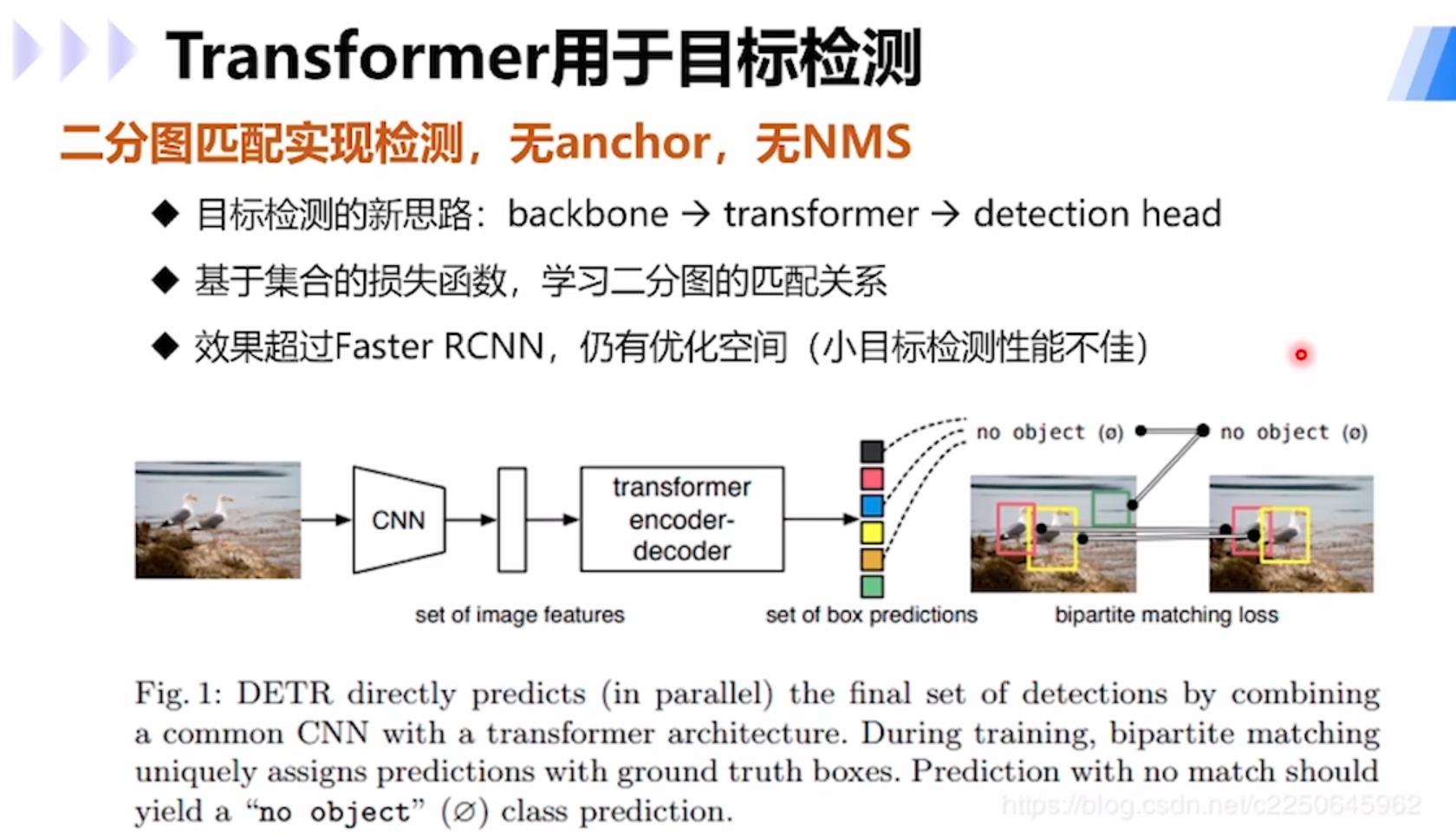
使用transformer进行目标检测的模型DETR:通过二分图匹配实现检测,无anchor,无NMS,提供了目标检测的新思路:backbone→transformer→detection head;基于集合的损失函数,学习二分图的匹配关系;大目标检测效果超过Faster R-CNN,小目标检测上仍有优化空间。
以上是关于旋转目标检测复现-yolov5-obb的主要内容,如果未能解决你的问题,请参考以下文章