判断hadoop伪分布式安装模式是否成功启动
Posted 月月爱学习
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了判断hadoop伪分布式安装模式是否成功启动相关的知识,希望对你有一定的参考价值。
1.使用命令start-all.sh,来同时启动HDFS和YARN
start-all.sh
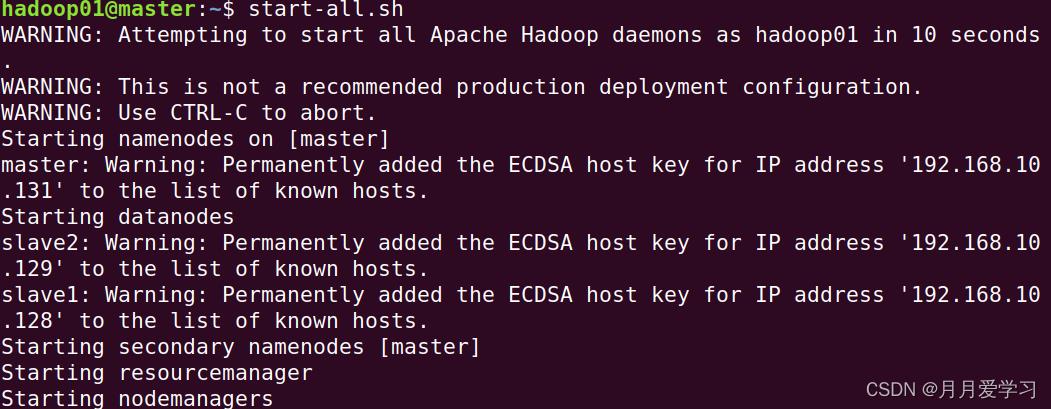
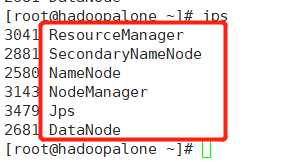
2.通过命令 jps 检验一下是否开启Hadoop的全部进程
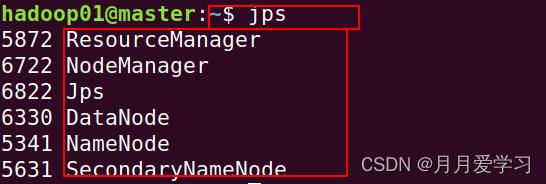
如图所示:DataNode,NameNode,SecondaryNameNode是文件系统HDFS的进程;
NodeManager,ResourceManager是YARN的进程。这五个进程都启动成功,才说明Hadoop启动成功。
Hadoop之伪分布式安装
一、Hadoop的安装模式有3种
①单机模式:不能使用HDFS,只能使用MapReduce,所以单击模式主要用于测试MR程序。
②伪分布式模式:用多个线程模拟真实多台服务器,即模拟真实的完全分布式环境。
③完全分布式模式:用多台机器(或启动多个虚拟机)来完成部署集群。
二、安装主要涉及以下内容:
①JDK
②配置主机名、hosts文件以及免密登录
③修改hadoop的配置文件,主要涉及以下几个配置文件(hadoop-2.7.7/etc/hadoop)
1)hadoop-env.sh:这里主要修改jdk的安装路径等
2)core-site.xml:主要指定namenode的地址和文件存放目录等
3)hdfs-site.xml:指定复本数量
4)mapred-site.xml:执行MR程序运行在yarn上
5)yarn-site.xml:指定NodeManager获取数据的方式和resourceManager的地址
6)slaves文件:伪分布式配置本主机名即可
④配置hadoop的环境变量和格式化namenode
三、下边将按照上述说明进行搭建hadoop的伪分布式
①获取Hadoop的安装包:http://hadoop.apache.org/releases.html,注意:source为源码包,binary为安装包
我这里以2.7.7版本为例:http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-2.7.7/hadoop-2.7.7.ta??r.gz
解压Hadoop安装包:tar -xvf hadoop...
目录说明:
bin目录:命令脚本
etc/hadoop:存放hadoop的配置文件
lib目录:hadoop运行的依赖jar包
sbin目录:启动和关闭hadoop等命令都在这里
libexec目录:存放的也是hadoop命令,但一般不常用
最常用的就是bin和etc目录
②安装jdk,下载对应linux版本的tar.gz包:https://www.oracle.com/technetwork/java/javase/downloads/index.html
1)解压:tar -xvf jdk-8u131-linux-x64.tar.gz
2)配置环境变量:vim /etc/profile
#java env JAVA_HOME=/home/softwares/jdk1.8.0_131 CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar PATH=$JAVA_HOME/bin:$PATH export JAVA_HOME PATH CLASSPATH export PATH=$PATH
3)通过:java,javac,java -version来查看jdk是否安装成功。
③关闭防火墙
1)service iptables stop 临时关闭
2)chkconfig iptables off 永久关闭
④配置主机名,修改完成以后重启!!!
vim /etc/sysconfig/network
NETWORKING=yes HOSTNAME=hadoopalone //hadoopalone 这是我修改的,表示是伪分布式
⑤配置hosts文件
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.144.133 hadoopalone //配置 ip和主机名映射
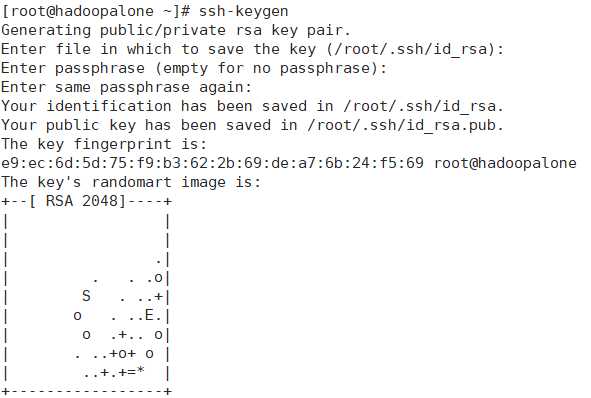
⑥配置免密登录
1)ssh-keygen,一路回车即可。
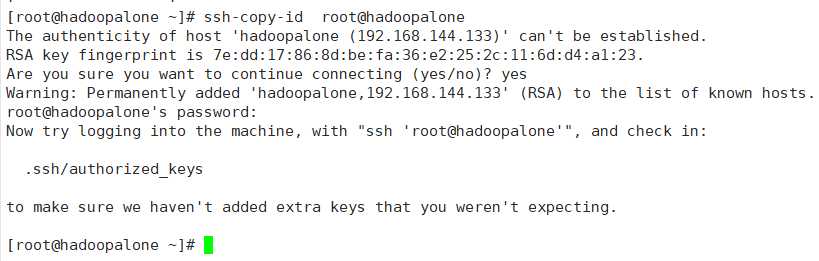
2)ssh-copy-id root@hadoopalone
⑦下面正式进入重点:Hadoop配置之hadoop-env.sh
这个文件里写的是hadoop的环境变量,主要修改hadoop的java_home路径
切换到 etc/hadoop目录
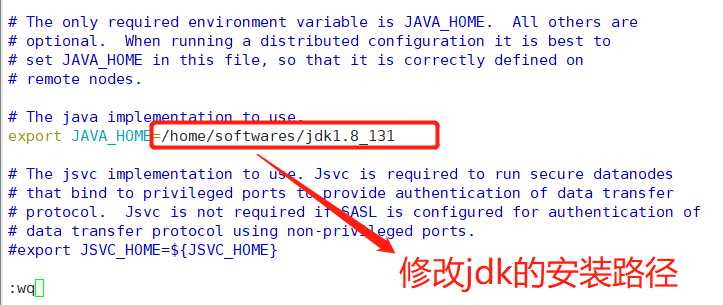
执行:vim hadoop-env.sh
修改java_home路径,如图所示,保存退出后,切记 source hadoop-env.sh使配置文件生效。
⑧Hadoop配置之core-site.xml,为防止图片失效,配置也粘贴出来。

1 <configuration> 2 <!--用来指定hdfs的老大,namenode的地址--> 3 <property> 4 <name>fs.defaultFS</name> 5 <value>hdfs://hadoopalone:9000</value> 6 </property> 7 <!--用来指定hadoop运行时产生文件的存放目录--> 8 <property> 9 <name>hadoop.tmp.dir</name> 10 <value>/home/softwares/hadoop-2.7.7/tmp</value> 11 </property> 12 <!--设置hdfs的操作权限,false表示任何用户都可以在hdfs上操作文件--> 13 <property> 14 <name>dfs.permissions</name> 15 <value>false</value> 16 </property> 17 </configuration>
⑨修改:Hadoop配置之hdfs-site.xml,为防止图片失效,配置也粘贴出来。

<configuration> <!--指定hdfs保存数据副本的数量,包括自己,默认值是3--> <!--如果是伪分布模式,此值是1即可--> <property> <name>dfs.replication</name> <value>1</value> </property> </configuration>
⑩修改:Hadoop配置之mapred-site.xml,为防止图片失效,配置也粘贴出来。默认是map-site.xml.template,拷贝并重命名为mapred-site.xml。

<configuration> <property> <!--指定mapreduce运行在yarn上--> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
(11)修改:Hadoop配置之mapred-site.xml,为防止图片失效,配置也粘贴出来。
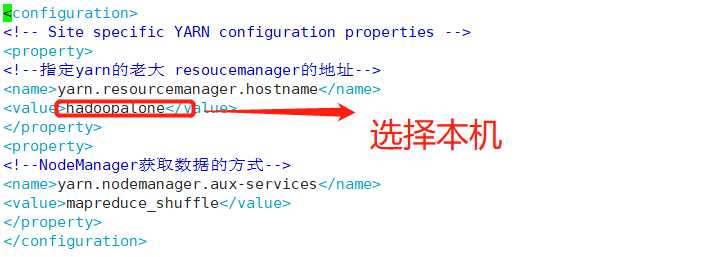
<configuration> <!-- Site specific YARN configuration properties --> <property> <!--指定yarn的老大 resoucemanager的地址--> <name>yarn.resourcemanager.hostname</name> <value>hadoopalone</value> </property> <property> <!--NodeManager获取数据的方式--> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>
(12)配置slaves文件,同样在hadoop-2.7.7/etc/hadoop目录下
vim slaves

(13)配置Hadoop的环境变量,记得source /etc/profile
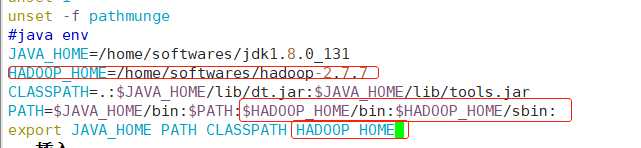
#java env
JAVA_HOME=/home/softwares/jdk1.8.0_131
HADOOP_HOME=/home/softwares/hadoop-2.7.7
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
PATH=$JAVA_HOME/bin:$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:
export JAVA_HOME PATH CLASSPATH HADOOP_HOME
export PATH=$PATH
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
(14)最后一步:格式化namenode
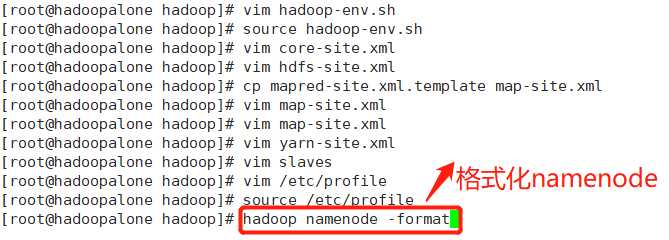
当出现以下中的关键语句表示格式化成功!
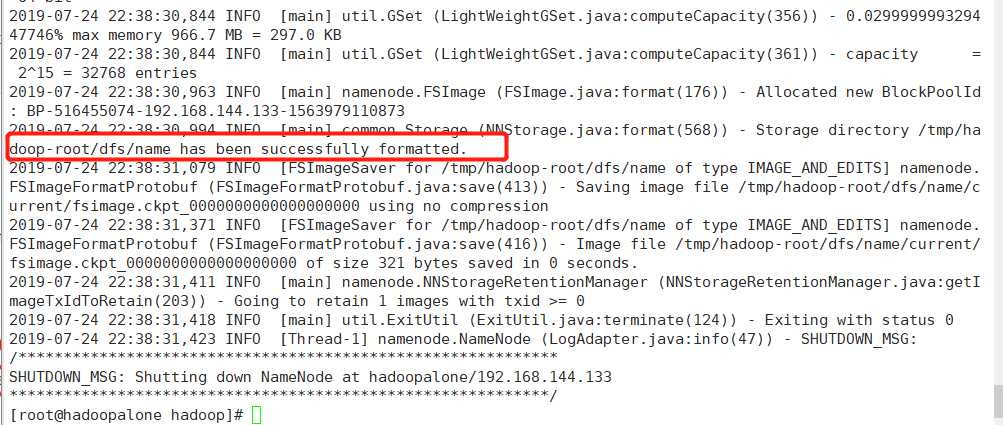
通过start-all.sh启动我们刚刚搭建的hadoop伪分布式模式:start-all.sh
通过:jps命令来查看,出现以下进程说明我们的hadoop伪分布式搭建完成!!!
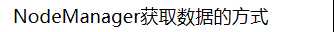
以上是关于判断hadoop伪分布式安装模式是否成功启动的主要内容,如果未能解决你的问题,请参考以下文章