李老师云计算实验一:Hadoop伪分布式集群部署与Eclipse访问Hadoop进行单词计数统计
Posted WtcSky
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了李老师云计算实验一:Hadoop伪分布式集群部署与Eclipse访问Hadoop进行单词计数统计相关的知识,希望对你有一定的参考价值。
索引
前言
本来打算写在一起,奈何一个实验的内容实在是太多了……
其实我的学长已经写过云计算的实验过程并且我也得到了不少帮助,但是仍然还是要写下这一篇博客,一是把内容完全整合到这一篇博客——面向单次实验的博客;二是有许多问题是我自己遇到的;三是我的Hadoop版本不同,可以做一个更新版本的介绍,总之同学们可以自行选择。
下面实验的要求短短十条不过百字,里面多少心血,要走多少坑爬多少山?就算对着别人的经验来做也总是出很多莫名奇妙的BUG,做这个实验需要好几天也是正常不过的事情,稍安勿躁吧只能说。尽量把每个地方可能遇到的问题说一下。
带★的是可能遇到的问题可以看一下,以防后续操作出问题。
内容可能来自博主自己手搓、吸取同学的经验、网络上内容的整合等等,仅供参考,更多内容可以查看大三下速通指南专栏。
实验内容
实验1:Hadoop伪分布式集群部署与Eclipse访问Hadoop进行单词计数统计。
(1) VMWare客户端安装
(2) VMWare NAT或仅主机网络设计与配置
(3) 防火墙配置
(4) 虚拟机互联互通
(5) 虚拟机访问外网
(6) 免密安全登录
(7) Hadoop集群设计与部署
(8) Eclipse访问Hadoop
(9) Map方法二次编程
(10) Reduce方法二次编程
1. 安装虚拟机
1.1 安装与激活
虚拟机之前学Linux的时候都安装过,不再过多赘述,百度一搜有一堆比我说得要更加清楚的博客。
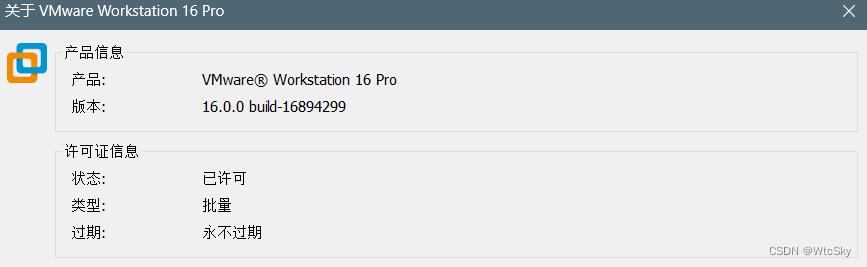
想要激活也很简单,网上搜到的相应版本的秘钥都是可以使用的。
1.2 ★解决使用虚拟机蓝屏(绿屏)
安装VMware最好装新版本的,旧版本可能与windows10、windows11不是很兼容导致经常蓝屏(绿屏),我刚开始做的时候使用的是VMware12,经常打开虚拟机或者拖拽文件就会死机,后续又下载的VMware16。
如果你已经开始操作了,没有问题的,重新安装VMware不会影响你创建好了的虚拟机。
2. 安装CentOS
2.1 下载CentOS
这里直接在阿里云镜像站下载的,如果下的慢可以去找其他的镜像站,这不是关键内容不做过多的阐述了。
选择CentOS-7-X86_64-DVD-1810.iso,等待下载完成。

2.2 VMware新建虚拟机
该操作需要重复三次(实验需要一个Master两个Slave……)
在VMware上选择文件->新建虚拟机,
然后选择自定义(高级),
然后一直下一步,直到选择安装来源,选择安装程序光盘映像文件(iso),浏览选择刚才下载的CentOS的位置(iso文件)。

下一步直到命名虚拟机,虚拟机的名称可以后续修改,改不改都可以,下面的位置是安装到的虚拟机位置(不想下C盘请修改)。
之后一直下一步就可以了,配置什么的后面可以通过编辑虚拟机进行修改。
三个虚拟机的位置最好都选在不同的文件夹中,如:
2.3 安装CentOS
该操作需要重复三次(实验需要一个Master两个Slave……)
新建虚拟机后会自动开机进入CentOS的安装程序,点进虚拟机,然后一直回车就好了,然后等待完成。
之后会弹出安装界面,按照需求选择,继续。
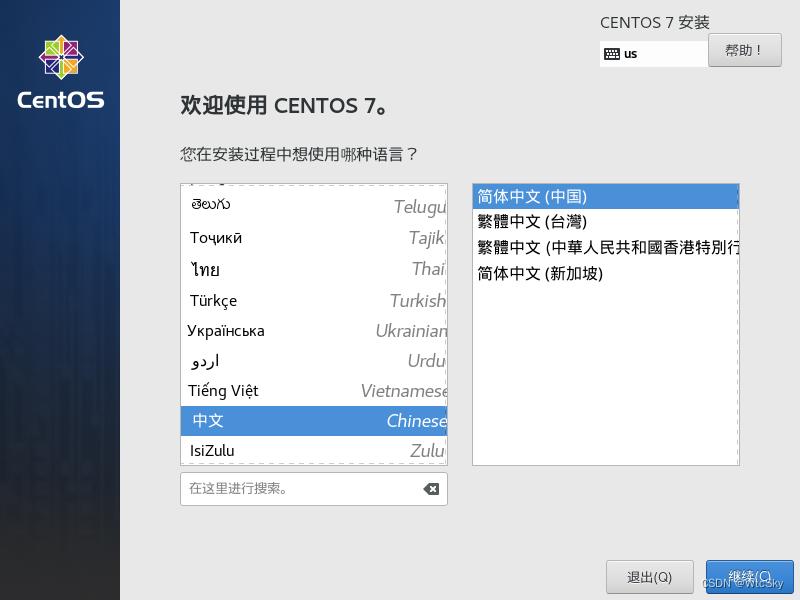
之后的安装信息摘要比较重要了,直接拖到下面前三个选项不要管,我们需要打开的有下面红框标记的三个。
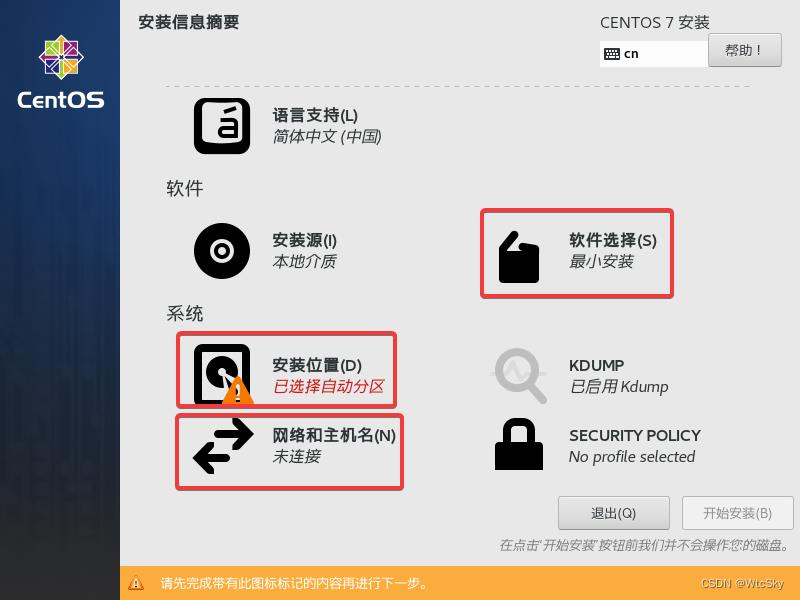
首先打开软件选择,选中带GUI的服务器,如果不选的话你的CentOS是纯命令行,说实话有点麻烦……点击完成即可。

然后打开安装位置,打开以后直接完成,什么都不需要选择。
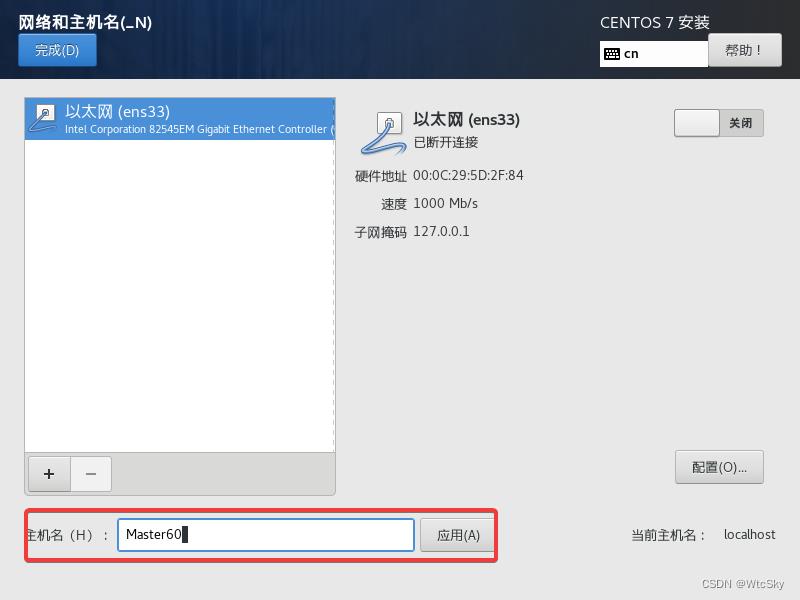
最后选择网络和主机名,根据老师的要求修改主机名(我们的要求是Master学号后两位、Slave1-学号后两位、Slave2-学号后两位)。
返回到安装界面,点击开始安装。
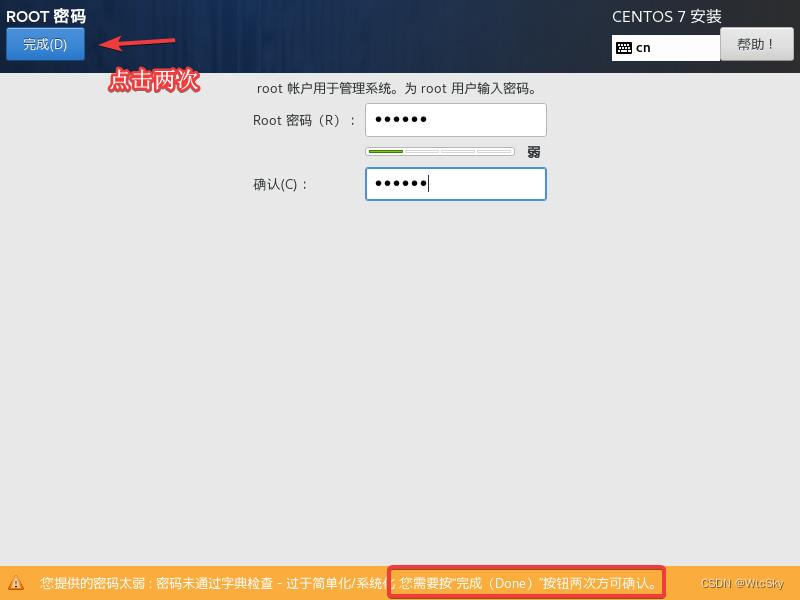
进入页面选择ROOT密码,设置为123456(别的也行,简单一点不要为难自己)。
然后等待安装完成即可。

3. VMWare 网络配置
按照老师要求,主机的ip最后一个字节是学号,
从机1是学号+1,从机2是学号+2……
3.0 使用VI编辑器和VMware
该操作需要重复三次(实验需要一个Master两个Slave……)
3.0.1 使用VI编辑器
之后会经常用到VI编辑器,因此做几个介绍:
- 使用
vi 文件路径指令打开文件 - 敲击键盘
insert键或者i键进入编辑(插入) - 在VI编辑器(以及终端)中,选中就是复制
- 在VI编辑器(以及中断)中,鼠标中键(滚轮)是粘贴
- 修改完成后
ESC,:wq是保存退出,一定要小写,大写会出错。
3.0.2 使用VMware
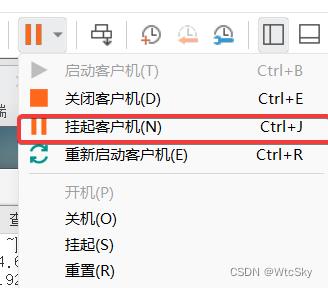
如果暂时不做了,最好是使用挂起客户机而不是关闭客户机。
3.1 虚拟机IP设置
首先查看一下虚拟机子网IP,在VMware上,点击编辑->虚拟网络编辑器。

点击VMnet8,查看下面的子网IP,如下图子网IP是192.168.64.0。
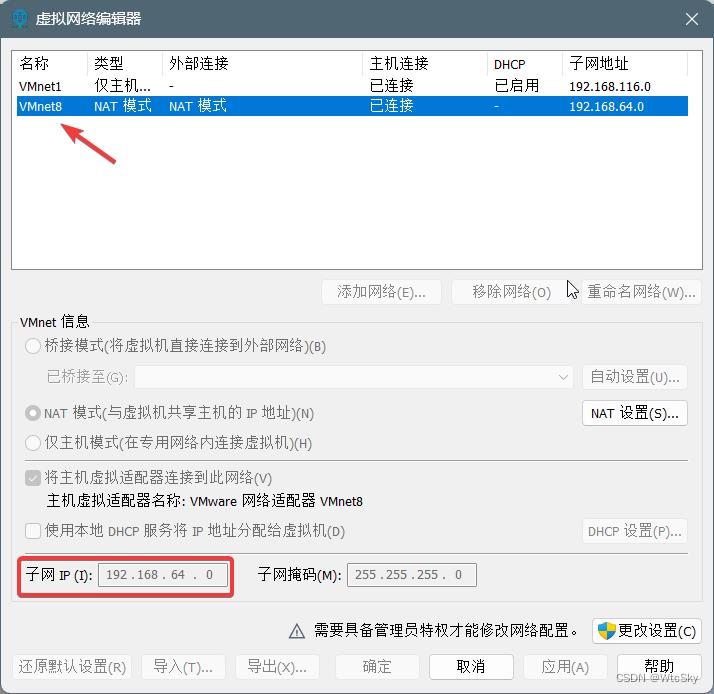
再点击一下NAT设置查看一下网关IP:

启动虚拟机,使用ROOT登录(未列出的->用户名root,密码123456)。
打开终端,输入vi /etc/sysconfig/network-scripts/ifcfg-ens33,复制命令,鼠标中键粘贴到终端。
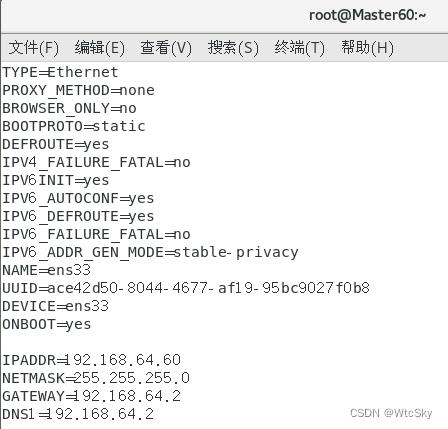
需要修改的是:BOOTPROTO=static、ONBOOT=yes。
在最后添加以下内容,我们之前得到的子网IP是192.168.64.0因此我们的IPADDR前三个字节需要相同,最后一个字节根据自己的学号修改。
GATEWAY与DNS1相同,都按照前面找到的网关IP填写。
IPADDR=192.168.64.60
NETMASK=255.255.255.0
GATEWAY=192.168.64.2
DNS1=192.168.64.2
然后ESC,:wq退出,不要少写了冒号!
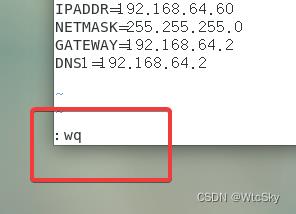
3.2 验证设置成功
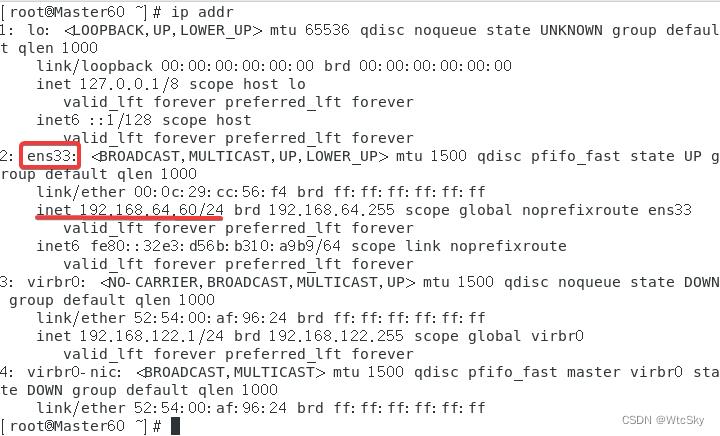
终端输入指令systemctl restart network(中间粘贴)
之后通过指令ip addr来查看,只要ens33出现了inet并且是自己的设置的IP就是成功了,如果没有,请对照3.1.1的注意事项查找错误。
用上面的方法完成Slave1和Slave2的IP设置,不再重复演示。
3.3 ★解决ens33没有成功设置IP
首先确保已经使用了systemctl restart network指令。
然后上面的一定严格按照给的写:字母写错、不是大写都有可能导致无法连接网络。大概率问题出在ens33的文件配置中。
如果之前已经设置成功并且显示,后续打开发现失效,可以参考5.3来解决。
4. 防火墙配置
实验文档只告诉一个防火墙配置,也不说配置什么,全是泛泛之谈!一百个字的实验文档轻飘飘的话,剩下全靠自己悟。
4.1 关闭防火墙
该操作需要重复三次(实验需要一个Master两个Slave……)
在终端使用指令依次使用下面两个指令:
systemctl stop firewalld关闭防火墙systemctl disable firewalld禁用防火墙(不再开机启动)
4.2 确认防火墙状态
在终端使用指令systemctl status firewalld查看防火墙状态,下图是已经关闭的状态:

没有关闭重启试试。
5. 虚拟机互联互通
该操作需要重复三次(实验需要一个Master两个Slave……)
5.1 添加映射
在终端使用指令vi /etc/hosts,将主机名与IP地址的映射关系存入。
如我的IP地址与主机名的对应关系是:
192.168.64.60 Master60
192.168.64.61 Slave1-60
192.168.64.62 Slave2-60
可以用#把前面两条注释掉,然后把自己的复制进去(鼠标中键),最后:wq保存,文档如下图所示:

5.2 互相ping验证连通性
首先确保三台虚拟机都已经完成了/etc/hosts的修改。
以Master(主机)为例,使用指令ping 192.168.64.61(IP以自己的从机IP为准),或者使用ping Slave2-60来检验是否连通(IP和主机名有映射关系了,所以ping IP和ping 主机名都可以)。
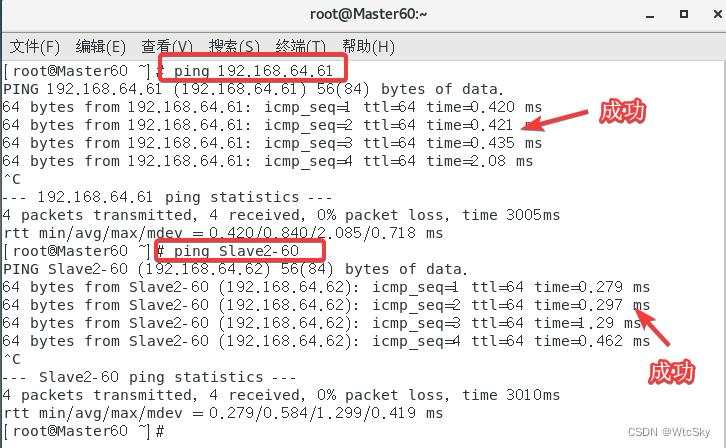
再分别从从机1和从机2去ping其他的两台机器,验证是否连通,过程是一样的只是把ip改一下,不再做演示。
5.3 ★解决IP失效(之前能联网现在不行了)
如果之前已经设置成功并且显示,后续打开发现失效可能是网卡出现问题了。
依次使用以下指令:
systemctl stop NetworkManagersystemctl disable NetworkManagersystemctl restart network
然后再通过ip addr查看是否成功(ens33显示IP)。
6. 虚拟机访问外网
该操作需要重复三次(实验需要一个Master两个Slave……)
6.1 方法一:ping百度
在终端通过ping baidu.com验证是否成功。
下面以主机为例:
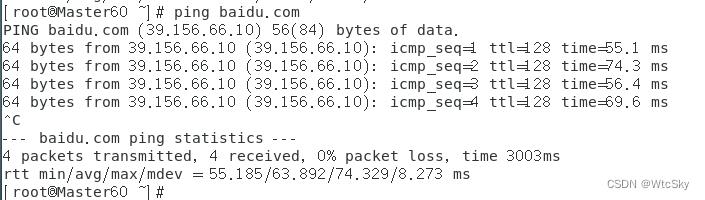
从机也需要验证,如果哪台机器ping不通请查看3.3以及5.3的解决方法或自行百度。
6.2 方法二:通过FireFox访问百度
这种方法需要再安装CentOS的时候选择了GUI界面(参考2.3)
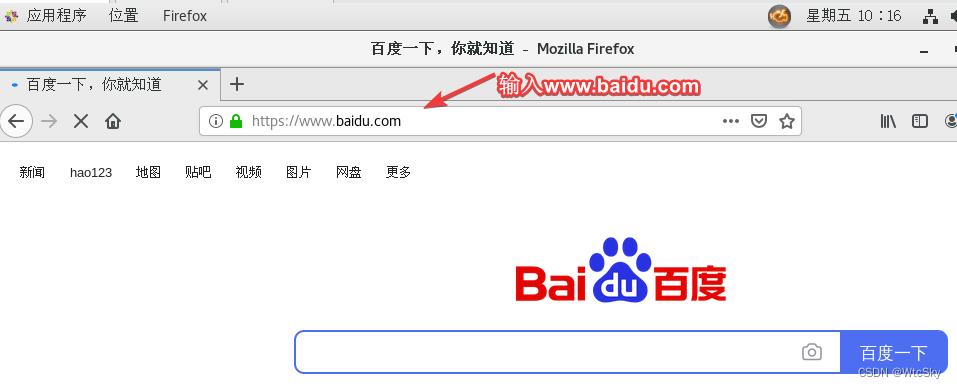
然后输入www.baidu.com,看是否能成功访问,以下是成功界面:
7. 免密安全登录
7.1 生成秘钥及分享秘钥
该操作需要重复三次(实验需要一个Master两个Slave……)
以主机为例,在终端依次使用以下指令:
ssh-keygen -t rsa(yes,然后一直回车)ssh-copy-id Slave1-60(Slave1-60修改为你的从机1的主机名或IP)ssh-copy-id Slave2-60(Slave1-60修改为你的从机2的主机名或IP)
步骤2、3需要输入密码(123456),密码不会显示(Linux特性)。
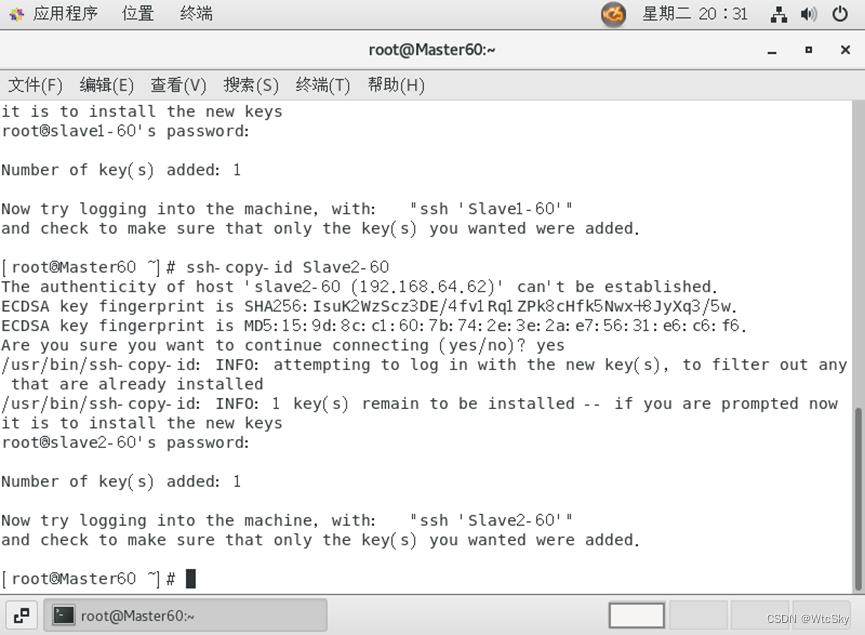
两个从机重复以上操作。
之后在**主机(Master)**进行如下操作(这一步从机不需要):
cd .ssh(目前所在路径是~)touch authorized_keyschmod 600 authorized_keyscat id_rsa.pub >> authorized_keys
这一步是为了之后做准备的……
7.2 测试是否成功
以从机1为例,在终端使用指令ssh Master60(改为自己主机的主机名)或者`ssh 192.168.64.610(改为自己主机的IP)。

可以发现此时不需要键入密码就可以登录。
8. Hadoop集群设计与部署
OK,这一步的难度大于前面七步的和,尽量说的详细一点。
该操作需要重复三次(实验需要一个Master两个Slave……)
8.1 下载Hadoop-3.3.1
我用的是Hadoop-3.3.1,下面的操作只要是Hadoop-3.x应该都是适用的,但是Hadoop-2.x可能有细枝末节的地方不太相同,建议看一下PushyTao学长的博客。
建议是在自己的电脑上而不是虚拟机上下载,因为每台虚拟机都需要一份,所以直接下在自己电脑桌面上然后拖到虚拟机里就可以了。
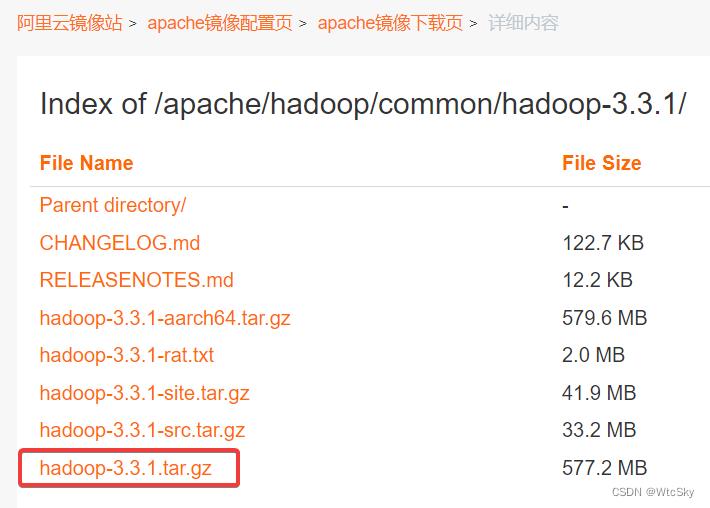
下面给出两个镜像站地址,哪个快下哪个吧:
以阿里云镜像站为例,要下载的是hadoop-3.3.1.tar.gz。
8.2 创建目录解压Hadoop
首先mkdir /user(现在的路径是~)
然后直接复制以下指令到终端(鼠标中键粘贴)
mkdir /user/hadoop
mkdir /user/hadoop/tmp
mkdir /user/hadoop/var
mkdir /user/hadoop/dfs
mkdir /user/hadoop/dfs/name
mkdir /user/hadoop/dfs/data
方便起见,后面的操作用GUI进行,点击应用程序,选择文件。

点击其他位置,然后选择计算机。
找到user文件夹点击进入,注意是user不是usr。

进入里面的hadoop目录,然后把电脑上的压缩包拖进来(下面的图是解压完成的)
然后在这个界面右键选择在终端打开。

这时候我终端的位置是这个目录:

然后输入指令tar -zxvf /usr/local/hadoop-3.3.1.tar.gz进行解压。
8.3 配置环境变量
在终端使用指令vi ~/.bashrc。
在最后键入i进行插入,需要修改的只有第一行HADOOP_INSTALL,把它改成自己Hadoop的位置就好了(含有bin、etc、……的目录)。
export HADOOP_INSTALL=/user/hadoop/hadoop-3.3.1
export PATH=$PATH:$HADOOP_INSTALL/bin
export PATH=$PATH:$HADOOP_INSTALL/sbin
export HADOOP_MAPRED_HOME=$HADOOP_INSTALL
export HADOOP_COMMON_HOME=$HADOOP_INSTALL
export HADOOP_HDFS_HOME=$HADOOP_INSTALL
export YARN_HOME=$HADOOP_INSTALL
export HADOOP_HOME=$HADOOP_INSTALL
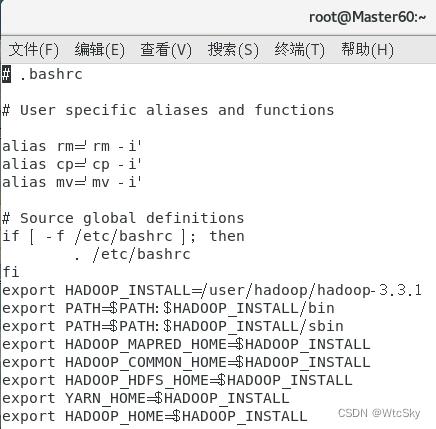
:wq保存退出。
然后在终端输入指令source ~/.bashrc
最后输入hdfs如果不是没有该指令就成功了。如果失败请看一下地址是否正确。
8.4 找到JDK位置
这个CentOS是自带了一个JDK确实是能用的,所以我也不另外下载了,找到这个JDK就可以了。
依次使用指令:
which java获得一个地址/usr/bin/javas -lrt /usr/bin/java,根据前面得到的地址修改,会获得另一个地址/etc/alternatives/javals -lrt /etc/alternatives/java,根据前面得到的地址修改,最终得到的就是jdk的位置。
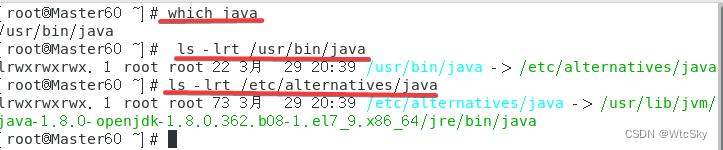
如果用的和我一样的系统,按理来说jdk的位置就是:java-1.8.0-openjdk-1.8.0.242.b08-1.el7.x86_64
上面显示0.362是因为后面的操作应该是有了一个新的版本但是为了还原,我还是说我的过程吧。
点进去这个这个目录,把里面jre的bin和lib给复制出来。
不搞出来之后会报错,JAVA_HOME需要这俩东西应该是,如果重新下jdk也差不多这么个意思。
8.5 修改主机配置文件
在做这一步之前先确保主机和两台从机都完成了以上操作,然后在主机上完成以下操作。
用GUI来完成吧,首先进入 /user/hadoop/hadoop-3.3.1/etc/hadoop/目录

这样的文件修改不同于VI而类似于windows系统的记事本。
复制粘贴都用鼠标就可以了。保存是ctrl+s。
8.5.1 hadoop-env.sh修改
打开hadoop-env.sh
在文件最后添加:
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.242.b08-1.el7.x86_64
export HADOOP_HOME=/user/hadoop/hadoop-3.3.1
export HDFS_NAMENODE_USER="root"
export HDFS_DATANODE_USER="root"
export HDFS_SECONDARYNAMENODE_USER="root"
export YARN_RESOURCEMANAGER_USER="root"
export YARN_NODEMANAGER_USER="root"
其中JAVA_HOME和HADOOP_HOME请根据自己情况来写。
8.5.2 core-site.xml修改
打开core-site.xml
在<configuration></configuration>之间输入下面的内容:
<property>
<name>hadoop.tmp.dir</name>
<value>/user/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.64.60:9000/</value>
</property>
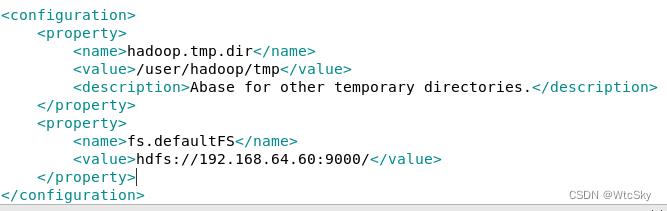
根据自己情况修改value标签内的内容。
8.5.3 hdfs-site.xml修改
打开hdfs-site.xml
在最后加入以下内容:
<configuration>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>192.168.64.60:9001</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/user/hadoop/dfs/name</value>
<description>Path on the local filesystem where theNameNode stores the namespace and transactions logs persistently.</description>
</property>
<property>
<name>dfs.data.dir</name>
<value>/user/hadoop/dfs/data</value>
<description>Comma separated list of paths on the localfilesystem of a DataNode where it should store its blocks.</description>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
<description>need not permissions</description>
</property>
</configuration>
上面内容提供了<configuration></configuration>,把之前的删了就好了。
还是把value标签自己改了。
8.5.4 yarn-site.xml修改
打开yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<description>The address of the applications manager interface in the RM.</description>
<name>yarn.resourcemanager.address</name>
<value>192.168.64.60:8032</value>
</property>
<property>
<description>The address of the scheduler interface.</description>
<name>yarn.resourcemanager.scheduler.address</name>
<value>192.168.64.60:8030</value>
</property>
<property>
<description>The http address of the RM web application.</description>
<name>yarn.resourcemanager.webapp.address</name>
<value>192.168.64.60:8088</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>192.168.64.60:8031</value>
</property>
<property>
<description>The address of the RM admin interface.</description>
<name>yarn.resourcemanager.admin.address</name>
<value>192.168.64.60:8033</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>2048</value>
<discription>every node memery size(MB) default is 8182MB</discription>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>
修改value的IP地址。
8.5.5 mapred-site.xml修改
打开mapred-site.xml
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>192.168.64.60:49001</value>
</property>
<property>
<name>mapred.local.dir</name>
<value>/user/hadoop/var</value>
</property>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
修改value中的ip及位置。
8.5.6 workers修改
打开workers
Slave1-60
Slave2-60
把两个从节点的主机名或者IP存进去。
8.6 分享主机配置文件
在/user/hadoop/hadoop-3.3.1/etc/hadoop/目录下打开终端。
之前已经设置了SSH免密登录,现在就派到用场了(当然这不是主要的),我可以直接把主机的文件分享到从机上。
直接复制以下指令到终端(鼠标中键),其中需要修改的是Slave1-60(改为自己的从机主机名或ip),后面的是存放在从机的地址(必须先在从机上完成8.1-8.4保证从机有这个目录)。
scp hadoop-env.sh root@Slave1-60:/user/hadoop/hadoop-3.3.1/etc/hadoop/
scp core-site.xml root@Slave1-60:/user/hadoop/hadoop-3.3.1/etc/hadoop/
scp hdfs-site.xml root@Slave1-60:/user/hadoop/hadoop-3.3.1/etc/hadoop/
scp mapred-site.xml root@Slave1-60:/user/hadoop/hadoop-3.3.1/etc/hadoop/
scp yarn-site.xml root@Slave1-60:/user/hadoop/hadoop-3.3.1/etc/hadoop/
scp workers root@Slave1-60:/user/hadoop/hadoop-3.3.1/etc/hadoop/
然后再传递给从机2一份:
scp hadoop-env.sh root@Slave2-60:/user/hadoop/hadoop-3.3.1/etc/hadoop/
scp core-site.xml root@Slave2-60:/user/hadoop/hadoop-3.3.1/etc/hadoop/
scp hdfs-site.xml root@Slave2-60:/user/hadoop/hadoop-3.3.1/etc/hadoop/
scp mapred-site.xml root@Slave2-60:/user/hadoop/hadoop-3.3.1/etc/hadoop/
scp yarn-site.xml root@Slave2-60:/user/hadoop/hadoop-3.3.1/etc/hadoop/
scp workers root@Slave2-60:/user/hadoop/hadoop-3.3.1/etc/hadoop/
8.7 格式化Hadoop
该操作需要重复三次(实验需要一个Master两个Slave……)
在各个节点使用终端输入指令hdfs namenode -format。
如果失败请查看自己的配置文件是否全部修改正确!Hadoop地址、JAVA_HOME之类的请仔细对照自己的实际情况!
如果成功,会出现以下界面:

所有的机器都完成了初始化之后进行下一步。
8.8 启动Hadoop
进入/user/hadoop/hadoop-3.3.1/sbin目录(如果自己能搞明白自己在什么目录完全可以自己掌控,以下的操作完全可以 在~路径下./user/hadoop/hadoop-3.3.1/sbin/start-all.sh)
在sbin目录下右键进入终端,使用指令./start-all.sh启动Hadoop
8.9 验证是否完成
在终端使用输入jps,如果显示bash: jps: command not found...,就使用指令yum install -y java-1.8.0-openjdk-devel。
如果在主机使用jps可以看到如下进程:
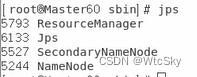
并且在两个从机使用jps可以看到如下进程:

就说明完成了任务。
8.10 浏览器查看集群
操作在主机上
此时通过浏览器访问192.168.64.60:9870来查看(主机的主机名或IP:9870)。

8.11 ★解决浏览器无法查看集群
可以尝试使用192.168.64.60:50070,Hadoop2.x使用的是50070端口。
如果还不行,看看防火墙是否关闭。一定是jps都显示上述的进程该网页才会生效。
8.12 ★虚拟机拖拽文件
需要安装VMware Tools,具体怎么做不多做说明,安装完成就能直接传输文件了。
往虚拟机中拖文件可能会报错,点一下重试就好了。
9. Eclipse访问Hadoop
9.1 下载Eclipse
在官网下载:Eclipse IDE for Java Developers,选择Linux x86_64。
这个只需要拖到主机Master上就可以了。
有了上面的经验,把这个压缩包拖到/opt目录下应该不成问题。
之后在/opt目录下打开终端,使用解压指令tar zxvf eclipse-java-2023-03-R-linux-gtk-x86_64.tar,这时候会有一个eclipse文件被解压到/opt。
点击(或者指令)进入/opt/eclipse,然后在该文件下打开终端,使用指令ln -s /opt/eclipse/eclipse /usr/bin/eclipse,此时再去/usr/bin目录下将eclipse拖到桌面即可。
现在直接点击eclipse就可以使用了。
9.2 配置eclipse
下载hadoop-eclipse-plugin-3.3.1,不需要解压放在eclipse路径下的dropins和plugins中。
打开eclipse,在菜单栏选择Window->Preferences。

然后在左侧选择Hadoop Map/Reduce,选择Hadoop的安装路径(按照自己的来)
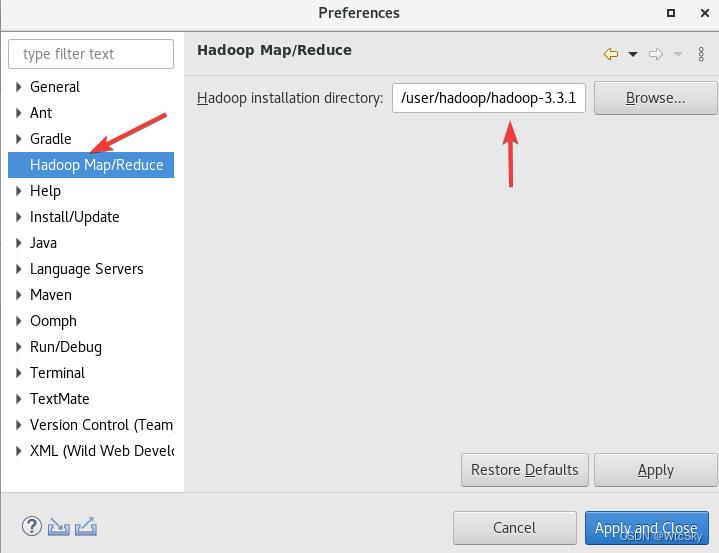
最后Apply and Close。
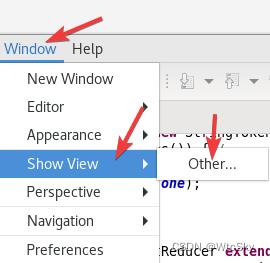
之后在菜单栏选择Window->Show View->Other。
选择MapReduce Tools->Map/Reduce Locations,点击Open
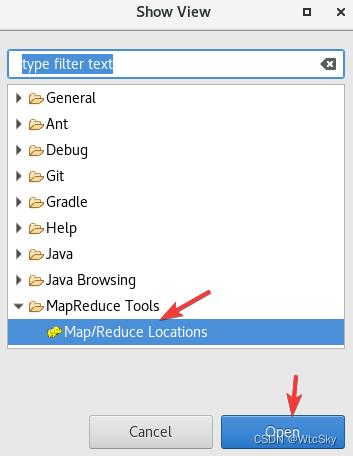
9.3 eclipse连接Hadoop
此时,会发现右上角出现大象(如果没有点击左侧第一个摁扭,里面可以打开),点击一下,下面会出现大象和+。

点击下面的大象和+
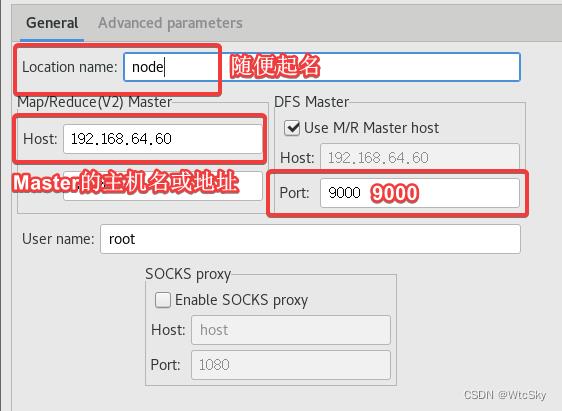
按照上图设置一下,点击Finish,下面会出现一条信息。

以及左侧项目栏会出一个DFS Locations
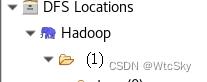
如果这里的Hadoop(刚才起的名字),点击可以显示文件夹,就说明连接成功反之会有一段错误代码。
9.4 ★解决eclipse连接Hadoop失败
确认每一台虚拟机都能上网,并且主机启动了start-all.sh。
不能上网请参考之前的内容。
10. MapReduce模型
10.1 在Hadoop集群创建文件
直接在主机终端使用指令
hadoop fs -mkdir /tmp
hadoop fs -chmod -R 777 /tmp
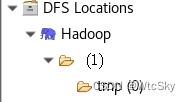
可以在eclipse中看到多出来的tmp目录。
10.2 创建Map/Reduce项目
新建一个项目
然后选择Map/Reduce Project,点击Next。

随便起名比如WORDCOUNT。
在src目录下直接创建一个Class类,类名是WordCount,弄个包也行无所谓。
然后把代码复制进去:
package wordcount;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount
public static class WordCountMapper extends Mapper<Object, Text, Text, IntWritable>
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) //
word.set(itr.nextToken());
context.write(word, one);
public static class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable>
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException
int sum = 0;
for (IntWritable val : values)
sum += val.get();
result.set(sum);
context.write(key, result);
public static void main(String[] args) throws Exception
Configuration conf = new Configuration();
if (args.length != 2)
System.err.println("Usage: <in> <out>");
System.exit(2);
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(WordCountMapper.class);
job.setCombinerClass(WordCountReducer.class);
job.setReducerClass(WordCountReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
如果连接成功了,那么上面的代码不会有错误,如果有错误一定是没有成功连接Hadoop。
下面是此时的状态
10.3 运行代码
这是一个命令行输入的代码,因此我们的先设置参数。
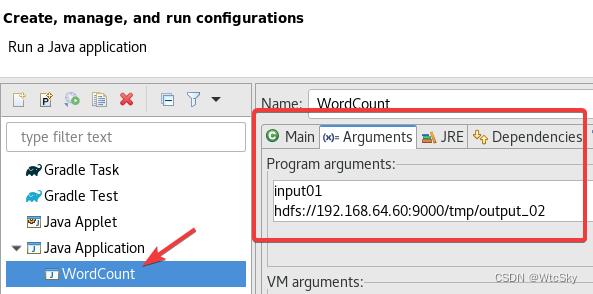
菜单上选择Run->Run Configurations...。

然后选择程序,在Arguments中输入参数:
第一个是input01,同时在项目下创建一个input01.txt来存输入,与src同级!注意是同级不是在src里。
第二个是hdfs://192.168.64.60:9000/tmp/output_01,这个要按照自己的Master的ip来设置,输出在/tmp/output_02文件里,这个文件会自动生成,并且如果已经存在了,就不能成功运行。
10.4 ★解决不能运行
如果java代码爆红,那是Hadoop没有连接成功,再看一下哪里没设置好。
如果说output文件已经存在,在命令行中换一个名字,或者删掉之前的文件。
如果是不影响运行的警告,可以右键src,选择New->Other->General->File。
文件名是:log4j.properties
文件内容是:
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
10.5 运行结果
我们的程序是计算单词出现了几次。
在input01文件中写入输入的内容。
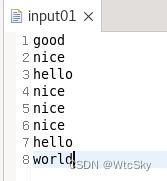
然后运行代码,右键刷新一下tmp目录
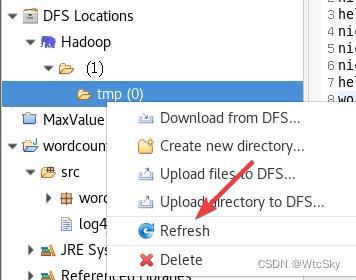
然后就会神奇的发现结果已经在目录里了。没有问题!

10.6 ★解决Map+Reduce方法二次编程
实际上就是上述代码的两个函数:
Mapper
public static class WordCountMapper extends Mapper<Object, Text, Text, IntWritable>
private final static IntWritable one = 云计算课程实验之安装Hadoop及配置伪分布式模式的Hadoop
0.环境
VMWare15 Pro、Ubuntu16.04、Hadoop3.2.1,伪分布式
1. VMware 15安装Ubuntu 16.04并配置环境
https://www.cnblogs.com/caoer/p/12669183.html
2. 创建hadoop用户
1)创建hadoop用户,并使用/bin/bash作为shell: sudo useradd -m hadoop -s /bin/bash
2) 为hadoop用户设置密码,之后需要连续输入两次密码: sudo passwd hadoop
3) 为hadoop用户增加管理员权限:sudo adduser hadoop sudo
4) 切换当前用户为用户hadoop: su – hadoop
5) 更新hadoop用户的apt: sudo apt-get update
3. JDK安装和Java环境变量配置
(1)安装 JDK 1.8
hadoop用户登陆,下载JDK安装包, 个人电脑系统选择对应版本,我选的是jdk-8u251-linux-x64.tar.gz,在文件下打开终端输入命令:
$ mkdir /usr/lib/jvm #创建jvm文件夹
$ sudo tar zxvf jdk-8u251-linux-x64.tar.gz -C /usr/lib/jvm #/ 解压到/usr/lib/jvm目录下
$ cd /usr/lib/jvm #进入该目录
$ mv jdk1.8.0_80 java #重命名为java
$ vi ~/.bashrc #给JDK配置环境变量
其中如果权限不够,无法在相关目录下创建jvm文件夹,那么可以使用 $ sudo -i 语句进入root账户来创建文件夹。
(2)Java环境变量配置
root用户登陆,命令行中执行命令”vi /etc/profile”,按I并加入以下内容,配置环境变量(注意/etc/profile这个文件很重要,后面Hadoop的配置还会用到)。
export JAVA_HOME=/usr/lib/jvm/java
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
保存并退出,执行以下命令使配置生效
$ source ~/.bashrc
$ java -version #检测是否安装成功,查看java版本
4. 配置所有节点之间SSH无密码验证
以节点A和B两个节点为例,节点A要实现无密码公钥认证连接到节点B上时,节点A是客户端,节点B是服务端,需要在客户端A上生成一个密钥对,包括一个公钥和一个私钥,而后将公钥复制到服务端B上。当客户端A通过ssh连接服务端B时,服务端B就会生成一个随机数并用客户端A的公钥对随机数进行加密,并发送给客户端A。客户端A收到加密数之后再用私钥进行解密,并将解密数回传给B,B确认解密数无误之后就允许A进行连接了。这就是一个公钥认证过程,其间不需要用户手工输入密码。重要过程是将客户端A公钥复制到B上。
因此如果要实现所有节点之间无密码公钥认证,则需要将所有节点的公钥都复制到所有节点上。
(1)安装ssh: sudo apt-get install openssh-server
登录ssh:ssh localhost
退出登录的ssh localhost:exit
(2)进入ssh目录:cd ~/.ssh/
(a)节点用hadoop用户登陆,并执行以下命令,生成rsa密钥对:
ssh-keygen -t rsa (回车后敲击三次回车)
这将在/home/hadoop/.ssh/目录下生成一个私钥id_rsa和一个公钥id_rsa.pub。
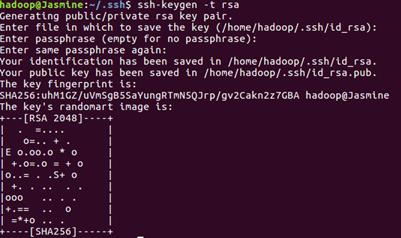
(c)加入授权:cat ./id_rsa.pub >> ./authorized_keys
这样配置过后SSH无密码登陆,可以通过命令“ssh localhost”来验证。
5. Hadoop集群配置
使用hadoop用户登陆,下载hadoop-3.2.1.tar.gz,将其解压到/usr/local/hadoop目录下: sudo tar -zxvf hadoop-2.6.0.tar.gz -C /usr/local,进入目录:cd /usr/local,重命名为hadoop: sudo mv hadoop-3.2.1 hadoop,修改文件权限:sudo chown -R hadoop ./hadoop。
给hadoop配置环境变量:
(1)打开bashrc文件:vi ~/.bashrc
(2)加入以下代码:
export HADOOP_HOME=/usr/local/hadoop
export CLASSPATH=$($HADOOP_HOME/bin/hadoop classpath):$CLASSPATH
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
(3)保存更改并生效:source ~/.bashrc。
$hadoop version 查看hadoop是否安装成功。
6. Hadoop集群启动
Hadoop 的配置文件位于 /usr/local/hadoop/etc/hadoop/ 中,伪分布式需要修改2个配置文件 core-site.xml 和 hdfs-site.xml 。Hadoop的配置文件是 xml 格式,每个配置以声明 property 的 name 和 value 的方式来实现。
a) 首先将jdk1.8的路径添(export JAVA_HOME=/usr/lib/jvm/java )加到hadoop-env.sh文件。
$ cd /usr/local/hadoop/etc/hadoop/
$ vim hadoop-env.sh
b) 修改core-site.xml:vim core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
c) 修改配置文件 hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
d) 配置完成后,执行 NameNode 的格式化
$ cd /usr/local/hadoop/
$ ./bin/hdfs namenode -format
e) 启动namenode和datanode进程,并查看启动结果
$ ./sbin/start-dfs.sh
$ jps
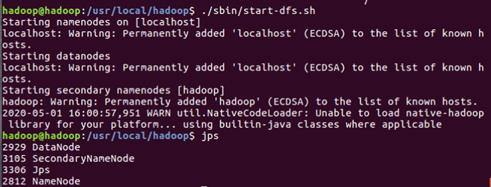
f) 成功启动后,可以访问 Web 界面 http://localhost:9870 查看 NameNode 和 Datanode 信息,还可以在线查看 HDFS 中的文件。
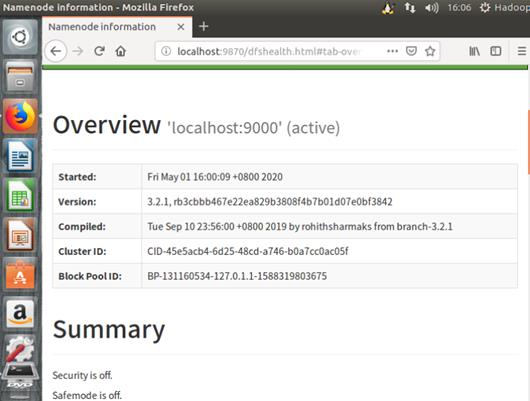
至此Hadoop安装就结束啦,以上为个人大数据学习成长历程~
以上是关于李老师云计算实验一:Hadoop伪分布式集群部署与Eclipse访问Hadoop进行单词计数统计的主要内容,如果未能解决你的问题,请参考以下文章