大数据项目组-月度考核汇报0102
Posted 延锋L
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据项目组-月度考核汇报0102相关的知识,希望对你有一定的参考价值。
目录
01-2023年02月-月度考核汇报
2月份完成项目情况
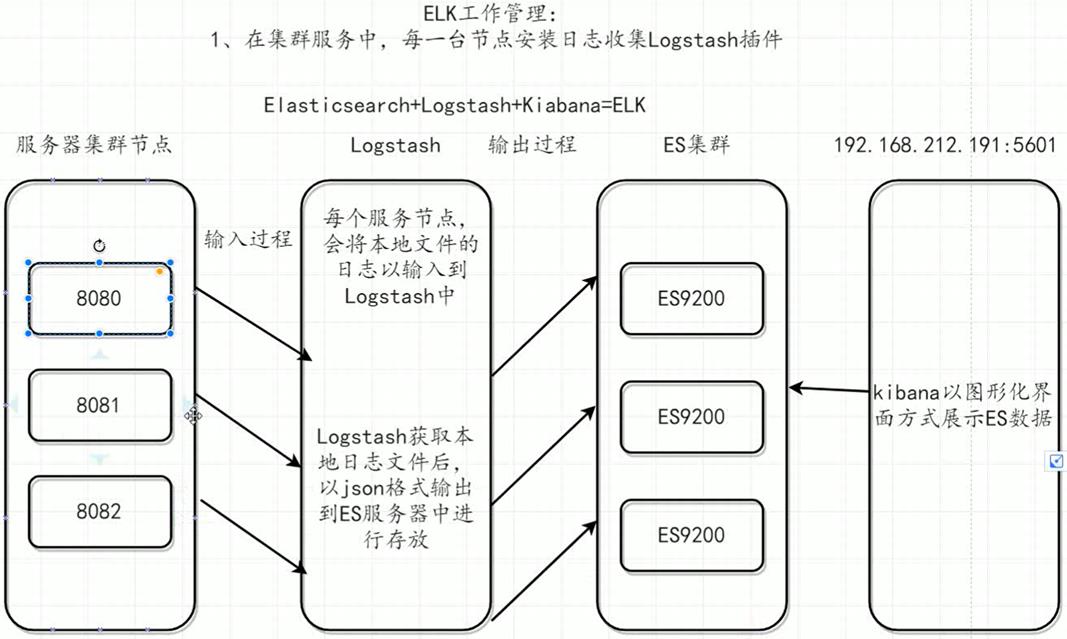
mysql数据同步到ElasticSearch任务进展(Windows系统):
通过logstash加载mysql.conf配置文件的方式实现了
在MySQL数据库进行增改后于一分钟内将数据状态同步至ES中。
2月份学习情况
本月主要学习了以下内容:
① ElasticSearch :索引库维护、集群、 Postman 工具的使用、 Java 客户端操作索引库、 SpringData 操作 ES 集群 ② Springboot+ElasticSearch 构建博客检索系统, logstash 与 kibana 的安装及使用。 ③ Hadoop : MapReduce 、 HDFS 、 Hive 、 FineBI 实现可视化报表。
3月份学习计划
本月计划学习以下内容:
① 主要学习内容 ① Logstash 实现 MySQL 与 ES 的数据同步,在 MySQL 数据库中进行增删改操作后,数据状态能够及时反馈至 ES 中; ② Logstash 获取 es 日志文件后,将数据以 json 格式输出到 es 中进行存放; ③ SpringData 操作 ElasticSearch ; ④ 在 linux 上部署 es 。 ② 次要学习内容 ① Apache Spark ,大数据快速计算引擎; ② SVN 、 Git 、 Docker ,项目版本管理工具、项目打包。
老师点评
无!
02-2023年03月-月度考核汇报
项目完成情况
Linux服务器中MySQL数据库数据同步ElasticSearch
① 安装线上运行版本的软件: jdk11 、 elk-8.5.1(es 、 logstash 、 kibana ) 、 node.js-14.21.3 、 esHead 插件; ② 连接线上测试数据库进行测试: 通过 logstash 加载配置文件的方式,将 MySQL 数据同步到 es 中,并在 kibana 中进行查看到了数据增改的同步效果; ③ 拍摄虚拟机快照保存虚拟机状态 ; ④ 详细记录 elk 安装过程及启动步骤 。
投入实际生产时可通过scp命令将本地生产环境拷贝至实际开发环境,为后续生产环境作准备。
本月学习内容
① Git ① Git 简介及安装使用; Git 连接远程仓库; Git 分支; ② Linux ① Windows 安装 Ubuntu 版本 Linux 系统; ② 复习 Linux 常用命令; ③ 复习 Linux 用户和权限知识点 ; ④ 复习 Linux 实用操作; ⑤ Linux 系统软件安装。 ③ Hadoop ① Hadoop 集群搭建, scp 命令、集群常用脚本。 ② Hadoop-HDFS ,客户端 API 。 ③ Hadoop-MapReduce , MR 序列化。 ④ Hadoop-Yarn ,生产环境核心参数配置、配置多队列的容量调度器。 ⑤ Hadoop- 生产调优手册, HDFS 集群压测。
① Git ① Git 简介及安装使用: 安装 Git 与 TortoiseGit ,测试本地仓库中文件的增删改; ② Git 连接远程仓库: GitHub 远程仓库、本地仓库推送至远程、克隆远程仓库; ③ Git 分支: 使用 Idea 使用 Idea 将工程添加到本地仓库、使用 Idea 克隆仓库并同步代码、在 Idea 中使用 git 的分支。 ② Linux ① Windows 安装 Ubuntu 版本 Linux 系统: 对比 Ubuntu 与 Cent OS 的差异; ② 复习 Linux 常用命令: ls 、 cd 、 pwd 、 mkdir 、 touch 、 cat 、 more 、 cp 、 mv 、 rm 、 which 、 find 、 grep 、 wc 、 echo 、 tail 、 vim 、 su 、 sudo 、 groupadd 、 useradd 、 usermod 、 userdel 、 getent 、 chmod 、 chown ; ③ 复习 Linux 用户和权限知识点: su 、 sudo 、 groupadd 、 useradd 、 usermod 、 userdel 、 getent 、 chmod 、 chown ; ④ 复习 Linux 实用操作: 软件安装方式、 systemctl 、端口、进程管理、环境变量; ⑤ Linux 系统软件安装: MySQL 、 Tomcat 、 nginx 、 RabbitMQ 、 Redis 、 ElasticSearch 。 ③ Hadoop ① Hadoop 集群搭建, scp 命令、集群常用脚本 ( xsync 文件分发、集群启停脚本、查看三台服务器 Java 进程脚本 ) 。 ② Hadoop-HDFS , shell 操作、客户端API( API创建文件夹: URI、Configuration、FileSystem )、core-site.xml 、 hdfs-site.xml 、 yarn-site.xml 、 mapred-site.xml 。 ③ Hadoop-MapReduce , MR 序列化 (Mapper 、 Reducer 和Driver)、在实体类中 实现序列化和反序列化方法 、数据压缩。 ④ Hadoop-Yarn , 查看日志及节点状态、生产环境核心参数配置、配置多队列的容量调度器。 ⑤ Hadoop- 生产调优手册, HDFS 核心参数、 HDFS 集群压测、 HDFS 多目录 。
下月学习计划
01、Hadoop
①复习hadoop中的重要知识点,重点复习HDFS、MapReduce、Yarn的使用。
②阅读书籍《 Hadoop权威指南_第四版_中文版》,以便对hadoop有更深的理解。
02、Spark(重点学习内容)
Spark是一种基于内存的快速、通用、可扩展的大数据分析计算引擎。学习spark教程,重点掌握以下内容:
①Spark Core:最基础与最核心的功能
②Spark SQL:操作结构化数据的组件。
③Spark Streaming:实时数据进行流式计算的组件。
④Spark Mllib:机器学习算法库。
⑤Spark GraphX:Spark 面向图计算提供的框架与算法库。
03、Flink(次要学习内容)
Apache Flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行状态计算。
①flink部署及架构;
②Data Stream API;
③flink处理函数。
04、kafka(次要学习内容)
Kafka是一个分布式的基于发布/订阅模式的消息队列,主要应用于大数据实时处理领域。
①生产者消费者模式实现;
②外部系统集成;
③生产调优方法。
老师点评
zyh老师:不局限于结构化数据,尝试流式数据等各种数据的同步。
hj老师:学习Flink cdc。
14月度考核
2、文件描述符与 struct file
每一个进程都有属于自己的一个PCB(进程控制块),在创建进程的时候,PCB 被创建,当进程终止的时候 ,PCB 也随着结束。这个 PCB 则都维护这一个文件描述符表,当 open 文件的时候,返回一个文件描述符,这个文件描述符是文件描述符表索引,也就是说,文件描述符表里面的一项执行了一个已经被打开的文件(struct file)。
当 open 一个文件的时候,系统会为每一个打开的文件在内核的空间关联的 struct file,它是由 内核打开文件的时候被创建,并将struct file 传给底层任何对文件进行操作的函数。当所有的操作实例结束之后,才会释放结构体。
所以,文件描述符是文件描述符表的索引,而文件描述符表的一项指向了打开 struct file,进一步说,文件描述符表中的指针,指向 file 结构体,也就是说,fd 是指向 这个 struct file 结构体。
struct file 结构体里面有 struct file_operations 结构体,他指向了底层驱动的函数实现。所以当对文件描述符 fd 做 read 、write 操作的时候,就会通过 struct file 里面 的 file_operations 的函数指向,去执行。
3、内核模块的再次学习
3.1、驱动编译过程分析
编译一个驱动:
Makefile:
LINUX_ROOT := /home/carlos/3516C/linux-3.0.y
obj-m := gpio.o
default:
make -C $(LINUX_ROOT) M=$(PWD) modules
clean:
make -C $(LINUX_ROOT) M=$(PWD) clean
3.1.1、编译步骤:
make -C /home/carlos/3516C/linux-3.0.y M=/home/carlos/3516C/driver/gpio_newBlue modules
make[1]: Entering directory `/home/carlos/3516C/linux-3.0.y‘ // 进入内核目录
CC [M] /home/carlos/3516C/driver/gpio_newBlue/gpio.o // 生成 gpio.o
Building modules, stage 2.
MODPOST 1 modules
CC /home/carlos/3516C/driver/gpio_newBlue/gpio.mod.o // 生成 gpio.mod.o
LD [M] /home/carlos/3516C/driver/gpio_newBlue/gpio.ko // 将 gpio.o 与 gpio.mod.o 连接,生成 gpio.ko
make[1]: Leaving directory `/home/carlos/3516C/linux-3.0.y‘编译的时候,是先进入内核目录,生成 gpio.o ,接着生成 gpio.mod.c ,根绝 gpio.mod.c 生成 gpio.mod.o,最后将 gpio.mod.o 与 gpio.o 两个文件连接起来,生成最终的 gpio.ko。
当编译完毕,生成的文件有:
基本的目标文件 + gpio.mod.c + gpio.mod.o + Module.symvers + modules.order 几个主要的目标文件。
(1) modules.order
modules.order : kernel//home/carlos/3516C/driver/gpio_newBlue/gpio.ko
目标文件,文件记载了,当前驱动的目标,最终生成了目标文件 gpio.ko
(2)gpio.mod.c + gpio.mod.o
gpio.mod.c : 是在编译的过程生成的文件。内容为:
MODULE_INFO(vermagic, VERMAGIC_STRING); // VERMAGIC_STRING
struct module __this_module
__attribute__((section(".gnu.linkonce.this_module"))) = {
.name = KBUILD_MODNAME,
.init = init_module,
#ifdef CONFIG_MODULE_UNLOAD
.exit = cleanup_module,
#endif
.arch = MODULE_ARCH_INIT,
};static const char __module_depends[]
__used
__attribute__((section(".modinfo"))) =
"depends="; // 没有依赖VERMAGIC_STRING 是内核的字符串信息,记载了内核的版本信息、gcc 版本、 SMP 等配置信息。当 gpio.mod.c 编译为 gpio.mod.o,可以去查看里面的内容:里面有一大部分是乱码,但是不是乱码的部分,则是非常重要的信息:
ELF depends=vermagic=3.0.8 mod_unload ARMv5 gpioGCC: (Hisilicon_v100(gcc4.4-290+uclibc_0.9.32.1+eabi+linuxpthread)) 4.4.1A,aeabi"
可见,可以从里面获得内核的版本为 3.0.8,编译器的版本为 Hisilicon_v100,进一步说,Hisilicon_v100 的编译器是由 4.4 的 gcc 和 uclibc_0.9.32.1 库、linuxpthread 库组成。
当我们使用 modinfo gpio.ko 的时候,就可以获得这些信息。
3.2、给驱动传参
驱动支持传参,当 insmod 的时候,就将参数传入。所以需要在驱动编写的时候,加入:
module_param(参数名, 参数类型, 参数权限);
如:
char *name = “abc”; // 指定默认参数
module_param(name, charp, 0644);
加载的时候,则 insmod xx.ko 参数名=参数值,
既:
insmod gpio.ko name=“AAA”
当没有输入参数的时候,则是使用默认的参数值。如果驱动已经被编译进内核的话,则可以在 uboot 的 bootargs 进行参数,格式为: 模块名.参数名=参数值。
当模块被 加载之后,会在 /sys/modules/ 下,有以模块名(gpio)同名的文件,而且传参的内容也会被打印到 log 里面:
cat /var/log/message
3.3、模块符号的导出
模块可以使用:
EXPORT_SYMBOL(符号名)
EXPORT_SYMBOL_GPL(符号名)
将一个模块内部的函数或者其它的进行到处,其他的模块可以进行调用。
比如:
int add_a_b(int a, int b)
{
return a + b;
}
EXPORT_SYMBOL(add_a_b);
当这个模块被编译的时候,模块导出来的符号信息到 Module.symvers 文件里面。
当加载模块之后,导出的符号,就可以在 /proc/kallsyms 里面找到,可以去 cat,里面记录的所有被到处的符号。
3.3.1、如何使用导出的符号
假如 a 模块被导出的符号,如何被 B 模块进行使用。显然 B 模块要调用 A 到处的符号,显然应该知道被到处符号的相关信息,比如地址信息等。 上面可以知道,模块 A 导出符号之后,到处符号的信息是被存储在,Module.symvers 里
$ cat Module.symvers
0x00000000 gpio_ioctl /home/carlos/3516C/driver/gpio_newBlue/gpio (unknown)Module.symvers 里面,指定了地址,模块的路径、导出的符号的相关信息。
方法一:
将 模块 A Module.symvers 的,复制到模块 B 的目录,这样模块 B 编译的时候,就可以通过 Module.symvers 里面的导出的符号信息找到导出的符号。
但是,要是每次都进行进行复制的动作,才可以引用别人的导出的符号的话,显然是非常的麻烦,所以一般是使用方法二。
方法二:
在内核编译的时候,和编译驱动模块一样,也是会生成 Module.symvers 目录,专门记录系统所以被到处的符号信息,Module.symvers 目录一般是在顶层目录,而且是可见的。所以,我们只需要将 模块 A 到处的符号,重定向到内核的 Module.symvers 文件就可以。
模块A 的Makefile:
LINUX_ROOT := /home/carlos/3516C/linux-3.0.y
obj-m := gpio.o
default:
make -C $(LINUX_ROOT) M=$(PWD) modules
arm-hisiv100nptl-linux-gcc gpiotest.c -o gpiotestcat Module.symvers >> /home/carlos/3516C/linux-3.0.y/Module.symvers // 导出符号到内核的总导出符号文件
clean:
rm -f gpiotest
make -C $(LINUX_ROOT) M=$(PWD) clean模块 A 完成正常编译的同时,将自身生成的 Module.symvers 文件的信息 ,重定向内核的总的 Module.symvers 文件。
模块 B 的调用:
extern int add_a_b(int a, int b);
模块 B 的Makefile:
按照正常 的 Makefile 就可以直接编译通过。因为模块 B 编译的时候,就会根据 –C ,跳转到内核里面去编译,可以获取内核提供接口、头文件的同时,还会获取内核的 Module.symvers 文件。
3.4、驱动模块的依赖
当模块使用 EXPORT_EXPORT 到处符号给别的模块使用,因此就存在了模块依赖的关系。
驱动模块的依赖,可以使用 depmod 用于分析驱动模块的依赖。depmod 命令,用于分析驱动模块的依赖关系,并将新的依赖关系保存到:
/lib/modules/3.19.0-15-generic/modules.dep 里面。
-a : 分析,显示所有的依赖关系,并将依赖写入 /lib/modules/3.19.0-15-generic/modules.dep 里面。
-n : 分析依赖,将依赖的信息,打印的输出界面,而不写入 /lib/modules/3.19.0-15-generic/modules.dep 里面。
(1)依赖加载的顺序
A 提供了符号给 B ,那么 B 依赖于 A。所以加载的时候,应该是将 A 先进行加载,之后再完成 B 的加载。
(2)卸载的顺序
B 卸载完成之后,在 A 完成卸载。
4、只 ls 目录文件
ls –l | grep ““^d”
因为目录文件的的“头” 都是以 d 开头。
5、精确定时
内核提供了较为精确的定时(但是本身的实现,是不准确的),ndelay(纳秒),mdelay(毫秒),但是,这些显得精准的延迟,在实际的情况就不是显得精准。原因是,调用了 udelay 或者 mdelay 的驱动线程和普通的用户线程是一样,也是受到进程调度。当驱动进程没有占用 CPU 的话,很可能会影响进程的调度,使得 CPU 在执行其他的线程,当再次调度回来的时候,时间的延迟,就不准确了。所以,如果想要精确定时的话,一般是是同硬件定时的方法实现。
6、获取进程可以打开文件的最大数目
一个进程打开文件的最大的数目是受限的,尝试去获取。
6.1、ulimit 指令
ulimit 指令可以去获取系统受限的资源限制情况:
$ ulimit -a
core file size (blocks, -c) 0
data seg size (kbytes, -d) unlimited // 进程最大数据段的大小,
scheduling priority (-e) 0
file size (blocks, -f) unlimited // 创建文件的大小,以块为单位
pending signals (-i) 123569
max locked memory (kbytes, -l) 32 // 最大可加锁内存
max memory size (kbytes, -m) unlimited // 最大内存
open files (-n) 1024 // 打开最大的文件描述符的数量
pipe size (512 bytes, -p) 8 // 管道的大小 518 * 8
POSIX message queues (bytes, -q) 819200
real-time priority (-r) 0
stack size (kbytes, -s) 10240 // 栈的大小
cpu time (seconds, -t) unlimited // 占用 CPU 时间
max user processes (-u) 123569 // 最 可用,用户最大线程
virtual memory (kbytes, -v) unlimited // 最大的虚拟内存
file locks (-x) unlimited因此,当我们需要获取限制的信息的时候,可以直接 ulimit –n 。不同的系统环境,给出的限制不一样,要根据自己的系统去获取。
修改 ulimit 指定的限制内容。
ulimit –n XXXXX
6.2、函数既:sysconf 去获取
sysconf - get configuration information at run time
SYNOPSIS
#include <unistd.h>long sysconf(int name);
name 的参数,根据指定, OPEN_MAX - _SC_OPEN_MAX,就 The maximum number of files that a process can have open at any time。
以上是关于大数据项目组-月度考核汇报0102的主要内容,如果未能解决你的问题,请参考以下文章