前端必学 - 大文件上传如何实现
Posted Never Yu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了前端必学 - 大文件上传如何实现相关的知识,希望对你有一定的参考价值。
前端必学 - 大文件上传如何实现
写在前面
1、正常的向后端发送请求,常见的 get、post 大家都很熟悉,是没有任何问题的;我们也可以用 post 或者表单请求发送 file文件 到后端。 但是大文件的上传是一个特殊的情况: 大文件上传最主要的问题就在于:在一个请求中,要上传大量的数据,导致整个过程会比较漫长,且失败后需要重头开始上传。
- 首先是上传过程时间比较久(要传输更多的报文,丢包重传的概率也更大),在这个过程中不能做其他操作,用户不能刷新页面,只能耐心等待请求完成。
- 常见的软件应用中,前端/后端都会对一个请求的时间进行限制,那么大文件的上传就会很容易超时,导致上传失败。
- 上传失败只能从头再来,你能接受吗?
2、面试/实际工作中,这也是一个常见的问题;所以,我们今天来彻底搞懂它。
问题分析
如果我们将这个文件拆分,将一次性上传大文件拆分成多个上传小文件的请求,因为请求是可以并发的,每个请求的时间就会缩短,且如果某个请求失败,只需要重新发送这一次请求即可,无需从头开始,这样不就可以解决大文件上传的问题了!
【明确目标】大文件上传需要实现下面几个需求:
- 支持拆分上传请求(即文件切片)
- 支持断点续传
- 支持显示上传进度和暂停上传
开始操作
一、文件如何切片
用户选择了一个大文件后,我们该如何处理它?
在 javascript 中,文件 File 对象是 Blob 对象的子类,Blob 对象包含一个重要的方法 slice,通过这个方法,我们就可以对二进制文件进行拆分。
// 生成文件切片
function createFileChunk(file, size = SIZE)
const fileChunkList = []
let cur = 0
while (cur < file.size)
fileChunkList.push(
file: file.slice(cur, cur + size),
)
cur += size
return fileChunkList
将文件拆分成 size 大小(可以是100k、500k、1M…)的分块,得到一个 file 的数组 fileChunkList,然后每次请求只需要上传这一个部分的分块即可。服务器接收到这些切片后,再将他们拼接起来就可以了。
二、得到原文件的hash值
拿到原文件的 hash 值是关键的一步,同一个文件就算改文件名,hash 值也不会变,就可以避免文件改名后重复上传的问题。
这里,我们使用 spark-md5.min.js 来根据文件的二进制内容计算文件的 hash。
说明:考虑到如果上传一个超大文件,读取文件内容计算 hash 是非常耗费时间的,并且会引起 UI 的阻塞,导致页面假死状态,所以我们使用 web-worker 在 worker 线程计算 hash,这样用户仍可以在主界面正常的交互。
由于实例化 web-worker 时,参数是一个 js 文件路径且不能跨域,所以我们单独创建一个 hash.js 文件放在 public 目录下,另外在 worker 中也是不允许访问 dom 的,但它提供了importScripts 函数用于导入外部脚本,通过它导入 spark-md5。
计算 hash 代码如下:
// public/hash.js
self.onmessage = e =>
const fileChunkList = e.data
const spark = new self.SparkMD5.ArrayBuffer()
let percentage = 0
let count = 0
const loadNext = index =>
const reader = new FileReader()
reader.readAsArrayBuffer(fileChunkList[index].file)
reader.onload = e =>
count++
spark.append(e.target.result)
if (count === fileChunkList.length)
self.postMessage(
percentage: 100,
hash: spark.end()
)
self.close()
else
percentage += 100 / fileChunkList.length
self.postMessage(
percentage
)
loadNext(count)
loadNext(count)
我们传入切片后的 fileChunkList,利用 FileReader 读取每个切片的 ArrayBuffer 并不断传入 spark-md5 中,每计算完一个切片通过 postMessage 向主线程发送一个进度事件,全部完成后将最终的 hash 发送给主线程。
【重要说明】
spark-md5需要根据所有切片才能算出一个hash值,不能直接将整个文件放入计算,否则即使不同文件也会有相同的hash,具体可以看官方文档 spark-md5。
三、文件上传
1)验证文件是否已经在服务端存在,如果存在,那就不用上传了,相当于秒传成功。
/**
* 返回值说明
* shouldUpload:标识这个文件是否还需要上传
* uploadedList: 服务端存在该文件的切片List
*/
const shouldUpload, uploadedList = await verifyUpload(
container.file.name,
container.hash
)
如果 shouldUpload 为 false,则表明这个文件不需要上传,提示:秒传成功。
2)然后上传除了 uploadedList 之外的文件切片。
/**
* 上传切片,同时过滤已上传的切片
* uploadedList:已经上传了的切片,这次不用上传了
*/
async function uploadChunks(uploadedList = [])
console.log(uploadedList, 'uploadedList')
const requestList = data.value
.filter(( hash ) => !uploadedList.includes(hash))
.map(( chunk, hash, index ) =>
const formData = new FormData()
// 切片文件
formData.append('chunk', chunk)
// 切片文件hash
formData.append('hash', hash)
// 大文件的文件名
formData.append('filename', container.file.name)
// 大文件hash
formData.append('fileHash', container.hash)
return formData, index
)
.map(async ( formData, index ) =>
request(
url: 'http://localhost:9999',
data: formData,
onProgress: createProgressHandler(index, data.value[index]),
requestList: requestListArr.value,
)
)
// 并发切片
await Promise.all(requestList)
// 之前上传的切片数量 + 本次上传的切片数量 = 所有切片数量时
// 切片并发上传完以后,发个请求告诉后端:合并切片
if (uploadedList.length + requestList.length === data.value.length)
// ok,都上传完了,请求合并文件
mergeRequest()
四、文件合并
文件合并方案有这么几种。
1、前端发送切片完成后,发送一个合并请求,后端收到请求后,将之前上传的切片文件合并。
2、后台记录切片文件上传数据,当后台检测到切片上传完成后,自动完成合并。
3、创建一个和源文件大小相同的文件,根据切片文件的起止位置直接将切片写入对应位置。
我们这里采用的是第一种方案。
下面以用 node.js 的实现为例:
/**
* 合并文件夹中的切片,生成一个完整的文件
* @Author Author
* @DateTime 2021-12-30T17:41:19+0800
* @param [string] filePath [完整的文件路径(最终文件切片合并为一个完整的文件)]
* @param [type] fileHash [大文件的文件名]
* @param [type] size [单个切片的大小]
* @return [type] [description]
*/
const mergeFileChunk = async (filePath, fileHash, size) =>
// 所有的文件切片放在以“大文件的文件hash命名文件夹”中
const chunkDir = path.resolve(UPLOAD_DIR, fileHash)
const chunkPaths = await fse.readdir(chunkDir)
// 根据切片下标进行排序
// 否则直接读取目录的获得的顺序可能会错乱
chunkPaths.sort((a, b) =>
return a.split('-')[1] - b.split('-')[1]
)
await Promise.all(
chunkPaths.map((chunkPath, index) =>
return pipeStream(
path.resolve(chunkDir, chunkPath),
/**
* 创建写入的目标文件的流,并指定位置,
* 目的是能够并发合并多个可读流到可写流中,这样即使流的顺序不同也能传输到正确的位置,
* 所以这里还需要让前端在请求的时候多提供一个 size 参数。
* 其实也可以等上一个切片合并完后再合并下个切片,这样就不需要指定位置,
* 但传输速度会降低,所以使用了并发合并的手段,
*/
fse.createWriteStream(filePath,
start: index * size,
end: (index + 1) * size
)
)
)
)
// 文件合并后删除保存切片的目录
fse.rmdirSync(chunkDir)
服务端根据文件标识,分片顺序进行合并,合并完以后删除分片文件。
技术点总结【重要】
一、上传文件?
我们都知道如果要上传一个文件,需要把 form 标签的 enctype 设置为 multipart/form-data,同时method 必须为 post 方法。(这是最原始的方式)
那么 multipart/form-data 表示什么呢?
multipart 互联网上的混合资源,就是资源由多种元素组成,form-data 表示可以使用 html Forms 和 POST 方法上传文件,具体的定义可以参考 RFC 7578。
但是现在,我们很少使用这种 form 的方式了,我们都是直接使用 XMLHttpRequest 来发送 Ajax 请求。
最开始 XMLHttpRequest 是不支持传输二进制文件的。文件只能使用表单的方式上传,我们需要写一个 Form,然后将 enctype 设置为 multipart/form-data。
后来 XMLHttpRequest 升级为 Level 2 之后,新增了 FormData 对象,用于模拟表单数据,并且支持发送和接收二进制数据。我们目前使用的文件上传基本都是基于 XMLHttpRequest Level 2。
xhr.send(data) 中 data 参数的数据类型会影响请求头部 content-type 的值。我们上传文件,data 的类型是 FormData,此时 content-type 默认值为 multipart/form-data;在上传文件场景下,不必设置 content-type 的值,浏览器会根据文件类型自动配置
二、显示进度
我们可以通过 onprogress 事件来实时显示进度,默认情况下这个事件每 50ms 触发一次。需要注意的是,上传过程和下载过程触发的是不同对象的 onprogress 事件:上传触发的是 xhr.upload 对象的 onprogress 事件,下载触发的是 xhr 对象的 onprogress 事件。
xhr.onprogress = updateProgress;
xhr.upload.onprogress = updateProgress;
function updateProgress(event)
if (event.lengthComputable)
var completedPercent = event.loaded / event.total;
PS 特别提醒:
xhr.upload.onprogress要写在xhr.send方法前面。
三、暂停上传
一个请求能被取消的前提是,我们需要将未收到响应的请求保存在一个列表中,然后依次调用每个 xhr 对象的 abort 方法。调用这个方法后,xhr 对象会停止触发事件,将请求的 status 置为 0,并且无法访问任何与响应有关的属性。
/**
* 暂停
*/
function handlePause()
requestListArr.value.forEach((xhr) => xhr?.abort())
requestListArr.value = []
从后端的角度看,一个上传请求被取消,意味着当前浏览器不会再向后端传输数据流,后端此时会报错,如下,错误信息也很清楚,就是文件还没到末尾就被客户端中断。当前文件切片写入失败。
四、Hash有优化空间吗?
计算 hash 耗时的问题,不仅可以通过 web-workder,还可以参考 React 的 FFiber 架构,通过 requestIdleCallback 来利用浏览器的空闲时间计算,也不会卡死主线程;
如果觉得文件计算全量 Hash 比较慢的话,还有一种方式就是计算抽样 Hash,减少计算的字节数可以大幅度减少耗时;
在前文的代码中,我们是将大文件切片后,全量传入 spark-md5.min.js 中来根据文件的二进制内容计算文件的 hash 的。
那么,举个例子,我们可以这样优化: 文件切片以后,取第一个和最后一个切片全部内容,其他切片的取 首中尾 三个地方各2各字节来计算 hash。这样来计算文件 hash 会快很多。
五、限制请求个数
解决了大文件计算 hash 的时间优化问题;下一个问题是:如果一个大文件切了成百上千来个切片,一次发几百个 http 请求,容易把浏览器搞崩溃。那么就需要控制并发,也就是限制请求个数。
思路就是我们把异步请求放在一个队列里,比如并发数是4,就先同时发起4个请求,然后有请求结束了,再发起下一个请求即可。
我们通过并发数 max 来管理并发数,发起一个请求 max--,结束一个请求 max++ 即可。
【预留】
六、拥塞控制,动态计算文件切片大小
【预留】
演示&源码
源代码:https://github.com/Neveryu/bigfile-upload
源代码:https://github.com/Neveryu/bigfile-upload
—————————— 【正文完】——————————
前端学习交流群,想进来面基的,可以加群: 685486827,832485817;

写在最后: 约定优于配置 —— 软件开发的简约原则
——————————【完】——————————
我的:
个人网站: https://neveryu.github.io/neveryu/
Github: https://github.com/Neveryu
新浪微博: https://weibo.com/Neveryu
微信: miracle421354532
更多学习资源请关注我的新浪微博…好吗
前端实现大文件上传
文件夹数据库处理逻辑
public class DbFolder
{
JSONObject root;
public DbFolder()
{
this.root = new JSONObject();
this.root.put("f_id", "");
this.root.put("f_nameLoc", "根目录");
this.root.put("f_pid", "");
this.root.put("f_pidRoot", "");
}
/**
* 将JSONArray转换成map
* @param folders
* @return
*/
public Map<String, JSONObject> toDic(JSONArray folders)
{
Map<String, JSONObject> dt = new HashMap<String, JSONObject>();
for(int i = 0 , l = folders.size();i<l;++i)
{
JSONObject o = folders.getJSONObject(i);
String id = o.getString("f_id");
dt.put(id, o);
}
return dt;
}
public Map<String, JSONObject> foldersToDic(String pidRoot)
{
//默认加载根目录
String sql = String.format("select f_id,f_nameLoc,f_pid,f_pidRoot from up6_folders where f_pidRoot=‘%s‘", pidRoot);
SqlExec se = new SqlExec();
JSONArray folders = se.exec("up6_folders", sql, "f_id,f_nameLoc,f_pid,f_pidRoot","");
return this.toDic(folders);
}
public ArrayList<JSONObject> sortByPid( Map<String, JSONObject> dt, String idCur, ArrayList<JSONObject> psort) {
String cur = idCur;
while (true)
{
//key不存在
if (!dt.containsKey(cur)) break;
JSONObject d = dt.get(cur);//查父ID
psort.add(0, d);//将父节点排在前面
cur = d.getString("f_pid").trim();//取父级ID
if (cur.trim() == "0") break;
if ( StringUtils.isBlank(cur) ) break;
}
return psort;
}
public JSONArray build_path_by_id(JSONObject fdCur) {
String id = fdCur.getString("f_id").trim();//
String pidRoot = fdCur.getString("f_pidRoot").trim();//
//根目录
ArrayList<JSONObject> psort = new ArrayList<JSONObject>();
if (StringUtils.isBlank(id))
{
psort.add(0, this.root);
return JSONArray.fromObject(psort);
}
//构建目录映射表(id,folder)
Map<String, JSONObject> dt = this.foldersToDic(pidRoot);
//按层级顺序排列目录
psort = this.sortByPid(dt, id, psort);
SqlExec se = new SqlExec();
//是子目录->添加根目录
if (!StringUtils.isBlank(pidRoot))
{
JSONObject root = se.read("up6_files"
, "f_id,f_nameLoc,f_pid,f_pidRoot"
, new SqlParam[] { new SqlParam("f_id", pidRoot) });
psort.add(0, root);
}//是根目录->添加根目录
else if (!StringUtils.isBlank(id) && StringUtils.isBlank(pidRoot))
{
JSONObject root = se.read("up6_files"
, "f_id,f_nameLoc,f_pid,f_pidRoot"
, new SqlParam[] { new SqlParam("f_id", id) });
psort.add(0, root);
}
psort.add(0, this.root);
return JSONArray.fromObject(psort);
}
public FileInf read(String id) {
SqlExec se = new SqlExec();
String sql = String.format("select f_pid,f_pidRoot,f_pathSvr from up6_files where f_id=‘%s‘ union select f_pid,f_pidRoot,f_pathSvr from up6_folders where f_id=‘%s‘", id,id);
JSONArray data = se.exec("up6_files", sql, "f_pid,f_pidRoot,f_pathSvr","");
JSONObject o = (JSONObject)data.get(0);
FileInf file = new FileInf();
file.id = id;
file.pid = o.getString("f_pid").trim();
file.pidRoot = o.getString("f_pidRoot").trim();
file.pathSvr = o.getString("f_pathSvr").trim();
return file;
}
public Boolean exist_same_file(String name,String pid)
{
SqlWhereMerge swm = new SqlWhereMerge();
swm.equal("f_nameLoc", name.trim());
swm.equal("f_pid", pid.trim());
swm.equal("f_deleted", 0);
String sql = String.format("select f_id from up6_files where %s ", swm.to_sql());
SqlExec se = new SqlExec();
JSONArray arr = se.exec("up6_files", sql, "f_id", "");
return arr.size() > 0;
}
/**
* 检查是否存在同名目录
* @param name
* @param pid
* @return
*/
public Boolean exist_same_folder(String name,String pid)
{
SqlWhereMerge swm = new SqlWhereMerge();
swm.equal("f_nameLoc", name.trim());
swm.equal("f_deleted", 0);
swm.equal("LTRIM (f_pid)", pid.trim());
String where = swm.to_sql();
String sql = String.format("(select f_id from up6_files where %s ) union (select f_id from up6_folders where %s)", where,where);
SqlExec se = new SqlExec();
JSONArray fid = se.exec("up6_files", sql, "f_id", "");
return fid.size() > 0;
}
public Boolean rename_file_check(String newName,String pid)
{
SqlExec se = new SqlExec();
JSONArray res = se.select("up6_files"
, "f_id"
,new SqlParam[] {
new SqlParam("f_nameLoc",newName)
,new SqlParam("f_pid",pid)
},"");
return res.size() > 0;
}
public Boolean rename_folder_check(String newName, String pid)
{
SqlExec se = new SqlExec();
JSONArray res = se.select("up6_folders"
, "f_id"
, new SqlParam[] {
new SqlParam("f_nameLoc",newName)
,new SqlParam("f_pid",pid)
},"");
return res.size() > 0;
}
public void rename_file(String name,String id) {
SqlExec se = new SqlExec();
se.update("up6_files"
, new SqlParam[] { new SqlParam("f_nameLoc", name) }
, new SqlParam[] { new SqlParam("f_id", id) });
}
public void rename_folder(String name, String id, String pid) {
SqlExec se = new SqlExec();
se.update("up6_folders"
, new SqlParam[] { new SqlParam("f_nameLoc", name) }
, new SqlParam[] { new SqlParam("f_id", id) });
}
}
1.在webuploader.js大概4880行代码左右,在动态生成的input组件的下面(也可以直接搜索input),增加webkitdirectory属性。
function FileUploader(fileLoc, mgr)
{
var _this = this;
this.id = fileLoc.id;
this.ui = { msg: null, process: null, percent: null, btn: { del: null, cancel: null,post:null,stop:null }, div: null};
this.isFolder = false; //不是文件夹
this.app = mgr.app;
this.Manager = mgr; //上传管理器指针
this.event = mgr.event;
this.Config = mgr.Config;
this.fields = jQuery.extend({}, mgr.Config.Fields, fileLoc.fields);//每一个对象自带一个fields幅本
this.State = this.Config.state.None;
this.uid = this.fields.uid;
this.fileSvr = {
pid: ""
, id: ""
, pidRoot: ""
, f_fdTask: false
, f_fdChild: false
, uid: 0
, nameLoc: ""
, nameSvr: ""
, pathLoc: ""
, pathSvr: ""
, pathRel: ""
, md5: ""
, lenLoc: "0"
, sizeLoc: ""
, FilePos: "0"
, lenSvr: "0"
, perSvr: "0%"
, complete: false
, deleted: false
};//json obj,服务器文件信息
this.fileSvr = jQuery.extend(this.fileSvr, fileLoc);
2.可以获取路径
this.open_files = function (json)
{
for (var i = 0, l = json.files.length; i < l; ++i)
{
this.addFileLoc(json.files[i]);
}
setTimeout(function () { _this.PostFirst(); },500);
};
this.open_folders = function (json)
{
for (var i = 0, l = json.folders.length; i < l; ++i) {
this.addFolderLoc(json.folders[i]);
}
setTimeout(function () { _this.PostFirst(); }, 500);
};
this.paste_files = function (json)
{
for (var i = 0, l = json.files.length; i < l; ++i)
{
this.addFileLoc(json.files[i]);
}
};
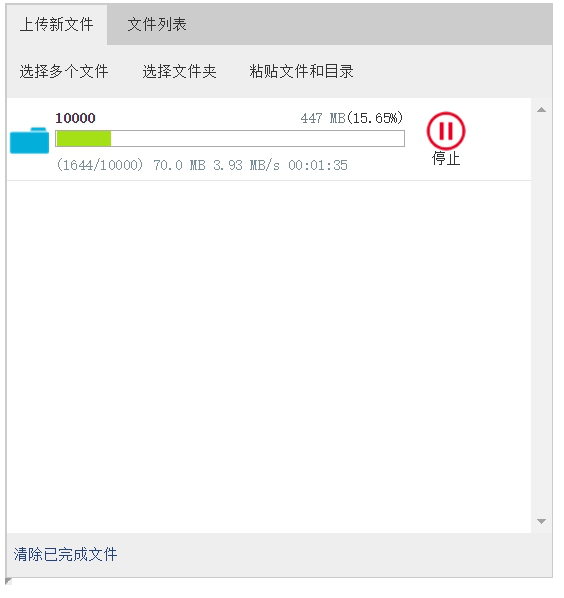
后端代码逻辑大部分是相同的,目前能够支持MySQL,Oracle,SQL。在使用前需要配置一下数据库,可以参考我写的这篇文章:http://blog.ncmem.com/wordpress/2019/08/07/java超大文件上传与下载/
可以入群一起讨论:374992201
以上是关于前端必学 - 大文件上传如何实现的主要内容,如果未能解决你的问题,请参考以下文章