550Elasticsearch详细入门教程系列 -分布式全文搜索引擎 Elasticsearch 2023.03.31
Posted youyouwuxin1234
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了550Elasticsearch详细入门教程系列 -分布式全文搜索引擎 Elasticsearch 2023.03.31相关的知识,希望对你有一定的参考价值。
目录
一、Elasticsearch简介&安装
1.1、Elasticsearch是什么?
The Elastic Stack, 包括 Elasticsearch、Kibana、Beats 和 Logstash(也称为 ELK Stack)。能够安全可靠地获取任何来源、任何格式的数据,然后实时地对数据进行搜索、分析和可视化。Elaticsearch,简称为 ES, ES 是一个开源的高扩展的分布式全文搜索引擎,是整个 Elastic Stack 技术栈的核心。它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理 PB 级别的数据。
1.2、全文搜索引擎
Google,百度类的网站搜索,它们都是根据网页中的关键字生成索引,我们在搜索的时候输入关键字,它们会将该关键字即索引匹配到的所有网页返回;还有常见的项目中应用日志的搜索等等。对于这些非结构化的数据文本,关系型数据库搜索不是能很好的支持。一般传统数据库,全文检索都实现的很鸡肋,因为一般也没人用数据库存文本字段。进行全文检索需要扫描整个表,如果数据量大的话即使对 SQL 的语法优化,也收效甚微。建立了索引,但是维护起来也很麻烦,对于 insert 和 update 操作都会重新构建索引。基于以上原因可以分析得出,在一些生产环境中,使用常规的搜索方式,性能是非常差的:
搜索的数据对象是大量的非结构化的文本数据。
文件记录量达到数十万或数百万个甚至更多。
支持大量基于交互式文本的查询。
需求非常灵活的全文搜索查询。
对高度相关的搜索结果的有特殊需求,但是没有可用的关系数据库可以满足。
对不同记录类型、非文本数据操作或安全事务处理的需求相对较少的情况。
为了解决结构化数据搜索和非结构化数据搜索性能问题,我们就需要专业,健壮,强大的全文搜索引擎。这里说到的全文搜索引擎指的是目前广泛应用的主流搜索引擎。它的工作原理是计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式。这个过程类似于通过字典中的检索字表查字的过程。
1.3、Elasticsearch的应用案例
GitHub: 2013 年初,抛弃了 Solr,采取 Elasticsearch 来做 PB 级的搜索。“GitHub 使用Elasticsearch 搜索 20TB 的数据,包括 13 亿文件和 1300 亿行代码”。
维基百科:启动以 Elasticsearch 为基础的核心搜索架构
SoundCloud:“SoundCloud 使用 Elasticsearch 为 1.8 亿用户提供即时而精准的音乐搜索服务”。
百度:目前广泛使用 Elasticsearch 作为文本数据分析,采集百度所有服务器上的各类指标数据及用户自定义数据,通过对各种数据进行多维分析展示,辅助定位分析实例异常或业务层面异常。目前覆盖百度内部 20 多个业务线(包括云分析、网盟、预测、文库、直达号、钱包、风控等),单集群最大 100 台机器,200 个 ES 节点,每天导入 30TB+ 数据。
新浪:使用 Elasticsearch 分析处理 32 亿条实时日志。
阿里:使用 Elasticsearch 构建日志采集和分析体系。
Stack Overflow:解决 Bug 问题的网站,全英文,编程人员交流的网站。
1.4、Elasticsearch的下载、安装、运行
Download Elasticsearch Free | Get Started Now | Elastic | Elastic
Elasticsearch 的官方地址:https://www.elastic.co/cn/
下载地址:https://www.elastic.co/cn/downloads/past-releases#elasticsearch
Elasticsearch 分为 Linux 和 Windows
版本,未来在企业里肯定是要用linux版本的,并且还要搭建集群。那么这里我学习ES为了方便、快速掌握,就采用windows版本了。下载完成之后,是一个压缩包,直接解压就可以了。

bin 可执行脚本目录
config 配置目录
jdk 内置 JDK 目录(ES是采用Java语言开发的)
lib 类库
logs 日志目录
modules 模块目录
plugins 插件目录
解压后,进入 bin 文件目录,点击 elasticsearch.bat 文件启动 ES 服务。
注意:9300 端口为 Elasticsearch 集群间组件的通信端口,9200 端口为浏览器访问的 http 协议的 RESTful 端口。
1.5、有关restful
REST 指的是一组架构约束条件和原则。满足这些约束条件和原则的应用程序或设计就是 RESTful。Web 应用程序最重要的 REST
原则是,客户端和服务器之间的交互在请求之间是无状态的。从客户端到服务器的每个请求都必须包含理解请求所必需的信息。如果服务器在请求之间的任何时间点重启,客户端不会得到通知。此外,无状态请求可以由任何可用服务器回答,这十分适合云计算之类的环境。客户端可以缓存数据以改进性能。在服务器端,应用程序状态和功能可以分为各种资源。资源是一个有趣的概念实体,它向客户端公开。资源的例子有:应用程序对象、数据库记录、算法等等。每个资源都使用
URI(Universal Resource Identifier)
得到一个唯一的地址。所有资源都共享统一的接口,以便在客户端和服务器之间传输状态。使用的是标准的 HTTP 方法,比如
GET、PUT、POST 和 DELETE。在 REST 样式的 Web
服务中,每个资源都有一个地址。资源本身都是方法调用的目标,方法列表对所有资源都是一样的。这些方法都是标准方法,包括 HTTP
GET、POST、PUT、DELETE,还可能包括 HEAD 和
OPTIONS。简单的理解就是,如果想要访问互联网上的资源,就必须向资源所在的服务器发出请求,请求体中必须包含资源的网络路径,以及对资源进行的操作(增删改查)。
二、参考链接
[01] 分布式全文搜索引擎 Elasticsearch
[02] 百度- Elasticsearch
ElasticSearch入门教程(超详细)
目录
1.1ElasticSearch是什么?
ElasticSearch是一个分布式,RestFul风格的搜索和数据分析的引擎,能够解决不断涌出的各种用例。作为Elastic Stack的核心,他集中存储您的数据,帮助您发现意料之中以及医疗之外的情况。
The Elastic Stack,包括Elasticsearch,Kibana,Beats和Logstash(也好吃能为ELK Stack),能够安全可靠的获取任何来源,任何格式的数据,然后实时的对数据进行搜索,分析和可视化。ElasticSearch简称ES,是一个开源的高扩展的分布式全文搜索引擎,是整个Elastic Stack技术栈的核心,他可以实时存储,检索数据,本身扩展性很好,可以扩展到上百台服务器,处理OB级别的数据。
2.1Elasticsearch安装
2.1.1 下载软件
ElasticSearch的官网地址:https://www.elastic.co/cn/
我们选择7.8.0版本(主要学习es和java客户端的使用)
解压后,进入bin文件夹目录,点击elasticsearch.bat启动ES服务

注意:9300端口号为ES集群之间组件的通信端口,9200端口为浏览器访问http协议的Restful端口
打开浏览器,输入http://localhost:9200

如何所示,es启动成功
可能会出现的错误:
1.es是使用java开发的,且7.8版本es需要jdk为1.8版本以上,默认安装包带有jdk环境,如果系统配置饿了JAVA_HOME,那么使用系统默认的JDK。
2.双击闪退-----可能是因为空间不足,修改config/jvm.options配置文件

2.2.2使用Postman客户端工具
如果直接通过浏览器向ES服务器发送请求,name需要在发送的请求中包含HTPP的标准方法,而HTTP大部分特性仅支持GET和POST,所以为了方便,使用Postman软件
Postman官网: https://www.getpostman.com
2.2.3数据格式
ES是面向文档型数据库,一条数据在这里就是一个文档,为了方便大家理解,我们将ES里存储文档数据和Mysql存储数据的概念进行一个类比

ES里的Index可以看做一个数据库,Type相当于表,Documents相当于行,Fields相当于列
正(排)向索引
id content
-----------------------------
1001 my name is zhang san
1002 my name is li si
根据文章编号,能够快速查询到文章内容。文章编号为主键
当需要查到文章内容包含zhang san 时,需要用到模糊查询,大小写问题,这种情况正向索引的效率就慢了很多。场景比如(百度上搜zhang san),这个时候倒排索引出现了
倒排索引
keyword id
---------------------------------
name 1001,1002
zhang 1001
li 1002
正向索引是根据id跟内容绑定,倒排索引是关键字和id绑定,再去查文章内容。上结构中name在序号为1001和1002的文章内容中都出现过,所以下面以此类推.统称为倒排索引,查询效率相对较快,表的作用已经弱化了。
2.2.4.1基本使用
(按我的理解:这种使用就是个入门,当个字典翻翻就可以)
(1)创建索引
对比Mysql中,创建索引就等于创建数据库
在postman中,向ES服务器发送PUT请求:http://127.0.0.1:9200/shopping

如果再次创建,同名就会报错。shopping已经存在了

(2)获取索引
只需要把请求方式变为GET

如果想展示出所有的索引信息,修改urlhttp://127.0.0.1:9200/_cat/indices?v

我这边两个索引,user2和shopping
(3)删除索引
请求方式改为DELETE,url为:http://127.0.0.1:9200/shopping

后续可以去验证一下是否删除成功.
2.2.4.2 文档操作
(1)添加文档数据
请求方法为POST. http://127.0.0.1:9200/shopping/_doc
_doc表示给索引中添加文档数据。文档数据的请求体不能为空(请求体里面就是添加的数据,如果数据都没有肯定报错),添加的数据以json串形式

可以自定义上面图中的返回值_id.请求url修改为: http://127.0.0.1:9200/shopping/_doc/1001

(2)查询文档数据
只需要改为GET请求
http://127.0.0.1:9200/shopping/_doc/1001 查询id为1001的文档数据
如果想查询shopping索引下的所有文档数据
http://127.0.0.1:9200/shopping/_search
(3)修改文档数据(全量修改和局部修改)
比如我全量修改上面id为1001的数据
http://127.0.0.1:9200/shopping/_doc/1001

这个时候,1001的数据全被修改了。小伙伴们可以去验证一下,不展示了。
局部数据的修改
请求为POST http://127.0.0.1:9200/shopping/_update/1001 _doc改为update,不然服务器以为我们要新增数据
局部数据修改,所以请求体中,改哪个写哪个。删除的话,大家自己按着这个思路走就行了

(4)条件查询&分页查询
条件查询
请求为GET http://127.0.0.1:9200/shopping/_search?q=name:张三
其中q的意思为query查询。查询索引中所有文档name为张三的信息

条件查询有一个弊端,url中'张三'容易乱码,所以请求参数写在请求体里面

其中url后面的参数不要,请求体中的参数 query为查询,match为匹配。匹配的是name为张三的数据,这样就容易理解了。
分页查询

其中,size是每页2条数据,from后面的值有一个公式。从第几页开始:(页数-1)*每页几条数据
比如从1页开始 from : 0
2页 from : 2
3页 from : 4
排序和隐藏

其中,_source后面表示我只需要显式name字段,其他字段就隐藏了。sort表示排序,json串是根据哪个字段---age,age内是升序降序。最终的结果

(5)多条件查询&范围查询(难点)
多条件查询

query:查询,bool:多个条件,must:等于sql语句中的and,两者都。(should表示sql中的or),match:匹配
用mysql:select * from 表名 where name ="张三" and sex ="男"
结果
结果出现两条,张飞也出来了,百思不得其解。这时候想起来可能和倒排索引,分词那块有关系,我又把name换成 "三",只出来一个"张三"这一条数据,又将name换成了"飞三",张飞和张三都查出来了。有点类似于模糊查询了.后来才知道,想要完全匹配match改成match_phrase
范围查询

filter:过滤,range:范围 gt:大于 lt:小于
等价于 select ........from where .......... and age>11 and age<41,下图是结果

(6)全文检索&完全匹配&高亮查询


highlight就是高亮查询,查询出来的结果就是em标签体那栏
(7)聚合查询

不仅可以分组,求年龄的平均值也可以

(8)映射关系
ES的映射关系类似于Mysql中表结构,字段长度等等信息。比如我们有时候查询一个name:"飞三" 会出现张飞和张三,可以设置ES的配置信息,控制分词效果。
先创建索引user

给user添加配置信息

添加数据..........
测试结果1: type:text生效。index:true生效
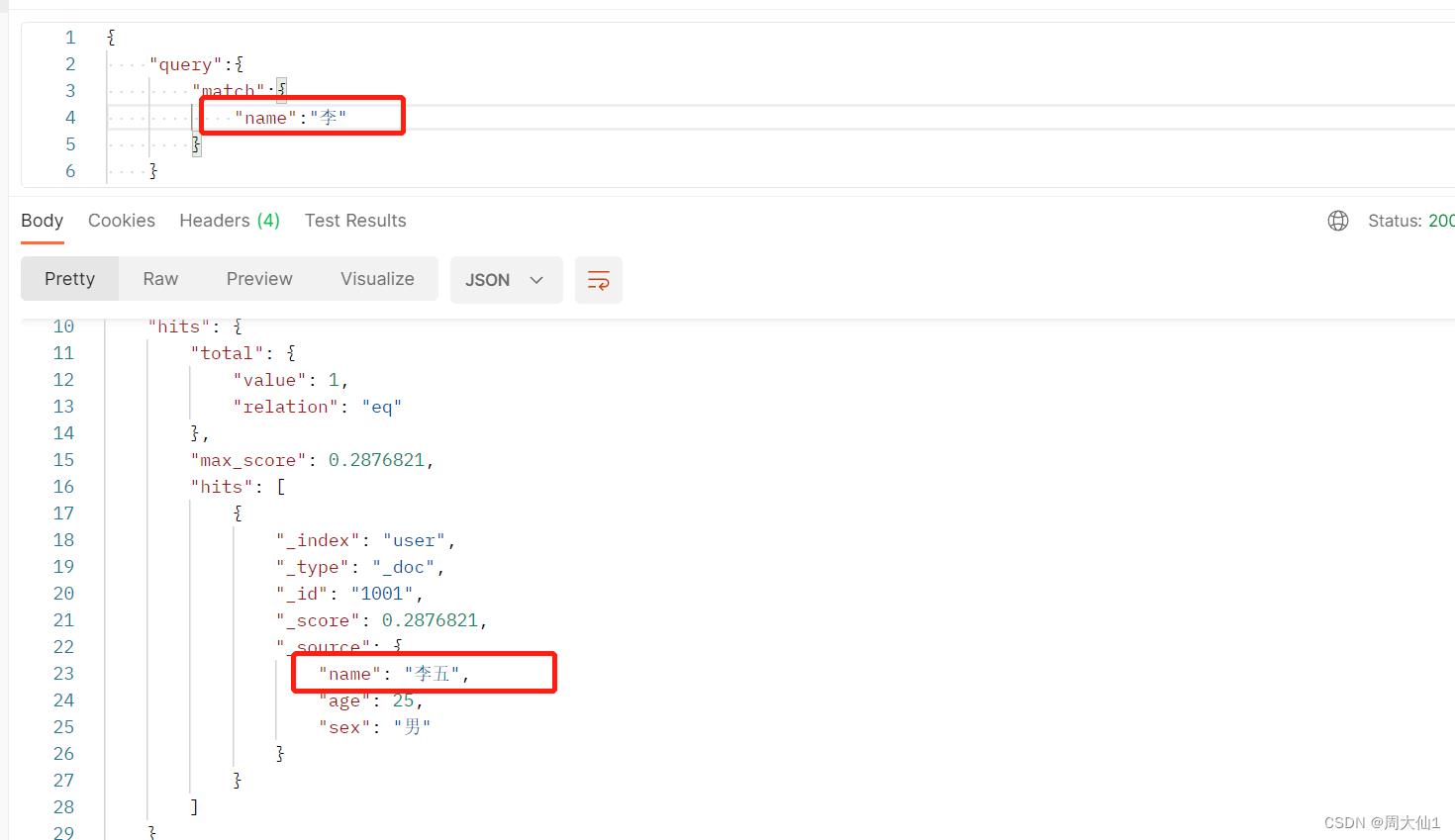
测试结果2: type:keyword 生效 index 生效

测试结果3: index:false 生效,不能根据索引去查询性别字段数据

最后感兴趣的小伙伴们可以去仔细了解一下倒排索引和分词。看一下上面mysql和es的对照表。就容易理解了
以上是关于550Elasticsearch详细入门教程系列 -分布式全文搜索引擎 Elasticsearch 2023.03.31的主要内容,如果未能解决你的问题,请参考以下文章
VMware ESXI 7.0 手动安装INTEL万兆X550-T2网卡驱动教程
ES 8.x 系列教程:ES 8.0 服务安装(可能是最详细的ES 8教程)